
【今日CV 计算机视觉论文速览 第128期】Mon, 10 Jun 2019
今日CS.CV 计算机视觉论文速览
Mon, 10 Jun 2019
Totally 38 papers
👉上期速览 ✈更多精彩请移步主页

Interesting:
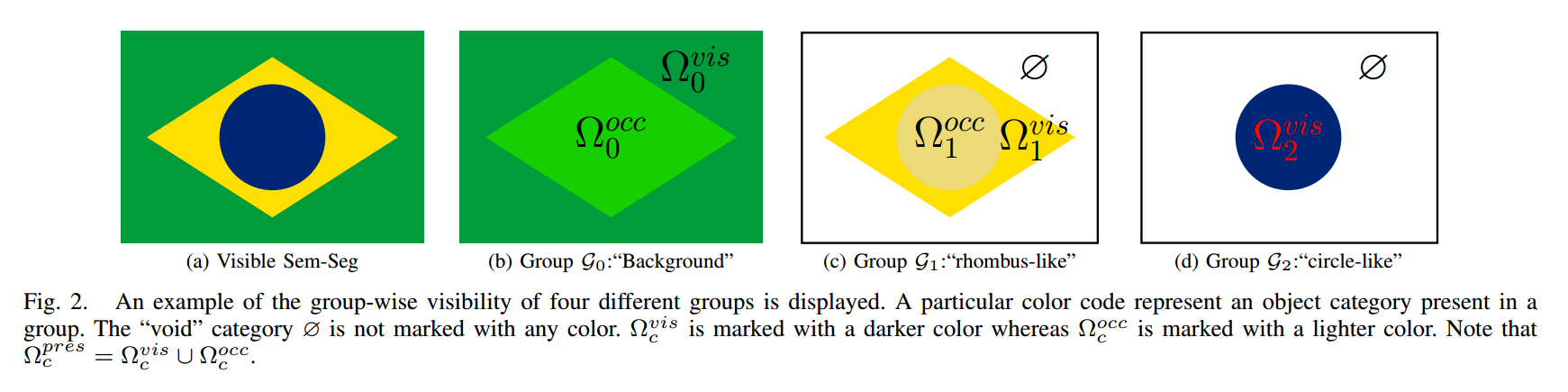
📚遮挡区域语义分割, 研究人员将语义分割模型拓展到了看不见的区域上,为遮挡物体也提出了有效的语义分割。将前景和背景分开, 按照分组的方式进行分割,在不增加网络尺寸的情况下可以通过改造的交叉熵来实现有效分割。(from 阿德莱德大学 澳大利亚)
一般语义分割与分组语义分割,可以将遮挡的部分背景有效分解出来:
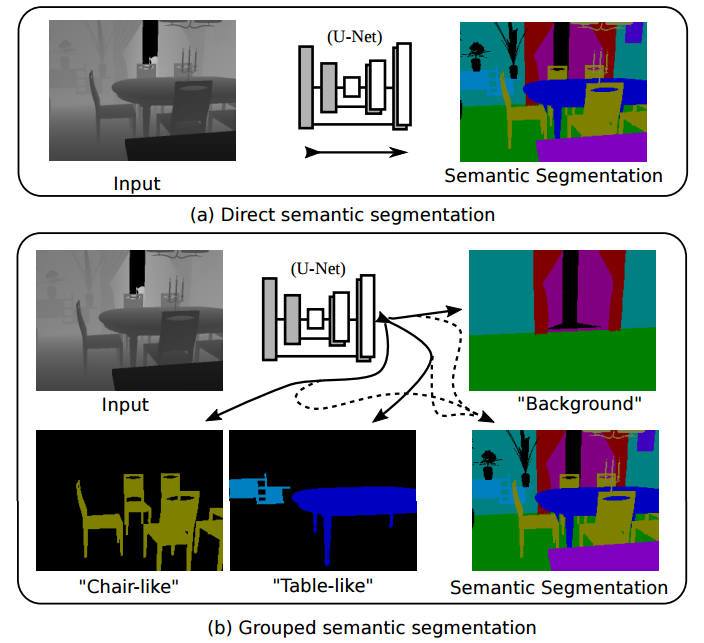
分组语义分割的例子:
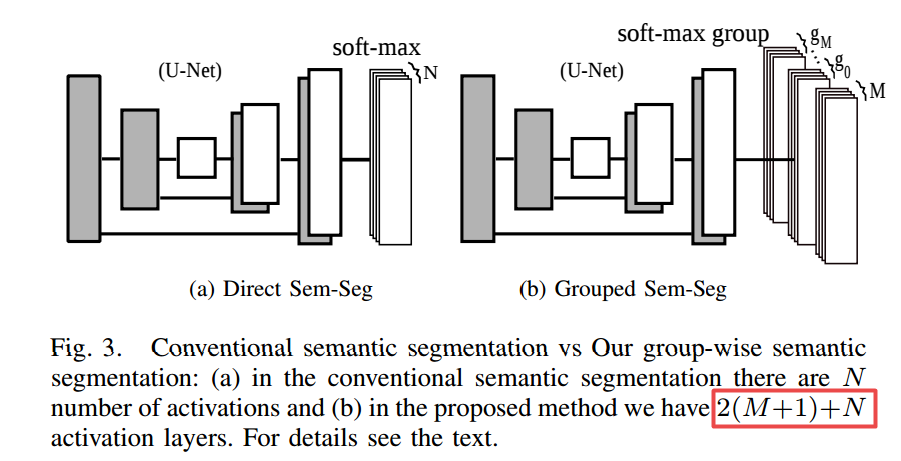
在标准语义分割的基础上增加了2(M+1)个分组(M 为分组数,N为类别数):
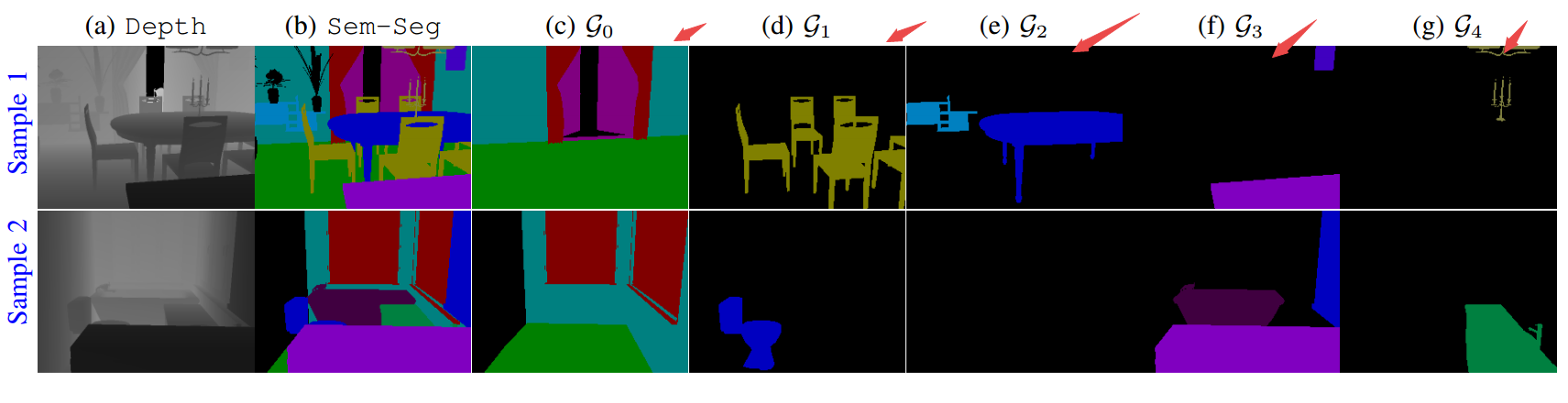
结果如下所示,可以看到不同组别的分类和每一组内各自的分类:
ref:https://github.com/shurans/SUNCGtoolbox
https://shurans.github.io/
dataset:SUNCG
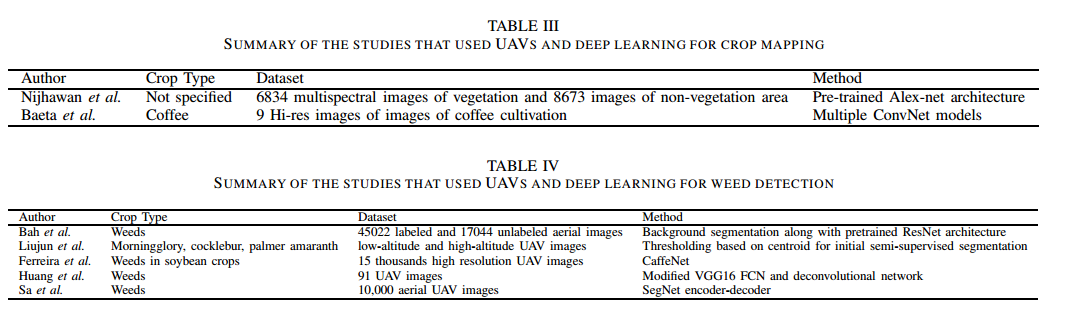
📚无人机用于环境和场景检测, UAV和多种相机结合实现对于不同作物的检测可以实现分类、计数、检测、产量预测、病虫害防治等,这篇文章总结了无人机在各个方面的应用和研究,将为智能农场提供新的思路。(from Kingston University, UK)
基于UAV的作物分类:

基于UAV的生产预测:

种植面积和害虫检测:
营养和病害检测:

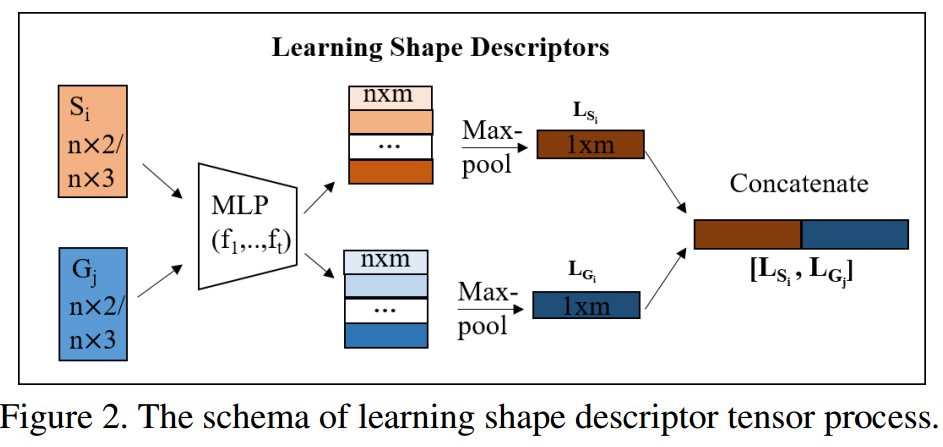
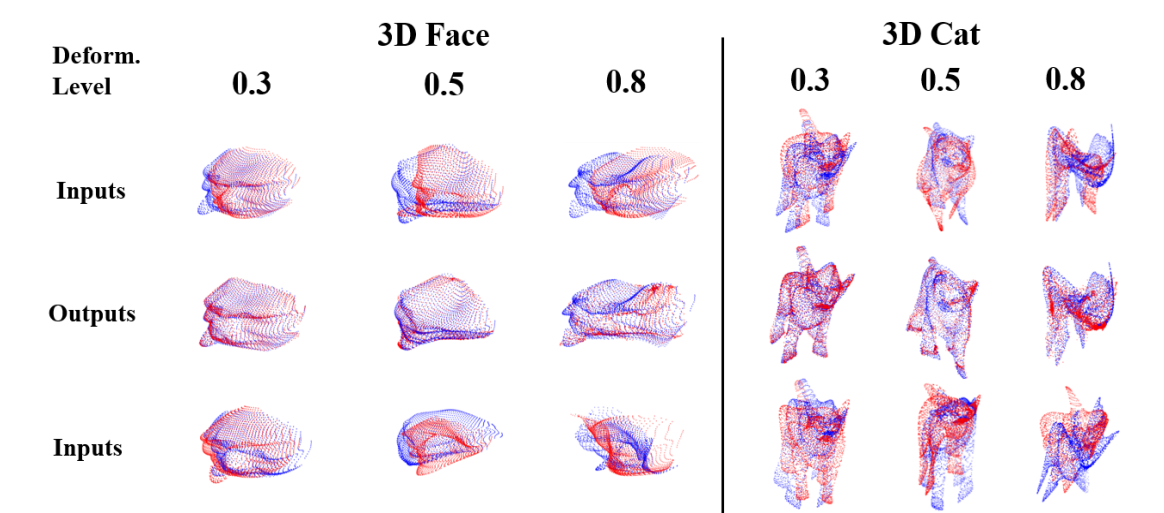
📚 coherent point drift networks,CPD-Net用于非刚体的配准网络, 传统的点云配准方法需要搜索一个集合变换来将源于目标配准,但十分耗时。这篇论文提出乐意一种非监督学习的方法可以将实现非刚体点集的实时变换配准,它可以从训练数据中学习到一个位移场函数来估计几何变换,并能够预测位置物体间配准的几何变换。并能够适用于任意函数来对不同复杂度的物体进行几何变换与配准,并可以保证连续位移矢量函数来进行配准。(from 纽约大学)
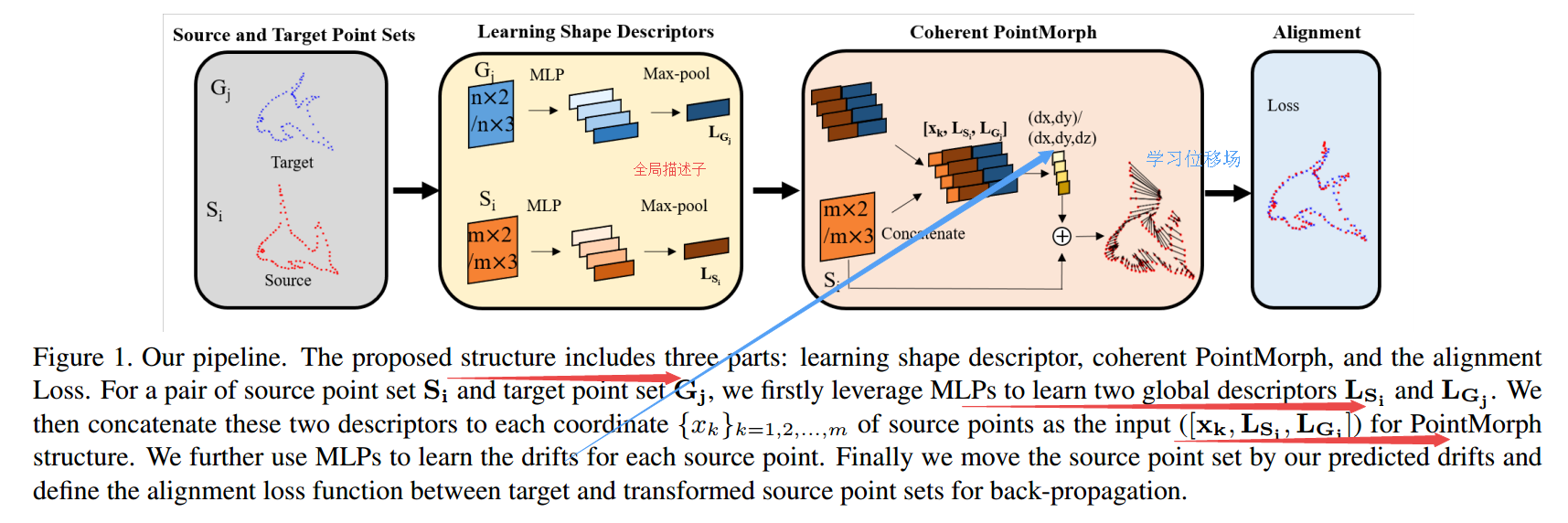
学习描述子 & 学习位移量:
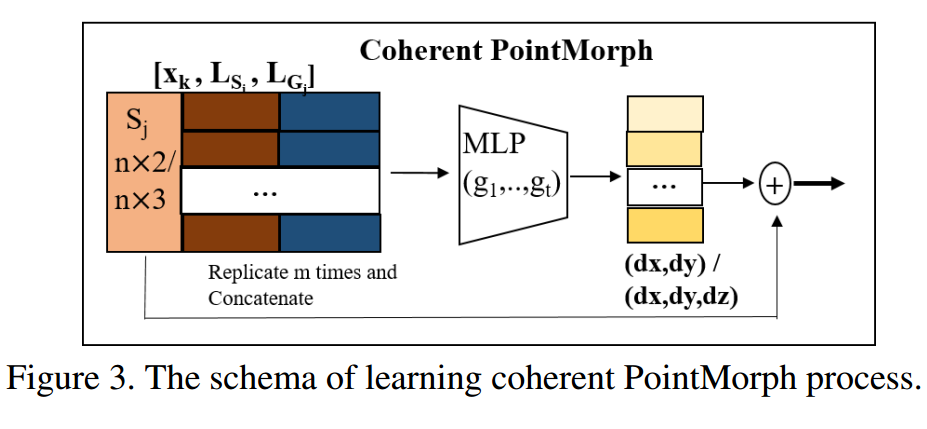
一些实验结果:
code:https://github.com/Lingjing324/CPD-Net
dataset:4.1. Experimental Dataset
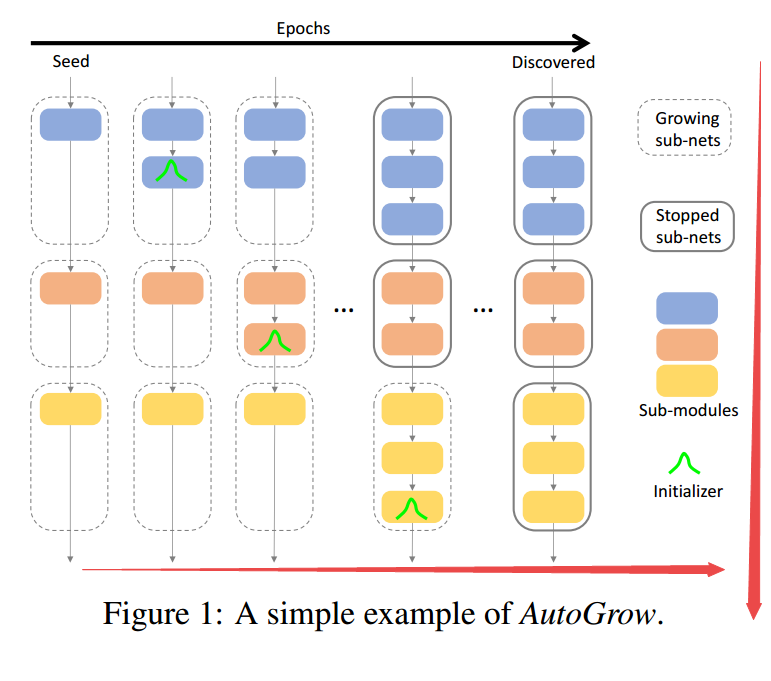
📚AutoGrow, 自动深度探索拓展的网络,从浅层架构开始不断根据模型表现拓展架构,通过通用增长和停止策略来最小化人类的介入,可以发现发现有效的网络深度并实现最优的效果。可以有效减少计算和搜索时间,局小于深度发现效率,可以拓展到大规模数据集上。(from 杜克大学)
随着训练不断增长的网络模型:
code:https://github.com/wenwei202/autogrow
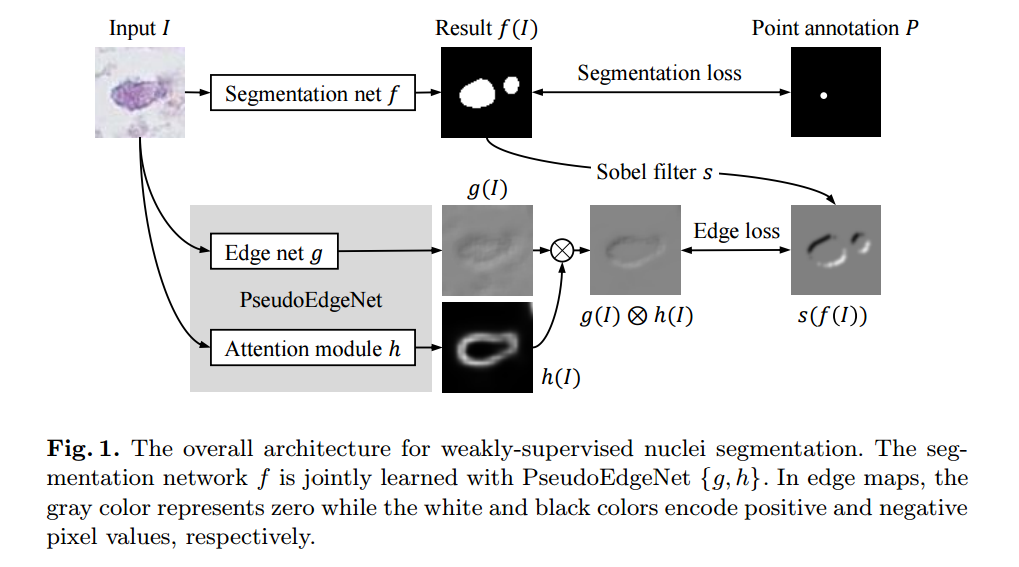
📚基于点标记的细胞分割方法,弱监督方法, (from Lunit Inc., Seoul, South Korea)
📚自动驾驶汽车重点技术综述, (from https://www.webofknowledge.com)
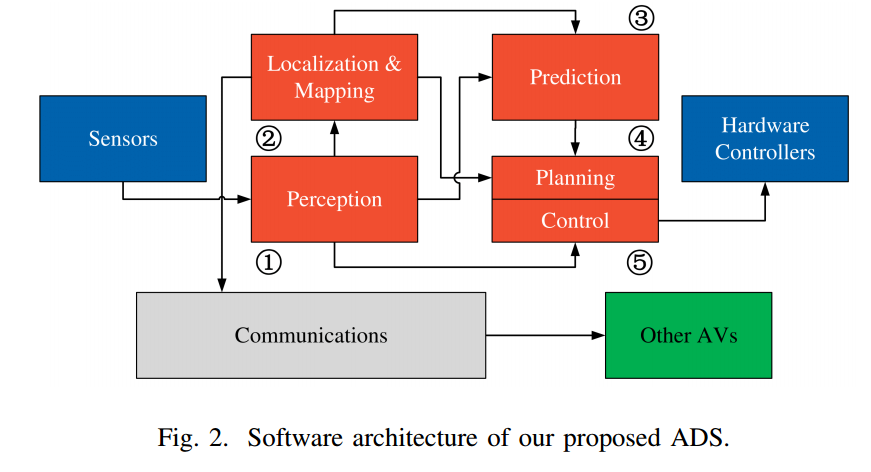
📚多模态端到端自动驾驶, (from Univ. Autonoma de Barcelona (UAB).)
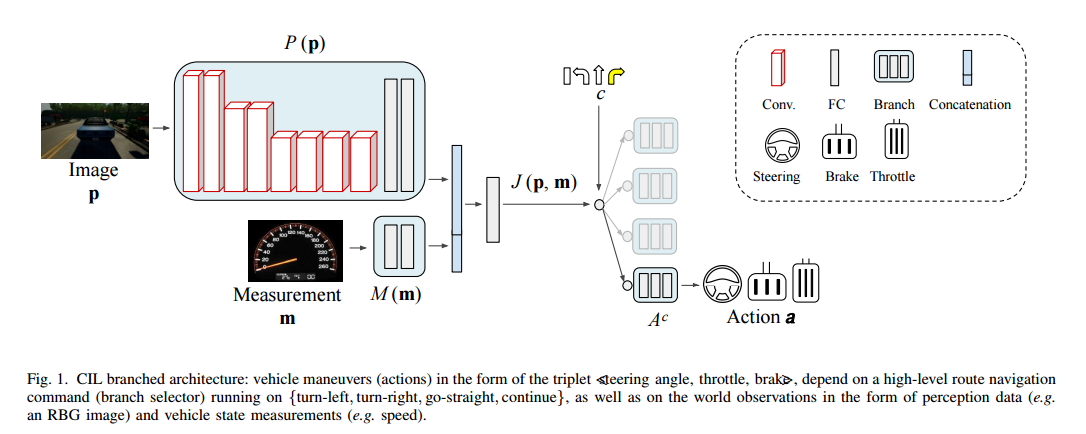
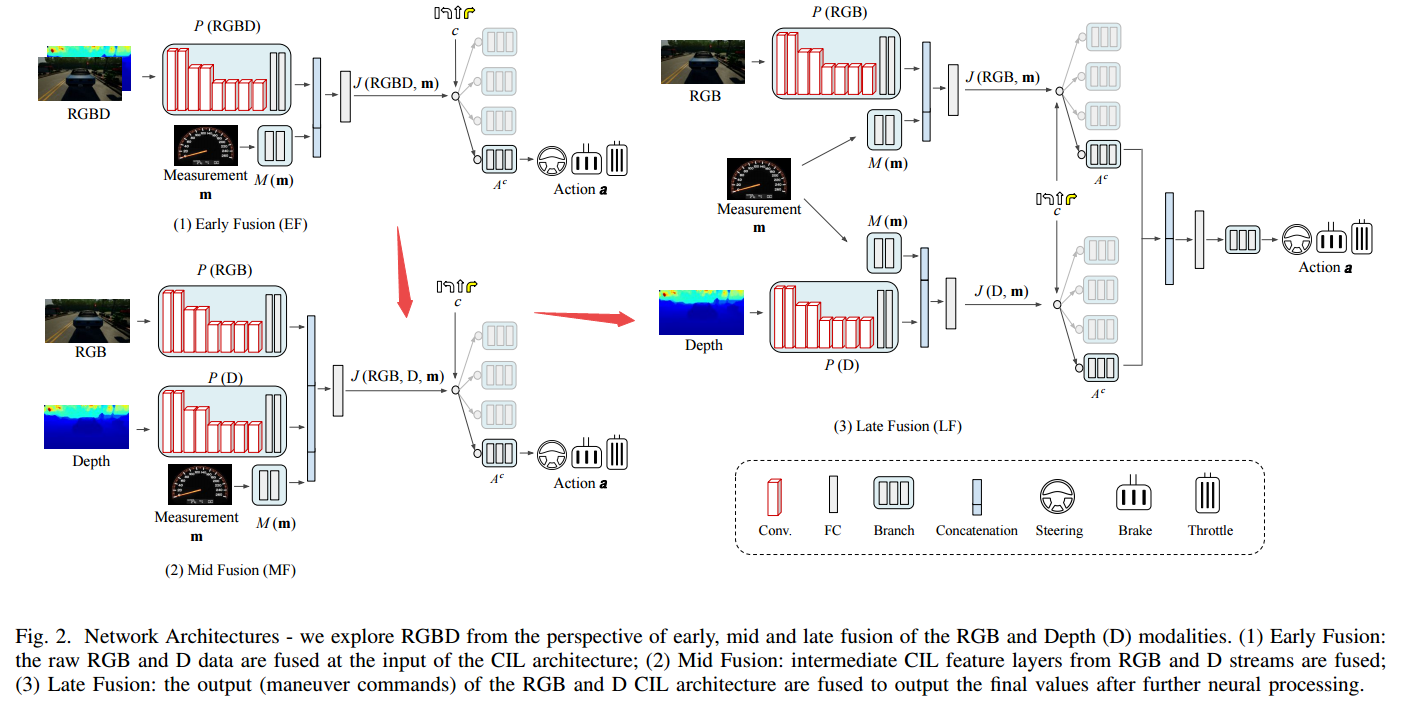
网络架构:
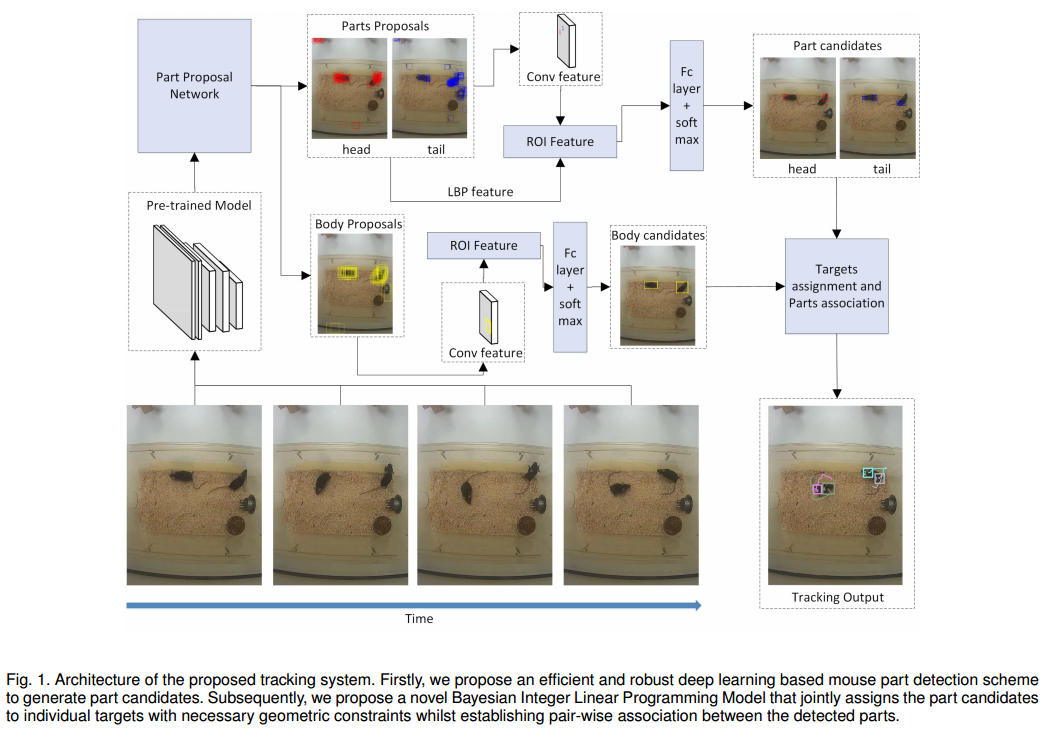
📚多主体检测与跟踪方法, (from University of Leicester, United Kingdom)
Daily Computer Vision Papers
| Evolving Losses for Unlabeled Video Representation Learning Authors AJ Piergiovanni, Anelia Angelova, Michael S. Ryoo 我们提出了一种从未标记数据中学习视频表示的新方法。给定大规模未标记的视频数据,目标是通过学习可以直接用于新任务(例如零次射击学习)的通用且可转移的表示空间来从这样的数据中受益。我们将无监督表示学习表示为多模态,多任务学习问题,其中表示也通过蒸馏在不同模态中共享。此外,我们还介绍了使用进化算法找到更好的损失函数来训练这样的多任务多模态表示空间的概念,我们的方法自动搜索捕获多个自监督任务和模态的损失函数的不同组合。我们的公式允许将音频,光流和时间信息提升到单个基于RGB的卷积神经网络中。我们还比较了使用其他未标记视频数据的效果,并评估了我们在标准公共视频数据集上的表示学习。 |
