
聚类算法的衡量指标
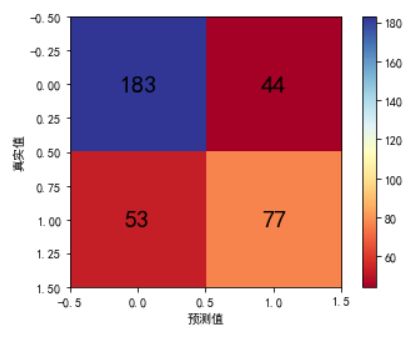
con = confusion_matrix(y_test,y_pred) import matplotlib.pyplot as plt cmap = plt.cm.get_cmap('RdYlBu') plt.imshow(con,cmap = cmap) plt.show()
均一性
一个簇中只包含一个类别的样本,则满足均一性;其实也可以认为就是正确率(每个聚簇中正确分类的样本数占该聚簇总样本数的比例和):
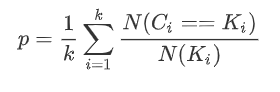
完整性
同类别样本被归类到相同簇中,则满足完整性;每个聚簇中正确分类的样本数占该类型的总样本数比例的和:
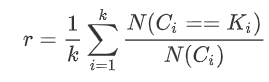
V-measure
均一性和完整性的加权平均:
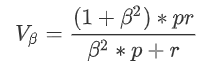
调整兰德系数(ARI)
Rand index(兰德指数)(RI),RI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合:
其中C表示实际类别信息,K表示聚类结果,a表示在C与K中都是同类别的元素对数 ,b表示在C与K中都是不同类别的元素对数,c_2^n 表示数据集中可以组成的对数
调整兰德系数(ARI,Adjusted Rnd Index),ARI取值范围[-1,1],值越大,表示聚类 结果和真实情况越吻合。从广义的角度来将,ARI是衡量两个数据分布的吻合程度的。
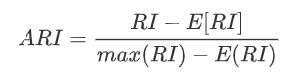
调整互信息(AMI)
调整互信息(AMI,Adjusted Mutual Information),类似ARI,内部使用信息熵:
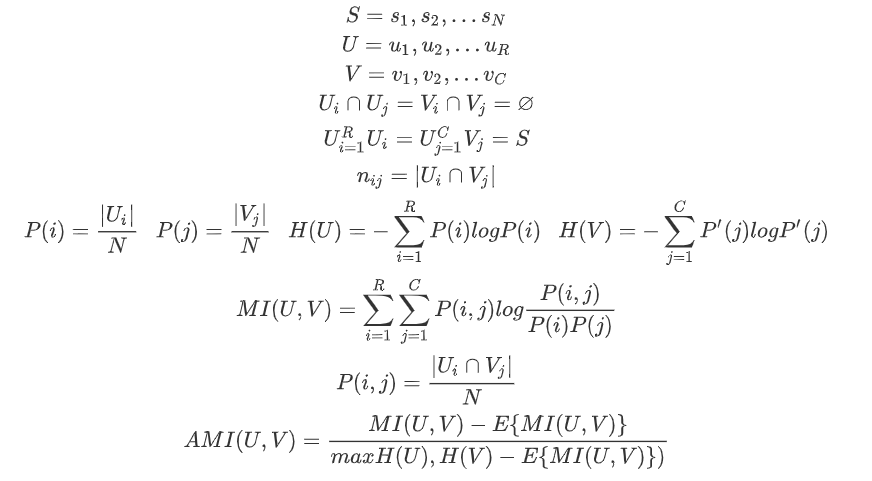
轮廓系数(Silhouette)
簇内不相似度:计算样本i到同簇其它样本的平均距离为ai;ai越小,表示样本i越应该被聚类到该簇,簇C中的所有样本的ai的均值被称为簇C的簇不相似度。
簇间不相似度:计算样本i到其它簇Cj的所有样本的平均距离bij,bi=min{bi1,bi2,...,bik};bi越大,表示样本i越不属于其它簇。
轮廓系数:si值越接近1表示样本i聚类越合理,越接近-1,表示样本i应该分类到另外的簇中,近似为0,表示样本i应该在边界上;所有样本的si的均值被成为聚类结果的轮廓系数。
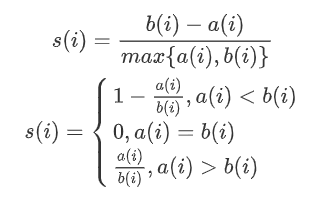

 浙公网安备 33010602011771号
浙公网安备 33010602011771号