
【今日CV 计算机视觉论文速览 第122期】Fri, 31 May 2019
今日CS.CV 计算机视觉论文速览
Fri, 31 May 2019
Totally 50 papers
👉上期速览✈更多精彩请移步主页
Interesting:
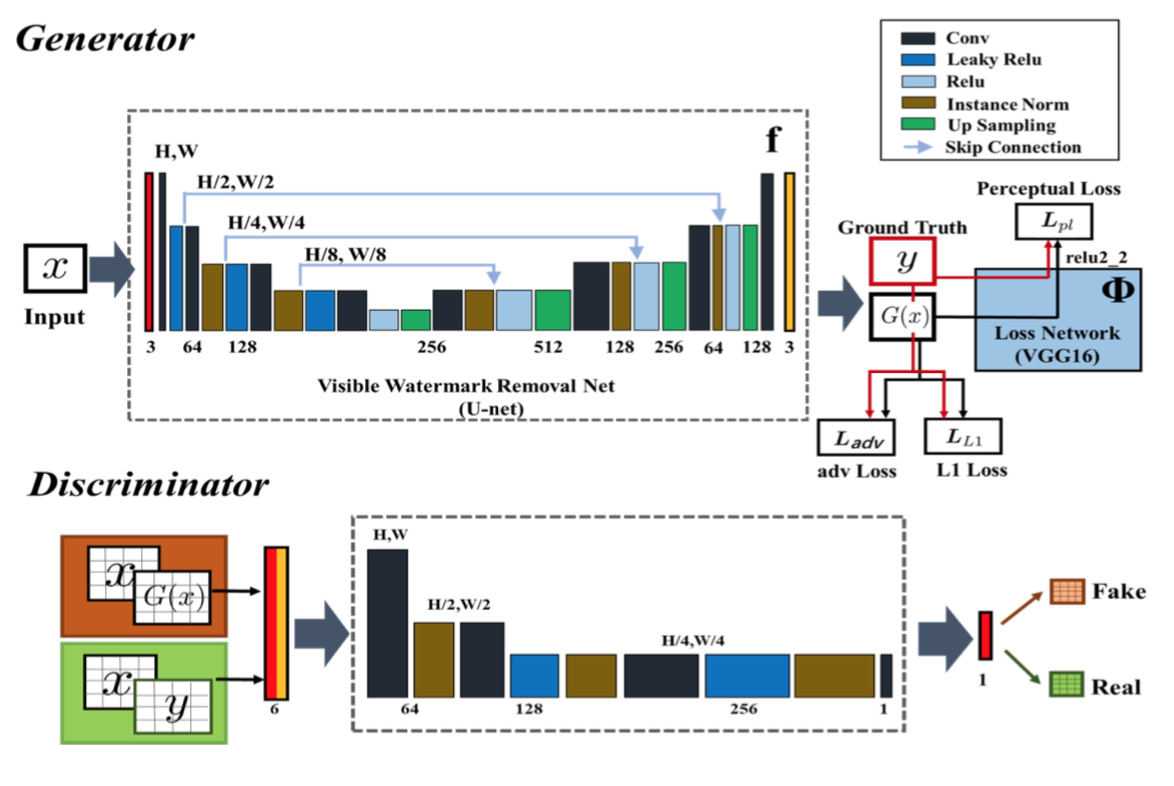
📚基于条件GANs的图像去水印方法,增强了条件L1损失和感知损害,作为对抗训练损失来给出了更为真实的图像。 (from 中山大学)
改造的损失函数:

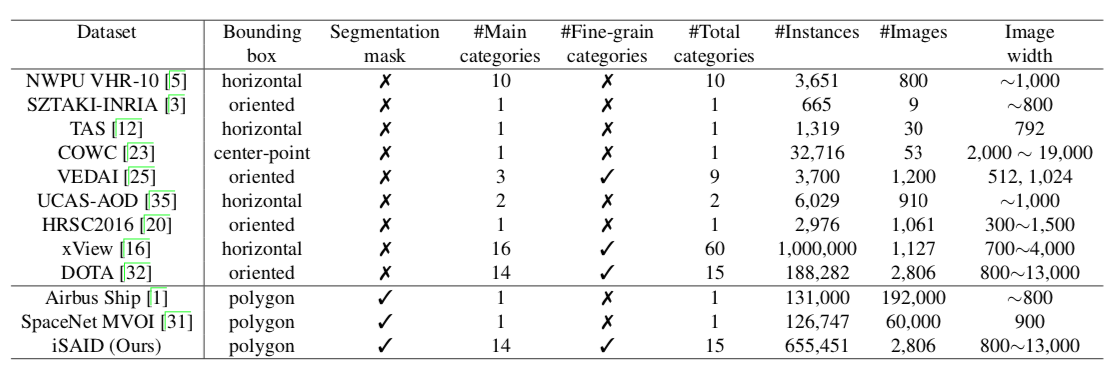
📚iSAID大规模的航空图像实例分割数据集, 包含了655451个实例标注,15个类别(from Inception Institute of Artificial Intelligence, UAE)
语义分割ss和实例分割is:

一些数据样例:

相关数据集:
ref:PANet++,Path aggregation network for instance segmentation. 用于实例分割

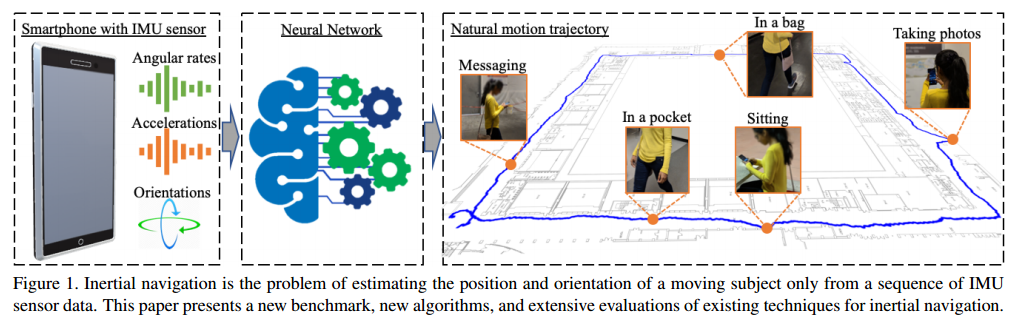
📚RoNIN,神经惯性里程计的基准数据集,包含了超过40h的IMU数据,收集于100个人类的正式三维轨迹数据,基于新型神经惯性导航架构来改进位姿估计,定量定性的评测了相关方法。(from 华盛顿大学St. Louis)
用于估计轨迹的模型:
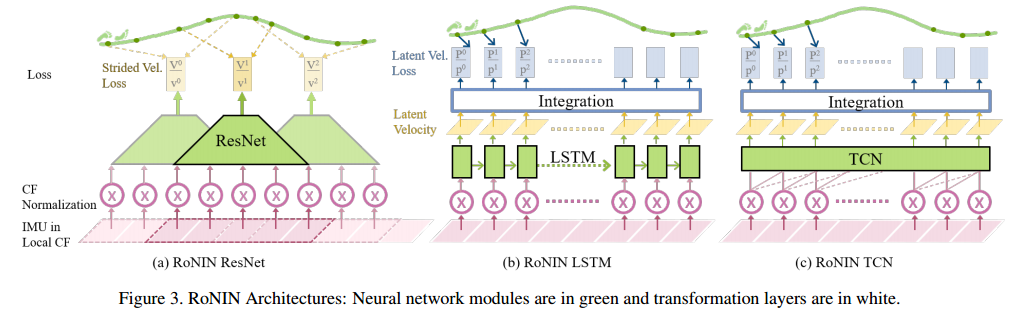
项目网站:http://ronin.cs.sfu.ca/
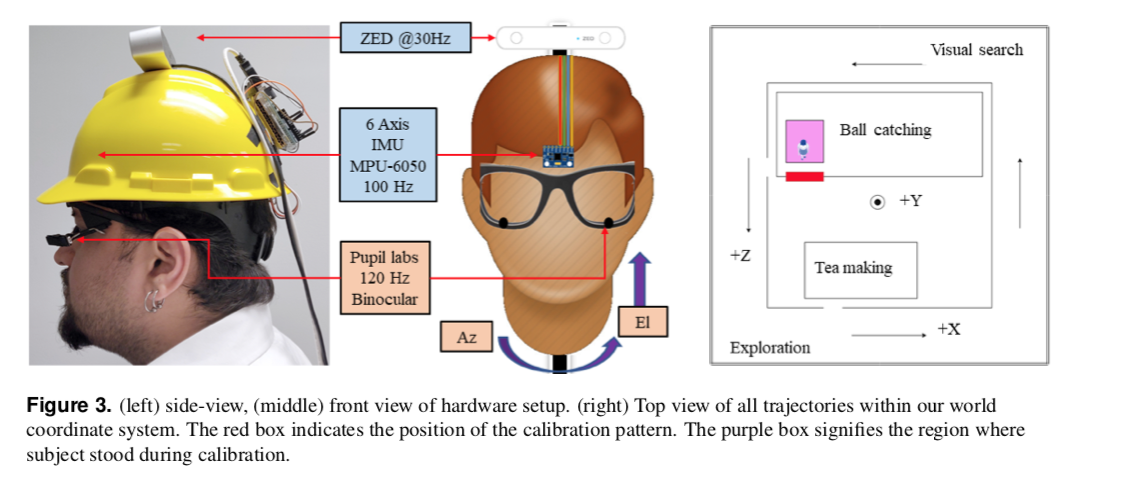
📚Gaze-in-wild, 大规模数据集研究日常生活中人眼和头部的位置坐标。(from Center for Imaging Science, RIT )
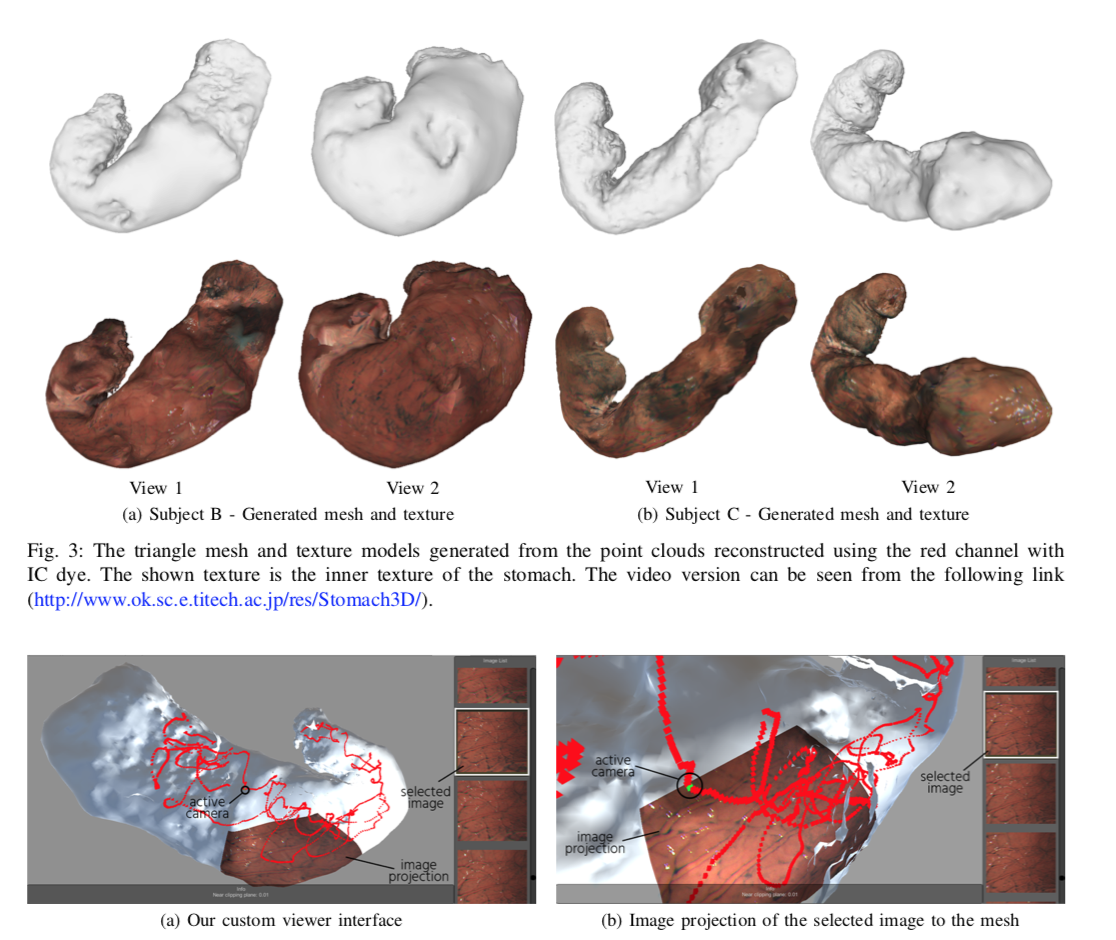
📚利用胃内窥镜视频,基于sfm的胃部三维重建, (from 东京技术大学)
ref:http://www.ok.sc.e.titech.ac.jp/res/Stomach3D/
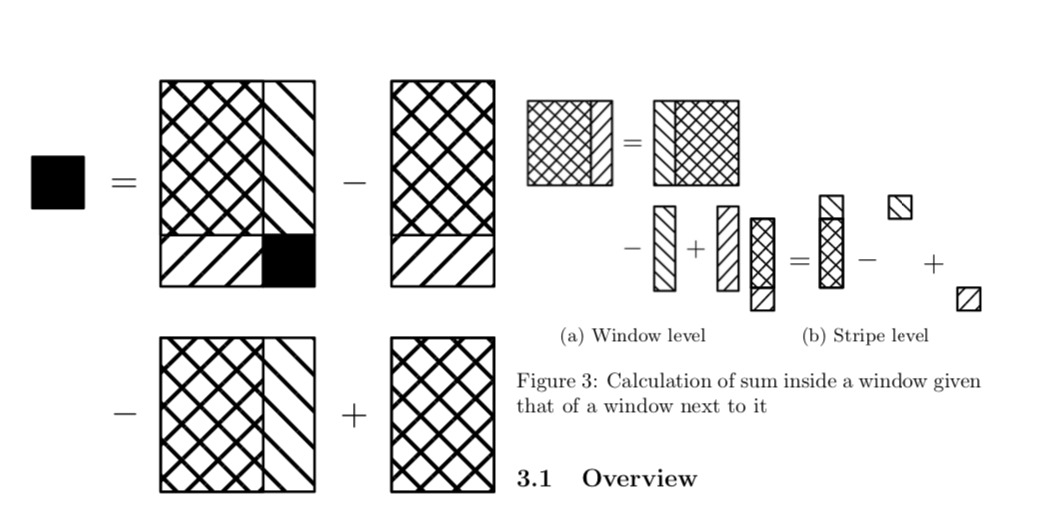
📚一种内存高效、快速实现的局域自适应二值化方法, (from 中山大学)
算法的一些实现:
和一些方法的比较:
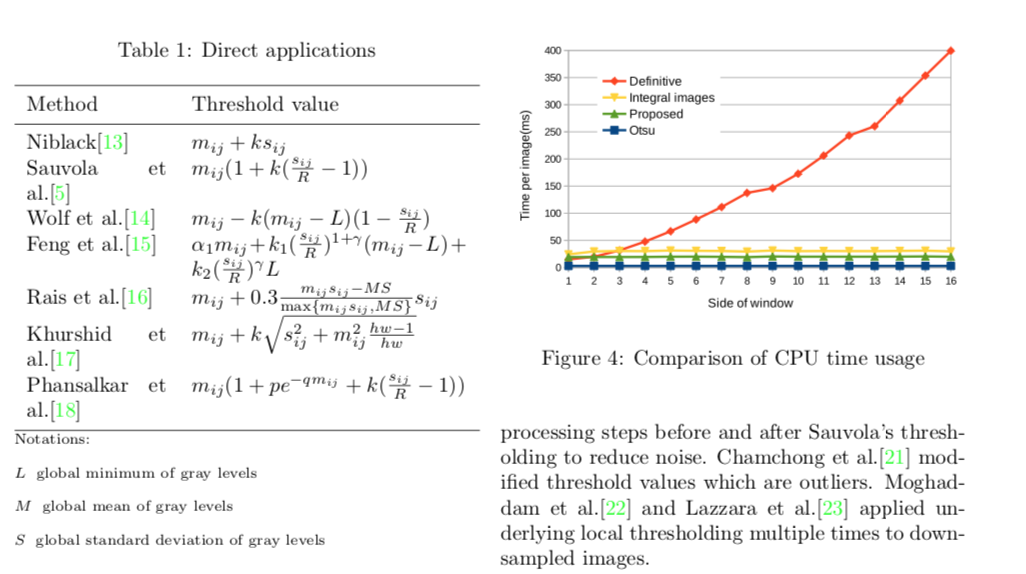
ref: Sauvola’s method
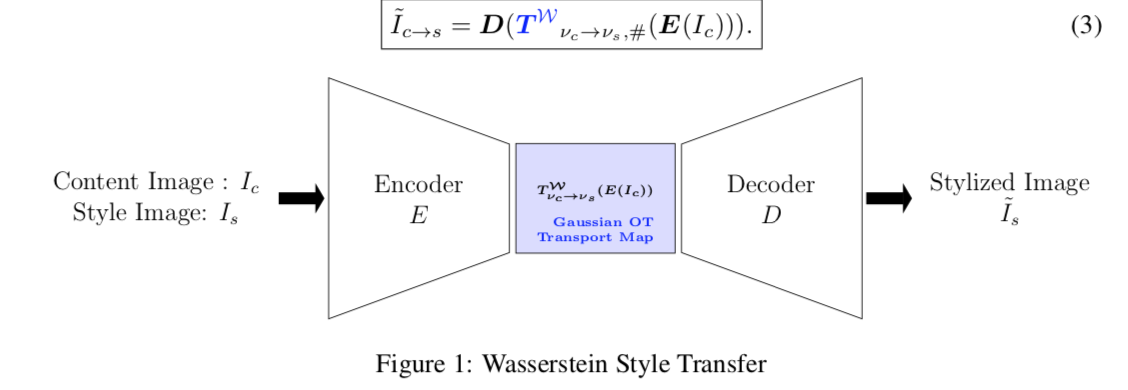
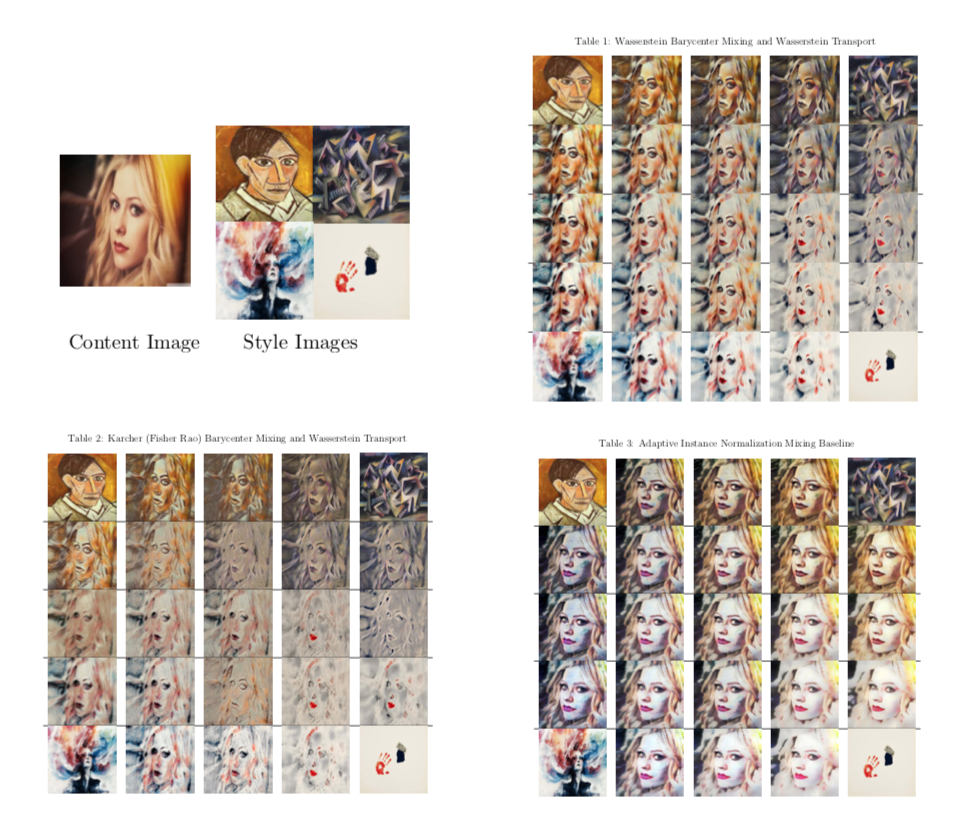
📚基于wasserstein的风格迁移, 研究人员利用高斯优化输运过程用于编码器解码器的图像风格迁移。基于高斯测度的优化输运可以将原分布映射到目标分布,同时也可以在内容和风格图像间进行差值,并进行多种风格混合。由于高斯在wasserstein质心下有闭合形式使得迁移和差值成为可能。(from IBM research)
迁移器的形式:
两种风格间的差值:

内容图像在四种风格下的wasserstein重心插值:
📚基于量子计算机D-WAVE2X进行图像分类, (from Los Alamos National Laboratory)
📚2D3D目标分类的检测的汇总, 这篇论述详细的总结了2d向3d扩展视觉任务所面临的困难,包括数据表示、计算资源消耗、不同的分布情况、数据较为稀疏标记缺乏等。并总结了基于二维图像和三维信息的视觉识别系统。文章综述了不同系统、数据集和方法。(from 纽约大学研究生中心)
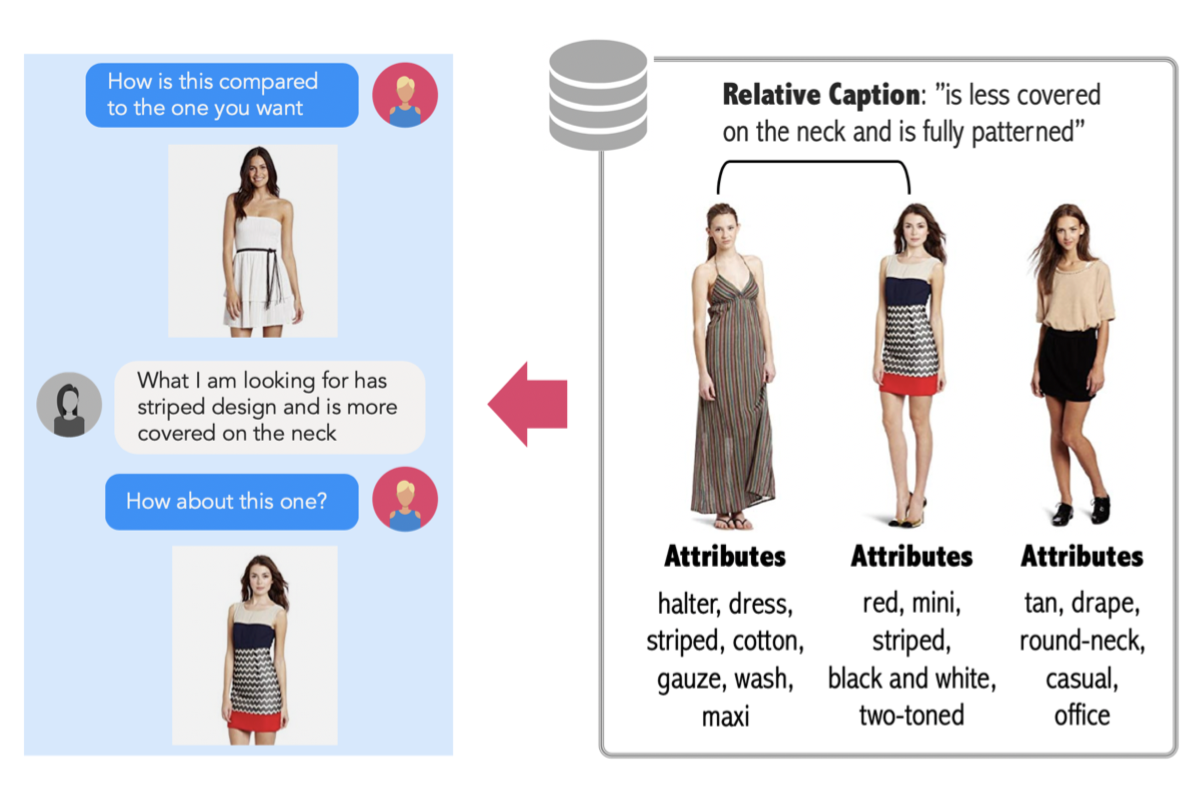
📚FashionID Dataset 基于次要信息和自然语言反馈的时尚图像检索, 数据集中包含了属性标签和相关的图像标题,可以用于构建自然语言反馈(from IBM research AI)
📚基于U-Net的医学图像分割模型, 充分利用了多尺度和先验信息(from DeepMind)
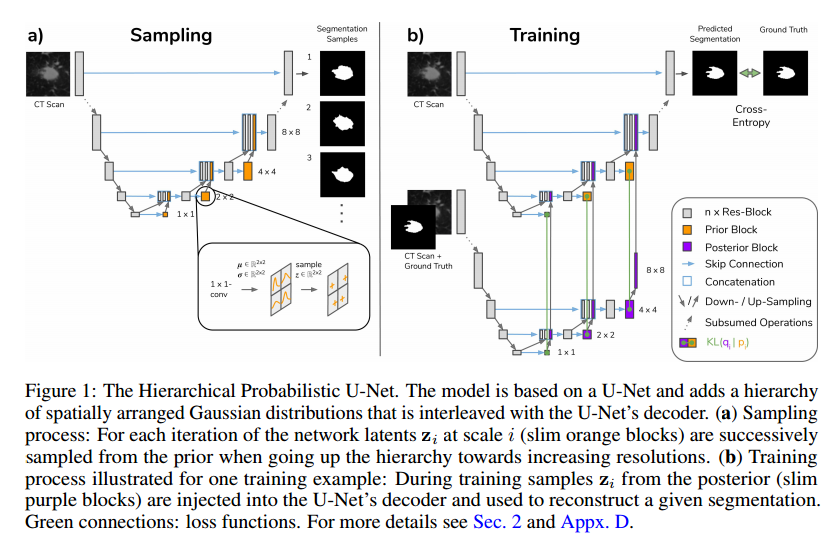
一些结果:
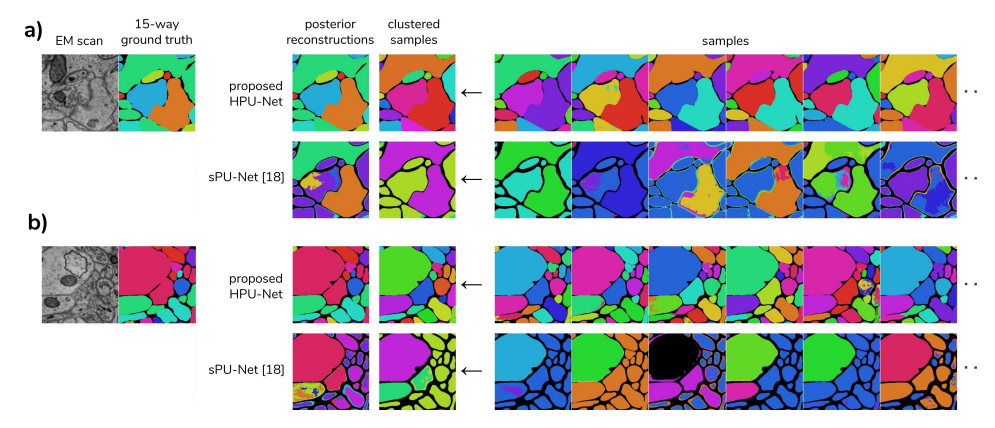
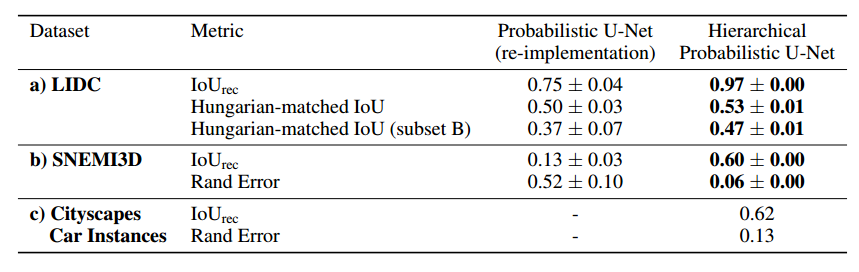
三维医学图像分割比赛:http://brainiac2.mit.edu/SNEMI3D/
概率Unet ref:A Probabilistic U-Net for Segmentation of Ambiguous Images,link
📚一种基于迁移学习的小样本缺陷检测方法, (from 滑铁卢大学)
一些结果,来自混泥土裂纹数据集Concrete crack:

Daily Computer Vision Papers
| On Network Design Spaces for Visual Recognition Authors Ilija Radosavovic, Justin Johnson, Saining Xie, Wan Yen Lo, Piotr Doll r 在过去几年中,设计用于视觉识别的更好的神经网络架构的进展是巨大的。为了帮助维持这一进展速度,我们建议在这项工作中重新审视比较网络架构的方法。特别地,我们引入了一种新的分布估计比较范例,其中通过将统计技术应用于采样模型的群体来比较网络设计空间,同时控制网络复杂性等混杂因素。与目前比较模型族的点和曲线估计的方法相比,分布估计可以更全面地描绘整个设计格局。作为案例研究,我们研究了神经架构搜索NAS中使用的设计空间。我们发现最近的NAS设计空间变体之间存在显着的统计差异,而这些差异在很大程此外,我们的分析表明,像ResNeXt这样的标准模型系列的设计空间可以与最近NAS工作中使用的更复杂的设计空间相媲美。我们希望这些对分布分析的见解能够在发现更好的视觉识别网络方面取得更大的进展。 |
| AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures Authors Michael S. Ryoo, AJ Piergiovanni, Mingxing Tan, Anelia Angelova 学习表示视频在算法和计算上都是一项非常具有挑战性的任务。标准视频CNN架构的设计是通过使用有限数量的空间时间模块(如3D卷积)直接将用于图像理解的架构扩展到第三维,或者通过引入手工制作的两个流设计来捕获视频中的外观和运动。我们将视频CNN解释为彼此连接的多流时空卷积块的集合,并提出了自动寻找具有更好连接性的视觉理解的神经架构的方法。这是通过改进由连接权重学习引导的过度连接的体系结构来完成的。搜索组合抽象不同输入类型的表示的结构,即,以多个时间分辨率的RGB和光流,搜索允许不同类型或信息源彼此交互。我们的方法(称为AssembleNet)优于公共视频数据集的先前方法,在某些情况下大幅提升。 |
| An attention-based multi-resolution model for prostate whole slide imageclassification and localization Authors Jiayun Li, Wenyuan Li, Arkadiusz Gertych, Beatrice S. Knudsen, William Speier, Corey W. Arnold 组织学评论通常被用作疾病诊断的金标准。计算机辅助诊断工具可以通过减少检查时间和观察者之间的可变性来帮助改善当前的病理学工作流程。以前在癌症分级方面的工作主要集中在对预定义的感兴趣区域ROI进行分类,或依赖于大量细粒度标签。在本文中,我们提出了一个基于两阶段注意的多实例学习模型,用于幻灯片水平癌症分级和弱监督ROI检测,并证明其在前列腺癌中的应用。与现有的Gleason分类模型相比,我们的模型更进一步,利用可视化显着性图来选择信息化的瓷砖进行细粒度等级分类。该模型主要是在大规模的整个幻灯片数据集上开发的,该数据集由3,521个前列腺活检切片组成,仅有718名患者的载玻片水平标签。该模型实现了前列腺癌分级的最先进性能,精确度为85.11,用于分类良性,低级Gleason 3级或3级,以及高级Gleason 4级3级或更高级别的滑动在独立测试组上。 |