| **Extracting Visual Knowledge from the Internet: Making Sense of Image Data Authors Yazhou Yao, Jian Zhang, Xiansheng Hua, Fumin Shen, Zhenmin Tang 最近在视觉识别方面的成功主要归功于特征表示,学习算法以及标记的训练数据的不断增加的大小。对前两个问题进行了广泛的研究,但对第三个问题的关注却少得多。由于手动标签的高成本,ImageNet等近期工作的规模在日常应用方面仍然相对较小。在这项工作中,我们主要关注如何大规模自动生成给定视觉概念的识别图像数据。利用生成的图像数据,我们可以为给定的概念训练强大的识别模型。我们在基准Pascal VOC 2007数据集上评估了提议的webly监督方法,结果证明了我们提出的方法在图像数据收集中的优越性。 |
| ****Multimodal End-to-End Autonomous Driving Authors Yi Xiao, Felipe Codevilla, Akhil Gurram, Onay Urfalioglu, Antonio M. L pez 自动驾驶汽车AV是未来智能移动的关键。 AV的一个关键组成部分是人工智能AI能够驱动到所需的目的地。今天,有不同的范例来解决AI驱动程序的开发问题。一方面,我们发现模块化管道,将驱动任务划分为子任务,如感知对象检测,语义分割,深度估计,跟踪和机动控制局部路径规划和控制。另一方面,我们发现端到端驾驶方法试图学习从输入原始传感器数据到车辆控制信号的转向角度的直接映射。后者的研究相对较少,但由于它们在传感器数据注释方面要求较低,因此越来越受欢迎。本文重点介绍端到端的自动驾驶。到目前为止,大多数依赖于此范例的提案都假设RGB图像作为输入传感器数据。然而,AV不仅仅配备摄像机,而且还配备有源传感器,提供传统LiDAR或新固态激光器的精确深度信息。因此,本文分析RGB和深度数据RGBD数据是否实际上可以作为多模式端到端驱动方法中的补充信息,从而产生更好的AI驱动程序。使用CARLA模拟器功能,标准基准测试和条件模仿学习CIL,我们将展示RGBD是如何产生更成功的端到端AI驱动程序的。我们将通过早期,中期和晚期融合方案比较RGBD信息的使用,包括多感觉和单传感器单眼深度估计设置。 |
| Ego-Pose Estimation and Forecasting as Real-Time PD Control Authors Ye Yuan, Kris Kitani 我们建议使用通过强化学习RL学习的基于比例导数PD控制的策略来估计和预测来自自我中心视频的3D人体姿势。该方法直接从未分段的自我中心视频和由各种复杂的人体运动组成的运动捕捉数据中学习,例如蹲伏,跳跃,弯曲和运动过渡。我们提出了一种视频条件反复控制技术来预测任意长度的物理有效和稳定的未来运动。我们还介绍了一种基于值函数的故障安全机制,它使我们的方法能够作为单通道算法运行在视频数据上。受控和野外数据的实验表明,我们的方法在定量度量和运动的视觉质量方面都优于现有技术,并且足够强大,可以直接转移到现实世界的场景。此外,我们的时间分析表明,我们的姿势估计和预测的组合使用可以在30 FPS下运行,使其适用于实时应用。 |
| HPILN: A feature learning framework for cross-modality person re-identification Authors Jian Wu Lin, Hao Li 大多数视频监控系统都使用RGB和红外摄像机,这使得它成为重新识别穿越RGB和红外模式的人的重要技术。由于RGB和红外中的异构图像引起的交叉模态变化以及由异构人体姿势,相机视图,光亮度等引起的内部模态变化,这项任务可能具有挑战性。为了应对这些挑战,新的特征学习框架,HPILN,提出。在该框架中,修改现有的单模态重新识别模型以适应交叉模态场景,之后使用特别设计的硬五重峰丢失和同一性损失来改进修改的交叉模态重新识别模型的性能。基于SYSU MM01数据集的基准,进行了大量实验,表明所提出的方法在累积匹配特征曲线CMC和平均平均精度MAP方面优于所有现有方法。 |
| Context-driven Active and Incremental Activity Recognition Authors Gabriele Civitarese, Riccardo Presotto, Claudio Bettini 多年来,基于移动设备传感器数据的人类活动识别一直是移动和普适计算领域的活跃研究领域。虽然所提出的大多数技术基于监督学习,但正在考虑半监督方法以显着减小初始化识别模型所需的训练集的大小。这些方法通常采用自我训练或主动学习来逐步完善模型,但其有效性似乎仅限于一组有限的身体活动。我们声称围绕用户的上下文,例如语义位置,与运输路线的接近度,一天中的时间以及关于该上下文与人类活动之间的关系的常识,可以有效地显着增加已识别的活动集合,包括那些难以区分仅考虑惯性传感器,以及高度依赖于环境的传感器。在本文中,我们提出了CAVIAR,一种用于实时活动识别的新型混合半监督和基于知识的系统。我们的方法将语义推理应用于上下文数据以细化半监督分类器的预测。上下文细化的预测被用作新的标记样本以更新结合自我训练和主动学习技术的分类器。从26个受试者获得的真实数据集上的结果显示了情境感知方法对识别率和由主动学习模块生成的对象的查询数量的有效性。为了评估上下文推理的影响,我们还将CAVIAR与纯统计版本进行比较,考虑在上下文数据上计算的特征作为机器学习过程的一部分。 |
| Visual Person Understanding through Multi-Task and Multi-Dataset Learning Authors Kilian Pfeiffer, Alexander Hermans, Istv n S r ndi, Mark Weber, Bastian Leibe 我们解决了学习用于人物识别,属性分类,身体部位分割和姿势估计的单个模型的问题。通过对这些任务的预测,我们可以更全面地了解人,这对许多应用都很有价值。这是一个经典的多任务学习问题。但是,不存在可以共同学习这些任务的数据集。因此,在训练期间需要组合几个数据集,这在其他情况下经常导致过去的性能降低。我们广泛评估不同任务和数据集如何相互影响,以及任务之间不同程度的参数共享如何影响性能。我们的最终模型匹配或优于其单一任务对应物,而不会产生显着的计算开销,使其对于资源受限的场景(如移动机器人)非常有趣。 |
