

【今日CV 计算机视觉论文速览 第126期】Thu, 6 Jun 2019
今日CS.CV 计算机视觉论文速览
Thu, 6 Jun 2019
Totally 38 papers
👉上期速览✈更多精彩请移步主页

Daily Computer Vision Papers
| Single-Camera Basketball Tracker through Pose and Semantic Feature Fusion Authors Adri Arbu s Sang esa, Coloma Ballester, Gloria Haro 跟踪体育运动员是一个极具挑战性的场景,特别是在紧凑的法院录制的单一馈送视频中,无法避免混乱和遮挡。本文分析了几种几何和语义的视觉特征,以检测和跟踪篮球运动员。进行消融研究,然后用于评论可以使用深度学习功能构建健壮的跟踪器,而无需提取上下文跟踪器,例如接近度或颜色相似性,也不应用相机稳定技术。所呈现的跟踪器包括1个检测步骤,其使用预训练深度学习模型来估计玩家姿势,接着是跟踪步骤2,其利用来自VGG网络中的卷积层的输出的姿势和语义信息。它的表现是根据MOTA对篮球数据集进行分析,该数据集的实例超过10k。 |
| A GLCM Embedded CNN Strategy for Computer-aided Diagnosis in Intracerebral Hemorrhage Authors Yifan Hu, Yefeng Zheng 计算机辅助诊断CADx系统已被证明可以通过提供各种医学图像的分类来协助放射科医师,如计算机断层扫描CT和磁共振MR。目前,卷积神经网络在CADx中发挥着重要作用。然而,由于CNN模型应该具有像输入一样的方形,通常很难将CNN算法直接应用于放射科医师感兴趣的感兴趣ROI的不规则分割区域。在本文中,我们提出了一种新的方法来构建模型。通过提取不规则区域的信息并将其转换为固定大小的灰度级共生矩阵GLCM,然后将GLCM用作CNN模型的一个输入。以这种方式,作为原始CNN的有用实现,CNN还提取了一些基于GLCM的特征。同时,网络将更加关注重要病变区域,实现更高的分类准确性。在三个分类数据库Hemorrhage,BraTS18和Cervix上进行实验,以验证我们的创新模型的普遍性。总之,所提出的框架优于每个数据库的相应的现有算法,其中测试损失和分类准确性作为评估标准。 |
| Multi-way Encoding for Robustness Authors Donghyun Kim, Sarah Adel Bargal, Jianming Zhang, Stan Sclaroff 深度模型是许多计算机视觉任务的最新技术,包括图像分类和对象检测。但是,已经证明深层模型容易受到对抗性的影响。我们重点介绍一个热门编码如何直接导致此漏洞,并建议摆脱这种广泛使用但非常容易受到影响的映射。我们通过利用不同的输出编码,多路编码,证明了源模型和目标模型的相关性,使目标模型更加安全。我们的方法使对手更难以找到用于生成目标模型的对抗性攻击的有用渐变。我们提出了对四个基准数据集的黑盒子和白盒攻击的鲁棒性。我们的方法的强度也通过对来自源模型的目标模型去相关来以模型水印的攻击的形式呈现。 |
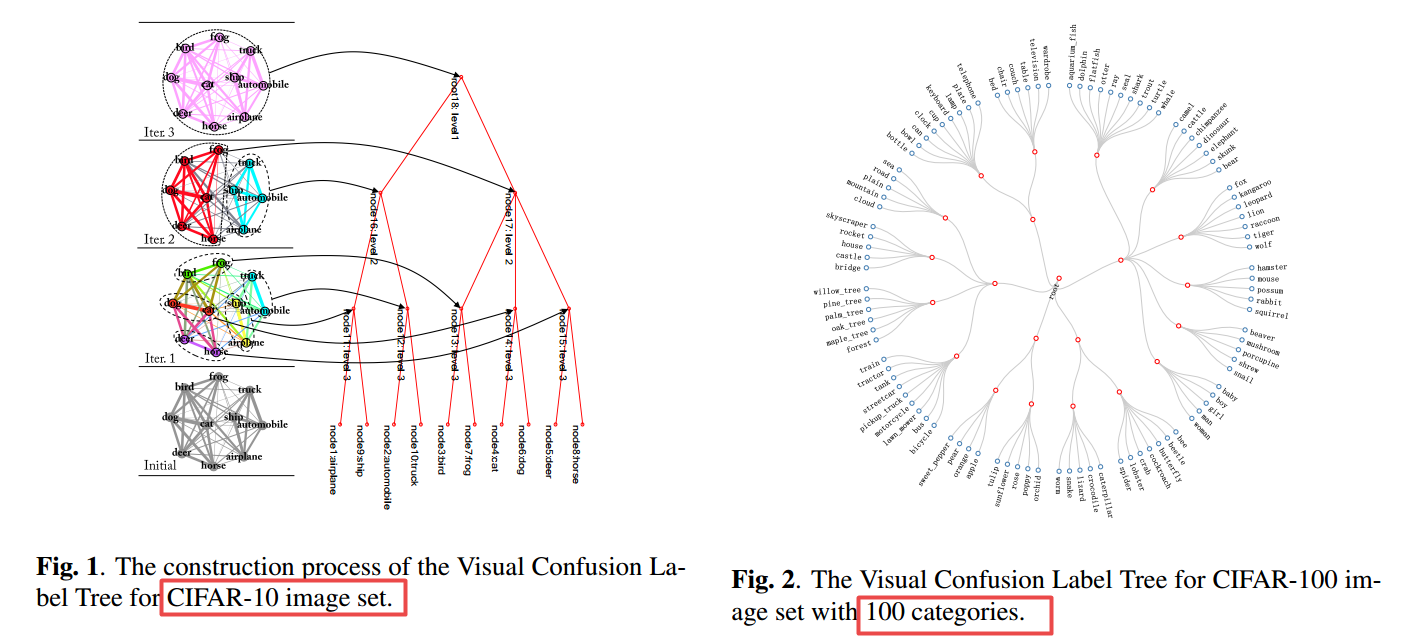
| Visual Confusion Label Tree For Image Classification Authors Yuntao Liu, Yong Dou, Ruochun Jin, Rongchun Li 卷积神经网络模型广泛用于图像分类任务。然而,这种模型的运行时间太长,以至于不符合移动设备的严格实时要求。为了优化模型并满足上述要求,我们提出了一种用树分类器替换卷积神经网络模型的完全连接层的方法。具体来说,我们基于卷积神经网络模型的输出构造视觉混淆标签树,并使用具有分层约束的多核SVM加分类器来训练树分类器。专注于那些混淆子集而不是整个类别集使得树分类器更具辨别力并且完全连接的层的替换减少了原始运行时间。实验表明,我们的树分类器在CIFAR 100和ImageNet数据集的前1个精度方面分别比4.3和2.4获得了对现有树分类器的显着改进。此外,与AlexNet和VGG16上的完全连接层相比,我们的方法可实现124x和115x的加速比,而不会降低精度。 |
| Improving Variational Autoencoder with Deep Feature Consistent and Generative Adversarial Training Authors Xianxu Hou, Ke Sun, Linlin Shen, Guoping Qiu 我们提出了一种改进变分自动编码器VAE性能的新方法。除了强制执行深度特征一致原则从而确保VAE输出及其相应的输入图像具有相似的深度特征外,我们还实施了生成对抗训练机制,以迫使VAE输出逼真和自然的图像。我们提出实验结果表明,使用我们的新方法训练的VAE在生成具有更清晰和更自然的鼻子,眼睛,牙齿,头发纹理以及合理背景的脸部图像方面优于现有技术水平。我们还表明,我们的方法可以学习输入面部图像的强大嵌入,可用于实现面部属性操作。此外,我们提出了一种多视图特征提取策略来提取有效的图像表示,其可用于实现面部属性预测中的现有技术性能。 |
