python-线程
线程被称作轻量级的进程,计算机的执行单位以线程为单位。计算机的最小可执行是线程,进程是资源分配的基本单位。线程是可执行的基本单位,是可被调度的基本单位。线程不可以自己独立拥有资源。线程的执行,必须依赖于所属进程中的资源。进程中必须至少应该有一个线程。
线程又分为用户级线程和内核级线程(了解)
- 用户级线程:对于程序员来说的,这样的线程完全被程序员控制执行,调度
- 内核级线程:对于计算机内核来说的,这样的线程完全被内核控制调度。
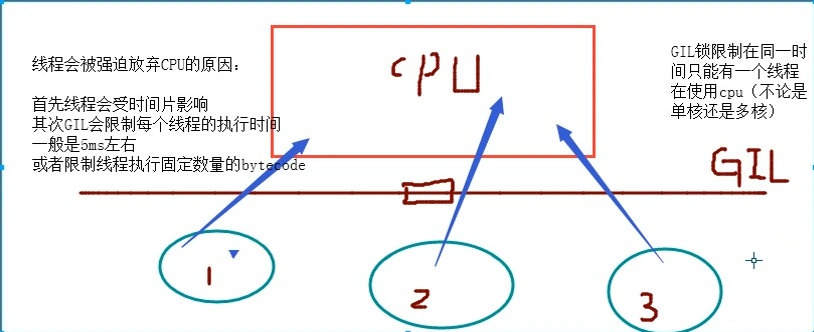
全局解释器锁GIL
全局解释锁(只有Cpython解释器才有)对于线程来说,因为有了GIL,所以没有真正的并行,只有并发
是CPython解释器上的一个锁,锁的是线程,意思是在同一时间只允许一个线程访问cpu
threading模块
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍(官方链接)
需注意,玩多线程编程时,可以不用再像写多进程一样,每个py文件中必须加上if __name__ == '__main__'这一行


import threading from threading import Thread import time #方法一 # def func(): # print('这是一个子线程') # time.sleep(2) # # if __name__ == '__main__': # t = Thread(target=func,args=()) # t.start() #方法二 # class MyThread(Thread): # def __init__(self): # super(MyThread, self).__init__() # def run(self): # print('我是一个子线程') # # t = MyThread() # t.start()
多线程与多进程对比
(1) cpu切换进程要比cpu切换线程 慢很多,在python中,如果IO操作过多的话,使用多线程最好了
(2) 在同一个进程内,所有线程共享这个进程的pid,也就是说所有线程共享所属进程的所有资源和内存地址
(3) 在同一个进程内,所有线程共享该进程中的全局变量
(4) 因为有GIL锁的存在,在Cpython中,没有真正的线程并行。但是有真正的多进程并行,当你的任务是计算密集的情况下,使用多进程好
(5)关于守护线程和守护进程的事情(注意:代码执行结束并不代表程序结束)
守护进程:要么自己正常结束,要么根据父进程的代码执行结束而结束
守护线程:要么自己正常结束,要么根据父线程的执行结束而结束
from multiprocessing import Process from threading import Thread import time def func(): pass if __name__ == '__main__': start = time.time() for i in range(1000): p = Process(target=func) p.start() print('开100个进程的时间:',time.time() - start) start = time.time() for i in range(1000): p = Thread(target=func) p.start() print('开100个线程的时间:', time.time() - start)
from multiprocessing import Process from threading import Thread import time,os def func(name): print('我是一个%s,我的pid是%s'%(name,os.getpid())) if __name__ == '__main__': print('我是main,我的pid是%s'%(os.getpid())) for i in range(10): p = Process(target=func,args=('进程',)) p.start() for i in range(10): p = Thread(target=func,args=('线程',)) p.start()
from multiprocessing import Process from threading import Thread,Lock import time,os def func(): global num tmp = num time.sleep(0.00001) num = tmp - 1 if __name__ == '__main__': num = 100 t_l = [] for i in range(100): t = Thread(target=func) t.start() t_l.append(t) # time.sleep(1) [t.join() for t in t_l] print(num)
守护线程
无论是进程还是线程,都遵循:守护xx会等待主xx运行完毕后被销毁。需要强调的是:运行完毕并非终止运行
from threading import Thread from multiprocessing import Process import time def func(): time.sleep(2) print(123) def func1(): time.sleep(1) print('abc') # 守护线程是根据主线程执行结束才结束 # 守护线程不是根据主线程的代码执行结束而结束 # 主线程会等待普通线程执行结束,再结束 # 守护线程会等待主线程结束,再结束 # 所以,一般把不重要的事情设置为守护线程 # 守护进程是根据主进程的代码执行完毕,守护进程就结束 if __name__ == '__main__': t = Thread(target=func) t.daemon = True t.start() # t1 = Thread(target=func1) # t1.start() # print(99999999999999999999) ############################################ 以下是验证守护进程 # from threading import Thread # from multiprocessing import Process # import time # # # def func(): # time.sleep(2) # print(123) # # def func1(): # time.sleep(1) # print('abc') # # # 守护线程是根据主线程执行结束才结束 # # 守护线程不是根据主线程的代码执行结束而结束 # # 主线程会等待普通线程执行结束,再结束 # # 守护线程会等待主线程结束,再结束 # # 所以,一般把不重要的事情设置为守护线程 # # 守护进程是根据主进程的代码执行完毕,守护进程就结束 # if __name__ == '__main__': # t = Process(target=func) # t.daemon = True # t.start() # t1 = Process(target=func1) # t1.start() # print(99999999999999999999)
锁