| The Art of Food: Meal Image Synthesis from Ingredients Authors Fangda Han, Ricardo Guerrero, Vladimir Pavlovic 在这项工作中,我们提出了一个基于生成深度模型的新计算框架,用于从其成分的文本描述中合成照片真实食物餐图像。以前关于从文本合成图像的工作通常依赖于预先训练的文本模型来提取文本特征,接着是生成神经网络GAN,旨在生成以文本特征为条件的逼真图像。这些作品主要集中在产生空间紧凑和明确定义的物体类别,如鸟类或花卉。相比之下,膳食图像明显更复杂,由多种成分组成,其外观和空间质量通过烹饪方法进一步改变。我们提出了一种方法,首先建立基于注意力的成分图像关联模型,然后用于调节负责合成膳食图像的生成神经网络。此外,添加循环一致约束以进一步改善图像质量和控制外观。大量实验表明,我们的模型能够生成与成分相对应的膳食图像,可用于增加现有数据集以解决其他计算食品分析问题。 |
| Moving Target Defense for Deep Visual Sensing against Adversarial Examples Authors Qun Song, Zhenyu Yan, Rui Tan 基于深度学习的视觉传感已经获得了极具吸引力的准确性,但是很容易受到对抗性示例攻击。具体来说,一旦攻击者获得深度模型,他们就可以构建对抗性示例来误导模型以产生错误的分类结果。可展开的对抗性示例,例如粘贴在道路标志和车道上的小贴纸,已经被证明可以有效地误导高级驾驶员辅助系统。针对对抗性示例的许多现有对策构建了对攻击者无视防御机制的安全性。因此,他们没有遵循Kerckhoffs的原则,并且一旦攻击者知道防御的细节就可以被颠覆。本文采用移动目标防御MTD策略,在系统部署后生成多个新的深度模型,协同检测和阻止对抗实例。我们的MTD设计基于对抗性示例,对模型的可转移性不同,例如,用于攻击构造的工厂设计模型。部署后的准秘密深度模型显着增加了攻击者构建有效对抗示例的门槛。我们还应用串行数据融合技术和早期停止技术,将推理时间缩短了5倍,同时保持了传感和防御性能。基于三个数据集的广泛评估,包括道路标志图像数据库和配备GPU的Jetson嵌入式计算板,显示了我们的方法的有效性。 |
| Anomaly Detection in Images Authors Manpreet Singh Minhas, John Zelek 视觉缺陷评估是一种异常检测。这与在路面和汽车零件等各种表面检测任务中发现诸如裂缝和标记等缺陷非常相关。该任务涉及检测异常样本与正常样本的偏差分歧。监督异常检测的两个主要挑战是缺乏标记的训练数据和异常实例的低可用性。半监督方法,其学习正常样本的基础分布,然后测量偏离偏差与估计模型,因为异常分数在其检测异常的总体能力方面具有局限性。本文提出了基于网络的卷积神经网络CNNs深度传递学习在异常检测中的应用。单类SVM在过去已经成功使用,但是我们假设单类分类的更深层网络应该表现更好。在已建立的异常检测基准以及现实世界数据集上获得的结果表明,通过在测试数据的接收器操作特征曲线值0.99下实现惊人的平均面积,所提出的方法明显优于现有技术方法。 CIFAR10的平均改进为41,MNIST为20,水泥裂缝数据为16。 |
| Gaze-in-wild: A dataset for studying eye and head coordination in everyday activities Authors Rakshit Kothari, Zhizhuo Yang, Christopher Kanan, Reynold Bailey, Jeff Pelz, Gabriel Diaz 前庭和眼睛系统之间的相互作用主要在受控环境中进行研究。因此,用于分类凝视事件的现成工具,例如,当允许头部运动时,注意力,追求,扫视失败。我们的方法是在佩戴配备惯性测量单元和3D立体相机的移动眼动仪时,在受试者执行日常任务时收集眼睛头部运动的新颖,自然和多模态数据集。该野外数据集GW中的凝视包括眼头旋转速度deg,红外眼睛图像和场景图像RGB D.编码器将一部分标记为凝视运动事件,其中基于0.72样本的Cohen s kappa相互协商。该标记数据用于训练和评估两种机器学习算法,随机森林和回归神经网络模型,用于凝视事件分类。评估涉及应用既定的和新颖的基于事件的绩效指标。分类器在检测固定和扫视时达到了人类的性能,但在检测追踪运动方面达不到60。而且,在没有头部运动信息的情况下,追求分类更加糟糕。在我们的最佳表现模型中对特征显着性的后续分析揭示了对绝对眼睛和头部速度的依赖,表明分类不需要头部和眼睛跟踪坐标系统的空间对准。 GW数据集,训练有素的分类器和评估指标将公开提供,旨在促进头部自由凝视事件分类的新兴领域的增长。 |
| Prostate Cancer Detection using Deep Convolutional Neural Networks Authors Sunghwan Yoo, Isha Gujrathi, Masoom A. Haider, Farzad Khalvati 前列腺癌是最常见的癌症形式之一,也是北美癌症死亡的第三大原因。作为计算机辅助检测CAD工具的一个组成部分,扩散加权磁共振成像DWI已被深入研究,以准确检测前列腺癌。利用深度卷积神经网络,CNN在计算机视觉任务(例如物体检测和分割)方面取得了重大成功,不同的CNN架构在医学成像研究界越来越多地被研究作为设计更准确的癌症检测CAD工具的有希望的解决方案。在这项工作中,我们开发并实施了基于CNN的自动化管道,用于检测临床上显着的前列腺癌PCa,用于给定的轴向DWI图像和每位患者。将427名患者的DWI图像用作数据集,其中包含175名PCa患者和252名健康患者。为了测量所提出的管道的性能,预留了427名患者中的108名测试装置,并且未在训练阶段使用。所提出的管道在切片水平和患者水平下的接收器操作特征曲线AUC分别达到0.87 95置信区间CI 0.84 0.90和0.84 95 CI 0.76 0.91。 |
| Semantics-Aligned Representation Learning for Person Re-identification Authors Xin Jin, Cuiling Lan, Wenjun Zeng, Guoqiang Wei, Zhibo Chen 人物识别reID旨在匹配人物图像以检索具有相同身份的人物图像。这是一项具有挑战性的任务,因为要匹配的图像通常在语义上不对齐,因为人体姿势和捕获视点的多样性,由于遮挡等原因导致的可见体的不完整性等。在本文中,我们提出了一个驱动reID的框架。网络通过精细的监督设计学习语义对齐的特征表示。具体来说,我们构建了一个语义对齐网络SAN,它包括一个基本网络作为编码器SA Enc用于重新ID,以及一个解码器SA Dec用于重建回归密集语义对齐的全纹理图像。我们在人员识别和对齐纹理生成的监督下共同训练SAN。此外,在解码器处,除了重建损失之外,我们在特征图上添加三元组reID约束损失作为感知损失。在推理测试中丢弃解码器,因此我们的方案在计算上是有效的。消融研究证明了我们设计的有效性。我们在基准数据集CUHK03,Market1501,MSMT17和部分人reID数据集Partial REID上实现了最先进的性能。 |
