python垃圾回收
引言
- 引用计数
- 标记清除
- 分代回收
python的垃圾回收,以引用计数为主,标记清除和分代回收为辅
1.引用计数
1.1环状双向链表refchain
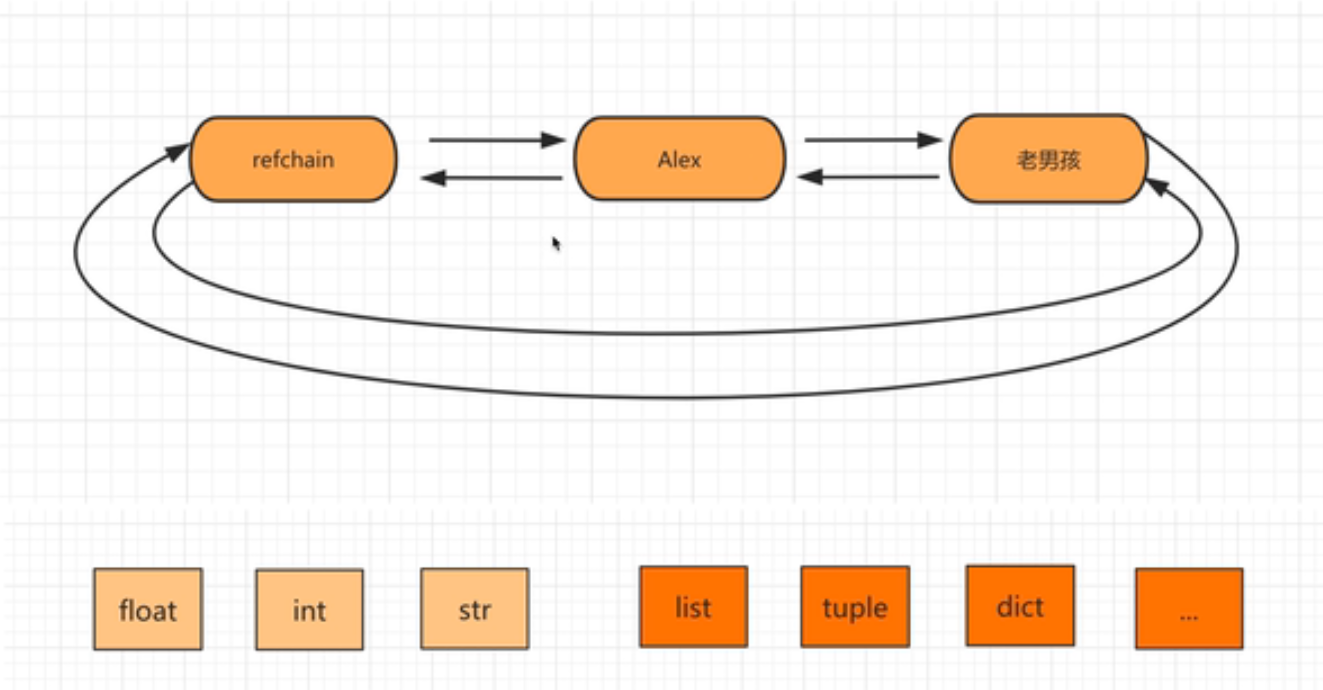
在python程序中创建的任何对象都会放在refchain链表中
name = "灵感" age = 18 hobby =["爬山","跑步"]
注意
内部会创建一些数据 [上一个对象,下一个对象,类型,引用个数 ] name = "灵感" wind =name # 此时引用的个数变成了2
age = 18
内部会创建一些数据 [上一个对象,下一个对象,类型,引用个数,value=18 ]
hobby =["爬山","跑步"]
内部会创建一些数据 [上一个对象,下一个对象,类型,引用个数,items=元素,元素的个数 ]
底层C语言
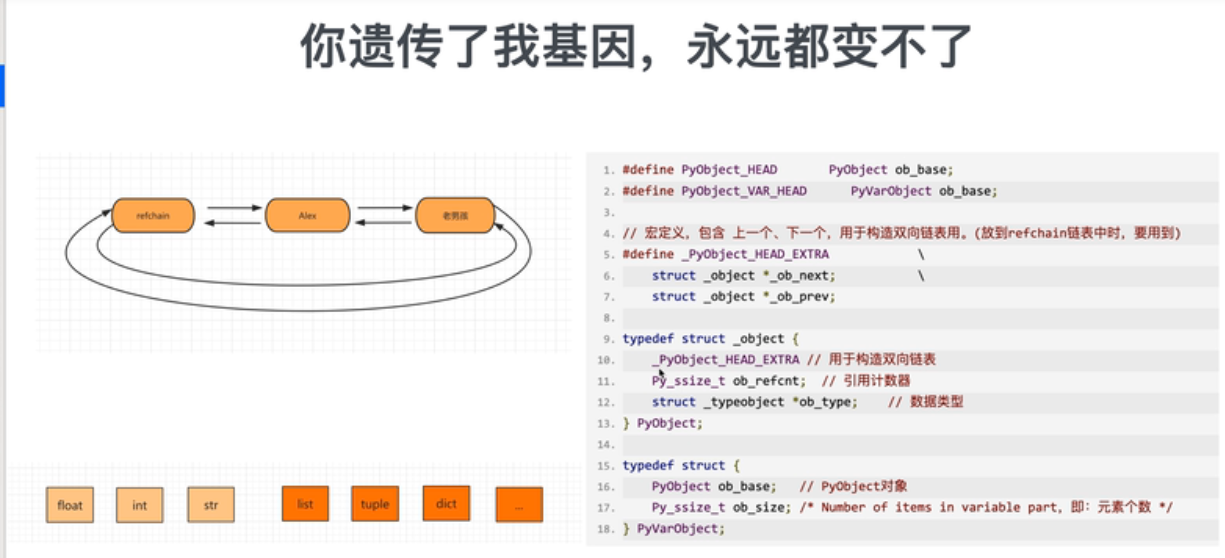
