Zookeeper介绍与集群安装
一、ZooKeeper 简介
1.1 ZooKeeper 是什么
zookeeper 是一个高性能的分布式应用程序协调服务,应用程序可以基于他非常简单的实现同步服务、分组服务、配置维护、命名服务等,通过 zookeeper,你可以使用现成的组件实现一致性服务、分组管理、leader 选举。 由于工程师不能很好地使用锁机制,以及基于消息的协调机制不适合在某些应用中使用,因此需要有一种可靠的、可扩展的、分布式的、可配置的协调机制来统一系统的状态。Zookeeper 的目的就在于此。 zookeeper 十分易用,它使用和文件系统中目录树相似的结构来实现他的功能,它使用 java 和 C 编写,运行在 java 环境下。
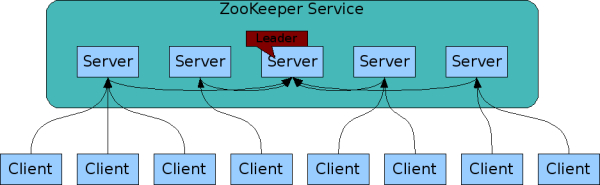
1.2 ZooKeeper 角色
|
角色 |
描述 |
|---|---|
|
Leader |
发起投票、决议,更新系统状态 |
|
Follower |
接收客户端请求,向客户端返回请求结果,选举过程中参与投票 |
|
Observer |
接收客户端连接,向 Leader 转发写请求,同步 Leader 状态,不参与投票,主要用于扩展系统,增加系统吞吐性能 |
|
Client |
发起请求 |
ZooKeeper 引用了 Leader、Follower和 Observer 三个角色。ZooKeeper 集群中的所有机器通过选举的方式选出一个 Leader,Leader 可以为客户端提供读服务和写服务。除了 Leader 外,集群中还包括了 Follower 和 Observer 。Follower 和 Observer 都能够提供读服务,唯一区别在于,*Observer * 不参与 Leader 的选举过程,也不参与写操作的"过半写成功"策略,因此 Observer 可以在不影响写性能的情况下提升集群的读性能。
1.3 ZooKeeper 特性
原子性
在Zookeeper中要么更新成功,要么失败,不存在只产生部分结果的情况。
高性能
Zookeeper的速度非常快。ZooKeeper 应用程序在数千台机器上运行,尤其是在读多写少的情况下,它的性能最佳,比率约为 10:1。
高可靠
通常情况下,只要大多数服务器可用,ZooKeeper 服务对外就是可用的。ZooKeeper 集群中,建议部署奇数个 ZooKeeper节点(或进程) —— 大多数情况下,3个节点就足够了。节点个数并不是越多越好 —— 节点越多,节点间通信所需的时间就会越久,选举 Leader 时需要的时间也会越久。
顺序一致性
Zookeeper保证 来自客户端的更新将按发送顺序处理。
ZooKeeper 在每次更新时都会使用一个数字来标记,该数字反映了所有 ZooKeeper 事务的顺序。
1.4 数据模型和分层命名空间
数据模型
ZooKeeper 提供的命名空间与标准文件系统的命名空间非常相似。名称是一系列由斜杠 (/) 分隔的路径元素。ZooKeeper 命名空间中的每个节点都有路径标识。
分层命名空间
zookeeper的分层命名空间图:
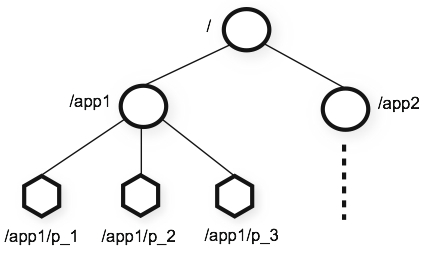
Zookeeper的数据存储节点类型分为了持久节点、临时节点、容器节点、TTL 节点。与标准文件系统不同,ZooKeeper 命名空间中的每个节点都可以有与之关联的数据以及子节点。这就像有一个文件系统,允许文件也是一个目录。我们使用官方术语 znode 来表示一个 ZooKeeper的 数据节点。
Znodes 维护一个统计信息结构,其中包括数据更改、ACL 更改和时间戳的版本号,以允许缓存验证和协调更新。每当 znode 的数据发生变化时,版本号就会增加。例如,每当客户端检索数据时,它也会接收数据的版本。存储在命名空间中每个 znode 的数据都是以原子方式读取和写入的。读取获取与 znode 关联的所有数据字节,写入替换所有数据。每个节点都有一个访问控制列表 (ACL),用于限制谁可以执行哪些操作。
ZooKeeper 被设计用于存储协调数据:状态信息、配置、位置信息等,因此每个节点存储的数据通常很小,在字节到千字节的范围内。
znode的属性说明:
ZooKeeper 树中的每个节点都称为 znode。通过bin/zkCli.sh start 连接上zk服务后,执行get -s znode_name,可以获取znode(示例znode是zk)的属性信息,如下:
[zk: 127.0.0.1:2181(CONNECTED) 11] get -s /zk
my_data
cZxid = 0x2
ctime = Thu Dec 07 10:27:25 CST 2023
mZxid = 0x2
mtime = Thu Dec 07 10:27:25 CST 2023
pZxid = 0x2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 7
numChildren = 0其中:
- my_data: 是该节点本身存储的内容。
- cZxid:该节点创建的事务id。
- ctime:该节点创建时的时间。
- mZxid:该节点被修改的事务id,即每次对znode的修改都会更新mZxid。
- mtime:该节点最新一次更新发生时的时间。
