
【今日CV 视觉论文速览】30 Nov 2018
今日CS.CV计算机视觉论文速览
Fri, 30 Nov 2018
Totally 62 papers

Interesting:
-
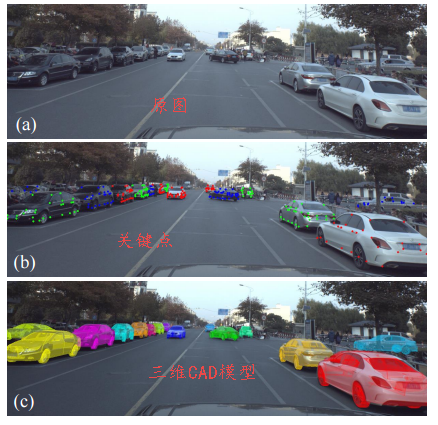
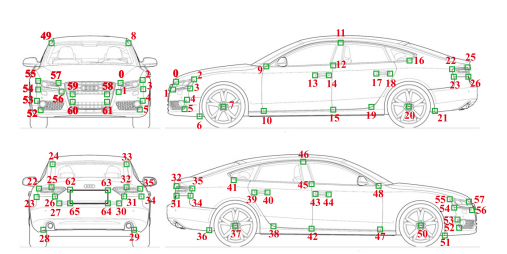
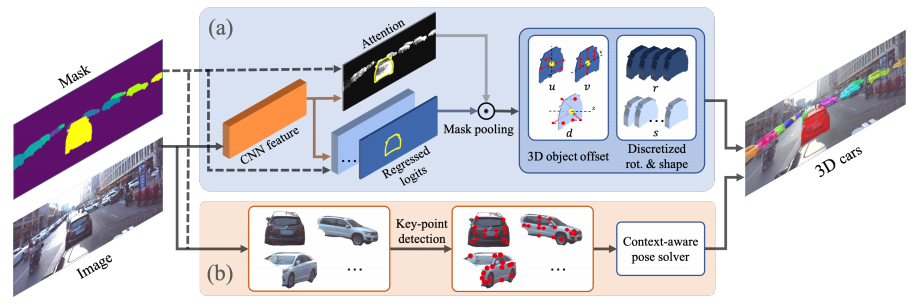
百度提出大规模三维汽车数据集ApolloCar3D,包括了5277张形式图片和60k汽车实例,最重要的是为每辆车提供了精确的语义标签关键点和工业级的CAD模型。每辆车包含了65个关键点标签。(from baidu et.al)
车也有自己的关键点了:
benchmark 流程图
-
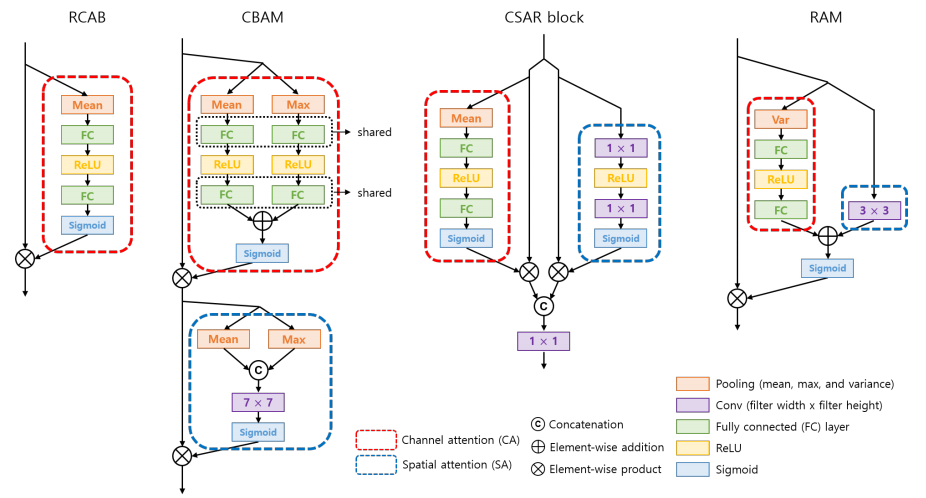
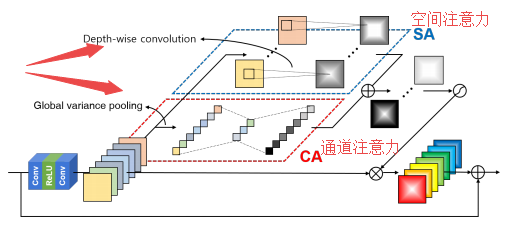
基于残差注意力机制的Residual Attention Module图像超分辨,利用基于通道/空间注意力机制优化了超分辨率方法,提出了基于残差注意力模块的超分辨方法。(from 韩国延世大学)
本文提出的方法SRRAM
-
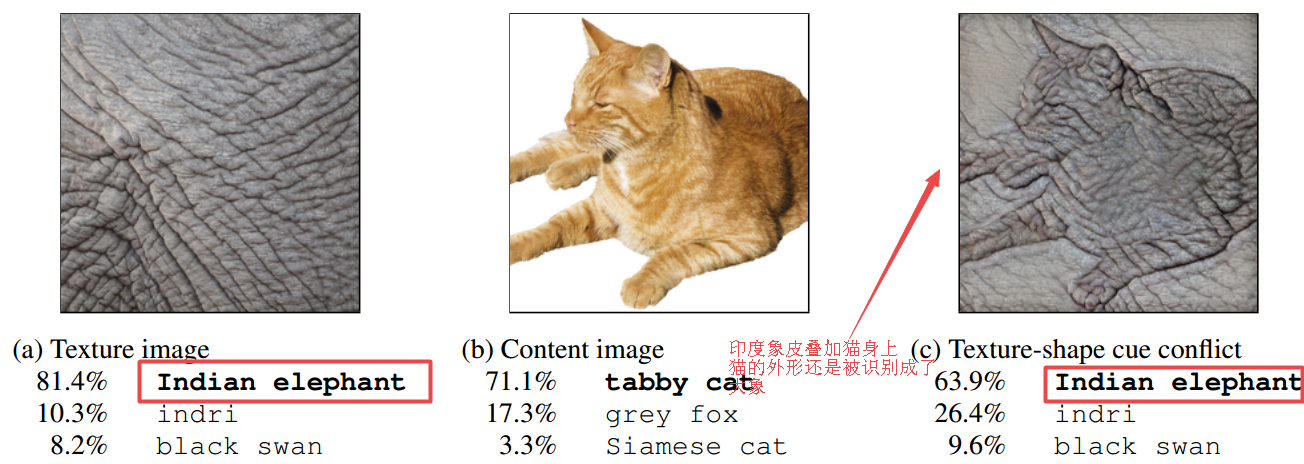
纹理对于CNN识别物体比外形更重要?!通过风格化StylizedImageNet数据集训练可以提高其识别物体外形的能力,增加鲁棒性!(from 图宾根大学)
styleImageNet训练后增强对于形状的辨别能力:
-
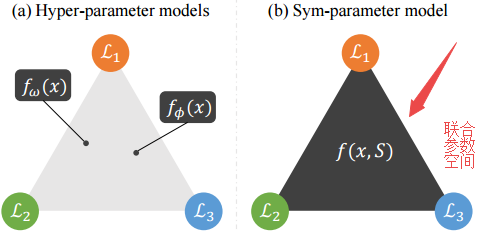
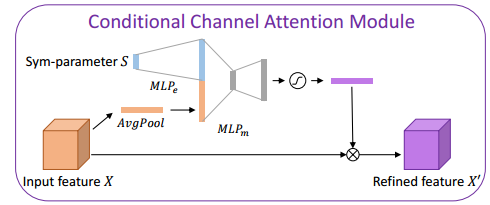
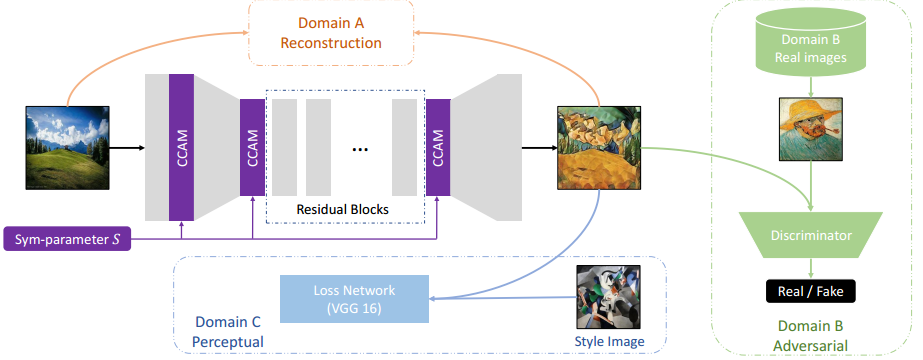
SGN 提出了一种可以结合多个域特征的方法来风格化图像。通过引入联合参数(sym-paramter)来混合不同的损失来合成,并基于此提出了SGN 实现多种损失函数联合,得到可控的参数空间,已生成不同的风格图像 (from 首尔大学 三星):
联合参数参数空间sym-parameters和条件通道注意力模块CCAM:
本文提出的风格化模型,综合了三种不同的损失:
生成器损失包含了重建损失、对抗损失和感官损失
通过控制S参数实现不同成分比例的的风格输出:
-
InverseRenderNet从单张图片中学习逆渲染问题,估计出反射率、法向量、光照和明暗图 (from 纽约大学)
网络结构:




 网络结构:
网络结构: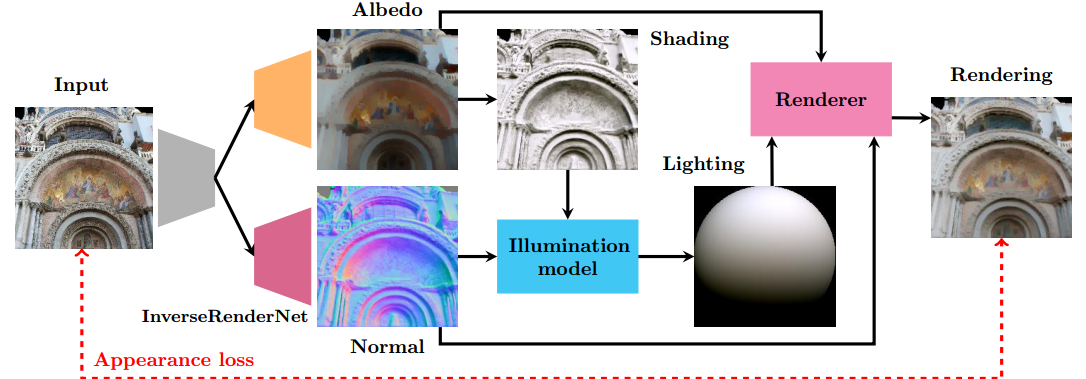
Daily Computer Vision Papers
[1] Title: Diverse Image Synthesis from Semantic Layouts via Conditional IMLE
Authors:Ke Li, Tianhao Zhang, Jitendra Malik
[2] Title: Image Translation to Mixed-Domain using Sym-Parameterized Generative Network
Authors:Simyung Chang, SeongUk Park, John Yang, Nojun Kwak
[3] Title: Touchdown: Natural Language Navigation and Spatial Reasoning in Visual Street Environments
Authors:Howard Chen, Alane Shur, Dipendra Misra, Noah Snavely, Yoav Artzi
[4] Title: InverseRenderNet: Learning single image inverse rendering
Authors:Ye Yu, William A. P. Smith
[5] Title: Iterative Projection and Matching: Finding Structure-preserving Representatives and Its Application to Computer Vision
Authors:Mohsen Joneidi, Alireza Zaeemzadeh, Nazanin Rahnavard, Mubarak Shah
[6] Title: Incremental Scene Synthesis
Authors:Benjamin Planche, Xuejian Rong, Ziyan Wu, Srikrishna Karanam, Harald Kosch, YingLi Tian, Andreas Hutter, Jan Ernst