| Efficient Codebook and Factorization for Second Order Representation Learning Authors Pierre Jacob, David Picard, Aymeric Histace, Edouard Klein 学习丰富而紧凑的表示是许多领域中的一个开放主题,例如对象识别或图像检索。深度神经网络在过去几年中已经为这些任务取得了重大突破,但它们的表示并不像需要的那样丰富,也不像预期的那样紧凑。为了构建更丰富的表示,高阶统计数据已经被利用并且表现出优异的性能,但它们产生更高维度的特征。尽管已经通过分解方案部分地解决了这个缺点,但是从未检索到一阶模型的原始紧凑性,或者以强大的性能降低为代价。我们的方法通过将码本策略与分解方案联合集成,能够产生紧凑的表示,同时保持具有很少附加参数的二阶性能。该公式导致三个图像检索数据集的现有技术结果。 |
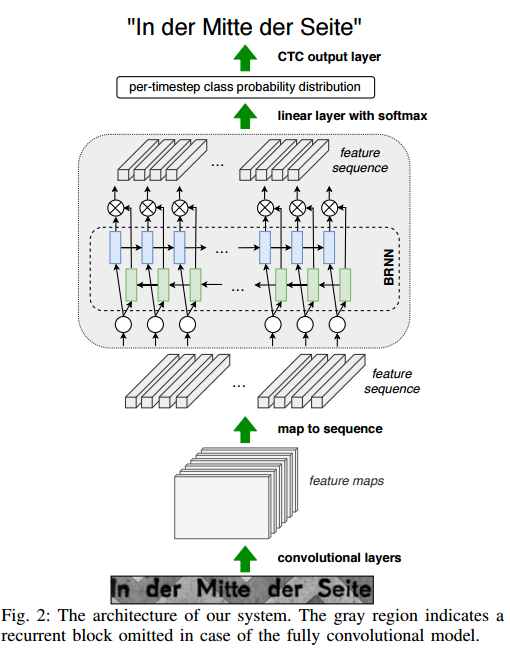
| Efficient, Lexicon-Free OCR using Deep Learning Authors Marcin Namysl, Iuliu Konya 与流行的看法相反,光学字符识别OCR仍然是一个具有挑战性的问题,当文本出现在无限制的环境中,如自然场景,由于几何扭曲,复杂的背景和各种字体。在本文中,我们提出了一个无分段的OCR系统,它结合了深度学习方法,综合训练数据生成和数据增强技术。我们使用大型文本语料库和超过2000种字体来渲染合成训练数据。为了模拟复杂自然场景中出现的文本,我们使用几何失真来增强提取的样本,并使用建议的数据增强技术alpha合成背景纹理。我们的模型采用卷积神经网络编码器从文本图像中提取特征。受神经机器翻译和语言建模的最新进展的启发,我们研究了递归和卷积神经网络在对输入元素之间的相互作用进行建模时的能力。 |
| Grounded Human-Object Interaction Hotspots from Video (Extended Abstract) Authors Tushar Nagarajan, Christoph Feichtenhofer, Kristen Grauman 学习如何与物体交互是实现具体视觉智能的重要一步,但现有技术受到严格的监督或传感要求。我们提出了一种直接从视频中学习人体对象交互热点的方法。我们的方法不是将能力资源视为手动监督的语义分割任务,而是通过观看真实人类行为的视频和预测所提供的行为来学习交互。给定一个新颖的图像或视频,我们的模型推断出一个空间热点地图,指示如何在潜在的交互中操纵对象,即使该对象当前处于静止状态。通过第一人称视频和第三人称视频的结果,我们展示了真实人类对象交互中的接地能力值。我们的弱监督热点不仅与强监督的可供性方法竞争,而且还可以预测新对象类别的对象交互。项目页面 |
| Consistency regularization and CutMix for semi-supervised semantic segmentation Authors Geoff French, Timo Aila, Samuli Laine, Michal Mackiewicz, Graham Finlayson 一致性正则化描述了一类在半监督分类问题中产生突破性结果的方法。先前的工作已经建立了群集假设,在该假设下,数据分布由由低密度区域分隔的均匀类别的样本群组成,这是其成功的关键。我们分析了语义分割的问题,发现数据分布没有表现出分离类的低密度区域,并且提供了这个解释为什么半监督分割是一个具有挑战性的问题。我们将最近提出的CutMix正则化器用于语义分割,并发现它能够克服这一障碍,从而将一致性正则化成功应用于半监督语义分段。 |
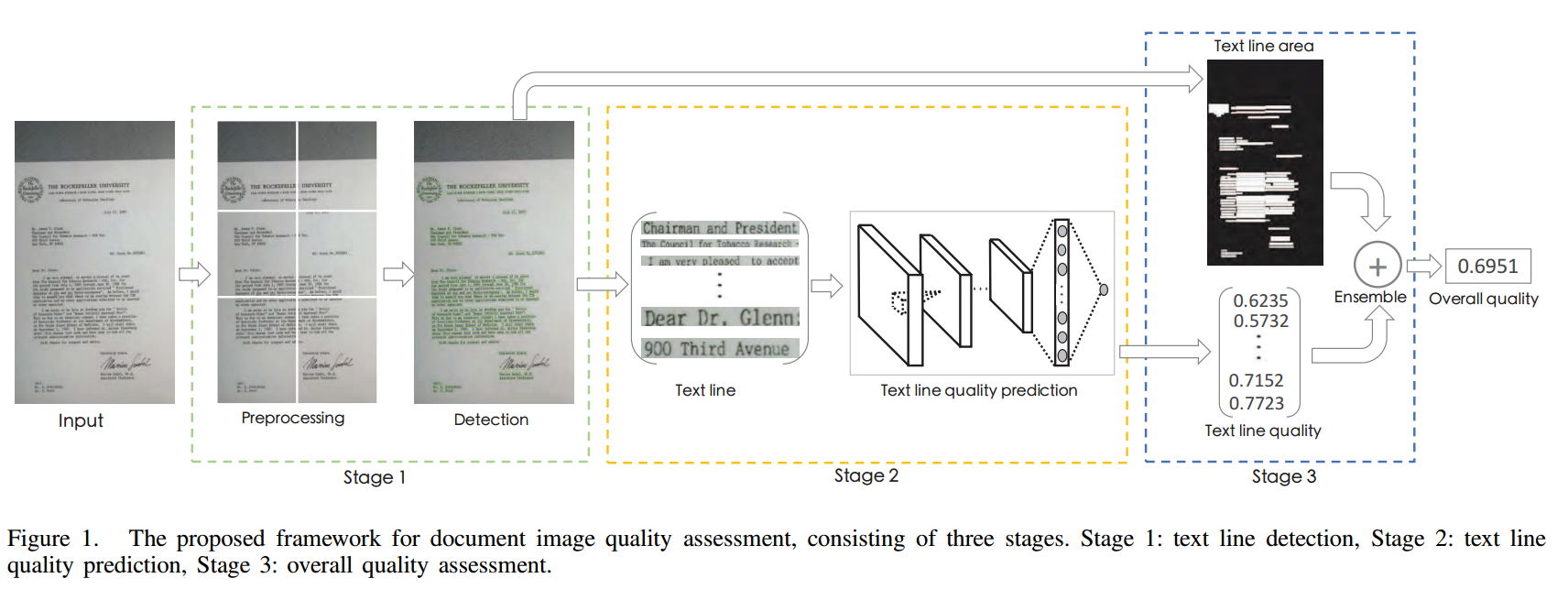
| Towards Document Image Quality Assessment: A Text Line Based Framework and A Synthetic Text Line Image Dataset Authors Hongyu Li, Fan Zhu, Junhua Qiu 由于文档图像的低质量将极大地破坏自动文本识别和分析成功的机会,因此有必要评估在线业务流程中上传的文档图像的质量,以便拒绝那些低质量的图像。在本文中,我们尝试实现文档图像质量评估,我们的贡献是双重的。首先,由于文档图像质量评估对文本更感兴趣,我们提出了一种基于文本行的框架来估计文档图像质量,它由三个阶段的文本行检测,文本行质量预测和整体质量评估组成。文本行检测旨在使用检测器找到潜在的文本行。在文本行质量预测阶段,使用基于CNN的预测模型为每个文本行计算质量分数。最终使用所有文本行质量的集合来评估文档图像的整体质量。其次,为了训练预测模型,合成具有不同属性的包括52,094个文本行图像的大规模数据集。对于每个文本行图像,使用分段函数计算质量标签。为了证明所提出的框架的有效性,在两个流行的文档图像质量评估基准上评估了综合实验。我们的框架在大而复杂的数据集上大幅度地优于最先进的方法。 |
| Baby steps towards few-shot learning with multiple semantics Authors Eli Schwartz, Leonid Karlinsky, Rogerio Feris, Raja Giryes, Alex M. Bronstein 从一个或几个视觉示例中学习是人类从婴儿早期开始的关键能力之一,但仍然是现代AI系统的重大挑战。虽然从一些图像示例中很少有镜头学习取得了相当大的进展,但对于婴儿在呈现新物体时通常提供的口头描述却少得多。在本文中,我们关注额外语义的作用,这些语义可以显着促进少数镜头视觉学习。基于最近在少数镜头学习中使用附加语义信息的进展,我们证明使用更丰富的语义和多个语义源可以进一步改进。使用这些想法,我们为流行的miniImageNet基准测试的一次性测试提供了一个新的结果,与基于视觉和基于语义的方法的先前最先进的结果相比。我们还进行了消融研究,调查我们的方法的组件和设计选择。 |