- pZxid:表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID。
- cversion:子节点的版本号。当该节点的子节点有变化时,cversion 的值就会增加1。
- dataVersion:数据版本号,数据每次修改该版本号加1。
- aclVersion:权限版本号,权限每次修改该版本号加1。
- ephemeralOwner:如果该节点为临时节点, ephemeralOwner值表示与该节点绑定的session id. 如果不是, ephemeralOwner值为0x0。
- dataLength:该节点的数据长度。
- numChildren:该节点拥有子节点的数量。
Zookeeper里面的版本号和我们理解的版本号不同,它表示的是对数据节点的内容、子节点列表或者ACL信息的修改次数。节点创建时dataversion、aclversion,cversion都为0,每次修改响应内容其对应的版本号加1。
Zookeeper中的版本号其实就是乐观锁的一种思想。两个API操作可以有条件地执行:setData和delete。这两个调用以版本号作为转入参数,只有当转入参数的版本号与服务器上的版本号一致时调用才会成功。当多个Zookeeper客户端对同一个znode进行操作时,版本的作用就会显得尤为重要。
1.5 watches
zooKeeper支持watch的概念。客户可以在znode上设置watch。当znode发生变化时,手表将被触发并移除。当watch被触发时,客户端会收到一个数据包,说明znode已更改。如果客户端和ZooKeeper服务器之一之间的连接中断,客户端将收到本地通知。
3.6.0中的新功能:客户端还可以在znode上设置永久的递归监视,这些监视在触发时不会被删除,并且会递归地触发注册的znode以及任何子znode上的更改。保证ZooKeeper非常快速和简单。然而,由于其目标是为构建更复杂的服务(如同步)奠定基础,因此它提供了一套保证:
- 顺序一致性-客户端的更新将按发送顺序应用。
- 原子性-更新成功或失败。没有部分结果。
- 单一系统映像-无论客户端连接到哪个服务器,客户端都会看到相同的服务视图。也就是说,即使客户端故障转移到具有相同会话的其他服务器,客户端也永远不会看到系统的旧视图。
- 可靠性-一旦应用了更新,它将从那时起一直持续到客户端覆盖更新为止。
- 及时性-保证系统的客户端视图在一定时间内保持最新。
简单API:
- ZooKeeper的设计目标之一是提供一个非常简单的编程接口。因此,它只支持以下操作:
- create:在树中的某个位置创建节点
- delete:删除节点
- exists:测试某个位置是否存在节点
- get data:从节点读取数据
- set data:将数据写入节点
- get children:检索节点的子节点列表
- sync:等待数据传播
1.6 Implementation
ZooKeeper Components显示了ZooKeeper服务的高级组件。除了请求处理器之外,组成ZooKeeper服务的每个服务器都复制了每个组件的副本。
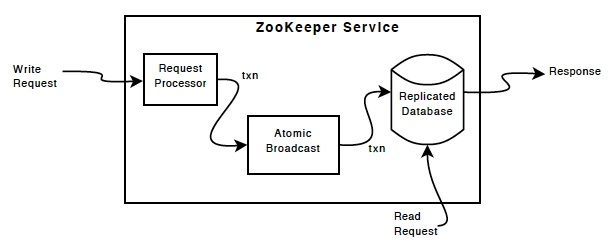
复制数据库是一个包含整个数据树的内存数据库。更新会记录到磁盘以实现可恢复性,写入操作在应用于内存数据库之前会序列化到磁盘。
每个ZooKeeper服务器都为客户端提供服务。客户端仅连接到一个服务器以提交请求。读取请求由每个服务器数据库的本地副本提供服务。更改服务状态的请求(写请求)由协议协议处理。
作为协议协议的一部分,来自客户端的所有写入请求都被转发到一个称为leader的服务器。其余的ZooKeeper服务器,称为追随者,从领导者那里接收消息建议,并就消息传递达成一致。消息传递层负责在失败时替换领导者,并将追随者与领导者同步。
ZooKeeper使用自定义原子消息传递协议。由于消息传递层是原子的,ZooKeeper可以保证本地副本永远不会发散。当leader收到写入请求时,它会计算应用写入时系统的状态,并将其转换为捕获此新状态的事务。
1.7 版本差异
| 版本 | 内容 |
| 3.9x | 用于拍摄快照和流出数据的管理服务器 API 传达触发 WatchEvent 触发的 Zxid TLS - 客户端信任/密钥存储的动态加载 添加 Netty-TcNative OpenSSL 支持 向 Zktreeutil 添加 SSL 支持 提高 syncRequestProcessor 性能 更新所有第三方依赖项,以消除所有已知的 CVE。 |
| 3.8.x |
日志框架从Apache Log4j1迁移到LogBack。 |
| 3.7.x |
基于Java控制ZooKeeper服务器的API。 |
| 3.6.x |
性能和安全性方面带来了许多改进。 |
| 3.5.x |
支持动态扩容/缩容。 |
| 3.4.x及以下 |
基础功能、客户端、选举算法等功能实现与完善。 |
1.8 配置:
https://zookeeper.apache.org/doc/r3.9.3/zookeeperAdmin.html#sc_systemReq
二、ZooKeeper 集群搭建
请参考 https://www.cnblogs.com/TimeSay/p/16613528.html