| An Artificial Intelligence-Based System for Nutrient Intake Assessment of Hospitalised Patients Authors Ya Lu, Thomai Stathopoulou, Maria F. Vasiloglou, Stergios Christodoulidis, Beat Blum, Thomas Walser, Vinzenz Meier, Zeno Stanga, Stavroula G. Mougiakakou 住院患者的定期营养摄入监测在降低与疾病相关的营养不良DRM的风险中起着关键作用。虽然已经开发了几种估算营养素摄入量的方法,但仍然需要更可靠和全自动化的技术,因为这可以提高数据准确性并减少参与者的负担和健康成本。在本文中,我们提出了一种基于人工智能的新系统,通过简单处理餐前消费前后捕获的RGB深度图像对,准确估计营养摄入量。为了开发和评估系统,我们组装了一个专门的新的322餐图像和食谱数据库,并使用创新策略与数据注释相结合。利用该数据库,开发了一种采用新型多任务神经网络和3D表面构造算法的系统。这允许顺序语义食物分割和消耗食物量的估计,并允许每种食物类型的营养物摄入的全自动估计具有15估计误差。 |
| Learning Classifier Synthesis for Generalized Few-Shot Learning Authors Han Jia Ye, Hexiang Hu, De Chuan Zhan, Fei Sha 现实世界中的视觉识别需要处理长尾甚至开放式数据。视觉系统的实用性是可靠地识别填充的头部视觉概念,同时了解少数实例的尾部类别。通过学习人口密集类别的强分类器或尾部类别的少数镜头分类器,课程平衡了许多镜头学习和少量镜头学习解决了这个具有挑战性的问题的一方。在本文中,我们研究了广义少数射击学习的问题,其中头部和尾部的识别是联合进行的。我们提出了一种基于神经词典的ClAssifier SynThesis LEarning CASTLE方法,除了多类头分类器之外,还合成校准的尾分类器,同时在全局识别框架中识别头部和尾部视觉类别。在两个标准基准数据集MiniImageNet和TieredImageNet上,CASTLE在不同的学习场景中表现出了卓越的性能,即许多镜头学习,少量镜头学习和普遍的少量镜头学习。 |
| **PseudoEdgeNet: Nuclei Segmentation only with Point Annotations Authors Inwan Yoo, Donggeun Yoo, Kyunghyun Paeng 细胞核分割是数字病理学中整个载玻片图像分析的重要任务之一。随着深度学习的急剧发展,最近的深度网络已经证明了核分割任务的成功表现。然而,实现良好性能的主要瓶颈是注释成本。大型网络需要大量的分段掩码,这个注释任务是给病理学家而不是公众。在本文中,我们提出了一种弱监督的核分割方法,它只需要点注释进行训练。该方法可以扩展到大的训练集,因为标记核的点比精细分割掩模便宜得多。为此,我们引入了一种名为PseudoEdgeNet的新型辅助网络,它引导分割网络即使没有边缘注释也能识别核边缘。我们使用两个公共数据集评估我们的方法,结果表明该方法始终优于其他弱监督方法。 |
| **Conditional Neural Style Transfer with Peer-Regularized Feature Transform Authors Jan Svoboda, Asha Anoosheh, Christian Osendorfer, Jonathan Masci 本文介绍了一种神经风格转移模型,它仅使用描述所需风格的一组示例来有条件地生成风格化图像。即使在零镜头设置中,所提出的解决方案也能产生高质量的图像,并且允许更改内容几何形状的更大自由度。这要归功于一种新颖的同行规则化层的引入,该层通过自定义图形卷积层在潜在空间中重构风格,旨在分离风格和内容。与绝大多数现有解决方案相反,我们的模型不需要任何预先训练的网络来计算感知损失,并且可以通过一组新的循环损失进行端到端的全面训练,这些循环损失直接在潜在的情况下运行 |
| NICO: A Dataset Towards Non-I.I.D. Image Classification Authors Yue He, Zheyan Shen, Peng Cui I.I.D.训练数据和测试数据之间的假设是大量图像分类方法的基础。在非IID性很常见的实际情况下,很难保证这种性质,导致这些模型的性能不稳定。然而,在文献中,非I.I.D.图像分类问题在很大程度上未得到充分研究。一个关键原因是缺乏精心设计的数据集来支持相关研究。在本文中,我们构建并发布了非I.I.D.名为NICO的图像数据集,它利用上下文有意识地创建非IID。扩展的实验结果和分析证明,NICO数据集可以很好地支持从头开始训练ConvNet模型,并且NICO可以支持各种非I.I.D.与其他数据集相比具有足够灵活性的情况。 |
| ***Seeing Behind Things: Extending Semantic Segmentation to Occluded Regions Authors Pulak Purkait, Christopher Zach, Ian Reid 由于深度神经网络DNN的出现,近年来语义分割和实例级分割取得了实质性进展。提出了许多具有卷积神经网络CNN的深层架构,它们大大超越了传统的机器学习方法。这些体系结构通过优化交叉熵损失来预测每个像素的直接可观察语义类别。在这项工作中,我们将语义分割的极限推向预测直接可见以及被遮挡的对象或对象部分的语义标签,其中网络的输入是单个深度图像。我们将语义类别分组为一个背景和多个前景对象组,并且我们建议修改标准交叉熵损失以应对设置。在我们的实验中,我们证明通过最小化所提出的损失而训练的CNN能够预测可见和被遮挡的对象部分的语义类别,而不需要与标准分割任务相比增加网络大小。结果在从SUNCG数据集增加的新生成的数据集上进行验证。 |