| A Deep Framework for Bone Age Assessment based on Finger Joint Localization Authors Xiaoman Zhang, Ziyuan Zhao, Cen Chen, Songyou Peng, Min Wu, Zhongyao Cheng, Singee Teo, Le Zhang, Zeng Zeng 骨龄评估是衡量骨骼儿童成熟度和生长障碍诊断的重要临床试验。诸如Tanner Whitehouse TW和Greulich和Pyle GP之类的传统方法由于它们的大观察者和观察者内部变化而可能表现不佳。在本文中,我们提出了一种手指关节定位策略来过滤掉图像中大多数非信息部分。当与传统的基于全图像的深度网络结合时,我们观察到了大大改进的性能。我们的方法利用全手和特定关节图像进行骨骼成熟度预测。在这项研究中,我们应用强大的深度神经网络,并探索了骨骼年龄预测的过程与特定的联合关节图像,以提高与整个手部图像相比的性能准确性。 |
| A Hierarchical Probabilistic U-Net for Modeling Multi-Scale Ambiguities Authors Simon A. A. Kohl, Bernardino Romera Paredes, Klaus H. Maier Hein, Danilo Jimenez Rezende, S. M. Ali Eslami, Pushmeet Kohli, Andrew Zisserman, Olaf Ronneberger 医学成像仅间接测量每个体素内组织的分子身份,这通常仅产生目标感兴趣测量的模糊图像证据,如语义分割。这种多样性和似是而非的解释的变化通常特定于给定的图像区域,并且因此可以在从像素到图像级别的所有路径上的各种尺度上表现出来。为了学习可以解释多种变化尺度的灵活分布,我们提出了分层概率U Net,一种带有条件变分自动编码器cVAE的分割网络,它使用分层潜在空间分解。我们证明了这种模型公式能够对高保真度的分段进行采样和重建,即具有精细分辨的细节,同时提供了跨尺度学习复杂结构分布的灵活性。我们在分割模糊医学扫描以及神经生物学和自然图像的实例分割的任务上展示了这些能力。我们的模型自动地将不同尺度的独立因素分开,这是我们认为在分割之外的结构化输出预测任务中有益的归纳偏差。 |
| Robust Sparse Regularization: Simultaneously Optimizing Neural Network Robustness and Compactness Authors Adnan Siraj Rakin, Zhezhi He, Li Yang, Yanzhi Wang, Liqiang Wang, Deliang Fan 已知通过梯度下降法训练的深度神经网络DNN易受恶意扰动的对抗性输入,也就是说。对抗性攻击。作为抵御对抗性攻击的对策之一,提出了增加DNN鲁棒性增强的模型容量,并且作为近期许多工作的有效方法进行了报告。在这项工作中,我们表明通过适当的重量修剪缩小模型大小甚至可以有助于提高对抗性攻击下的DNN稳健性。为了获得同时稳健和紧凑的DNN模型,我们提出了一种称为鲁棒稀疏正则化RSR的多目标训练方法,通过各种正则化技术的融合,包括通道噪声注入,套索权重惩罚和对抗训练。我们在流行的ResNet 20,ResNet 18和VGG 16 DNN架构上进行了大量实验,以证明RSR对流行白盒的有效性,即PGD和FGSM以及黑盒攻击。得益于RSR,与其PGD对抗性训练基线相比,可以修剪ResNet 18的85个重量连接,同时在CIFAR 10数据集上分别实现干净和扰动数据准确度的0.68和8.72改善。 |
| Align-and-Attend Network for Globally and Locally Coherent Video Inpainting Authors Sanghyun Woo, Dahun Kim, KwanYong Park, Joon Young Lee, In So Kweon 我们提出了一种用于视频修复的新型前馈网络。我们使用一组采样视频帧作为参考,以获取可见内容以填充目标帧的孔。我们的视频修复网络包括两个阶段。第一阶段是对齐模块,其使用参考帧和目标帧之间的计算的单应性。然后基于帧相似性聚集可见补丁以粗略地填充目标孔。第二阶段是非本地关注模块,其将生成的补丁与空间和时间中的已知参考补丁相匹配,以细化先前的全局对齐阶段。两个阶段都包括用于参考的大空间时间窗口大小,因此能够建模远程信息和孔区域之间的长程相关性。因此,甚至可以处理具有大的或缓慢移动的孔的具有挑战性的场景,这些场景几乎不能通过现有的基于流的方法建模。我们的网络还设计有循环传播流,以鼓励视频结果的时间一致性。视频对象去除的实验表明,我们的方法使用全局和局部相干内容来绘制漏洞。 |
| Recognition in Unseen Domains: Domain Generalization via Universal Non-volume Preserving Models Authors Thanh Dat Truong, Chi Nhan Duong, Khoa Luu, Minh Triet Tran 跨领域的认可最近成为研究界的一个活跃话题。然而,在新的看不见的领域中,它的识别问题在很大程度上被忽视了。在这种情况下,交付的深层网络模型无法更新,调整或微调。因此,不能应用最近的深度学习技术,例如域自适应,特征传递和微调。本文提出了一种在深度学习背景下解决领域概括问题的新方法。所提出的方法在各种问题的不同数据集上进行评估,即,对MNIST,SVHN和MNIST M进行数字识别,ii对扩展耶鲁B,CMU PIE和CMU MPIE进行面部识别,以及iii对RGB和热图像数据集进行行人识别。实验结果表明,我们提出的方法不断提高性能的准确性。它还可以轻松地与端到端深度网络设计中的任何其他CNN框架结合,用于对象检测和识别问题,以改善其性能。 |
| Memory-efficient and fast implementation of local adaptive binarization methods Authors Chungkwong Chan 二值化被广泛用作图像预处理步骤,以在识别之前将对象尤其是文本与背景分离。对于具有不均匀照明的噪声图像,应逐像素地计算阈值以获得良好的分割。由于局部阈值通常取决于基于矩的统计量,例如矩形窗口内的灰度级的均值和方差,因此通常使用积分图像来加速计算。但是,积分图像是消耗内存的。对于Sauvola方法,给定H倍W输入图像,两个积分图像占据16HW字节。通过使用递归技术来避免积分图像,中间数据结构的存储器使用可以显着减少到6分钟H,W字节,而时间复杂度保持为O HW而与窗口大小无关。因此,所提出的实现使得各种局部自适应二值化方法能够在具有有限资源的设备上的实时使用情况中应用。 |
| 3D Reconstruction of Whole Stomach from Endoscope Video Using Structure-from-Motion Authors Aji Resindra Widya, Yusuke Monno, Kosuke Imahori, Masatoshi Okutomi, Sho Suzuki, Takuji Gotoda, Kenji Miki 胃内窥镜检查是一种常见的临床实践,使医生能够诊断体内的胃。为了识别胃病变位置,例如胃内的早期胃癌,该工作旨在利用从标准单眼内窥镜视频产生的颜色纹理信息重建整个胃的3D形状。以前的工作已经尝试从内窥镜图像重建各种器官的3D结构。然而,它们主要集中在部分表面上。在这项工作中,我们研究了如何从运动SfM启用结构,以从标准内窥镜视频重建胃的整个形状。我们专门研究了染色内窥镜检查和颜色通道选择对SfM的综合影响。我们的研究发现,通过使用染色内窥镜下捕获的红色通道图像,通过在胃表面上散布靛蓝胭脂红IC染料,可以实现全胃的3D重建。 |