C源码的结构体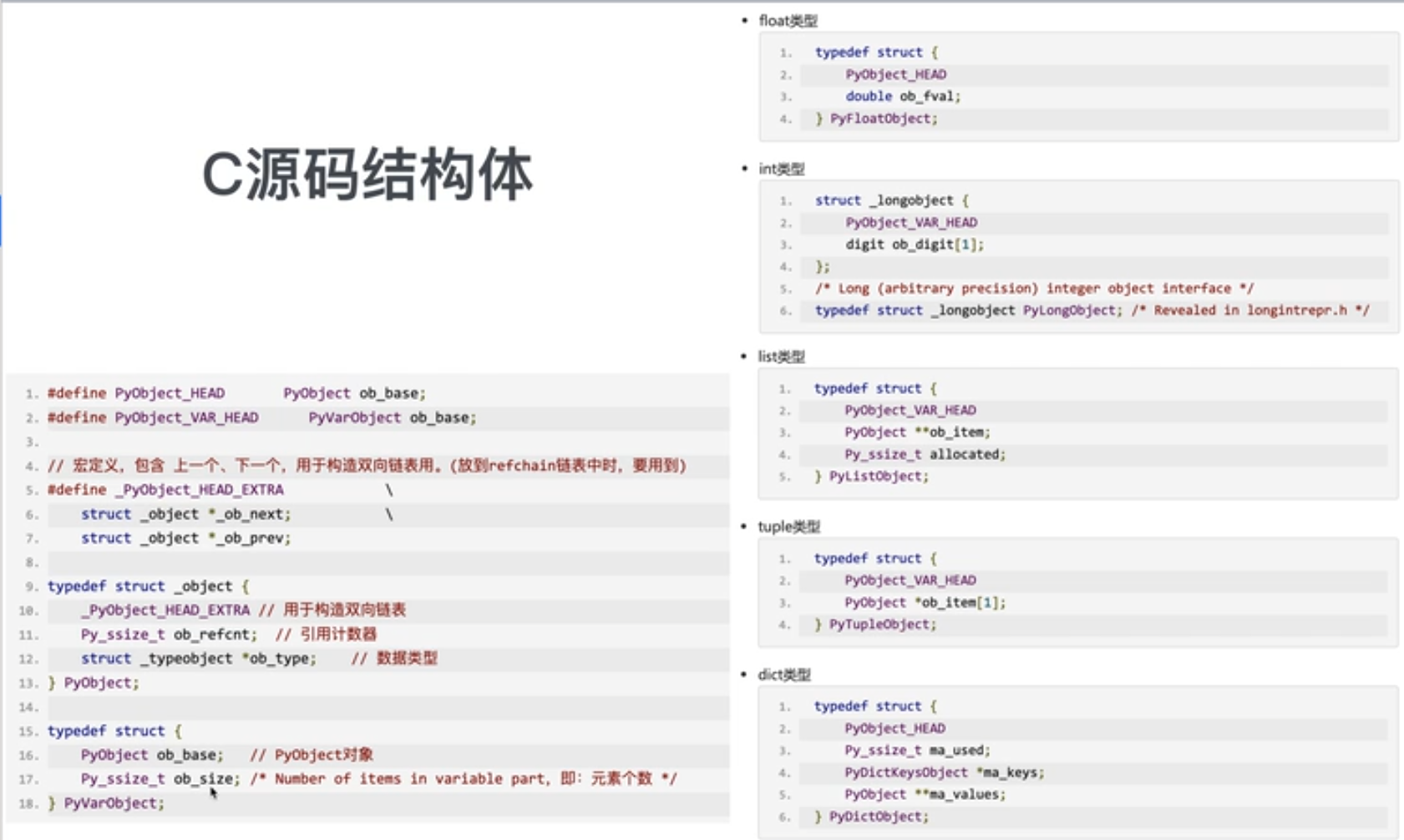
实例
s1 = 1 s2 = 3.14 s3 = [1,2,3]
当python程序运行时,会根据数据类型的不同找到其对应的结构体.根据结构体中的字段来创建相关的数据,
然后将对象添加到refchain双线链表中
在C源码中有两个关键的结构体:PyObject , PyVarObject
每个对象中有ob_refcnt就是引用计数器,值默认为1,当有其他变量引用对象时,引用计数器就会发生变化
引用
a = 灵感 b = a
此时引用计数器为2
删除引用
a = 灵感 b = a del b # b变量删除,b对应对象引用计数器-1 del a # a变量删除,a对应对象引用计数器-1
注意:
当一个对象的引用计数器为0时,意味着没有人再使用这个对象了,python解释器就会认为这个对象变成了垃圾,就要垃圾回收掉.
垃圾回收:
- 对象从refchain链表移除
- 对象被销毁,内存归还
以上基本可以解决了python的垃圾回收,但是还有一些特殊的情况
循环引用 & 交叉感染
lst1 = [1,2,3] #refchain中创建一个列表对象,因ls1=对象,所以列表对象引用计数为1 lst2 = [4,5,6]#refchain中创建一个列表对象,因ls2=对象,所以列表对象引用计数为1 ls1.append(lst2) # 把lst2追加到lst1中,则lst2对应的[4,5,6]对象的引用计数器加1,最终为2 lst2.append(lst1)# 把lst1追加到lst2中,则lst1对应的[1,2,3]对象的引用计数器加1,最终为2 del lst1 # 引用计数器-1 del lst2 # 引用计数器-1
以上会导致数据对象常驻内存,永远不会消耗,这样代码如果多了,内存一点点就被吃掉,数据对象没有被及时销毁,最终导致内存泄漏
我们通过标记清除来解决上面的问题!