同步锁(互斥锁) Lock
一把锁配一把钥匙
from multiprocessing import Process from threading import Thread,Lock import time,os # l = Lock()# 一把钥匙配一把锁 # l.acquire() # print('abc') # l.acquire()# 程序会阻塞住 陷入死锁了 # print(123)
死锁的演示
from multiprocessing import Process from threading import Thread,Lock import time,os def man(l_tot,l_pap): l_tot.acquire()# 是男的获得厕所资源,把厕所锁上了 print('常建在厕所上厕所') time.sleep(1) l_pap.acquire()# 男的拿纸资源 print('常建拿到卫生纸了!') time.sleep(0.5) print('常建完事了!') l_pap.release()# 男的先还纸 l_tot.release()# 男的还厕所 def woman(l_tot,l_pap): l_pap.acquire() # 女的拿纸资源 print('小雪拿到卫生纸了!') time.sleep(1) l_tot.acquire() # 是女的获得厕所资源,把厕所锁上了 print('小雪在厕所上厕所') time.sleep(0.5) print('小雪完事了!') l_tot.release() # 女的还厕所 l_pap.release() # 女的先还纸 if __name__ == '__main__': l_tot = Lock() l_pap = Lock() t_man = Thread(target=man,args=(l_tot,l_pap)) t_woman = Thread(target=woman,args=(l_tot,l_pap)) t_man.start() t_woman.start()
递归锁RLock
可以有无尽的把锁,但配一把万能钥匙
from threading import RLock s = RLock() s.acquire() s.acquire() s.acquire() s.acquire() s.acquire() s.acquire() print(123)
from multiprocessing import Process from threading import Thread,RLock import time,os # RLock是递归锁 --- 是无止尽的锁,但是所有锁都有一个共同的钥匙 # 想解决死锁,配一把公共的钥匙就可以了。 def man(l_tot,l_pap): l_tot.acquire()# 是男的获得厕所资源,把厕所锁上了 print('张三在厕所上厕所') time.sleep(1) l_pap.acquire()# 男的拿纸资源 print('张三拿到卫生纸了!') time.sleep(0.5) print('张三完事了!') l_pap.release()# 男的先还纸 l_tot.release()# 男的还厕所 def woman(l_tot,l_pap): l_pap.acquire() # 女的拿纸资源 print('小雪拿到卫生纸了!') time.sleep(1) l_tot.acquire() # 是女的获得厕所资源,把厕所锁上了 print('小雪在厕所上厕所') time.sleep(0.5) print('小雪完事了!') l_tot.release() # 女的还厕所 l_pap.release() # 女的先还纸 if __name__ == '__main__': l_tot = l_pap = RLock() t_man = Thread(target=man,args=(l_tot,l_pap)) t_woman = Thread(target=woman,args=(l_tot,l_pap)) t_man.start() t_woman.start()
信号量
同进程的一样
from threading import Semaphore,Thread import time def func(sem,i): sem.acquire() print('第%s个人进入屋子'%i) time.sleep(2) print('第%s个人离开屋子'%i) sem.release() sem = Semaphore(20) for i in range(20): t = Thread(target=func,args=(sem,i)) t.start()
事件
同进程的一样
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
from threading import Thread,Event import time,random def conn_mysql(e,i): count = 1 while count <= 3: if e.is_set(): print('第%s个人连接成功!'%i) break print('正在尝试第%s次重新连接...'%(count)) e.wait(0.5) count += 1 def check_mysql(e): print('\033[42m 数据库正在维护 \033[0m') time.sleep(random.randint(1,2)) e.set() if __name__ == '__main__': e = Event() t_check = Thread(target=check_mysql,args=(e,)) t_check.start() for i in range(10): t_conn = Thread(target=conn_mysql,args=(e,i)) t_conn.start()
条件
条件是让程序员自行去调度线程的一个机制
Condition4个方法 acquire() 加锁 release() 解锁 wait() 是指让线程阻塞住 notify(int) 是指给wait发一个信号,让wait变成不阻塞 int是指,你要给多少给wait发信号
from threading import Thread,Condition import time # Condition涉及4个方法 # acquire() # release() # wait() 是指让线程阻塞住 # notify(int) 是指给wait发一个信号,让wait变成不阻塞 # int是指,你要给多少给wait发信号 def func(con,i): con.acquire() con.wait()# 线程执行到这里,会阻塞住,等待notify发送信号,来唤醒此线程 con.release() print('第%s个线程开始执行了!'%i) if __name__ == '__main__': con = Condition() for i in range(10): t = Thread(target=func,args=(con,i)) t.start() while 1: con.acquire() num = int(input(">>>")) con.notify(num)# 发送一个信号给num个正在阻塞在wait的线程,让这些线程正常执行 con.release()