[7] Title: Face Detection in the Operating Room: Comparison of State-of-the-art Methods and a Self-supervised Approach
Authors:Thibaut Issenhuth, Vinkle Srivastav, Afshin Gangi, Nicolas Padoy
[8] Title: Discovering Spatio-Temporal Action Tubes
Authors:Yuancheng Ye, Xiaodong Yang, Yingli Tian
[9] Title: ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness
Authors:Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, Wieland Brendel
[10] Title: ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
Authors:Xibin Song, Peng Wang, Dingfu Zhou, Rui Zhu, Chenye Guan, Yuchao Dai, Hao Su, Hongdong Li, Ruigang Yang
[11] Title: Iterative Residual CNNs for Burst Photography Applications
Authors:Filippos Kokkinos, Stamatios Lefkimmiatis
[12] Title: Efficient Coarse-to-Fine Non-Local Module for the Detection of Small Objects
Authors:Hila Levi, Shimon Ullman
[13] Title: Parameter-Free Spatial Attention Network for Person Re-Identification
Authors:Haoran Wang, Yue Fan, Zexin Wang, Licheng Jiao, Bernt Schiele
[14] Title: Two-level Attention with Two-stage Multi-task Learning for Facial Emotion Recognition
Authors:Xiaohua Wang, Muzi Peng, Lijuan Pan, Min Hu, Chunhua Jin, Fuji Ren
[15] Title: Bootstrapping Deep Neural Networks from Image Processing and Computer Vision Pipelines
Authors:Kilho Son, Jesse Hostetler, Sek Chai
[16] Title: Towards Human-Friendly Referring Expression Generation
Authors:Mikihiro Tanaka, Takayuki Itamochi, Kenichi Narioka, Ikuro Sato, Yoshitaka Ushiku, Tatsuya Harada
[17] Title: Networks for Nonlinear Diffusion Problems in Imaging
Authors:Simon Arridge, Andreas Hauptmann
[18] Title: Progressive Recurrent Learning for Visual Recognition
Authors:Xutong Ren, Lingxi Xie, Chen Wei, Siyuan Qiao, Chi Su, Jiaying Liu, Alan L. Yuille
[19] Title: RAM: Residual Attention Module for Single Image Super-Resolution
Authors:Jun-Hyuk Kim, Jun-Ho Choi, Manri Cheon, Jong-Seok Lee
[20] Title: EV-SegNet: Semantic Segmentation for Event-based Cameras
Authors:Iñigo Alonso, Ana C. Murillo
[21] Title: Utilizing Complex-valued Network for Learning to Compare Image Patches