| Deep Spherical Quantization for Image Search Authors Sepehr Eghbali, Ladan Tahvildari 利用紧凑离散码编码高维图像的哈希方法已被广泛应用于增强大规模图像检索。在本文中,我们提出了深度球形量化DSQ,这是一种新的方法,使深度卷积神经网络生成有监督和紧凑的二进制代码,以实现高效的图像搜索。我们的方法同时学习将输入图像变换为低维度判别空间的映射,并使用多码本量化来量化变换后的数据点。为了消除范数方差对码本学习的负面影响,我们强制网络L 2对提取的特征进行归一化,然后使用专门针对位于单位超球面上的点设计的新的监督量化技术来量化所得到的矢量。此外,我们引入了一种易于实现的量化技术扩展,可以强化码本的稀疏性。大量实验证明,DSQ及其稀疏变体可以生成语义上可分离的紧凑二进制代码,其在三个基准上优于许多现有技术的图像检索方法。 |
| Risky Action Recognition in Lane Change Video Clips using Deep Spatiotemporal Networks with Segmentation Mask Transfer Authors Ekim Yurtsever, Yongkang Liu, Jacob Lambert, Chiyomi Miyajima, Eijiro Takeuchi, Kazuya Takeda, John H. L. Hansen 先进的驾驶员辅助和自动驾驶系统依靠风险评估模块来预测和避免危险情况。当前的方法使用昂贵的传感器设置和复杂的处理流程,限制了它们的可用性和稳健性。为了解决这些问题,我们引入了一种新颖的基于深度学习的动作识别框架,用于对单眼摄像机捕获的短视频片段中的危险车道变换行为进行分类。我们设计了一个深度时空分类网络,该网络使用预先训练的最新实例分割网络Mask R CNN作为此任务的空间特征提取器。所提出方法的长短期记忆LSTM和较浅的最终分类层在具有注释风险标签的半自然变道车道变化数据集上进行训练。对最先进的特征提取器进行了全面比较,以找到最佳的网络布局和培训策略。使用所提出的网络获得了具有0.937 AUC分数的最佳结果。我们的代码和训练有素的模型是开源的。 |
| Does Generative Face Completion Help Face Recognition? Authors Joe Mathai, Iacopo Masi, Wael AbdAlmageed 面部遮挡,覆盖面部的大多数或有辨别力的部分,可以打破面部感知并导致信息的急剧损失。诸如最近的深度面部识别模型之类的生物识别系统不能免受覆盖面部部分的障碍物或其他物体的影响。虽然大多数当前的面部识别方法未被优化以处理遮挡,但是已经有一些尝试直接在训练阶段中提高鲁棒性。与那些不同,我们建议研究生成面部完成对识别的影响。我们提供了一个面部完成编码器解码器,它基于一个带有门控机制的卷积算子,训练有大量的面部遮挡。为了系统地评估真实遮挡对识别的影响,我们建议玩遮挡游戏,我们将3D对象渲染到不同的面部,提供有效去除这些遮挡的影响的宝贵知识。野生LFW中标记面的广泛实验及其更难以改变的LFW BLUFR,证明面部完成能够部分恢复机器视觉系统中的面部感知以提高识别率。 |
| Recognizing American Sign Language Manual Signs from RGB-D Videos Authors Longlong Jing, Elahe Vahdani, Matt Huenerfauth, Yingli Tian 在本文中,我们提出了一种基于3D卷积神经网络3DCNN的多流框架来识别美国手语ASL手动标志,包括手的动作,以及在某些情况下从RGB D视频实时非手动面部动作,融合多模态功能,包括手势,面部表情和来自多通道RGB,深度,运动和骨架关节的身体姿势。为了学习视频中的整体时间动态,通过为每个视频选择帧的子集来生成代理视频,然后将其用于训练所提出的3DCNN模型。我们收集了一个新的ASL数据集ASL 100 RGBD,其中包含由Microsoft Kinect V2摄像头捕获的42个RGB D视频,每个100个ASL手动标志,包括RGB通道,深度图,骨架关节,面部特征和HDface。对于每个语义区域,即人类签名者执行的每个单词的持续时间,数据集被完全注释。我们提出的方法在我们新收集的ASL 100 RGBD数据集中识别100个ASL单词时达到92.88准确度。我们的框架识别来自RGB D视频的手势的有效性在Chalearn IsoGD数据集上得到了进一步证明,并且通过仅使用5个通道而不是12个通道,在平均融合方面达到了比现有技术工作高5.51的精度。在以前的工作中。 |
| **Figure Captioning with Reasoning and Sequence-Level Training Authors Charles Chen, Ruiyi Zhang, Eunyee Koh, Sungchul Kim, Scott Cohen, Tong Yu, Ryan Rossi, Razvan Bunescu 条形图,饼图和线图等数字被广泛用于以简洁的格式传达重要信息。它们通常是人性化的,但计算机很难自动处理。在这项工作中,我们研究了图形字幕的问题,其目标是自动生成图形的自然语言描述。虽然已经广泛研究了自然图像字幕,但是字幕字幕已经受到相对较少的关注并且仍然是一个具有挑战性的问题。首先,我们基于FigureQA为图形字幕引入了一个新的数据集FigCAP。其次,我们提出了两种新颖的注意机制。为了在图中准确生成标签,我们建议标签图注意。为了模拟图形标签之间的关系,我们提出了关系图注意。第三,我们使用强化学习的序列级训练,以直接优化评估指标,从而减轻暴露偏差问题,并进一步改进生成长字幕的模型。大量实验表明,所提出的方法优于基线,从而证明了大量数据库自动标题的巨大潜力。 |