定时器
from threading import Timer# 定时器 def func(): print('就是这么nb!') Timer(2.5,func).start() # Timer(time,func) # time:睡眠的时间,以秒为单位 # func:睡眠时间之后,需要执行的任务
队列
额外补充同一进程内的队列,不能做多进程之间的通信
先进先出
import queue # q = queue.Queue() # # 先进先出 # q.put(1) # q.put(2) # q.put(3) # print(q.get()) # print(q.get())
后进先出
# q = queue.LifoQueue() # # 后进先出的队列 # q.put(1) # q.put(2) # q.put(3) # print(q.get())
优先级队列
q = queue.PriorityQueue() # 优先级队列,put()方法接收的是一个元组(),第一个位置是优先级,第二个位置是数据 # 优先级如果是数字,直接比较数值 # 如果是字符串,是按照 ASCII 码比较的。当ASCII码相同时,会按照先进先出的原则 # q.put((1,'abc')) # q.put((5,'qwe')) # q.put((-5,'zxc')) # print(q.get()) # print(q.get()) # print(chr(48))
线程池
from concurrent.futures import ThreadPoolExecutor
concurrent.futures 这个模块是异步调用的机制,提交任务都是用submit
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from multiprocessing import Pool # concurrent.futures 这个模块是异步调用的机制 # concurrent.futures 提交任务都是用submit # for + submit 多个任务的提交 # shutdown 是等效于Pool中的close+join,是指不允许再继续向池中增加任务,然后让父进程(线程)等待池中所有进程执行完所有任务。 # from multiprocessing import Pool.apply / apply_async import time def func(num): sum = 0 for i in range(num): for j in range(i): for x in range(j): sum += x ** 2 print(sum) if __name__ == '__main__': pass # pool的进程池的效率演示 # p = Pool(5) # start = time.time() # for i in range(100): # p.apply_async(func,args=(i,)) # p.close() # p.join() # print('Pool进程池的效率时间是%s'%(time.time() - start)) # 多进程的效率演示 # tp = ProcessPoolExecutor(5) # start = time.time() # for i in range(100): # tp.submit(func, i) # tp.shutdown() # 等效于 进程池中的 close + join # print('进程池的消耗时间为%s' % (time.time() - start)) # 多线程的效率 # tp = ThreadPoolExecutor(20) # start = time.time() # for i in range(1000): # tp.submit(func,i) # tp.shutdown()# 等效于 进程池中的 close + join # print('线程池的消耗时间为%s'%(time.time() - start)) # 结果:针对计算密集的程序来说 # 不管是Pool的进程池还是ProcessPoolExecutor()的进程池,执行效率相当 # ThreadPoolExecutor 的效率要差很多 # 所以 当计算密集时,使用多进程。
from concurrent.futures import ThreadPoolExecutor import time def func(num): sum = 0 for i in range(num): sum += i ** 2 print(sum) t = ThreadPoolExecutor(20) start = time.time() t.map(func,range(1000))# 提交多个任务给池中。 等效于 for + submit t.shutdown() print(time.time() - start)
from concurrent.futures import ThreadPoolExecutor import time def func(num): sum = 0 # time.sleep(5) # print(num) # 异步的效果 for i in range(num): sum += i ** 2 return sum t = ThreadPoolExecutor(20) # 下列代码是用map的方式提交多个任务,对应 拿结果的方法是__next__() 返回的是一个生成器对象 res = t.map(func,range(1000)) t.shutdown() print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) # 下列代码是用for + submit提交多个任务的方式,对应拿结果的方法是result # res_l = [] # for i in range(1000): # re = t.submit(func,i) # res_l.append(re) # # t.shutdown() # [print(i.result()) for i in res_l] # 在Pool进程池中拿结果,是用get方法。 在ThreadPoolExecutor里边拿结果是用result方法
from concurrent.futures import ProcessPoolExecutor # 不管是ProcessPoolExecutor的进程池 还是Pool的进程池,回调函数都是父进程调用的。 import os import requests def func(num): sum = 0 for i in range(num): sum += i ** 2 return sum def call_back_fun(res): # print(res.result(),os.getpid()) print(os.getpid()) if __name__ == '__main__': print(os.getpid()) t = ProcessPoolExecutor(20) for i in range(1000): t.submit(func,i).add_done_callback(call_back_fun) t.shutdown()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号