| Corn leaf detection using Region based convolutional neural network Authors Mohammad Ibrahim Sarker, Heechan Yang, Hyongsuk Kim 机器学习领域已经成为一个日益萌芽的研究领域,因为在处理更复杂的图像检测挑战时需要更有效的方法。解决农业问题越来越重要,因为食物是生命的基础。然而,由于许多不同的杂草,近期玉米田系统的检测精度仍然远离实际需求。本文提出了一个模型来处理农田收集的数字图像中的玉米叶片检测问题。基于使用CNN采用的几种现有技术模型进行的实验结果,已经提出基于区域的方法作为更快和更准确的玉米叶检测方法。由于具有ResNet的这些独特属性,我们将其与基于区域的网络相结合,例如更快的rcnn,其能够在重杂草遮挡中自动检测玉米叶。该方法在来自场的数据集上进行评估,我们自己编写注释。我们提出的方法在玉米检测系统中实现了明显优异的性能。 |
| AI-Skin : Skin Disease Recognition based on Self-learning and Wide Data Collection through a Closed Loop Framework Authors Min Chen, Ping Zhou, Di Wu, Long Hu, Mohammad Mehedi Hassan, Atif Alamri 人体皮肤状况的改变存在很多隐患,例如长时间暴露于紫外线引起的晒伤,不仅会产生审美影响,导致心理抑郁和缺乏自信,甚至可能危及生命。由于皮肤癌变。目前的皮肤病研究采用自动分类系统来提高皮肤病分类的准确率。但是,对图像样本数据库的过度依赖无法为不同的人群提供个性化的诊断服务。为克服这一问题,本文提出了一种基于数据宽度演化和自学习的医学AI框架,以提供满足实时性,可扩展性和个性化要求的皮肤病医疗服务。首先,讨论了用户和远程医疗数据中心的闭环信息流中的广泛数据集。其次,给出了一种基于信息熵的数据集过滤算法,以减轻边缘节点的负荷,同时提高远程云分析模型的学习能力。此外,该框架提供了一个外部算法加载模块,可以根据所选模型与应用程序要求兼容。加载并比较了三种深度学习模型,即LeNet 5,AlexNet和VGG16,验证了算法加载模块的通用性。建立了实时,个性化,可扩展的皮肤病识别系统的实验平台。并分析了测试仪与远程数据中心交互场景下的系统计算和通信延迟。结果表明,我们提出的系统可靠,有效。 |
| Weakly Supervised Object Detection with 2D and 3D Regression Neural Networks Authors Florian Dubost, Hieab Adams, Pinar Yilmaz, Gerda Bortsova, Gijs van Tulder, M. Arfan Ikram, Wiro Niessen, Meike Vernooij, Marleen de Bruijne 弱监督检测方法可以在训练期间推断图像中目标对象的位置而不需要位置或外观信息。我们提出了一种弱监督深度学习方法,用于检测出现在图像中多个位置的对象。该方法使用编码器解码器网络的最后特征映射来计算关注图,该编码器解码器网络仅利用全局标签优化图像中目标对象的出现次数。与先前的方法相比,由于解码器部分,以全输入分辨率生成注意力图。将所提出的方法与基于MNIST的数据集中的数字检测的两个任务中的多种现有技术方法进行比较,并且在2202 3D的数据集中的四个脑区域中检测扩大的血管周围空间中的一种脑损伤的现实生活应用脑MRI扫描。在基于MNIST的数据集中,所提出的方法优于其他方法。在大脑数据集中,几种弱监督检测方法接近每个区域的人体内部协议。所提出的方法在操作点的所有脑区域中达到最低数量的假阳性检测,而其平均灵敏度与其他最佳方法的相似。 |
| Farm land weed detection with region-based deep convolutional neural networks Authors Mohammad Ibrahim Sarker, Hyongsuk Kim 机器学习已成为一个主要的研究领域,以处理越来越复杂的图像检测问题。在现有技术CNN模型中,基于实验结果,本文提出了一种基于区域的完全卷积网络,用于快速准确的物体检测。在基于区域的网络中,ResNet被认为是最新的CNN架构,它在2015年的ImageNet大规模视觉识别挑战ILSVRC中取得了最佳成果。深度残留网络ResNets可以使培训过程更快,并且与同等级别相比可以获得更高的准确性传统的神经网络。由于具有ResNet的这些独特属性,本文评估了微调ResNet对杂草数据集的对象分类的性能。农田杂草检测数据集不足以培养这种深度CNN模型。为了克服这个缺点,我们执行退出技术以及深度剩余网络,以减少过拟合问题,并应用所提出的ResNet进行数据增强,以从杂草数据集中获得显着的优异结果。我们使用基于区域的全卷积网络R FCN技术实现了更好的物体检测性能,该技术与我们提出的ResNet 101锁存。 |