2.标记清除
它的底层通过2个链表来解决循环引用的这个问题
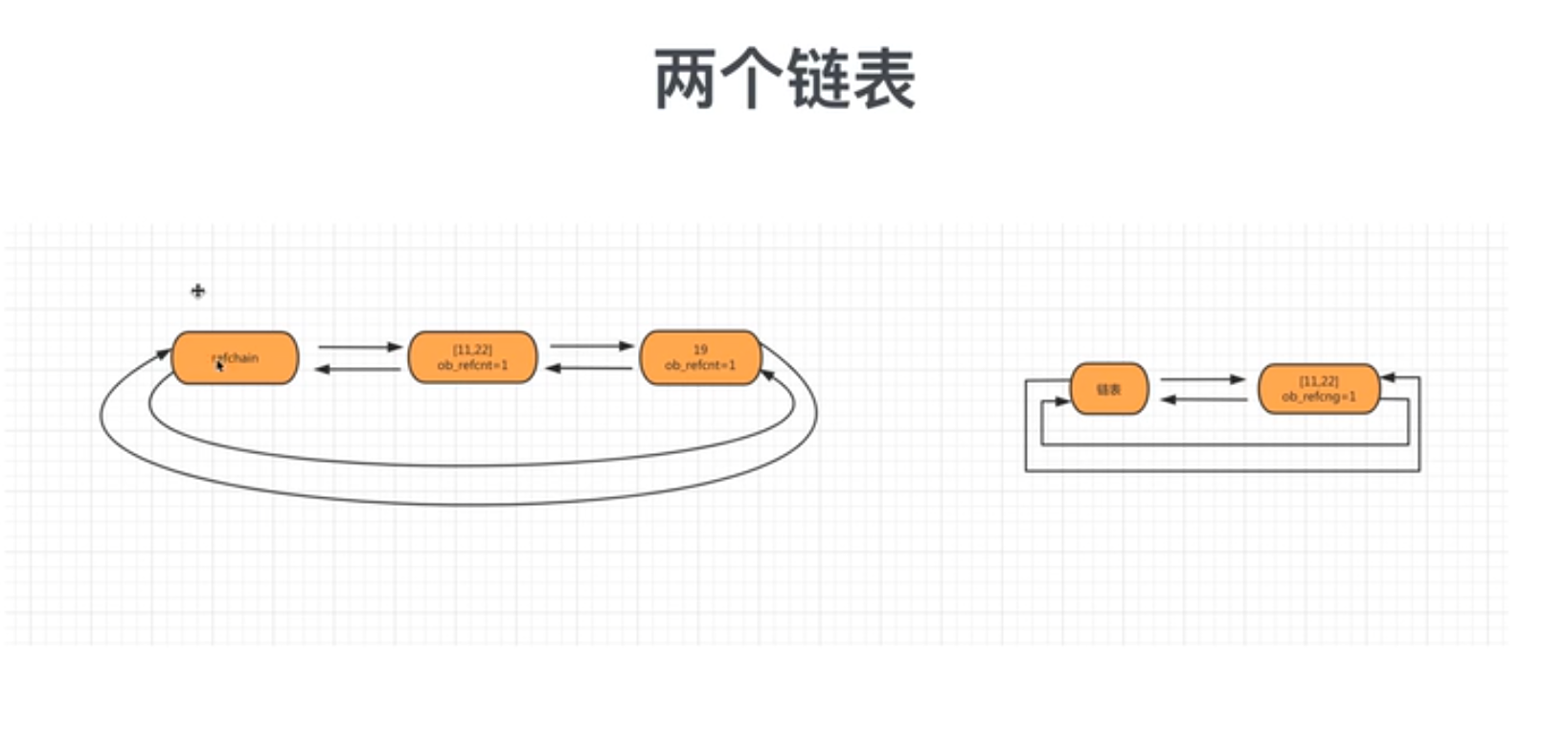
目的:
-
为了解决循环引用的这个问题
实现:
-
在python的底层再维护一个链表,这个链表中专门放那些可能存在循环引用的对象.比如(list/dict/set/tuple)
-
在python的内部,某种情况下触发,会去全量扫描,可能存在循环引用的链表中的每个元素
-
如果扫描到,让双方的引用计数器-1,如果引用计数器变成0,则垃圾回收,如果还没变成0,证明这个数据还在使用
思考问题:
-
什么时候扫描?
-
链表数据非常大,扫描的代价大不大,多久扫描一次?