| Multi-scale guided attention for medical image segmentation Authors Ashish Sinha, Jose Dolz 尽管卷积神经网络CNN正在推动医学图像分割的进步,但标准模型仍然存在一些缺点。首先,使用多尺度方法,即编码器解码器架构,导致信息的冗余使用,其中类似的低级特征在多个尺度上被多次提取。其次,长距离特征依赖性未被有效建模,导致与每个语义类相关联的非最佳判别特征表示。在本文中,我们尝试通过基于引导自我关注机制的使用捕获更丰富的上下文依赖性来克服提出的体系结构的这些限制。该方法能够将局部特征与其对应的全局依赖性集成,并且以自适应方式突出显示相互依赖的信道映射。此外,不同模块之间的额外损失引导注意机制去除噪声并通过强调相关特征关联来关注图像的更多判别区域。我们在磁共振成像MRI的腹部器官分割的背景下评估所提出的模型。一系列消融实验支持这些注意模块在所提出的架构中的重要性。此外,与其他最先进的分割网络相比,我们的模型可以产生更好的分割性能,提高预测的准确性,同时降低标准偏差。这证明了我们生成精确可靠的医学图像自动分割方法的效率。我们的代码和训练有素的模型在公开发布 |
| How to make a pizza: Learning a compositional layer-based GAN model Authors Dim P. Papadopoulos, Youssef Tamaazousti, Ferda Ofli, Ingmar Weber, Antonio Torralba 食谱是用于准备特定菜肴的有序指令集。从视觉角度来看,每个指示步骤可被视为通过添加额外物体(例如,添加成分或改变现有物品的外观,例如烹饪菜肴)来改变菜肴的视觉外观的方式。在本文中,我们的目标是通过构建一个反映这一步骤程序的生成模型来教一台机器如何制作披萨。为此,我们学习了可组合模块操作,可以添加或删除特定成分。每个运营商都被设计为Generative Adversarial Network GAN。仅给出弱图像级监督,操作员被训练以生成需要添加到现有图像或从现有图像移除的视觉层。所提出的模型能够通过以正确的顺序顺序地应用相应的移除模块将图像分解成有序的层序列。合成和真实披萨图像的实验结果表明,我们提出的模型能够以弱监督的方式对披萨配料进行分割,2通过揭示它们下面的遮挡物即去除它们,即修复,并且3推断出浇头的排序而没有任何深度订购监督。代码,数据和模型可在线获取。 |
| **Detection and Tracking of Multiple Mice Using Part Proposal Networks Authors Zheheng Jiang, Zhihua Liu, Long Chen, Lei Tong, Xiangrong Zhang, Xiangyuan Lan, Danny Crookes, Ming Hsuan Yang, Huiyu Zhou 小鼠社会行为的研究越来越多地在神经科学研究中进行。然而,从相互作用小鼠的视频中自动量化小鼠行为仍然是一个具有挑战性的问题,其中物体跟踪在将小鼠定位在其生活空间中起关键作用。人工标记通常用于多个小鼠跟踪,这些小鼠是侵入性的并因此干扰动态环境中小鼠的运动。在本文中,我们提出了一种新的方法来连续跟踪几个鼠标和单个部分,而无需任何特定的标记。首先,我们提出了一种有效且稳健的基于深度学习的鼠标部分检测方案,以生成部分候选。随后,我们提出了一种新颖的贝叶斯整数线性规划模型,该模型联合地将具有必要几何约束的候选零件分配给各个目标,同时在检测到的零件之间建立成对关联。研究界没有公开的数据集,为多个小鼠的部件检测和跟踪提供定量测试平台,我们在这里介绍一个由复杂的行为和动作组成的新的具有挑战性的Multi Mice PartsTrack数据集。最后,我们针对新数据集上的几个基线评估了我们提出的方法,其结果表明我们的方法在准确性方面优于其他最先进的方法。 |
| Segment Integrated Gradients: Better attributions through regions Authors Andrei Kapishnikov, Tolga Bolukbasi, Fernanda Vi gas, Michael Terry 显着性方法可以帮助理解深度神经网络。近年来,显着性方法得到了许多改进,以及评估它们的新方法。在本文中,我们提出了一种新的基于区域的归因方法,即Segment Integrated Gradients SIG,它建立在Sundararajan等人的综合梯度上。 2017年,2介绍了用于凭经验评估基于图像质量图的质量的评估方法。性能信息曲线PICs和3为归因方法提供了基于公理的健全性检查。通过实证实验和实例结果,我们证明SIG比普通模型和ImageNet数据集的其他显着性方法产生更好的结果。 |
| Iterative Self-Learning: Semi-Supervised Improvement to Dataset Volumes and Model Accuracy Authors Robert Dupre, Jiri Fajtl, Vasileios Argyriou, Paolo Remagnin 基于简单的迭代学习循环以及学习的阈值技术和集合决策支持系统,引入了一种新颖的半监督学习技术。通过在训练深入学习的分类模型时使用未标记的数据,展示了最新的模型性能和增加的训练数据量。当评估半监督学习技术以及许多更具挑战性的图像分类数据集CIFAR 100和ImageNet的200类子集时,对常用数据集执行所提出的方法的评估。 |