Authors:Siwen Jiang, Wenxuan Wei, Shihao Guo, Hongguang Fu, Lei Huang
[22] Title: Grid R-CNN
Authors:Xin Lu, Buyu Li, Yuxin Yue, Quanquan Li, Junjie Yan
[23] Title: Attacks on State-of-the-Art Face Recognition using Attentional Adversarial Attack Generative Network
Authors:Qing Song, Yingqi Wu, Lu Yang
[24] Title: 3D Shape Reconstruction from a Single 2D Image via 2D-3D Self-Consistency
Authors:Yi-Lun Liao, Yao-Cheng Yang, Yu-Chiang Frank Wang
[25] Title: Generalized Graph Convolutional Networks for Skeleton-based Action Recognition
Authors:Xiang Gao, Wei Hu, Jiaxiang Tang, Pan Pan, Jiaying Liu, Zongming Guo
[26] Title: Efficient Semantic Segmentation for Visual Bird’s-eye View Interpretation
Authors:Timo Sämann, Karl Amende, Stefan Milz, Christian Witt, Martin Simon, Johannes Petzold
[27] Title: Global Second-order Pooling Neural Networks
Authors:Zilin Gao, Jiangtao Xie, Qilong Wang, Peihua Li
[28] Title: Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose
Authors:Daniil Osokin
[29] Title: Hand Gesture Detection and Conversion to Speech and Text
Authors:K. Manikandan, Ayush Patidar, Pallav Walia, Aneek Barman Roy
[30] Title: Effective, Fast, and Memory-Efficient Compressed Multi-function Convolutional Neural Networks for More Accurate Medical Image Classification
Authors:Luna M. Zhang
[31] Title: Shape-conditioned Image Generation by Learning Latent Appearance Representation from Unpaired Data
Authors:Yutaro Miyauchi, Yusuke Sugano, Yasuyuki Matsushita
[32] Title: Weakly Supervised Silhouette-based Semantic Change Detection
Authors:Ken Sakurada
[33] Title: Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Authors:Hadi Kazemi, Sobhan Soleymani, Fariborz Taherkhani, Seyed Mehdi Iranmanesh, Nasser M. Nasrabadi
[34] Title: DuLa-Net: A Dual-Projection Network for Estimating Room Layouts from a Single RGB Panorama
Authors:Shang-Ta Yang, Fu-En Wang, Chi-Han Peng, Peter Wonka, Min Sun, Hung-Kuo Chu
[35] Title: Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
Authors:Yaadhav Raaj, Haroon Idrees, Gines Hidalgo, Yaser Sheikh
[36] Title: Simple stopping criteria for information theoretic feature selection