3.分代回收
四个链表搞定一切
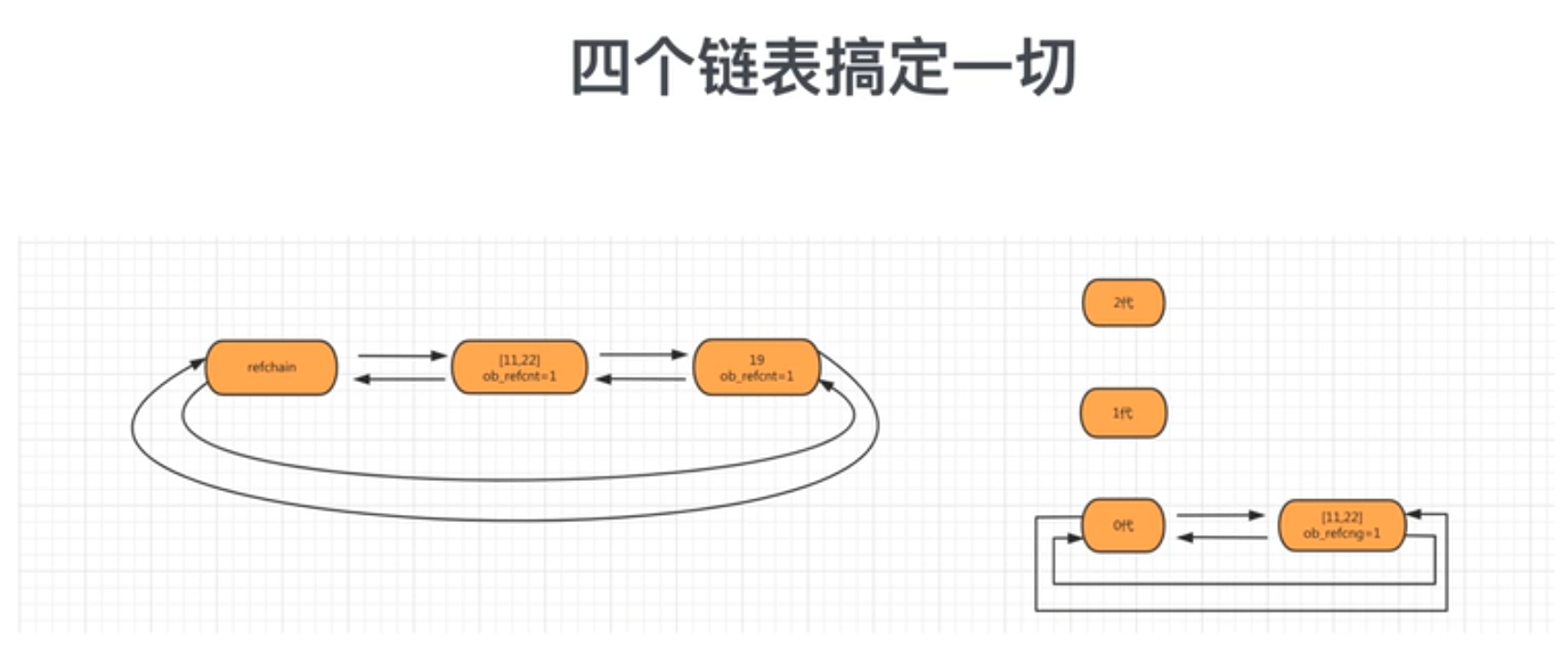
看图
lst = [11,22] 首先,我定义lst=[11,22],这个数据对象会放在refchain链表中,同时这个数据对象会同步0代这个链表中
当0代这个链表数据对象达到700个会扫描一次,如果有循环引用的情况,引用计数器就-1,有垃圾就回收掉 如果不是垃圾,就把数据添加到1代链表中,此时0代链表中就没有数据了 1代链表中会存储这些数据,同时记录0代链表扫描次数,当前扫描了1次 当0代链表扫描了10次,1代链表才开始扫描 1代链表扫描10次时,会把数据传给2代链表 2代链表存储1代链表传过来的数据,同时记录1代链表扫描次数
幻想毫无价值,计划渺如尘埃,目标不可能达到。这一切的一切毫无意义——除非我们付诸行动。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号