| Interactive-predictive neural multimodal systems Authors lvaro Peris, Francisco Casacuberta 尽管神经模型在序列学习中取得了进步,但在各种任务中被利用,它们仍然会产生错误。在许多使用案例中,这些都是由后期修订过程中的人类专家纠正的。交互式预测框架旨在通过考虑用于迭代地改进假设的部分校正来最小化在该过程上花费的人力。在这项工作中,我们概括了通常应用于机器翻译领域的交互式预测方法,以解决其他多模式问题,即图像和视频字幕。我们研究了该框架在多模态神经序列中对序列模型的应用。我们表明,遵循这个框架,我们大约将用于纠正自动系统生成的输出的工作减半。此外,我们将系统部署在可公开访问的演示中,以便更好地理解交互式预测框架的行为。 |
| Learning Semantics-aware Distance Map with Semantics Layering Network for Amodal Instance Segmentation Authors Ziheng Zhang, Anpei Chen, Ling Xie, Jingyi Yu, Shenghua Gao 在这项工作中,我们演示了另一种解决模块分割问题的方法。具体来说,我们首先引入一个新的表示,即语义感知距离图sem dist map,作为我们的氨基分割目标,而不是常用的掩模和热图。 sem dist map是一种水平集表示,其中对象的不同区域根据其可见性被放置在地图上的不同级别中。它是掩模和热图的自然延伸,其中模态,模式分割以及深度顺序信息都被很好地描述。然后,我们还介绍了一种新颖的卷积神经网络CNN架构,我们将其称为语义分层网络,从图像中的所有对象逐层估计sem dist map,从全局级到实例级。关于COCOA和D2SA数据集的大量实验已经证明,我们的框架可以使用最先进的性能预测结构分割,遮挡和深度顺序。 |
| Does computer vision matter for action? Authors Brady Zhou, Philipp Kr henb hl, Vladlen Koltun 计算机视觉产生场景内容的表示。许多计算机视觉研究都是基于这些中间表示对行动有用的假设。最近在机器学习和机器人技术的交叉点上的工作通过直接针对手头的任务(从像素到动作)训练感觉运动系统而使这个假设成为问题,没有明确的中间表示。因此,我们工作的核心问题计算机视觉是否对行动起重要作用我们通过沉浸式模拟探索这个问题及其分支,这使我们能够进行大规模的可控制的可重复实验。我们采用沉浸式三维环境来模拟城市驾驶,越野越野行走和战斗等挑战。我们的主要发现是计算机视觉确实重要。配备中间表示的模型训练更快,实现更高的任务性能,并更好地概括到以前看不见的环境。可以在以下位置找到总结工作并说明结果的视频 |
| iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images Authors Syed Waqas Zamir, Aditya Arora, Akshita Gupta, Salman Khan, Guolei Sun, Fahad Shahbaz Khan, Fan Zhu, Ling Shao, Gui Song Xia, Xiang Bai 现有的Earth Vision数据集适用于语义分割或对象检测。在这项工作中,我们引入了第一个基准数据集,用于航拍图像中的实例分割,它结合了实例级对象检测和像素级分割任务。与自然场景中的实例分割相比,航空图像呈现独特的挑战,例如,每个图像的大量实例,大的物体尺度变化和丰富的微小物体。我们在航空图像数据集中进行大规模且密集注释的实例分割iSAID在2,806个高分辨率图像中为15个类别提供655,451个对象实例。每个实例的这种精确的每像素注释确保了精确的定位,这对于详细的场景分析是必不可少的。与现有的基于小规模航空图像的实例分割数据集相比,iSAID包含对象类别数量的15倍和实例数量的5倍。我们使用两种流行的自然图像实例分割方法对数据集进行基准测试,即Mask R CNN和PANet。在我们的实验中,我们展示了在航拍图像上直接应用现成的Mask R CNN和PANet提供了次优的实例分割结果,因此需要来自研究界的专门解决方案。 |
| P3SGD: Patient Privacy Preserving SGD for Regularizing Deep CNNs in Pathological Image Classification Authors Bingzhe Wu, Shiwan Zhao, Guangyu Sun, Xiaolu Zhang, Zhong Su, Caihong Zeng, Zhihong Liu 最近,深度卷积神经网络CNN在病理图像分类方面取得了巨大成功。然而,由于标记的病理图像的数量有限,仍然存在两个需要解决的挑战1过度拟合CNN模型的性能由于其大量参数和标记的训练数据的不足而被过度拟合破坏。使用传统方法训练的模型的隐私泄漏可以不自觉地揭示训练数据集中患者的私人信息。数据集越小,隐私泄漏越严重。为了解决上述两个挑战,我们引入了一种新的随机梯度下降SGD方案,命名为患者隐私保护SGD P3SGD,其通过基于每个患者数据建立的大步骤更新来执行患者级别中SGD的模型更新。具体来说,为了保护隐私并规范CNN模型,我们建议将精心设计的噪声注入更新中。此外,我们为P3SGD配备了精确的策略,以自适应地控制注入噪声的规模。为了验证P3SGD的有效性,我们对现实世界的临床数据集进行了大量实验,并定量证明了P3SGD在降低过度拟合风险方面的卓越能力。我们还对差异隐私下的隐私成本进行了严格的分析。此外,我们发现使用P3SGD训练的模型与使用非私人SGD训练的模型相比,能够抵抗模型反转攻击。 |
| A Trainable Multiplication Layer for Auto-correlation and Co-occurrence Extraction Authors Hideaki Hayashi, Seiichi Uchida 在本文中,我们为神经网络提出了一个可训练的乘法层TML,可用于计算输入特征之间的乘法。将图像作为输入,TML将每个像素值提升到权重的幂,然后将它们相乘,从而从输入图像中提取更高阶的局部自相关。 TML还可用于从卷积网络的特征映射中提取共现。 TML的训练是基于对权重的约束的反向传播而制定的,使我们能够以端到端的方式学习判别性乘法模式。在实验中,通过可视化学习的内核和相应的输出特征来研究TML的特征。还使用公共数据集评估TML对分类和神经网络解释的适用性。 |
| Hierarchical Structure and Joint Training for Large Scale Semi-supervised Object Detection Authors Ye Guo, Yali Li, Shengjin Wang 通用对象检测是计算机视觉中最基本和最重要的问题之一。当涉及到数千个类别的大规模对象检测时,为每个类别提供所有边界框标签是不切实际的。在本文中,我们提出了一种新的大规模半监督对象检测的层次结构和联合训练框架。首先,我们利用目标类别之间的关系来建立分层网络,以进一步提高识别的性能。其次,将边界框级标记图像和图像级标记图像结合起来进行联合训练,该方法可以很容易地应用于当前的两阶段目标检测框架中,具有良好的性能。实验结果表明,所提出的大规模半监督目标检测网络在ImageNet检测验证数据集上获得了最新的性能,mAP为38.1。 |