官网下载地址:http://www.apache.org/dyn/closer.cgi/zookeeper
wget http://mirror.olnevhost.net/pub/apache/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz tar zxvf apache-zookeeper-3.5.9-bin.tar.gz mv apache-zookeeper-3.5.9-bin /usr/local/zookeeper
编辑 /etc/profile 文件, 在文件末尾添加以下环境变量配置:
# ZooKeeper Env export ZOOKEEPER_HOME=/usr/local/zookeeper export PATH=$PATH:$ZOOKEEPER_HOME/bin
运行以下命令使环境变量生效: source /etc/profile
初次使用 ZooKeeper 时,需要将$ZOOKEEPER_HOME/conf 目录下的 zoo_sample.cfg 重命名为 zoo.cfg, zoo.cfg
mv $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
创建目录/usr/local/zookeeper/data 和/usr/local/zookeeper/logs 修改配置文件
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper/data dataLogDir=/usr/local/zookeeper/logs clientPort=2181
如果是多节点,配置文件中尾部增加
server.1=192.168.1.1:2888:3888 #如果伪集群搭建 IP可相同,端口可不同 server.2=192.168.1.2:2888:3888 server.3=192.168.1.3:2888:3888
同时,增加
#master echo "1">/usr/local/zookeeper/data/myid #slave1 echo "2">/usr/local/zookeeper/data/myid #slave2 echo "3">/usr/local/zookeeper/data/myid
# cd /usr/local/zookeeper/zookeeper-3.4.11/bin # ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/zookeeper-3.4.11/bin/../conf/zoo.cfg Starting zookeeper ... STARTED zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: follower
服务启动完成后,可以使用 telnet 和 stat 命令验证服务器启动是否正常:
# telnet 127.0.0.1 2181 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. stat Zookeeper version: 3.4.11-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT Clients: /127.0.0.1:48430[0](queued=0,recved=1,sent=0) Latency min/avg/max: 0/0/0 Received: 1 Sent: 0 Connections: 1 Outstanding: 0 Zxid: 0x0 Mode: standalone Node count: 4 Connection closed by foreign host.
想要停止 ZooKeeper 服务, 可以使用如下命令:
# cd /usr/local/zookeeper/zookeeper-3.4.11/bin # ./zkServer.sh stop ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper/zookeeper-3.4.11/bin/../conf/zoo.cfg Stopping zookeeper ... STOPPED
#git clone https://github.com/DeemOpen/zkui.git
# wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo #cd zkui/ #yum install -y maven #mvn clean install
#vim config.cfg serverPort=9090 #指定端口 zkServer=192.168.1.1:2181 sessionTimeout=300000
2.0-SNAPSHOT 会随软件的更新版本不同而不同,执行时请查看target 目录中真正生成的版本
nohup java -jar target/zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &
http://192.168.1.1:9090/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号