Authors:Shujian Yu, Jose C. Principe
[37] Title: Traffic Danger Recognition With Surveillance Cameras Without Training Data
Authors:Lijun Yu, Dawei Zhang, Xiangqun Chen, Alexander Hauptmann
[38] Title: ADCrowdNet: An Attention-injective Deformable Convolutional Network for Crowd Understanding
Authors:Ning Liu, Yongchao Long, Changqing Zou, Qun Niu, Li Pan, Hefeng Wu
[39] Title: Visual SLAM with Network Uncertainty Informed Feature Selection
Authors:Pranav Ganti, Steven L. Waslander
[40] Title: Automatic Rendering of Building Floor Plan Images from Textual Descriptions in English
Authors:Mahak Jain, Anurag Sanyal, Shreya Goyal, Chiranjoy Chattopadhyay, Gaurav Bhatnagar
[41] Title: Optimizable Object Reconstruction from a Single View
Authors:Kejie Li, Ravi Garg, Ming Cai, Ian Reid
[42] Title: Visual Question Answering as Reading Comprehension
Authors:Hui Li, Peng Wang, Chunhua Shen, Anton van den Hengel
[43] Title: Adversarial Attacks for Optical Flow-Based Action Recognition Classifiers
Authors:Nathan Inkawhich, Matthew Inkawhich, Yiran Chen, Hai Li
[44] Title: Guided patch-wise nonlocal SAR despeckling
Authors:Sergio Vitale, Davide Cozzolino, Giuseppe Scarpa, Luisa Verdoliva, Giovanni Poggi
[45] Title: Joint Correction of Attenuation and Scatter Using Deep Convolutional Neural Networks (DCNN) for Time-of-Flight PET
Authors:Jaewon Yang, Dookun Park, Jae Ho Sohn, Zhen Jane Wang, Grant T. Gullberg, Youngho Seo
[46] Title: Non-Volume Preserving-based Feature Fusion Approach to Group-Level Expression Recognition on Crowd Videos
Authors:Kha Gia Quach, Ngan Le, Khoa Luu, Chi Nhan Duong, Ibsa Jalata, Karl Ricanek
[47] Title: Deep learning based automatic segmentation of lumbosacral nerves on non-contrast CT for radiographic evaluation: a pilot study
Authors:Guoxin Fan, Huaqing Liu, Zhenhua Wu, Yufeng Li, Chaobo Feng, Dongdong Wang, Jie Luo, Xiaofei Guan, William M. Wells III, Shisheng He
[48] Title: Semantic Part Detection via Matching: Learning to Generalize to Novel Viewpoints from Limited Training Data
Authors:Yutong Bai, Qing Liu, Lingxi Xie, Yan Zheng, Weichao Qiu, Alan Yuille