| RoNIN: Robust Neural Inertial Navigation in the Wild: Benchmark, Evaluations, and New Methods Authors Hang Yan, Sachini Herath, Yasutaka Furukawa 本文为数据驱动的惯性导航研究奠定了新的基础,其任务是从一系列IMU传感器测量中估计移动主体的位置和方向。更具体地说,本文提出了一个新的基准,其包含来自100个人类受试者的超过40小时的IMU传感器数据,其具有在自然人体运动下的地面真实3D轨迹2个新颖的神经惯性导航架构,对具有挑战性的运动案例和3个定性和三种惯性导航基准的竞争方法的定量评估。我们将分享代码和数据,以促进进一步的研究。 |
| Towards Photo-Realistic Visible Watermark Removal with Conditional Generative Adversarial Networks Authors Xiang Li, Chan Lu, Danni Cheng, Wei Hong Li, Mei Cao, Bo Liu, Jiechao Ma, Wei Shi Zheng 可见水印在图像版权保护中起着重要作用,并且可见水印对攻击的鲁棒性是必不可少的。为了评估和提高水印的有效性,水印去除吸引了越来越多的关注,成为一个热门的研究热点。当前的方法将水印去除作为图像转换到图像转换问题,其中采用具有像素方式损失的编码解码体系结构来将透明水印像素转移到未标记的像素中。然而,当呈现多个逼真图像时,水印更可能是未知的和多样的,即,水印可能是不透明的或半透明的,水印的类别和图案是未知的。当将现有方法应用于现实世界场景时,它们大多不能令人满意地重建在复杂和各种水印下模糊的隐藏信息,即残留的水印痕迹保留并且重建的图像缺乏现实。为了解决这个难题,在本文中,我们提出了一个新的水印处理框架,使用条件生成对抗网络cGANs在现实世界的应用程序中去除可见水印。所提出的方法使得水印去除解决方案能够使用基于水印图像的基于补片的鉴别器更加接近于照片真实重建,其经过对数训练以区分恢复图像和原始无水印图像之间的差异。在大规模可见水印数据集上的广泛实验结果证明了所提方法的有效性,并清楚地表明,与现有技术方法相比,我们提出的方法可以产生更多的照片真实和令人信服的结果。 |
| Unsupervised Classification of Street Architectures Based on InfoGAN Authors Ning Wang, Xianhan Zeng, Renjie Xie, Zefei Gao, Yi Zheng, Ziran Liao, Junyan Yang, Qiao Wang 街道建筑在城市形象和街景分析中发挥着重要作用。然而,现有方法都受到监督,这需要昂贵的标记数据。为了解决这个问题,我们提出了一种基于信息最大化生成对抗网InfoGAN的街道建筑无监督分类框架,其中我们利用InfoGAN的辅助分布Q作为无监督分类器。中国南京真实街景图像数据库的实验验证了我们框架的实用性和准确性。此外,我们从隐藏在真实图像中的内在信息中得出一系列启发式结论。这些结论将有助于规划人员更好地了解建筑类别。 |
| The General Pair-based Weighting Loss for Deep Metric Learning Authors Haijun Liu, Jian Cheng, Wen Wang, Yanzhou Su 深度量度学习旨在通过深度神经网络学习样本对之间的距离度量,以提取类似样本彼此接近的语义特征嵌入,而不同样本相距更远。基于对距离的大量损失函数已经在文献中提出,用于指导深度量学习的训练。在本文中,我们将它们统一在基于通用对的加权损失函数中,其中最小化目标损失仅仅是信息对的距离加权。基于通用对的加权损失包括两个主要方面,1个样本挖掘和2个加权。样本挖掘旨在选择信息丰富的正对和负对集合,以利用小批量中的样本的结构化关系,并且还减少非平凡对的数量。对加权旨在根据对距离为不同对分配不同的权重,以便有区别地训练网络。我们详细回顾了那些与现有损失函数一致的现有配对损失,并从样本挖掘和配对权重的角度探讨了一些可能的方法。最后,对三个图像检索数据集的大量实验表明,我们基于通用对的加权损失获得了新的最新技术性能,证明了基于对的样本挖掘和对加权的有效性,可用于深度量学习。 |
| Attention: A Big Surprise for Cross-Domain Person Re-Identification Authors Haijun Liu, Jian Cheng, Shiguang Wang, Wen Wang 在本文中,我们关注模型泛化和适应跨域人员识别Re ID。与现有的跨域Re ID方法不同,利用那些未标记的目标域数据的辅助信息,我们的目标是通过判别性特征学习增强模型泛化和适应,并直接利用预先训练的模型到新的域数据集,而不使用任何信息来自目标域。为了解决辨别特征学习问题,我们惊奇地发现简单地引入注意机制来自适应地提取每个域的人物特征是非常有效的。我们采用两种流行的注意机制,基于长程依赖的注意和基于直接生成的注意。它们都可以通过空间或通道尺寸单独进行关注,甚至是空间和通道尺寸的组合。不同注意的轮廓很好地说明了。此外,我们还通过跳过连接将注意结果合并到模型的最终输出中,以改善具有高级和中级语义视觉信息的特征。通过直接利用预训练模型到新域的方式,注意结合方法真正可以增强模型推广和适应以执行跨域人Re ID。我们在三个大型数据集之间进行了大量实验,市场1501,DukeMTMC reID和MSMT17。令人惊讶的是,仅引入注意力可以实现最先进的性能,甚至比利用来自目标域的辅助信息的那些跨域Re ID方法更好。 |
| Deep Learning Approach for Receipt Recognition Authors Anh Duc Le, Dung Van Pham, Tuan Anh Nguyen 受近期计算机视觉和自然语言处理深度学习的成功启发,我们提出了一种识别扫描收据的深度学习方法。识别系统具有基于连接主义文本提议网络的两个主要模块文本检测和基于基于注意的编码器解码器的文本识别。我们还提出了预处理来提取收据区域和OCR验证以忽略手写。关于扫描收据OCR和信息提取的稳健阅读挑战数据集的实验2019表明,通过整合预处理和OCR验证,提高了准确度。我们的识别系统在检测和识别任务中获得了71.9的F1分数。 |
| The Fashion IQ Dataset: Retrieving Images by Combining Side Information and Relative Natural Language Feedback Authors Xiaoxiao Guo, Hui Wu, Yupeng Gao, Steven Rennie, Rogerio Feris 我们为基于自然语言的时尚图像检索贡献了一个新的数据集和一种新方法。与以前的时尚数据集不同,我们提供自然语言注释,以促进交互式图像检索系统的培训,以及常用的基于属性的标签。我们提出了一种新颖的方法,并且凭经验证明,将自然语言反馈与视觉属性信息相结合,可以产生相对于使用这些模态中的任何一种的卓越的用户反馈建模和检索性能。我们相信,我们的数据集可以鼓励进一步开发更多自然和现实世界适用的会话购物助理。 |
