
Xgboost
思想:怎么样在当前模型再加入一个基础模型,使得组合后的效果更好。
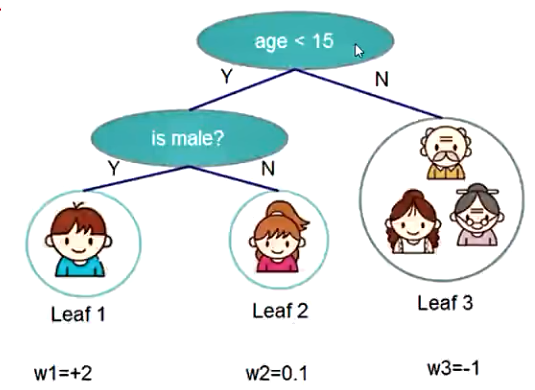
问题:是否会玩电脑游戏?

目标函数:
如何得到最优解:
集成算法的表示:
基础模型:决策树模型
集成方法:
并行构造多棵树?没那么简单,一个一个的加!

🥇问题:每一轮加入一个什么样的基础模型呢?
✒️解决方案:加了它能优化我的目标函数

树模型结构
-
叶子子数限制
-
权重正则化
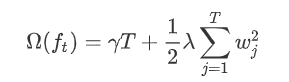
简化目标函数
-
要保证预测值和真实值之间的差异值最小(ml基本思想)
-
要让树模型更精简(存在树的惩罚项)
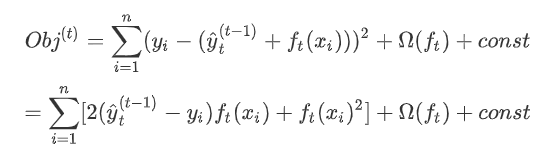
1.使用泰勒展开式近似代替
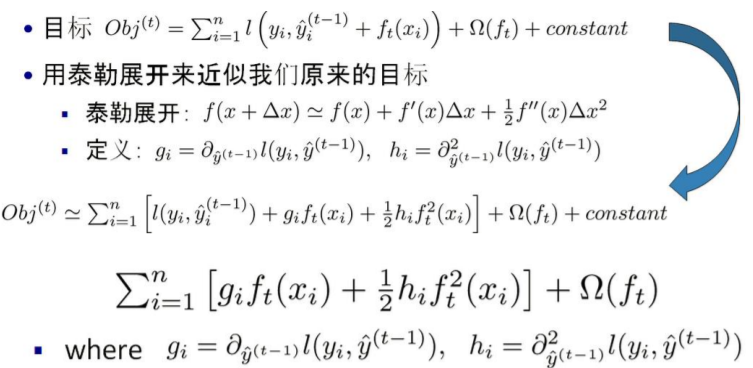
2.将样本遍历改为节点遍历
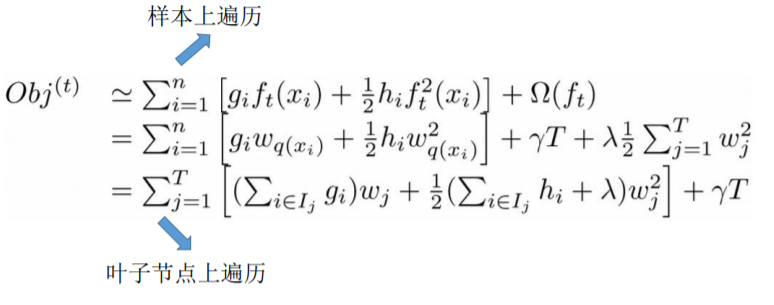
3.化简目标函数
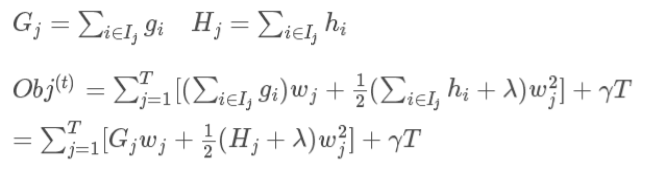
4.求导求最值:

案例

正则化的惩罚力度树的复杂度的控制因子结构分数越小就代表树的结构越好
类似于决策树中的信息增益,我们使用结构分数增益来确定划分:
对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效的枚举所有的分割:
要枚举所有x<a 这样的条件,对于某个的分割a我们要计算左边和右边的导数和。

from xgboost import XGBRegressor import numpy as np from sklearn.datasets import load_breast_cancer can = load_breast_cancer() X = can.data Y = can.target model = XGBRegressor() model.fit(X, Y) print(model.score(X,Y)) #0.9896016265482058

 浙公网安备 33010602011771号
浙公网安备 33010602011771号