[49] Title: Unsupervised Meta-Learning For Few-Shot Image and Video Classification
Authors:Siavash Khodadadeh, Ladislau Bölöni, Mubarak Shah
[50] Title: 2D/3D Megavoltage Image Registration Using Convolutional Neural Networks
Authors:Hector N. B. Pinheiro, Tsang Ing Ren, Stefan Scheib, Armel Rosselet, Stefan Thieme-Marti
[51] Title: Phase Collaborative Network for Multi-Phase Medical Imaging Segmentation
Authors:Huangjie Zheng, Lingxi Xie, Tianwei Ni, Ya Zhang, Yan-Feng Wang, Qi Tian, Elliot K. Fishman, Alan L. Yuille
[52] Title: Cartoon-to-real: An Approach to Translate Cartoon to Realistic Images using GAN
Authors:K M Arefeen Sultan, Labiba Kanij Rupty, Nahidul Islam Pranto, Sayed Khan Shuvo, Mohammad Imrul Jubair
[53] Title: Meta-Learning for Few-shot Camera-Adaptive Color Constancy
Authors:Steven McDonagh, Sarah Parisot, Zhenguo Li, Gregory Slabaugh
[54] Title: Learning to Synthesize Motion Blur
Authors:Tim Brooks, Jonathan T. Barron
[55] Title: On the Implicit Assumptions of GANs
Authors:Ke Li, Jitendra Malik
[56] Title: Perceiving Physical Equation by Observing Visual Scenarios
Authors:Siyu Huang, Zhi-Qi Cheng, Xi Li, Xiao Wu, Zhongfei Zhang, Alexander Hauptmann
[57] Title: Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs
Authors:Kazuki Osawa, Yohei Tsuji, Yuichiro Ueno, Akira Naruse, Rio Yokota, Satoshi Matsuoka
[58] Title: Deep learning for pedestrians: backpropagation in CNNs
Authors:Laurent Boué
[59] Title: Variational Autoencoding the Lagrangian Trajectories of Particles in a Combustion System
Authors:Pai Liu, Jingwei Gan, Rajan K. Chakrabarty
[60] Title: RetinaMatch: Efficient Template Matching of Retina Images for Teleophthalmology
Authors:Chen Gong, N. Benjamin Erichson, John P. Kelly, Laura Trutoiu, Brian T. Schowengerdt, Steven L. Brunton, Eric J. Seibel
[61] Title: Towards Task Understanding in Visual Settings
Authors:Sebastin Santy, Wazeer Zulfikar, Rishabh Mehrotra, Emine Yilmaz
[62] Title: Unrepresentative video data: A review and evaluation
Authors:Georgios Mastorakis


 浙公网安备 33010602011771号
浙公网安备 33010602011771号