
【今日CV 视觉论文速览】14 Nov 2018
今日CS.CV计算机视觉论文速览
Wed, 14 Nov 2018
Totally 25 papers

Daily Computer Vision Papers
[1] Title: Fast Human Pose Estimation
Authors:Feng Zhang, Xiatian Zhu, Mao Ye
[2] Title: Home Activity Monitoring using Low Resolution Infrared Sensor
Authors:Lili Tao, Timothy Volonakis, Bo Tan, Yanguo Jing, Kevin Chetty, Melvyn Smith
[3] Title: Detect or Track: Towards Cost-Effective Video Object Detection/Tracking
Authors:Hao Luo, Wenxuan Xie, Xinggang Wang, Wenjun Zeng
[4] Title: Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Authors:Fu-En Wang, Hou-Ning Hu, Hsien-Tzu Cheng, Juan-Ting Lin, Shang-Ta Yang, Meng-Li Shih, Hung-Kuo Chu, Min Sun
[5] Title: Pose Invariant 3D Face Reconstruction
Authors:Lei Jiang, XiaoJun Wu, Josef Kittler
[6] Title: Deep Neural Network Concepts for Background Subtraction: A Systematic Review and Comparative Evaluation
Authors:Thierry Bouwmans, Sajid Javed, Maryam Sultana, Soon Ki Jung
[7] Title: Image Captioning Based on a Hierarchical Attention Mechanism and Policy Gradient Optimization
Authors:Shiyang Yan, Fangyu Wu, Jeremy S. Smith, Wenjin Lu, Bailing Zhang
[8] Title: BAN: Focusing on Boundary Context for Object Detection
Authors:Yonghyun Kim, Taewook Kim, Bong-Nam Kang, Jieun Kim, Daijin Kim
[9] Title: Gradient Harmonized Single-stage Detector
Authors:Buyu Li, Yu Liu, Xiaogang Wang
[10] Title: Child Gender Determination with Convolutional Neural Networks on Hand Radio-Graphs
Authors:Mumtaz A. Kaloi, Kun He
[11] Title: Vehicle Re-identification Using Quadruple Directional Deep Learning Features
Authors:Jianqing Zhu, Huanqiang Zeng, Jingchang Huang, Shengcai Liao, Zhen Lei, Canhui Cai, LiXin Zheng
[12] Title: Application of Faster R-CNN model on Human Running Pattern Recognition
Authors:Kairan Yang, Feng Geng
[13] Title: Exploiting temporal and depth information for multi-frame face anti-spoofing
Authors:Zezheng Wang, Chenxu Zhao, Yunxiao Qin, Qiusheng Zhou, Zhen Lei
[14] Title: LookinGood: Enhancing Performance Capture with Real-time Neural Re-Rendering
Authors:Ricardo Martin-Brualla, Rohit Pandey, Shuoran Yang, Pavel Pidlypenskyi, Jonathan Taylor, Julien Valentin, Sameh Khamis, Philip Davidson, Anastasia Tkach, Peter Lincoln, Adarsh Kowdle, Christoph Rhemann, Dan B Goldman, Cem Keskin, Steve Seitz, Shahram Izadi, Sean Fanello
[15] Title: Generating faces for affect analysis
Authors:Dimitrios Kollias, Shiyang Cheng, Evangelos Ververas, Irene Kotsia, Stefanos Zafeiriou
[16] Title: NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification
Authors:Rongcheng Lin, Jing Xiao, Jianping Fan
[17] Title: Blindfold Baselines for Embodied QA
Authors:Ankesh Anand, Eugene Belilovsky, Kyle Kastner, Hugo Larochelle, Aaron Courville
[18] Title: A new approach for pedestrian density estimation using moving sensors and computer vision
Authors:Eric K. Tokuda, Yitzchak Lockerman, Gabriel B. A. Ferreira, Ethan Sorrelgreen, David Boyle, Roberto M. Cesar-Jr., Claudio T. Silva
[19] Title: OriNet: A Fully Convolutional Network for 3D Human Pose Estimation
Authors:Chenxu Luo, Xiao Chu, Alan Yuille
[20] Title: Deep Object Centric Policies for Autonomous Driving
Authors:Dequan Wang, Coline Devin, Qi-Zhi Cai, Fisher Yu, Trevor Darrell
[21] Title: Hallucinating Point Cloud into 3D Sculptural Object
Authors:Chun-Liang Li, Eunsu Kang, Songwei Ge, Lingyao Zhang, Austin Dill, Manzil Zaheer, Barnabas Poczos
[22] Title: Improved Fourier Mellin Invariant for Robust Rotation Estimation with Omni-cameras
Authors:Qingwen Xu, Arturo Gomez Chavez, Heiko Buelow, Andreas Birk, Soeren Schwertfeger
[23] Title: Distributionally Robust Semi-Supervised Learning for People-Centric Sensing
Authors:Kaixuan Chen, Lina Yao, Dalin Zhang, Xiaojun Chang, Guodong Long, Sen Wang
[24] Title: Modality Attention for End-to-End Audio-visual Speech Recognition
Authors:Pan Zhou, Wenwen Yang, Wei Chen, Yanfeng Wang, Jia Jia
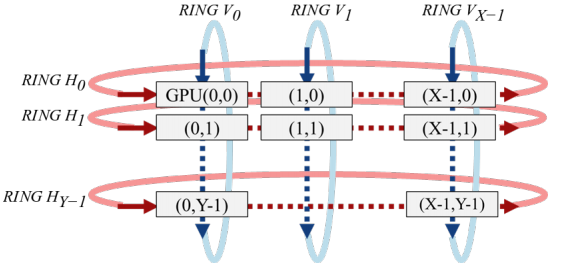
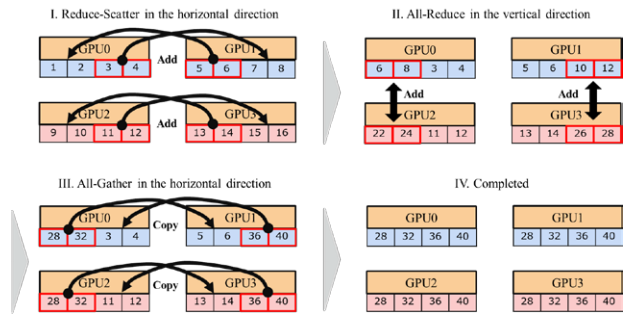
[25] Title: ImageNet/ResNet-50 Training in 224 Seconds
Authors:Hiroaki Mikami, Hisahiro Suganuma, Pongsakorn U-chupala, Yoshiki Tanaka, Yuichi Kageyama
Interesting:
ImageNet/ResNet-50 Training in 224 Seconds
利用2176 Tesla V100 GPUs在
224s内训练完ResNet-50,达到75.03%的精度;
在1088 Tesla V100 GPUs上达到90%的效率;
使用了索尼研发的工具包nnabla;
在ABCI(AI Bridging Cloud InfrastructureAI Briding Cloud Infrastructure)完成这一工作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号