需要掌握的知识
网络编程相关问题
1.进程间如何通信?
队列 ,管道
2.解释什么是异步非阻塞?
异步:两个任务之间没有明确的相互关系,各自执行
非阻塞:在主程序中没有等待的操作,所有的等待都会被异步出去
3.路由器和交换机的区别?
交换机是工作中局域网内
路由器是工作局域网和局域网之外
4.什么是域名解析?
把域名指向网站的空间ip,让人们能通过注册域名,就可以方便访问一个网站,又称DNS解析
5.如何修改本地hosts文件?
hosts是域名解析的第一步,先从host上面找,找不到在从DNS上面找
生产者与消费者模型应用场景?
爬虫,高并发的应用程序
什么是cdn?
内容分发网络,将用户访问指向工作最近的缓存服务器,由缓存服务器直接响应用户请求
对于CPU密集型怎么使用多线程,说说线程池,线程锁的用法,有没有用过multiprocessing或concurrent.future?
开一个进程,在进程中使用线程
concurrent.future 开线程池
如果一个线程不用线程锁,如果由多个线程在使用同一份数据就要用线程锁
线程里面由两种锁,一种是递归锁,一种互斥锁
互斥锁,要比递归锁性能高,尽量选择互斥锁,但要避免死锁
只有两把互斥锁出现同一个线程里面,就要考虑出现死锁的情况
concurrent.future 提供了线程池和进程池
死锁
多个线程 多把锁 交替acquire
gevent 模块是什么
就是协程
什么是Nginx?
轻量级负载均衡,它的性能并没有那么高,支持http协议,邮件相关协议
什么是负载均衡?
目前市面上都是用的软件级别的,硬件级别的非常的贵
什么是rpc及应用场景?
远程过程调用,解决分布式系统之间服务之间的相互调用,使得远程调用像本地一样方便
什么是正向代理和反向代理?
用户端就是正向代理,服务端是反向代理
csv文件【erotic.csv】中共存在271万多条数据,请获取其中的subscription_id,并使用线程池为每100条数据创建一个线程去处理(打印或通过爬虫去提交到某处),erotic.csv文件格式为:
"subscription_id","erotic","num"
"UCURGHWsDe7S-v1ufCAq9Rfw","5","1"
开一个线程专门读,往一个队列里扔,我的所有线程池其他线程,从队列里面取100条数据就结束,
for 循环 rang(100),从队列里面get,取到每条数据可以insert 插入到数据库中4
简述事务及其特性?
原子性(数据不可拆分),
一致性(保证数据的一致性),
隔离性(一个任务处理事务,其它任务不能处理),
持久性(一旦更改了,就永远的更改了)
数据库相关
简述触发器,函数,视图,存储过程?
触发器就是当你执行某一个操作的时候,比如说我之间insert的时候,我就触发一个其他的事件
假设我由2个表一个a表,一个b表,我往a插入数据的时候,触发b表同时插入数据
函数:sum count max min 或者自定义函数,取出所有的基数,偶数等
视图:我建立一个复杂的联表关系,一旦执行这个视图,相当于这个联表关系直接帮我写出来了,不需要自己写复杂的sql取拼了
存储过程:把多条sql语句写到整个一个过程里,一旦调用这个过程,就执行这N条sql语句,优化和编译的时间都省了
索引在什么情况下遵循最左前缀的规则?
1.联合索引的情况下 2.建立条件时候,查询的第一个元素,也在你的索引里面,这样才能命中最左前缀索引
列举创建索引但是无法命中索引的情况?
1.不符合最左前缀的原则,使用 not in != 等等,条件当中用or 连接,or连接的几个字段都不是索引
2.mysql预估使用全表扫描,比使用索引还要快的时候,也会无法命中索引
数据库导入导出命令?
mysql备份表 在shell>mysqldump -h 表示mysql ip地址 在shell>mysqldump -h 127.0.0.1 -uroot -p123 库名 表名 > 路径/文件名.sql 注意:导出的路径必须是在配置文件中配置过的 因为目录的权限是有设定的 mysql>source 路径/文件名.sql 恢复文件
你了解哪些数据库优化方案?
分库,分表,分区,建立索引,定长数据放前面,读写分离,调整存储引擎,优化sql,(不能用*,大范围的查询)
简述MySQL的执行计划的作用和使用方法?
explain + sql 语句,在sql语句没有执行前,判断sql语句的性能是否良好
1000W条数据,使用limit offset分页时,为什么越往后,越慢?如何解决?