| $d$-SNE: Domain Adaptation using Stochastic Neighborhood Embedding Authors Xiang Xu, Xiong Zhou, Ragav Venkatesan, Gurumurthy Swaminathan, Orchid Majumder 深度神经网络通常需要大量标记数据来训练他们的大量参数。如果没有适当的正规化,训练更大更深的网络是很困难的,特别是在使用小型数据集时。在横向上,收集注释良好的数据是昂贵,耗时且通常是不可行的。规范这些网络的一种流行方法是简单地使用来自备用代表性数据集的更多数据来训练网络。如果代表性数据集的统计数据与我们的目标不同,这可能会导致不利影响。这种困境是由于域名转移的问题。当使用来自代表域的特征提取器时,来自移位域的数据可能不会产生定制特征。在本文中,我们提出了一种新的域自适应SNE技术,巧妙地使用随机邻域嵌入技术和一种新的修改的Hausdorff距离。所提出的技术是可学习的端到端,因此非常适合训练神经网络。大量实验证明,d SNE优于现有技术水平,并且对于不同数据集中的变化具有鲁棒性,即使在单次和半监督学习设置中也是如此。 d SNE还展示了同时推广到多个域的能力。 |
| Distant Pedestrian Detection in the Wild using Single Shot Detector with Deep Convolutional Generative Adversarial Networks Authors Ranjith Dinakaran, Philip Easom, Li Zhang, Ahmed Bouridane, Richard Jiang, Eran Edirisinghe 在这项工作中,我们研究了采用单击检测器SSD作为数据处理技术应用深度卷积生成对抗网络DCGAN的可行性,以应对野外行人检测的挑战。具体而言,我们尝试在填充完成中使用,其中图像的一部分被遮蔽以生成图像的随机变换,其中部分缺失以扩展现有的标记数据集。在我们的工作中,GAN已经在低分辨率图像上进行了大量训练,以便消除野外行人探测的挑战,并考虑人类,以及智能城市中几乎没有其他类别的探测。通过训练GAN模型和SSD执行的物体检测器实验提供了结果的实质性改进。该方法在用于对象检测的GAN网络的当前现状中提供了非常有趣的概述。我们使用加拿大高级研究院CIFAR,Caltech,KITTI数据集来训练和测试不同分辨率下的网络,实验结果与DCGAN级联SSD和SSD本身进行了比较。 |
| Extending Monocular Visual Odometry to Stereo Camera System by Scale Optimization Authors Jiawei Mo, Junaed Sattar 本文提出了一种将单目视觉测距技术扩展到立体摄像系统的新方法。所提出的方法使用额外的相机来准确地估计和优化单眼视觉测距的尺度,而不是从立体匹配中对3D点进行三角测量。具体地,由单目视觉测距法生成的3D点被投影到立体对的另一个相机上,并且通过直接最小化光度误差来恢复和优化比例。特别地,与直接立体匹配相比,它在计算上是有效的,为立体视觉系统增加了最小的开销,并且对于重复纹理是鲁棒的。此外,直接比例优化使立体视觉测距几乎完全基于直接方法。对公共数据集(例如KITTI)以及地面和水下的室外环境进行广泛评估,证明了通过尺度优化扩展的立体视觉测距方法的准确性和效率,以及具有挑战性纹理的环境中的稳健性。 |
| Dynamic Traffic Scene Classification with Space-Time Coherence Authors Athma Narayanan, Isht Dwivedi, Behzad Dariush 本文研究了在移动车辆上捕获的视频产生的视点下的空间时间变化下的动态交通场景分类问题。该问题的解决方案对于实现解释或预测道路使用者行为所需的有效驾驶辅助技术是重要的。目前,由于缺乏考虑由车辆自我运动引起的交通场景的时空演变的基准数据集,动态交通场景分类尚未得到充分解决。本文有三个主要贡献。首先,发布带注释的数据集以实现动态场景分类,其包括在旧金山湾区域收集的80小时的各种高质量驾驶视频数据剪辑。数据集包括道路位置,道路类型,天气和路面状况的时间注释。其次,我们介绍了利用数据集的语义上下文和时间特性进行道路场景动态分类的新颖和基线算法。最后,我们展示了算法和实验结果,突出了场景分类中提取的特征如何作为强大的先验,并有助于战术驾驶员行为理解。结果显示,文献中先前报道的驾驶行为检测基线有显着改善。 |
| A survey of Object Classification and Detection based on 2D/3D data Authors Xiaoke Shen 最近,通过使用基于深度神经网络的算法,对象分类,检测和语义分割解决方案得到显着改善。然而,基于2D图像的系统的一个挑战是它们不能提供准确的3D位置信息。这对于位置敏感的应用程序(如自动驾驶和机器人导航)至关重要。另一方面,诸如RGB D和基于RGB LiDAR的系统之类的3D方法可以提供显着改善仅RGB方法的解决方案。这就是为什么这对工业界和学术界来说都是一个有趣的研究领域。与基于2D图像的系统相比,基于3D的系统由于以下五个原因而更复杂1数据表示本身更复杂。 3D图像可以用点云,网格,体积来表示。 2D图像具有像素网格表示。 2添加额外维度时,计算和内存资源要求更高。 3不同的物体分布和室内外场景区域的差异使得一个统一的框架难以实现。与密集的2D图像相比,特别是对于室外场景而言,3D数据是稀疏的,这使得检测任务更具挑战性。最后,与精心构建的2D数据集(如ImageNet)相比,大尺寸标记数据集(对于基于监督的算法非常重要)仍在构建中。基于上面列出的挑战,所描述的系统由应用场景,数据表示方法和所解决的主要任务组织。同时,还引入了对3D影响很大的基于2D的关键系统,以显示它们之间的联系。 |
| What Makes Training Multi-Modal Networks Hard? Authors Weiyao Wang, Du Tran, Matt Feiszli 在具有多个输入模态的任务上考虑多模态与单模态网络的端到端训练,多模态网络接收更多信息,因此它应匹配或优于其单个模态对应物。然而,在我们的实验中,我们观察到相反的最佳单模态网络总是优于多模态网络。这种观察在不同的模态组合和不同的任务和基准上是一致的。 |
| Entropic Regularisation of Robust Optimal Transport Authors Rozenn Dahyot, Hana Alghamdi, Mairead Grogan Grogan等人11,12最近通过最小化捕获两个图像调色板和目标的颜色分布的两个概率密度函数之间的欧几里德距离L2来提出颜色转移的解决方案。它被证明对基于最佳传输的颜色转移的替代解决方案非常有竞争力。我们表明事实上Grogan等人的公式也可以被理解为一种新的稳健的基于最优运输的框架,其边缘上的熵正则化。 |
| Emergence of Object Segmentation in Perturbed Generative Models Authors Adam Bielski, Paolo Favaro 我们引入了一个新颖的框架来构建一个模型,该模型可以学习如何在没有任何人类注释的情况下从一组图像中分割对象。我们的方法建立在观察到对象段的位置可以相对于给定背景局部扰动而不影响场景的真实性的基础上。我们的方法是首先训练分层场景的生成模型。分层表示由背景图像,前景图像和前景的掩模组成。然后通过将掩蔽的前景图像叠加到背景上来获得合成图像。生成模型以对抗方式对抗鉴别器进行训练,这迫使生成模型产生逼真的合成图像。为了强制生成器学习前景层对应于对象的表示,我们通过引入前景图像和掩模相对于背景的随机移位来扰乱生成模型的输出。因为生成器在计算其输出之前不知道移位,所以它必须产生对于任何这样的随机扰动都是现实的分层表示。最后,我们学习通过定义一个自动编码器来分割图像,该自动编码器由我们训练的编码器和预先训练好的生成器组成,我们将其冻结。编码器将图像映射到特征向量,该特征向量作为输入馈送到生成器以给出与原始输入图像匹配的合成图像。因为生成器输出场景的显式分层表示,所以编码器学习检测和分割对象。我们在几个对象类别的真实图像上演示了这个框架。 |