| Invariant Tensor Feature Coding Authors Yusuke Mukuta, Tatsuya Harada 我们提出了一种利用不变性的新颖特征编码方法。我们考虑保留图像内容的变换构成一组有限正交矩阵的设置。在许多图像变换中就是这种情况,例如图像旋转和图像翻转。我们证明了当我们使用凸损失最小化学习线性分类器时,群不变特征向量包含足够的判别信息。从这个结果,我们提出了一个新的主成分分析特征建模,k意味着聚类,用于大多数特征编码方法,和全局特征函数,明确考虑组动作。虽然全局特征函数通常是复杂的非线性函数,但我们可以通过将函数构造为基本表示的张量积表示来容易地计算该空间上的群动作,从而产生不变特征函数的显式形式。我们在几个图像数据集上展示了我们的方法的有效性。 |
| Compact Approximation for Polynomial of Covariance Feature Authors Yusuke Mukuta, Tatsuaki Machida, Tatsuya Harada 协方差池是一种具有良好分类精度的特征池方法。因为协方差特征包括二阶统计量,所以特征元素的比例是变化的。因此,使用矩阵平方根来归一化协方差特征会影响性能改进。当池化方法应用于从CNN模型提取的局部特征时,当池化函数可反向传播并且以端到端方式学习特征提取模型时,准确性增加。最近,提出了协方差特征矩阵平方根的迭代多项式逼近方法,与基于奇异值分解的方法相比,训练得更快,更稳定。在本文中,我们提出了紧致双线性池的扩展,它是协方差特征的多项式的标准协方差特征的紧凑近似。随后,我们将所提出的近似应用于对应于矩阵平方根的多项式,以获得协方差特征的平方根的紧致近似。我们的方法通过基于局部特征的相似性对应于一对局部特征的近似特征的加权和来近似协方差的更高维多项式。我们将我们的方法应用于标准细粒度图像识别数据集,并证明所提出的方法显示出与原始特征相比更小的尺寸。 |
| Detecting Kissing Scenes in a Database of Hollywood Films Authors Amir Ziai 检测电影中的场景类型对于视频编辑,评级分配和个性化等应用非常有用。我们提出了一种用于检测电影中的接吻场景的系统。该系统由两部分组成。第一分量是二元分类器,其预测二进制标签,即接吻或不给出从一秒片段的静止帧和音频波两者中提取的特征。第二个组件将连续的非重叠段的二进制标签聚合成一组接吻场景。我们尝试了各种2D和3D卷积体系结构,如ResNet,DesnseNet和VGGish,并开发了一种高度精确的接吻检测器,可以在多种类型的好莱坞电影数据库中获得0.95的验证,这些数据包括多种类型和跨越数十年。该项目的代码可在以下网站获得 |
| A Feature Transfer Enabled Multi-Task Deep Learning Model on Medical Imaging Authors Fei Gao, Hyunsoo Yoon, Teresa Wu, Xianghua Chu 物体检测,分割和分类是医学图像分析中的三个常见任务。多任务深度学习MTL联合处理这三个任务,这提供了几个优点,节省了计算时间和资源,并提高了过度拟合的鲁棒性。但是,现有的多任务深度模型从每个任务开始作为单独的任务,并在架构的最后用一个成本函数集成并行执行的任务。这种架构无法在训练的早期阶段利用来自每个单独任务的特征的组合能力。在这项研究中,我们提出了一种新的架构FTMTLNet,一种通过特征传输实现的MTL。传统的转移学习处理来自不同数据源a.k.a.域的相同或类似任务。基本假设是从源域获得的知识可以帮助目标域上的学习任务。我们建议的FTMTLNet利用来自同一域的不同任务。考虑到任务的特征是域的不同视图,可以使用来自多个视图的知识来很好地利用组合的特征图以增强普遍性。为了评估所提方法的有效性,将FTMTLNet与来自文献的模型进行比较,包括8个分类模型,4个检测模型和3个分割模型,使用公共全视野数字乳房X线照片数据集进行乳腺癌诊断。实验结果表明,FTMTLNet在分类和检测方面优于竞争模型,在分割方面具有可比性。 |
| Infant Contact-less Non-Nutritive Sucking Pattern Quantification via Facial Gesture Analysis Authors Xiaofei Huang, Alaina Martens, Emily Zimmerman, Sarah Ostadabbas 非营养性吸吮NNS定义为当手指,奶嘴或其他物体放置在婴儿口中时发生的吸吮动作,但没有营养物质被输送。除了提供安全感之外,NNS甚至可以被视为婴儿中枢神经系统发育的指标。婴儿非营养性吮吸过程中的丰富数据,如吮吸频率,周期数和振幅,是判断婴儿或早产儿大脑发育的重要线索。如今,大多数研究人员通过使用压力传感器等接触设备来收集NNS数据。然而,这种侵入性接触将直接影响婴儿的自然吸吮行为,导致收集的数据显着失真。因此,我们提出了一种新颖的接触式NNS数据采集和量化方案,利用面部标志跟踪技术从记录的婴儿吸吮视频中提取婴儿颌骨的运动信号。由于完成吸吮动作需要大量的面部肌肉和颅神经的同步协调和神经整合,伴随婴儿吸吮奶嘴的面部肌肉运动信号可以间接地替换NNS信号。我们已经对从几个婴儿在NNS行为期间收集的视频评估了我们的方法,并且我们已经实现了与视觉检查以及基于接触的传感器读数的结果非常接近的量化的NNS模式。 |