跟limit无关,跟offset有关系 id 25 5 页 (125-150) 先给id 加上索引,然后计算那一页需要多少id,用between and 就会很快
什么是索引合并?
两个独立的索引,在经过explain之后,合并成了一个索引
什么是覆盖索引?
select 要查询的字段,不需要回表就可以得到
简述一下数据库的读写分离?
把数据库分为主库和从库,主库用于读写,从库用于读
主要解决读性能的瓶颈,而不是写性能的瓶颈
简述数据库分库分表(水平,垂直)?
1.为什么要进行水平分表? 所有的水平分,和垂直分都是根据B+树的原理来的
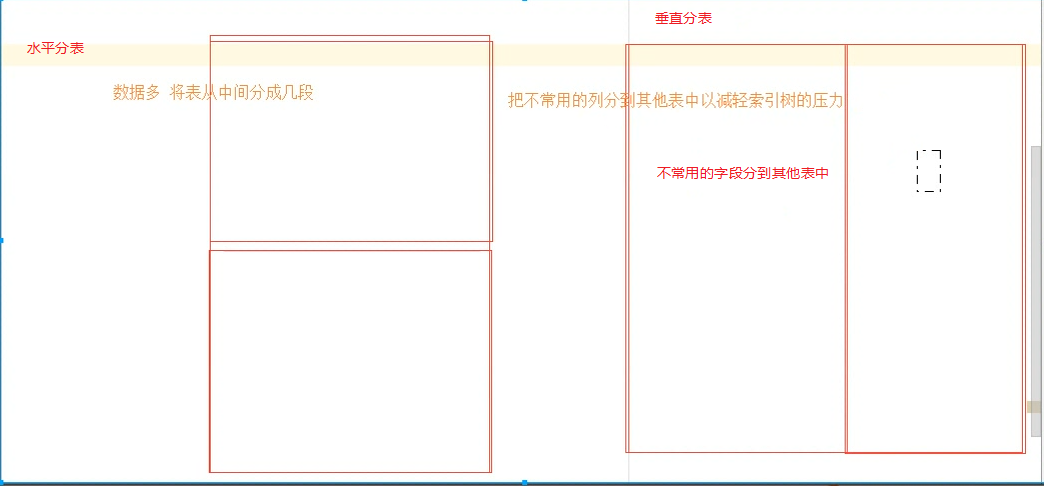
数据库锁的作用?
mysql共享锁和排他锁 1.行锁:行共享,行排他 我要读数据时候,要不要锁上? 如果我读的时候锁上,那么这行数据就不能修改了 行共享:我锁了这条数据,别人还可以读,叫行共享 行排他:我锁了这条数据,别人不能读也不能写 2.表锁 程序级别还有一个锁,叫悲观锁和乐观锁,在做策略的时候想的 悲观锁,在增删改查之前都要给这个表的数据加锁 效率低,准确率高 乐观锁 我在做操作的同时,默认你不会在操作这个数据,我只在updata操作上加锁,其他我都不加
简述项目中优化sql语句执行的效率方法
不要用select * ,查询时候不要使用函数
从delete语句中省略where子句,将产生什么后果
delete 语句将从表中删除所有的记录,不会删除表结构
叙述mysql半同步复制原里?
首先介绍为什么要复制?
异步复制
机器创建一个集控,肯定是有主有从正常情况下往主库(Master)里写,往从库(Slave)中同步数据,默认是异步的
会把事件写到bin log里面,提交这个事务,从库在异步复制,我们不管也不知道从库复制情况,是否丢数据也不清楚.
同步复制
master提交事务之后,直到事务在所有的Slave中都提交了,才会返回客户端,这个事务才会执行完毕
半同步复制原里
master会向Slave提交一个事务,且会把这个事务写到一个relay log当中,relay log是一个已经编译完成2进质文件
并且把这个信息刷新到磁盘上,master已经收到这个信息了,这个时候事务会结束,也就是说它大概会阻塞一会,但是
如果master提交事件超时了,超出我规定的时间了,那么mater会自动转化为异步复制也就是不等待
这个把异步可能数据同步不成功,同步的阻塞问题 一起综合了一些
请简述sql注入的攻击原理及如何在代码层面防止sql注入
select count(1) where name = '%s' or 1=1 --age = '%s' 如何防止呢?据我所知,现在不会出现sql注入了
索引的好处和坏处
好处加速查询,坏处拖慢写速度,增加数据存储所占的空间
什么是Mysql的慢日志?
