
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字)中获取,并且可以使用以高级函数表示的复杂算法进行处理map,例如reduce,join和window。最后,处理后的数据可以推送到文件系统,数据库和实时仪表板
在内部,它的工作原理如下。Spark Streaming接收实时输入数据流并将数据分成批处理,然后由Spark引擎处理,以批量生成最终结果流
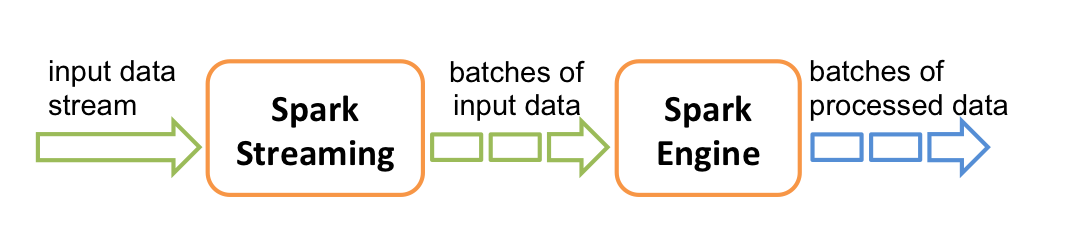
计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加或者存储到外部设备
WordCount例子实现(JAVA)
package stuSpark.com;
import scala.Tuple2;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.util.Arrays;
public class JavaSparkStreaming {
public static void main(String[] args){
//JavaStreamingContext对象,它是流功能的主要入口点。使用两个执行线程创建一个本地StreamingContext,批处理间隔为1秒。
//SparkStreaming 中local后必须为大于等于2的数字【即至少2条线程】。因为receiver 占了一个不断循环接收数据
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// 创建一个DStream来表示来自TCP源的流数据,指定为主机名(例如localhost)和端口(例如9999)
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
//linesDStream表示将从数据服务器接收的数据流。此流中的每条记录都是一行文本。然后用空格分割为单词
// flatMap是一个DStream操作,通过从源DStream中的每个记录生成多个新记录来创建新的DStream。
//使用FlatMapFunction对象定义了转换Java API中有许多这样的便利类可以帮助定义DStream转换。
//DStream是RDD产生的模板,在Spark Streaming发生计算前,其实质是把每个Batch的DStream的操作翻译成为了RDD操作
JavaDStream<String> words = lines.flatMap(
new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String x) {
return (Iterable<String>) Arrays.asList(x.split(" ")).iterator();
}
});
//计算
JavaPairDStream<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
});
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordCounts.print();//将此DStream 中生成的每个RDD的前十个元素打印到控制台
jssc.start(); // 开始
jssc.awaitTermination(); // 等待计算终止
}
}
1.创建StreamingContext对象 同Spark初始化需要创建SparkContext对象一样,使用Spark Streaming就需要创建StreamingContext对象。创建StreamingContext对象所需的参数与SparkContext基本一致,包括指明Master,设定名称(如NetworkWordCount)。需要注意的是参数Seconds(1),Spark Streaming需要指定处理数据的时间间隔,如上例所示的1s,那么Spark Streaming会以1s为时间窗口进行数据处理。此参数需要根据用户的需求和集群的处理能力进行适当的设置;
2.创建InputDStream如同Storm的Spout,Spark Streaming需要指明数据源。如上例所示的socketTextStream,Spark Streaming以socket连接作为数据源读取数据。当然Spark Streaming支持多种不同的数据源,包括Kafka、 Flume、HDFS/S3、Kinesis和Twitter等数据源;
3.操作DStream对于从数据源得到的DStream,用户可以在其基础上进行各种操作,如上例所示的操作就是一个典型的WordCount执行流程:对于当前时间窗口内从数据源得到的数据首先进行分割,然后利用Map和ReduceByKey方法进行计算,当然最后还有使用print()方法输出结果;
4.启动Spark Streaming之前所作的所有步骤只是创建了执行流程,程序没有真正连接上数据源,也没有对数据进行任何操作,只是设定好了所有的执行计划,当ssc.start()启动后程序才真正进行所有预期的操作。
使用Netcat(在大多数类Unix系统中找到的小实用程序)作为数据服务器运行
$ nc -lk 9999启动示例
$ ./bin/run-example streaming.JavaNetworkWordCount localhost 9999然后,在运行netcat服务器的终端中键入的任何行将被计数并每秒在屏幕上打印

 浙公网安备 33010602011771号
浙公网安备 33010602011771号