| StarNet: Pedestrian Trajectory Prediction using Deep Neural Network in Star Topology Authors Yanliang Zhu, Deheng Qian, Dongchun Ren, Huaxia Xia 行人轨迹预测对于许多重要应用至关重要。由于行人之间复杂的相互作用,这个问题是一个巨大的挑战。以前的方法只模拟行人之间的成对相互作用,这不仅过分简化了行人之间的相互作用,而且计算效率也很低。在本文中,我们提出了一个新的模型StarNet来处理这些问题。 StarNet具有星型拓扑结构,包括独特的集线器网络和多个主机网络。中心网络采用观察到的所有行人的轨迹来产生人际交互的全面描述。然后,主机网络(每个主机网络对应于一个行人)查阅描述并预测未来的轨迹。星形拓扑结构为StarNet提供了优于传统型号的两大优势。首先,StarNet能够考虑集线器网络中所有行人的集体影响,从而做出更准确的预测。其次,StarNet在计算上是高效的,因为主机网络的数量与行人的数量成线性关系。对多个公共数据集的实验表明,StarNet在准确性和效率方面都大大超过了多个技术水平。 |
| One-pass Multi-task Networks with Cross-task Guided Attention for Brain Tumor Segmentation Authors Chenhong Zhou, Changxing Ding, Xinchao Wang, Zhentai Lu, Dacheng Tao 类不平衡一直是医学图像分割的主要挑战之一。模型级联MC策略显着缓解了类不平衡问题。尽管其性能优异,但这种方法导致了不希望的系统复杂性,同时忽略了模型之间的相关性。为了处理MC的这些缺陷,我们在本文中提出了一种轻量级深度模型,即一次通过多任务网络OM Net来比MC更好地解决类不平衡,并且仅需要一次通过计算用于脑肿瘤分割。首先,OM Net将单独的分段任务集成到一个深层模型中。其次,为了更有效地优化OM Net,我们利用任务之间的相关性来设计在线培训数据传输策略和基于课程学习的培训策略。第三,我们进一步建议在任务之间共享预测结果,这使我们能够设计一个跨任务引导注意CGA模块。在前一任务提供的预测结果的指导下,CGA可以基于类别特定统计自适应地重新校准通道明智的特征响应。最后,引入了一种简单而有效的后处理方法来改进所提出的关注网络的分割结果。进行了大量实验以证明所提出技术的有效性。最令人印象深刻的是,我们在BraTS 2015和BraTS 2017数据集上实现了最先进的性能。通过提议的方法,我们还赢得了64个参赛队伍中BraTS 2018挑战赛的第三名。我们将公开提供代码 |
| Fully Automated Pancreas Segmentation with Two-stage 3D Convolutional Neural Networks Authors Ningning Zhao, Nuo Tong, Dan Ruan, Ke Sheng 由于胰腺是腹部器官,其形状和大小的变化非常大,因此自动和准确的胰腺分割对于医学图像分析而言可能是具有挑战性的。在这项工作中,我们提出了一个基于卷积神经网络CNN的胰腺分割的全自动两阶段框架。在第一阶段,U Net被训练用于下采样3D体积分割。然后从估计的标签中提取覆盖胰腺的候选区域。受到着名地区CNN报道的优越性能的推动,在第二阶段,另一个3D U Net在第一阶段产生的候选区域进行训练。我们评估了所提出的方法在NIH计算机断层扫描CT数据集上的性能,并验证了其在测试中的骰子sorensen系数DSC精度方面优于其他最先进的2D和3D胰腺分割方法。该方法的平均DSC为85.99。 |
| PAC-GAN: An Effective Pose Augmentation Scheme for Unsupervised Cross-View Person Re-identification Authors Chengyuan Zhang, Lei Zhu, Shichao Zhang 人员识别人员Re Id旨在检索由不相交和非重叠相机捕获的同一人的行人图像。许多研究人员最近关注这个热点问题并提出基于深度学习的方法,以有监督或无监督的方式提高识别率。然而,与其他图像检索基准相比,首先不能忽视的两个限制是,现有人员Re Id数据集的大小远远不能满足要求,其次不能为深度模型的训练提供足够的行人样本,现有样本数据集没有足够的人体运动或姿势覆盖,以提供更多的先验学习知识。在本文中,我们介绍了一种新的无监督姿势增强交叉视图人Re Id方案,称为PAC GAN来克服这些限制。我们首先提出了交叉视图姿势增强的正式定义,然后提出了PAC GAN的框架,这是一种新颖的条件生成对抗网络基于CGAN的方法,以提高无人监督的角色视图人Re Id的性能。具体而言,PAC GAN中称为CPG Net的姿势生成模型是从原始图像和骨架样本中生成足够数量的姿势丰富样本。通过将合成的姿势丰富的样本与原始样本组合来产生姿势增强数据集,其被馈送到名为Cross GAN的corss视图人Re Id模型中。此外,我们在CPG网络中使用权重共享策略来提高新生成样本的质量。据我们所知,我们是第一次尝试通过姿势增强来增强无监督的交叉视图人Re Id,并且大量实验的结果表明所提出的方案可以对抗现有技术。 |
| Learning to Compose and Reason with Language Tree Structures for Visual Grounding Authors Richang Hong, Daqing Liu, Xiaoyu Mo, Xiangnan He, Hanwang Zhang 在图像中基于自然语言,例如在树的左侧定位黑狗,是人工智能的核心问题之一,因为它需要理解细粒度和组合语言空间。然而,现有的解决方案依赖于整体语言特征和视觉特征之间的关联,而忽略了语言中隐含的构图推理的本质。在本文中,我们提出了一种自然语言基础模型,它可以自动组成二叉树结构来解析语言,然后以自下而上的方式沿着树进行视觉推理。我们将模型称为RVG TREE递归接地树,其灵感来自直觉,即任何语言表达式都可以递归地分解为两个组成部分,并且可以通过计算子树返回的接地得分来递归累积接地置信度得分。 RVG TREE可以通过使用直通Gumbel Softmax估计器进行端到端训练,该估计器允许来自连续得分函数的梯度通过离散树结构。几个基准测试的实验表明,我们的模型通过更可解释的推理实现了最先进的性能。 |