用来记录在mysql中影响时间超过预值得sql语句,具体运行得时间超过配置文件中值,就会记录到慢日志中
MySQL里有2000W数据,redis中只存20W数据,如何保证redis中都是热点数据?
计算常查得数据有多少,设置redis能占用得内存
Redis
1.redis支持的数据类型
string list hash set zset
2.redis线程模型
redis5.x之前都是单线程实现。但是6.x开始支持多线程
redis单线程为什么快?
1.完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。 2.采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗; 3.使用多路I/O复用模型,非阻塞IO;
3.redis 提供的持久机制
- rdb
- aof
rdb持久化原理
redis会单独创建一个子进程进行持久化,子进程的数据和环境变量都和原进程一模一样,会先将数据写入到一个临时文件中, 待持久化结束了,在用这个临时文件替换上次持久化好的文件,在整个过程中,主进程不进行任何IO操作,这就确保了极高的性能 触发机制: bgsave命令 子进程持久化 # save命令是主进程持久化(阻塞) shutdown 正常关闭 触发RDB模式,如果kill 命令,非正常关闭不会触发 redis 配置 :指定在多长时间内,有多少次更新,就将数据同步到数据文件,可以多个条件配合 RDB持久化可以关闭嘛? 正常情况下我把配置save相关注释即可,但是如果开启了主从复制是关闭不掉的,只要开启了主从复制, 主机不管你有没有配置save 都会默认开启持久化
aof持久化
aof保存的命令字符串和协议,一直往append.aof写
主要的优势比rdb丢失的数据少,aof丢失数据不会超过2秒,因为默认配置1秒执行一次
虽然安全,但是性能太慢了
aof重写机制
专门给appdend.aof 瘦身
默认是达到64mb就重写,我们生产上不可能让它达到64mb就重写,至少配4G以上,因为重写也是耗费性能的
aof 和 rdb 同时存在,听谁的?
aof
2.触发机制(根据配置文件配置项)
no:表示等操作系统进行数据缓存同步到磁盘(快,持久化没保证)
always:同步持久化,每次发生数据变更时,立即记录到磁盘(慢,安全)
everysec:表示每秒同步一次(默认值,很快,但可能会丢失一秒以内的数据)
主从复制
作用:1.读写分离 2.容灾备份 怎么配置: 1.配从不配主 2.使用命令 SLAVEOF 动态指定主从关系 ,如果设置了密码,关联后使用 config set masterauth 密码 缺点: 1.由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延 迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。 2.当主机宕机之后,将不能进行写操作,需要手动将从机升级为主机,从机需要重新制定master 简单总结: 一个master可以有多个Slave 一个slave只能有一个master 数据流向是单向的,只能从主到从
redis哨兵模式
开启一个或多个sentinel相当于开启一个或多个进程,对主节点进行监控,定时ping redis的主节点,如果半数以上sentinel发现ping主节点不通了,
认为主节点挂了,则进行故障转移,就是选出一个从节点代替主节点
缓存的四大问题?
使用缓存最基本的思路:首先查询缓存,缓存中有就直接返回,缓存中没有,再去查询数据库,数据库查询数据之后,我们再把这个数据加入缓存 方便我们下一次查询的时候,直接查找缓存 1.缓存穿透 指数据库中没有的数据,缓存也没有的数据,\ 解决方案:将空值缓存起来 2.缓存击穿 指缓存中没有,数据库中有的数据(一般是指缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据, 又同时去数据库去取数据 解决方法:可以使用互斥锁避免大量请求同时落到db。
3.缓存雪崩 指缓存服务器重启或者大量缓存集中在某一个时间段内失效 解决方案: 通常的解决方案是将key的过期时间后面加上一个随机数,让key均匀的失效。 考虑用队列或者锁让程序执行在压力范围之内,当然这种方案可能会影响并发量。 热点数据可以考虑不失效 4.缓存与数据库数据一致性 解决方案:先删除缓存,在修改数据库,如果数据库修改失败了,那么数据库中是旧数据,缓存是旧数据, 那么数据不会不一致,因为读的时候缓存没有,则读数据库中的旧数据,然后更新到缓存中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号