| ***Scene and Environment Monitoring Using Aerial Imagery and Deep Learning Authors Mahdi Maktabdar Oghaz, Manzoor Razaak, Hamideh Kerdegari, Vasileios Argyriou, Paolo Remagnino 无人驾驶飞行器无人机是用于智能农业相关应用的有前途的技术。利用无人机对农业农场进行空中监测,可以进行与作物监测有关的关键决策。深度学习技术的进步进一步提高了基于航空影像的分析的精确性和可靠性。在无人机上安装各种传感器RGB,光谱相机的功能允许远程作物分析应用,例如植被分类和分割,作物计数,产量监测和预测,作物绘图,杂草检测,疾病和营养缺乏检测等。在为智能农业应用探索无人机的文献中发现了大量研究。本文综述了深度学习智能农业无人机图像的研究。根据应用,我们将这些研究分为五大类,包括植被识别,分类和分割,作物计数和产量预测,作物绘图,杂草检测和作物病害以及营养缺乏检测。提供了对每项研究的深入批判性分析。 |
| Attention is all you need for Videos: Self-attention based Video Summarization using Universal Transformers Authors Manjot Bilkhu, Siyang Wang, Tushar Dobhal 视频字幕和摘要近年来由于序列建模的进步而变得非常流行,随着长短期存储器网络LSTM的复苏和门控循环单元GRU的引入。现有体系结构使用CNN提取空间时间特征,并利用GRU或LSTM来模拟与软关注层的依赖关系。这些注意力层确实有助于注意最突出的特征并改进复发单元,然而,这些模型具有复发单元本身的固有缺点。 Transformer模型的引入推动了Sequence Modeling领域的新方向。在这个项目中,我们实现了一个基于变压器的视频字幕模型,利用C3N和两个流I3D等3D CNN架构进行视频提取。我们还应用某些降维技术,以便将模型的整体尺寸保持在限制范围内。我们最终分别在MSVD和ActivityNet数据集上显示单个和密集视频字幕任务的结果。 |
| ***Benchmarking 6D Object Pose Estimation for Robotics Authors Antti Hietanen, Jyrki Latokartano, Alessandro Foi, Roel Pieters, Ville Kyrki, Minna Lanz, Joni Kristian K m r inen 对机器人技术进行基准6D物体姿态估计的基准并不简单,因为足够的精度取决于许多因素,例如,所选择的抓取器,尺寸,物体的重量和材料,抓握点以及机器人任务本身。我们将问题表述为成功掌握,即对于影响任务的一组固定因素,给定姿势估计是否足以完成任务。通过在姿势误差空间中采样并执行任务并自动检测成功或失败,在概率框架中建模成功的掌握。在给定姿势残差的情况下,采样小时数和数千个样本用于构建成功掌握的非参数概率。该框架通过实验对象和装配任务进行实验验证,并比较几种基于现有技术的点云基于3D姿态估计方法。 |
| A deep learning approach for automated detection of geographic atrophy from color fundus photographs Authors Tiarnan D. Keenan, Shazia Dharssi, Yifan Peng, Qingyu Chen, Elvira Agr n, Wai T. Wong, Zhiyong Lu, Emily Y. Chew 目的评估深度学习在彩色眼底照片检测地理萎缩GA中的效用,旨在探索检测中心GA CGA的潜在用途。设计开发了一种深度学习模型来检测彩色眼底照片中GA的存在,以及另外两种在不同情况下检测CGA的模型。参与者从AREDS数据集中的4,582名参与者的纵向随访中拍摄了59,812张彩色眼底照片。金标准标签来自使用标准化协议的人类专家阅读中心评分员。方法训练深度学习模型以使用彩色眼底照片来预测从没有AMD的眼睛到晚期AMD的眼睛的GA存在。训练第二个模型以预测来自相同群体的CGA存在。训练第三个模型以用GA预测来自眼睛子集的CGA存在。对于训练和测试,使用5倍交叉验证。为了与人类临床医生的表现进行比较,将模型表现与88名视网膜专家的模型表现进行了比较。结果深度学习模型GA检测,所有眼睛的CGA检测和GA眼中心检测的AUC分别为0.933 0.976,0.939 0.976和0.827 0.888。 GA检测模型的准确度,灵敏度,特异性和精密度分别为0.965,0.692,0.978和0.584。 CGA检测模型具有0.966,0.763,0.971和0.394的等效值。中心检测模型的等效值为0.762,0.782,0.729和0.799。结论深度学习模型证明了GA自动检测的高精度。 AUC不逊于人类视网膜专家。深度学习方法也可以应用于CGA的识别。代码和预训练模型可在以下公开获得 |
| ***Coherent Point Drift Networks: Unsupervised Learning of Non-Rigid Point Set Registration Authors Lingjing Wang, Yi Fang 给定新的源和目标点集对,标准点集注册方法通常重复进行所需几何变换的独立迭代搜索,以使源点集与目标点对齐。这限制了它们在应用程序中的使用,以处理使用大容量数据集的实时点集注册。本文提出了一种新的方法,称为相干点漂移网络CPD网络,用于无监督学习几何变换到实时非刚性点集注册。与先前的努力相反,例如相干点漂移,CPD Net可以学习位移场函数以估计来自训练数据集的几何变换,从而预测用于先前未见对的对齐的期望几何变换,而无需任何额外的迭代优化过程。此外,CPD Net利用深度神经网络的功能来拟合任意函数,该函数自适应地适应所需几何变换的不同复杂程度。特别是,CPD Net被证明具有理论上的保证,可以学习连续位移矢量函数,这可以进一步避免像以前的工作那样施加额外的参数平滑约束。我们的实验验证了CPD Net在各种2D 3D数据集上非刚性点集配准的出色表现,即使存在明显的位移噪声,异常值和缺失点。我们的代码是可用的 |