| PI-Net: A Deep Learning Approach to Extract Topological Persistence Images Authors Anirudh Som, Hongjun Choi, Karthikeyan Natesan Ramamurthy, Matthew Buman, Pavan Turaga 诸如持久性图表之类的拓扑特征及其功能近似(如持久性图像PI)已经显示出对机器学习和计算机视觉应用的巨大希望。其大规模采用的主要瓶颈是计算开销和难以将它们合并到可区分的架构中。我们在本文中迈出了重要的一步,通过提出一种直接从输入数据生成PI的新颖的一步法来缓解这些瓶颈。我们提出了一种称为PI Net的简单卷积神经网络架构,它允许我们学习输入数据和PI之间的映射。我们设计了两个独立的架构,一个设计用于将多变量时间序列信号作为输入,另一个接受多通道图像作为输入。我们将这些网络分别称为Signal PI Net和Image PI Net。据我们所知,我们是第一个提出使用深度学习直接从数据计算拓扑特征的人。我们探讨了使用加速计传感器数据和图像分类在两个应用人类活动识别中使用所提出的方法。我们展示了在监督的深度学习架构中融合PI的难易程度,以及从数据中提取PI的几个数量级的加速。我们的代码可在 |
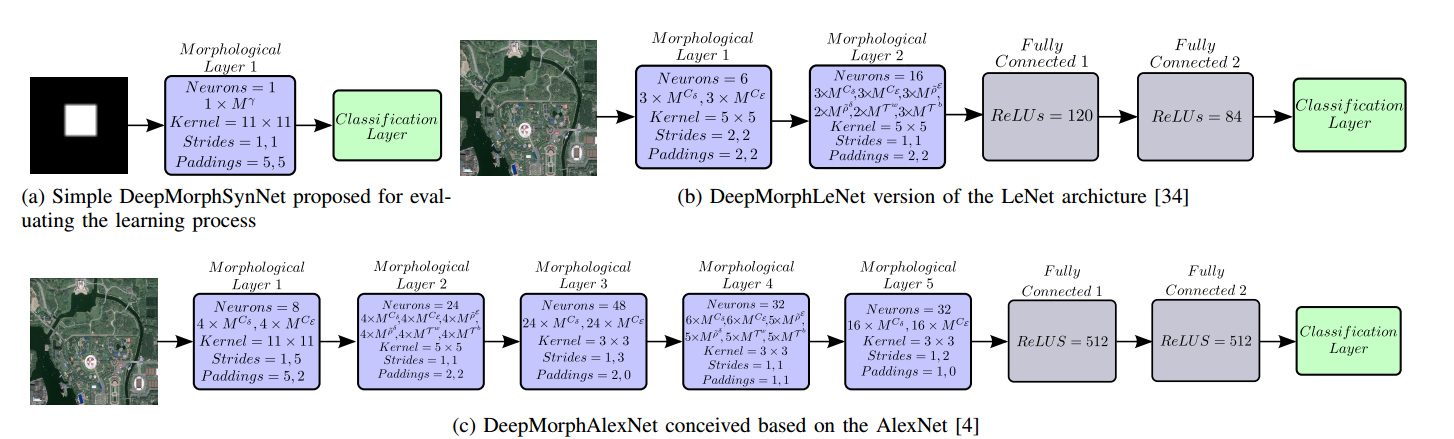
| An Introduction to Deep Morphological Networks Authors Keiller Nogueira, Jocelyn Chanussot, Mauro Dalla Mura, William Robson Schwartz, Jefersson A. dos Santos 最近基于深度学习的计算机视觉应用方法的令人印象深刻的结果为研究和工业界带来了新的空气。这种成功主要归功于允许这些方法学习数据驱动特征的过程,通常基于线性操作。然而,在某些情况下,这样的操作没有良好的性能,因为它们的继承过程模糊了边缘,丢失了角落,边界和对象几何的概念。克服这一点,非线性操作,例如形态学操作,可以保留对象的这些属性,在某些应用中是优选的甚至是现有技术。受此鼓励,在这项工作中,我们提出了一个新的网络,称为深度形态网络DeepMorphNet,能够通过优化结构元素执行特征学习过程,同时进行非线性形态学操作。 DeepMorphNets可以使用深度学习方法培训中常用的传统现有技术进行端到端的训练和优化。使用两个合成和两个传统的图像分类数据集对所提出的算法进行系统评估。结果表明,与当前深度学习方法学习的相比,所提出的DeepMorphNets是一种很有前途的技术,可以学习不同的特征。 |
| Geo-Aware Networks for Fine Grained Recognition Authors Grace Chu, Brian Potetz, Weijun Wang, Andrew Howard, Yang Song, Fernando Brucher, Thomas Leung, Hartwig Adam 细粒度识别可以区分具有细微视觉差异的类别。为了帮助识别细粒度类别,已使用除图像之外的其他信息。然而,使用地理定位信息来提高细粒度分类准确性的努力很少。我们对这一领域的贡献是双重的。首先,据我们所知,这是第一篇系统地研究将地理定位信息纳入从地理定位先验到后期处理到特征调制的细粒度图像分类的各种方法的论文。其次,为了克服没有细粒度数据集具有完整地理定位信息的情况,我们通过向现有流行数据集iNaturalist和YFCC100M提供补充信息,引入并将公开两个具有地理定位的细粒度数据集。这些数据集的结果表明,与仅图像模型结果相比,最佳地理感知网络在iNaturalist上可以实现8.9的前1准确度增加,在YFCC100M上可以实现5.9增加。此外,对于像Mobilenet V2这样的小型图像基线模型,最佳地理感知网络比仅图像模型的前1精度高12.6,比没有地理定位的Inception V3模型实现更高的性能。我们的工作鼓励使用地理定位信息来改善服务器和设备模型的细粒度识别。 |
| 4-D Scene Alignment in Surveillance Video Authors Robert Wagner, Daniel Crispell, Patrick Feeney, Joe Mundy 为固定摄像机监控视频设计强大的活动检测器需要了解3D场景。本文介绍了一种自动相机校准过程,该过程提供了一种在不同时间推理物体之间空间接近度的机制。它将基于CNN的相机姿态估计器与行人观察提供的垂直比例相结合,以建立4D场景几何。与以前的一些方法不同,人们不需要被跟踪,也不需要明确地检测头部和脚部。它对各个高度变化和相机参数估计误差都很稳健。 |