| Video from Stills: Lensless Imaging with Rolling Shutter Authors Nick Antipa, Patrick Oare, Emrah Bostan, Ren Ng, Laura Waller 因为图像传感器芯片具有用于读出像素的有限带宽,所以记录视频通常需要在帧速率和像素计数之间进行折衷。压缩感测技术可以通过假设图像是可压缩的来避免这种折衷。在这里,我们建议使用多路复用光学器件对场景进行空间压缩,从一行传感器像素中采集有关整个场景的信息,这些信息可以通过滚动快门CMOS传感器快速读取。方便地,这种多路复用可以通过简单的无透镜,基于漫射器的成像系统来实现。使用稀疏恢复方法,我们能够以每秒超过4,500帧的速度恢复140个视频帧,所有这些都来自使用滚动快门传感器的单个捕获图像。我们的概念验证系统使用易于制造的扩散器与现成的传感器配对。所得到的原型使得高帧率视频的压缩编码成为单个滚动快门曝光,并且超过了对于足够稀疏的对象的等效全局快门系统的采样限制性能。 |
| Image classification using quantum inference on the D-Wave 2X Authors Nga T.T. Nguyen, Garrett T. Kenyon 我们使用量子退火D Wave 2X计算机来获得NP硬稀疏编码问题的解决方案。为了减少稀疏编码问题的维数以适应量子D Wave 2X硬件,我们通过瓶颈自动编码器传递下采样的MNIST图像。为了在这个简化的维度数据集上建立分类性能的基准,我们使用了在TensorFlow中实现的类似AlexNet的架构,获得了94.54 pm的分类得分0.7。作为对照,我们展示了相同的AlexNet类似架构在原始MNIST图像上产生了接近现有技术的分类性能sim 99。为了获得用于推断缩小尺寸MNIST数据集的稀疏表示的一组优化特征,我们在随机的47个图像块上打印,随后是使用随机梯度下降的离线无监督学习算法以优化稀疏编码。我们的单层稀疏编码与AlexNet的第一个卷积层(如深度神经网络)的步幅和补丁大小相匹配,包含47个完全连接的特征,47个是可嵌入D Wave 2 X硬件的字典元素的最大数量。最近的工作表明,稀疏度的最佳水平对应于与推定的二阶相变相关联的折衷参数的临界值,该观察由D波能量状态的自由能分析支持。当由D Wave 2 X推断的稀疏表示传递给线性支持向量机时,我们获得了95.68的分类得分。因此,在这个问题上,我们发现单层量子推断能够胜过标准的深度神经网络架构。 |
| What Can Neural Networks Reason About? Authors Keyulu Xu, Jingling Li, Mozhi Zhang, Simon S. Du, Ken ichi Kawarabayashi, Stefanie Jegelka 神经网络已经成功地应用于解决推理任务,从学习简单的概念,如接近,到复杂的问题,其推理程序类似于算法。根据经验,并非所有网络结构都能同样适用于推理。例如,图形神经网络已经取得了令人印象深刻的实证结果,而结构较少的神经网络可能无法学会推理。从理论上讲,目前对推理任务与网络学习之间相互作用的理解有限。在本文中,我们通过研究其结构与相关推理过程的算法结构的一致性,开发了一个框架来表征神经网络可以很好地学习哪些任务。这表明图形神经网络可以学习动态编程,这是一种强大的算法策略,可以解决一大类推理问题,例如关系问题回答,排序,直观物理和最短路径。我们的观点还暗示了为复杂推理设计神经架构的策略。在几个抽象的推理任务中,我们从经验上看,我们的理论与实践很好地吻合。 |
| Graph Neural Tangent Kernel: Fusing Graph Neural Networks with Graph Kernels Authors Simon S. Du, Kangcheng Hou, Barnab s P czos, Ruslan Salakhutdinov, Ruosong Wang, Keyulu Xu 虽然图形内核GK很容易训练并且享受可证明的理论保证,但它们的实际性能受到其表达能力的限制,因为内核函数通常依赖于手工制作的图形组合特征。与图形内核相比,图形神经网络GNN通常可以获得更好的实际性能,因为GNN使用多层体系结构和非线性激活函数来提取图形的高阶信息作为特征。然而,由于大量的超参数和训练过程的非凸性,GNN更难训练。 GNN的理论保证也不是很清楚。此外,GNN的表达能力随着参数的数量而扩展,因此当计算资源有限时很难利用GNN的全部功能。本文提出了一类新的图形核,即图形神经切线核GNTK,它们对应于通过梯度下降训练的无限宽多层GNN。 GNTK享有GNN的全部表达能力,并继承了GK的优势。从理论上讲,我们展示GNTK可以在图上学习一类平滑函数。根据经验,我们在图分类数据集上测试GNTK并显示它们实现了强大的性能。 |
| Grounding Language Attributes to Objects using Bayesian Eigenobjects Authors Vanya Cohen, Benjamin Burchfiel, Thao Nguyen, Nakul Gopalan, Stefanie Tellex, George Konidaris 我们开发了一个基于简单物理描述消除对象歧义的系统。该系统将自然语言短语和包含分割对象的深度图像作为输入,并预测观察对象与所描述的对象的相似程度。我们的系统旨在仅从少量人类标记的语言数据中学习,并推广到未在语言注释深度图像训练集中表示的视点。通过将3D形状表示与语言表示分离,我们的方法能够使用少量语言注释深度数据和更大的未标记3D对象网格语料将语言与新对象接地,即使从不寻常的视点部分地观察这些对象也是如此。我们的系统能够消除基于自然语言描述的通过深度图像观察到的新物体之间的歧义。我们的方法还使得能够在从正面视点捕获的一小组深度图像上对人类注释数据进行训练的视点转移,尽管在其训练集中没有这样的深度图像,但是我们的系统成功地从后视图预测了对象属性。最后,我们在Baxter机器人上演示我们的系统,使其能够根据人类提供的自然语言描述选择特定对象。 |
| Generalized Separable Nonnegative Matrix Factorization Authors Junjun Pan, Nicolas Gillis 非负矩阵分解NMF是非负数据的线性维数技术,具有图像分析,文本挖掘,音频源分离和高光谱分离等应用。给定数据矩阵M和分解等级r,NMF寻找具有r列的非负矩阵W和具有r行的非负矩阵H,使得M近似WH。一般来说,NMF很难解决。然而,它可以在可分性假设下有效地计算,该可分性假设要求基矢量表现为数据点,即存在索引集算法K,使得W M,mathcal K.在本文中,我们概括了可分性假设我们只要求对于每个等级一个因子W,k H k,对于k 1,2,点,r,W,k M,j对于某些j或H k,M i ,对某些人来说。我们将相应的问题称为广义可分NMF GS NMF。我们讨论了GS NMF的一些性质,并提出了一种我们用快速梯度法求解的凸优化模型。我们还提出了一种受连续投影算法启发的启发式算法。为了验证我们的方法的有效性,我们将它们与合成,文档和图像数据集上的几种最先进的可分离NMF算法进行比较。 |