| A Generative Framework for Zero-Shot Learning with Adversarial Domain Adaptation Authors Varun Khare, Divyat Mahajan, Homanga Bharadhwaj, Vinay Verma, Piyush Rai 在本文中,我们提出了一个基于领域适应的零射击学习生成框架。我们明确地针对零镜头学习ZSL中看到和看不见的类分布之间的域转移问题,并通过开发生成模型并通过对抗域适应来训练它来寻求最小化它。我们的方法基于端到端学习所见类和未见类的类分布。为了使模型能够学习看不见的类的类分布,我们根据类属性信息对这些类分布进行参数化,这些信息可用于看不见的类和看不见的类。这提供了一种非常简单的方法来学习任何看不见的类的类分布,仅给出其类属性信息,并且没有标记的训练数据。通过对抗域适应来训练该模型提供了对来自已见和未见类的数据之间的分布不匹配的鲁棒性。通过一系列全面的实验,我们表明,与各种先进的ZSL模型相比,我们的模型在各种基准数据集上都能提供更高的精度。 |
| Deep Angular Embedding and Feature Correlation Attention for Breast MRI Cancer Analysis Authors Luyang Luo, Hao Chen, Xi Wang, Qi Dou, Huangjin Lin, Juan Zhou, Gongjie Li, Pheng Ann Heng 乳腺MRI的准确和自动分析在乳腺癌的早期诊断和成功治疗计划中起着重要作用。由于异质性,肿瘤的准确诊断仍然是一项具有挑战性的任务。在本文中,我们建议通过深度学习DL的余弦边缘Sigmoid Loss CMSL在MRI中识别乳腺肿瘤,并基于所学习的特征通过COrrelation Attention Map COAM定位可能的癌症病变。 CMSL将肿瘤特征嵌入到超球面,并通过余弦约束施加决策余量。通过这种方式,DL模型可以在角度空间中学习更多可分离的类间特征和更紧凑的类内特征。此外,我们利用特征向量之间的相关性来生成注意力图,该注意力图可以仅用图像级别标签准确地定位癌症候选者。我们建立了最大的乳腺癌数据集,涉及10,290个DCE MRI扫描量,用于开发和评估所提出的方法。由CMSL驱动的模型在测试集上实现了0.855的分类准确度和0.902的AUC,灵敏度和特异性分别为0.857和0.852,总体上优于其他竞争方法。此外,与其他现有技术的弱监督定位方法相比,所提出的COAM实现了癌症中心的更准确定位。 |
| **Deep Learning based Cephalometric Landmark Identification using Landmark-dependent Multi-scale Patches Authors Chonho Lee, Chihiro Tanikawa, Jae Yeon Lim, Takashi Yamashiro 提出了一种基于深度神经网络的头影测量界标识别模型。两个神经网络,称为贴片分类和点估计,通过从日本年轻患者的935个头影图裁剪的多尺度图像块进行训练,其尺寸和方向根据正畸医生检查的界标依赖标准而变化。所提出的模型识别22个硬组织和11个软组织标志。为了评估所提出的模型,计算真实值和估计值之间的欧几里德距离误差的界标估计精度,以及使用置信椭圆估计的界标位于相应范数内的成功率。所提出的模型成功识别出1.32±3.5mm的误差范围内的硬组织界标,平均成功率为96.4,软组织界标的误差范围为1.16 4.37 mm,平均成功率为75.2。我们验证,考虑贴片的尺寸依赖性尺寸和方向有助于提高估计精度。 |
| Selfie: Self-supervised Pretraining for Image Embedding Authors Trieu H. Trinh, Minh Thang Luong, Quoc V. Le 我们介绍一种称为Selfie的预训练技术,它代表SELF监督的图像嵌入。 Selfie将掩盖语言建模的概念概括为连续数据,例如图像。给定输入图像中的蒙版补丁,我们的方法学会选择正确的补丁,以及从同一图像采样的其他干扰物补丁,以填充掩蔽的位置。该分类目标避免了预测目标补丁的精确像素值的需要。预训练架构包括卷积块网络,用于处理补丁,然后是注意力集中网络,以在预测掩码补丁之前汇总未掩码补丁的内容。在微调期间,我们重复使用预训练找到的卷积权重。我们在三个基准CIFAR 10,ImageNet 32 x 32和ImageNet 224 x 224上评估我们的方法,其中包含5到100个训练集的不同标记数据量。与同一网络的标准监督培训相比,我们的预训练方法可在所有设置中对ResNet 50进行一致的改进。值得注意的是,在ImageNet 224 x 224上,每类5个例子60个,我们的方法将ResNet 50的平均精度从35.6提高到46.7,绝对精度提高了11.1个点。我们的预训练方法还通过显着降低数据集中测试精度的标准偏差,提高了ResNet 50的训练稳定性,特别是在低数据状态下。 |
| **Key Ingredients of Self-Driving Cars Authors Rui Fan, Jianhao Jiao, Haoyang Ye, Yang Yu, Ioannis Pitas, Ming Liu 在过去的十年中,许多研究文章已经发表在自动驾驶领域。然而,它们中的大多数仅关注于特定的技术领域,例如视觉环境感知,车辆控制等。此外,由于自动驾驶汽车技术的快速发展,这些物品变得非常快速地过时。在本文中,我们简要但全面地概述了自动驾驶汽车AC的关键成分,包括驾驶自动化水平,交流传感器,交流软件,开源数据集,行业领导者,交流应用和现有挑战。 |