| A systematic framework for natural perturbations from videos Authors Vaishaal Shankar, Achal Dave, Rebecca Roelofs, Deva Ramanan, Benjamin Recht, Ludwig Schmidt 我们引入了一个系统框架,用于量化分类器对视频中自然发生的图像扰动的鲁棒性。作为该框架的一部分,我们构建了Imagenet Video Robust,这是一个人类专家审查的22,178个图像数据集,分为1,109组感知相似图像,这些图像来自ImageNet视频对象检测数据集中的帧。我们评估了在ImageNet上训练的各种分类器,包括训练有效性的模型,并显示中位分类准确度下降16。此外,我们评估更快的R CNN和R FCN模型进行检测,并显示自然扰动同时引起分类和定位误差,导致检测mAP中值下降14个点。我们的分析表明,现实世界中的自然扰动对于当前的CNN来说存在很大问题,这对他们在需要可靠,低延迟预测的安全关键环境中的部署构成了重大挑战。 |
| Investigating the Lombard Effect Influence on End-to-End Audio-Visual Speech Recognition Authors Pingchuan Ma, Stavros Petridis, Maja Pantic 最近提出了几种视听语音识别模型,其目的在于改善噪声中仅音频模型的鲁棒性。然而,几乎所有这些都忽略了伦巴第效应的影响,即在嘈杂环境中说话风格的变化,其旨在使语音更易于理解并且影响语音的声学特性和嘴唇运动。在本文中,我们研究了伦巴第效应在视听语音识别中的影响。据我们所知,这是第一个使用端到端深层架构并使用看不见的扬声器呈现结果的工作。我们的结果表明,正确建模伦巴第语音总是有益的。即使将相对少量的Lombard语音添加到训练集中,也可以显着改善存在嘈杂Lombard语音的真实场景中的性能。我们还展示了文献中遵循的标准方法,其中模型在嘈杂的普通语音上进行训练和测试,提供了对视频性能的正确估计,并略微低估了视听性能。在仅音频接近的情况下,对于高于3dB的SNR而言,性能被高估,并且对于较低的SNR而言低估了性能。 |
| On the use of Pairwise Distance Learning for Brain Signal Classification with Limited Observations Authors David Calhas, Enrique Romero, Rui Henriques 使用脑电图增加对脑信号数据的访问为研究电生理学大脑活动和进行神经元疾病的门诊诊断创造了新的机会。这项工作提出了依赖于信号光谱特性的精神分裂症分类的成对远程学习方法。鉴于观察数量有限,即临床试验中的病例和/或对照个体,我们提出了一种连体神经网络结构,以从每个通道的观察的成对组合中学习辨别特征空间。以这种方式,信号的多变量顺序被用作数据增强的形式,进一步支持网络泛化能力。提出了在余弦对比损失下学习参数的卷积层,以充分探索从脑信号导出的光谱图像。病例对照人群的结果显示,使用所提出的神经网络提取的特征导致精确的精神分裂症诊断10pp的准确性和对光谱特征的敏感性,从而表明存在非平凡的,辨别性的电生理学脑模式。 |
| OctopusNet: A Deep Learning Segmentation Network for Multi-modal Medical Images Authors Yu Chen, Yuexiang Li, Jiawei Chen, Yefeng Zheng 深度学习模型,例如完全卷积网络FCN,已经广泛用于3D生物医学分割并且实现了最先进的性能。多种方式通常用于疾病诊断和量化。在文献中广泛使用两种方法来融合分割网络早期融合中的多种模态,其将多种模态堆叠为不同的输入通道和后期融合,其融合来自最终的不同模态的分割结果。这些融合方法容易受到由具有广泛变化的输入模态引起的交叉模态干扰的影响。为了解决这个问题,我们提出了一种新颖的深度学习架构,即OctopusNet,以更好地利用和融合多种形式中包含的信息。所提出的框架针对用于特征提取的每种模态使用单独的编码器,并利用超融合解码器来融合所提取的特征,同时避免特征爆炸。我们在两个公开可用的数据集上评估了拟议的OctopusNet,即ISLES 2018和MRBrainS 2013.实验结果表明我们的框架优于常用的特征融合方法,并产生最先进的分割精度。 |
| Combining crowd-sourcing and deep learning to understand meso-scale organization of shallow convection Authors Stephan Rasp, Hauke Schulz, Sandrine Bony, Bjorn Stevens 新现象和机制的发现通常始于科学家识别模式的直观能力,例如卫星图像或模型输出。然而,通常,这种直观证据难以编码和再现。在这里,我们展示了人群采购和深度学习如何结合起来,以扩大大气现象的直观发现。具体而言,我们关注的是交易中浅层云的组织,它们在地球的能量平衡中发挥着不成比例的巨大作用。基于视觉检查,定义了糖,花,鱼和砾石四种主观模式或组织。在两个研究所的云标记日,67名参与者在众包采购平台上分类了超过30,000张卫星图像。物理分析表明,这四种模式与不同的大规模环境条件有关。然后,我们使用分类作为深度学习算法的训练集,学习了以人类准确度检测云模式。这使得分析远远超出人类分类。例如,我们创建了四种模式的全球气候学。这些揭示了地理热点,可以深入了解中尺度云组织与大规模环流的相互作用。我们的项目表明,人群采购和深度学习相结合,开辟了新的数据驱动方式,探索云循环相互作用,并作为地球科学中广泛可能研究的模板。 |