| Wasserstein Style Transfer Authors Youssef Mroueh 我们在编码器解码器框架中为图像样式传输提出高斯最优传输。高斯测量的最佳传输已经封闭形式从源到目标分布的Monge映射。此外,内容和风格图像之间的插值可以被视为Wasserstein几何中的测地线。利用这种洞察力,我们展示了如何使用高斯测量的Wasserstein重心来混合不同的目标样式。由于高斯人在Wasserstein重心下关闭,这使我们可以进行简单的风格转换和风格混合和插值。此外,我们展示了如何使用高斯之间的其他测地指标(例如Fisher Rao度量)来实现不同样式的混合,而内容到新插值样式的传输仍然使用高斯OT图执行。我们简单的方法允许生成在许多艺术风格之间插入的新风格化内容。插值中使用的度量导致不同的样式。 |
| Exploiting Epistemic Uncertainty of Anatomy Segmentation for Anomaly Detection in Retinal OCT Authors Philipp Seeb ck, Jos Ignacio Orlando, Thomas Schlegl, Sebastian M. Waldstein, Hrvoje Bogunovi , Sophie Klimscha, Georg Langs, Ursula Schmidt Erfurth 通过检测医学图像中的相关生物标志物来辅助诊断和治疗指导。尽管有监督的深度学习可以对病理区域进行准确的分割,但是通过要求对这些区域的先验定义,大规模注释以及训练集中的代表性患者群组进行限制。相反,异常检测不限于病理学的特定定义,并且允许在没有注释的情况下对健康样品进行训练。然后,异常区域可以作为生物标记物发现的候选者。关于正常解剖结构的知识带来了用于检测异常的隐含信息。我们建议利用贝叶斯深度学习来利用这个属性,这是基于认知不确定性将与正常训练集的解剖学偏差相关联的假设。贝叶斯U网使用现有方法生成的健康解剖学的弱标签,在明确定义的健康环境中进行训练。在测试时,我们使用蒙特卡洛辍学捕获我们模型的认知不确定性估计。然后应用一种新颖的后处理技术来利用这些估计并将它们的分层外观转移到异常的平滑斑点形分割。我们使用视网膜层的弱标签在视网膜光学相干断层扫描OCT图像中实验验证了这种方法。我们的方法在年龄相关性黄斑变性AMD病例的独立异常测试集中达到了0.789的Dice指数。由此产生的分割允许非常高的准确度,用于分离晚期湿性AMD,干性地理性萎缩GA,糖尿病性黄斑水肿DME和视网膜静脉阻塞RVO的健康和患病病例。最后,我们定性地观察到我们的方法还可以检测正常扫描中的其他偏差,例如切边伪影。 |
| Bandlimiting Neural Networks Against Adversarial Attacks Authors Yuping Lin, Kasra Ahmadi K. A., Hui Jiang 在本文中,我们从傅里叶分析的角度研究深度学习中的对抗性攻击和防御问题。我们首先明确地计算了深ReLU神经网络的傅立叶变换,并且表明在神经网络的傅里叶谱中存在衰减但非零的高频分量。我们证明神经网络对对抗性样本的脆弱性可归因于这些无关紧要但非零的高频成分。基于此分析,我们建议使用简单的后平均技术来平滑这些高频分量,以提高神经网络抵御对抗性攻击的鲁棒性。 ImageNet数据集的实验结果表明,我们提出的方法在保护文献中提出的许多现有对抗攻击方法方面具有普遍的效果,包括FGSM,PGD,DeepFool和C W攻击。我们的后平均方法很简单,因为它不需要任何重新训练,同时它可以成功地保护这些方法生成的95个以上的对抗样本,而不会在原始干净图像上引入小于1的任何显着性能下降。 |
| Batch weight for domain adaptation with mass shift Authors Miko aj Bi kowski, R Devon Hjelm, Aaron Courville 无监督域转移是将样本从源分发转移或转换到不同目标分布的任务。当前解决方案无监督域转移通常对分布模式很好匹配的数据进行操作,例如在源分布和目标分布之间具有相同的类别频率。然而,当模式不能很好地匹配时,这些模型表现不佳,例如当样本独立于两个不同但相关的域绘制时。这种模式不平衡是有问题的,因为生成对抗性网络GAN(在该设置中的成功方法)对模式频率敏感,这导致源样本与生成的目标分布样本之间的语义不匹配。我们提出了一种重新加权训练样本的原则方法,以校正转移分布之间的这种质量转移,我们称之为批量权重。我们还为域转移和训练传输网络的新简化目标提供严格的概率设置,这是在当前最先进的图像到图像转换模型中使用的复杂的多分量损失函数的替代方案。新目标源于对联合分布的区分,并以抽象的,高级的而非像素的方式强制执行循环一致性。最后,我们通过实验证明了所提出的方法在几个图像到图像转换任务中的有效性。 |
| Zeroth-Order Stochastic Alternating Direction Method of Multipliers for Nonconvex Nonsmooth Optimization Authors Feihu Huang, Shangqian Gao, Songcan Chen, Heng Huang 乘法器的交替方向方法ADMM是一种流行的优化工具,用于机器学习中的复合和约束问题。然而,在许多机器学习问题中,例如黑盒攻击和强盗反馈,ADMM可能会失败,因为这些问题的显式梯度难以获得或不可行。零阶梯度自由方法可以有效地解决这些问题,因为目标函数值仅在优化中需要。最近,虽然存在一些零阶ADMM方法,但它们建立在目标函数的凸性上。显然,这些现有的零阶方法在许多应用中受到限制。因此,在本文中,我们提出了一类快速零阶随机ADMM方法,即ZO SVRG ADMM和ZO SAGA ADMM,用于基于坐标平滑梯度估计来解决具有多个非光滑罚分的非凸问题。此外,我们证明了ZO SVRG ADMM和ZO SAGA ADMM都具有O 1 T的收敛速度,其中T表示迭代次数。特别是,我们的方法不仅达到非凸优化的最佳收敛速度O 1 T,而且能够有效地解决许多复杂的机器学习问题,具有多个正则化的惩罚和约束。最后,我们对黑盒深度神经网络进行了黑盒二进制分类和结构化对抗攻击实验,验证了算法的有效性。 |
| A Quaternion-based Certifiably Optimal Solution to the Wahba Problem with Outliers Authors Heng Yang, Luca Carlone Wahba问题,也称为旋转搜索,旨在找到最佳旋转以对齐两组矢量观测给定推定的对应关系,并且是许多计算机视觉和机器人应用中的基本例程。当大量矢量观测是异常值时,这项工作提出了第一个多项式时间可证明最优的方法来解决Wahba问题。我们的第一个贡献是使用截断最小二乘TLS成本来制定Wahba问题,该成本对大部分虚假对应不敏感。第二个贡献是使用单位四元数重写问题,并显示TLS成本可以被构建为二次约束二次规划QCQP。由于最终的优化仍然是高度非凸的并且难以全局求解,我们的第三个贡献是开发凸半定规划SDP松弛。我们表明,虽然天真的放松一般表现不佳,但即使存在大噪音和异常值,我们的放松也很紧张。我们在合成和真实数据集中验证了所提出的算法,名为QUASAR QUAternion的Semidefinite relAxation for Robust alignment,表明该算法优于RANSAC,强大的局部优化技术和全局异常值去除方法。 QUASAR能够计算可认证的最佳解决方案,即即使在95个对应关系是异常值的情况下,放松也是准确的。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号