| **EVDodge: Embodied AI For High-Speed Dodging On A Quadrotor Using Event Cameras Authors Nitin J. Sanket, Chethan M. Parameshwara, Chahat Deep Singh, Ashwin V. Kuruttukulam, Cornelia Ferm ller, Davide Scaramuzza, Yiannis Aloimonos 人类着迷于了解像鸟类和蜜蜂这样的超高效敏捷飞行生物已推动了数十年的研究,试图解决微型空中机器人避障问题。然而,大多数先前的研究都集中在静态避障上。这是由于缺乏高速视觉传感器和可扩展的视觉算法。在过去的十年中,神经形态传感器的指数增长受到自然界的启发,并有可能成为视觉运动估计问题的事实标准。 |
| ***AutoGrow: Automatic Layer Growing in Deep Convolutional Networks Authors Wei Wen, Feng Yan, Hai Li 我们建议AutoGrow从浅层种子架构开始自动深度神经网络DNN中的深度发现,如果增长提高准确性,AutoGrow会增加新层,否则增长停止并发现网络深度。残差和普通块用作增长子模块,用于研究带有和不带有快捷方式的DNN。我们提出了通用的增长和停止策略,以尽量减少人们在最佳深度搜索上花费的精力我们的实验表明,通过将相同的策略应用于不同的任务,AutoGrow可以始终有效地发现网络深度,并在MNIST,FashionMNIST,SVHN,CIFAR10,CIFAR100和ImageNet的各种数据集上实现最先进的精确度。与通常设计巨大搜索空间并消耗巨大资源的神经架构搜索NAS相比,AutoGrow位于研究范围的另一端,专注于有效深度发现,并将增长和搜索时间缩短到与训练相似的水平。单DNN。因此,AutoGrow能够扩展到大型数据集,如ImageNet。我们的研究还表明,先前的网络态射对于增加层深度是次优的。最后,我们证明AutoGrow可以培训更深层次的普通网络,即使使用批量标准化也存在问题。 |
| Decompose-and-Integrate Learning for Multi-class Segmentation in Medical Images Authors Yizhe Zhang, Michael T. C. Ying, Danny Z. Chen 由医学专家注释的医学图像的分割图包含丰富的空间信息。在本文中,我们建议分解注释图,以学习医学图像中的分割问题的解缠结和更丰富的特征变换。我们的新计划包括两个主要阶段的分解和整合。通过注释图分解进行分解,将原始分割问题分解为多个分割子问题,这些新的分割子问题通过训练多个深度学习模块来建模,每个模块都有自己的一组特征变换。集成过程总结了前一阶段中模块的解决方案,然后为原始分段问题形成最终解决方案。提出了多种注释图分解方法,并开发了一种新的端到端可训练的K到1深度网络框架,用于实现我们提出的分解和集成学习方案。在实验中,我们使用现有技术的完全卷积网络(例如3D中的DenseVoxNet和2D中的CUMedNet)来证明我们的分解和整合分割,改善了多个3D和2D数据集上的分割性能。消融研究证实了我们提出的医学图像学习方案的有效性。 |
| Visually Grounded Neural Syntax Acquisition Authors Haoyue Shi, Jiayuan Mao, Kevin Gimpel, Karen Livescu 我们提出了视觉接地神经语法学习者VG NSL,这是一种在没有任何明确监督的情况下学习句法表征和结构的方法。该模型通过查看自然图像和阅读成对的字幕来学习。 VG NSL生成文本的选区解析树,递归地组成成分的表示,并将它们与图像匹配。我们通过与图像的匹配分数来定义成分的具体性,并使用它来指导文本的解析。在MSCOCO数据集上的实验表明,就针对金解析树的F1分数而言,VG NSL优于不使用视觉基础的各种无监督解析方法。我们发现VGNSL在随机初始化的选择和训练数据量方面更加稳定。我们还发现VG NSL获得的具体性与语言学家定义的类似度量相关。最后,我们还在Multi30K数据集中将VG NSL应用于多种语言,表明我们的模型始终优于先前的无监督方法。 |
| V-NAS: Neural Architecture Search for Volumetric Medical Image Segmentation Authors Zhuotun Zhu, Chenxi Liu, Dong Yang, Alan Yuille, Daguang Xu 深度学习算法,特别是2D和3D完全卷积神经网络FCN,已迅速成为体积医学图像分割的主流方法。然而,2D卷积不能充分利用沿第三轴的丰富空间信息,而3D卷积遭受要求苛刻的计算和高GPU内存消耗。在本文中,我们建议自动搜索网络架构定制到体积医学图像分割问题。具体地说,我们将结构学习公式化为可微分神经结构搜索,让网络本身在每层选择2D,3D或Pseudo 3D P3D卷积。我们在3个公共数据集上评估我们的方法,即NIH Pancreas数据集,来自Medical Segmentation Decathlon MSD Challenge的Lung and Pancreas数据集。我们的方法,名为V NAS,在正常器官NIH胰腺和异常器官MSD肺肿瘤和MSD胰腺肿瘤的分割任务方面始终优于其他现有技术,这显示了所选结构的力量。此外,一个数据集上的搜索结构可以很好地推广到其他数据集,这证明了我们提出的方法的鲁棒性和实际应用。 |
| Chinese Abs From Machine Translation |


 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}