| A Robust Roll Angle Estimation Algorithm Based on Gradient Descent Authors Rui Fan, Lujia Wang, Ming Liu, Ioannis Pitas 本文提出了一种鲁棒的侧倾角估计算法,该算法是根据我们之前发表的工作开发的,其中通过使用黄金分割搜索算法最小化全局能量,从密集视差图估计侧倾角。在本文中,为了实现更高的计算效率,我们利用梯度下降来优化上述全局能量。实验结果表明,所提出的侧倾角估计算法需要较少的迭代次数才能达到与前一种方法相同的精度。 |
| AssemblyNet: A Novel Deep Decision-Making Process for Whole Brain MRI Segmentation Authors Pierrick Coup , Boris Mansencal, Micha l Cl ment, R mi Giraud, Baudouin Denis de Senneville, Vinh Thong Ta, Vincent Lepetit, Jos V. Manjon 使用深度学习DL的全脑分割是非常具有挑战性的任务,因为与可用训练图像的数量相比,解剖标签的数量非常高。为了解决这个问题,先前的DL方法提出使用全局卷积神经网络CNN或少数独立的CNN。在本文中,我们提出了一种新的集合方法,基于大量的CNN处理不同的重叠脑区。受议会决策系统的启发,我们提出了一个名为AssemblyNet的框架,由两个U网组件组成。这种议会制度能够处理复杂的决定并迅速达成共识。 AssemblyNet引入了相邻U网之间的知识共享,第二大会以更高的分辨率制定了修正程序,以完善第一个大会的决定,以及通过多数表决获得的最终决定。当使用相同的45个训练图像时,AssemblyNet在Dice度量,基于补丁的联合标签融合15和SLANT 27乘以10方面优于全球U Net 28。最后,AssemblyNet展示了处理有限训练数据的高容量,以在实际训练和测试时间内实现全脑分割。 |
| Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper) Authors Santiago Castro, Devamanyu Hazarika, Ver nica P rez Rosas, Roger Zimmermann, Rada Mihalcea, Soujanya Poria 讽刺经常通过几种口头和非口头线索来表达,例如,语气的变化,单词的过分强调,抽出的音节或直面的表情。最近在讽刺检测方面的大部分工作都是在文本数据上进行的。在本文中,我们认为结合多模态线索可以改善讽刺的自动分类。作为开发用于讽刺检测的多模式方法的第一步,我们提出了一种新的讽刺数据集,即多模式讽刺检测数据集MUStARD,由流行的电视节目编制而成。 MUStARD包含用讽刺标签注释的视听话语。每个话语都伴随着对话中历史话语的背景,其提供关于话语发生的场景的附加信息。我们的初步结果表明,与使用个体模态相比,使用多模态信息可以将讽刺检测的相对错误率降低F评分高达12.9。完整数据集可公开使用 |
| Artifact Disentanglement Network for Unsupervised Metal Artifact Reduction Authors Haofu Liao, Wei An Lin, S. Kevin Zhou, Jiebo Luo 当前基于深度神经网络的计算机断层扫描CT金属伪影减少方法是监督方法,其严重依赖于合成数据进行训练。然而,由于合成数据可能无法完美地模拟CT成像的潜在物理机制,因此监督方法通常不能很好地推广到临床应用。为了解决这个问题,我们建议,就我们所知,第一个无监督的MAR学习方法。具体而言,我们引入了一种新颖的人工解法网络,该网络能够在受影响的工件和无伪影图像域之间实现不同形式的生成和规则化,以支持无监督学习。大量实验表明,我们的方法明显优于现有的无监督模型的图像到图像转换问题,并且在综合数据集上实现了与现有监督模型相当的性能。当应用于临床数据集时,我们的方法相对于监督模型实现了相当大的改进。 |
| Chinese Abs From Machine Translation |
Interesting:
📚DeepMorphNet深度形态学网络,用于获取更稳定准确的形态学操作结果, (from Universidade Federal de Minas Gerais, Brazil)
📚高效无字典的光学字符识别,利用多种字体和场景合成不同形状的字体,并将其合成在不同自然场景中,包含了扭曲和形变(不同的透明度合成)。 (from Fraunhofer IAIS德国夫琅禾费研究所)
dataset:https://github.com/tesseract-ocr/tessdata_fast
📚Visual Confusion Label Tree的图像分类模型, (from 国防科大)
📚基于文本线和合成文本图像实现的文件质量评价, (from Tongdun Technology ZhongAn Technology)
TL;DwR
PI-Net分析图像的拓扑信息 ,code:https://github.com/anirudhsom/PI-Net
+运动员检测与追踪
玉米叶子检测 & 农田杂草检测
++StarNet 行人轨迹预测,基于星形拓扑结果CNN
+接吻场景检测,code:http://github.com/amirziai/kissing-detector
大气模式分析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}