机器学习-推荐系统
简介
推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
前景
随着电子商务规模的不断扩大,商品个数和种类快速增长,顾客需要花费大量的时间才能找到自己想买的商品。这种浏览大量无关的信息和产品过程无疑会使淹没在信息过载问题中的消费者不断流失。为了解决这些问题,个性化推荐系统应运而生。个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务。
案例
我们所使用的软件产品中就比如今日头条,有很多都比我们更懂我们自己,他们会自动的展现我们喜欢看的内容。
打开音乐软件推荐的都是我们想听的歌曲。
打开淘宝,显示的都是我们想买的东西,打开短视频软件都是自己想看的视频,难道他们是我们肚子的蛔虫,能知道我们想什么吗?

其实,很多朋友都已经知道我说的是什么东西,随着科技的进步,计算能力的突破,大数据的普及,现在很多软件都能做到千人千面,构建一个推荐系统变得十分重要。
主要推荐方法
基于内容的推荐
基于内容的推荐是信息过滤技术的延续与发展,它是建立在项目的内容信息上作出推荐的,而不需要依据用户对项目的评价意见,更多地需要用机 器学习的方法从关于内容的特征描述的事例中得到用户的兴趣资料。在基于内容的推荐系统中,项目或对象是通过相关的特征的属性来定义,系统基于用户评价对象 的特征,学习用户的兴趣,考察用户资料与待预测项目的相匹配程度。用户的资料模型取决于所用学习方法,常用的有决策树、神经网络和基于向量的表示方法等。 基于内容的用户资料是需要有用户的历史数据,用户资料模型可能随着用户的偏好改变而发生变化。基于内容推荐方法的优点是:
1)不需要其它用户的数据,没有冷开始问题和稀疏问题。
2)能为具有特殊兴趣爱好的用户进行推荐。
3)能推荐新的或不是很流行的项目,没有新项目问题。
4)通过列出推荐项目的内容特征,可以解释为什么推荐那些项目。
5)已有比较好的技术,如关于分类学习方面的技术已相当成熟。缺点是要求内容能容易抽取成有意义的特征,要求特征内容有良好的结构性,并且用户的口味必须能够用内容特征形式来表达,不能显式地得到其它用户的判断情况。
协同过滤推荐
协同过滤推荐技术是推荐系统中应用最早和最为成功的技术之一。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后 利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统从而根据这一喜好程度来对目标用户进行推荐。
协同过滤最大优 点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象,如音乐、电影。用户评分矩阵用户评分矩阵协同过滤是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用 户。
其基本思想非常易于理解,在日常生活中,我们往往会利用好朋友的推荐来进行一些选择。协同过滤正是把这一思想运用到电子商务推荐系统中来,基于其他用 户对某一内容的评价来向目标用户进行推荐。基于协同过滤的推荐系统可以说是从用户的角度来进行相应推荐的,而且是自动的即用户获得的推荐是系统从购买模式或浏览行为等隐式获得的,不需要用户努力地找到适合自己兴趣的推荐信息,如填写一些调查表格等。
和基于内容的过滤方法相比,协同过滤具有如下的优点:
1) 能够过滤难以进行机器自动内容分析的信息,如艺术品,音乐等。
2) 共享其他人的经验,避免了内容分析的不完全和不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤。
3) 有推荐新信息的能力。可以发现内容上完全不相似的信息,用户对推荐信息的内容事先是预料不到的。这也是协同过滤和基于内容的过滤一个较大的差别,
基于内容的过滤推荐很多都是用户本来就熟悉的内容,而协同过滤可以发现用户潜在的但自己尚未发现的兴趣偏好。
4) 能够有效的使用其他相似用户的反馈信息,较少用户的反馈量,加快个性化学习的速度。虽然协同过滤作为一种典型的推荐技术有其相当的应用,
但协同过滤仍有许多的问题需要解决。最典型的问题有稀疏问题和可扩展问题。
基于关联规则推荐
基于关联规则的推荐是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。关联规则挖掘可以发现不同商品在销售过程中的相关性,在零 售业中已经得到了成功的应用。管理规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集Y,其直观的意义就是用户在购 买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会同时购买面包。算法的第一步关联规则的发现最为关键且最耗时,是算法的瓶颈,但可以离线进行。其次,商品名称的同义性问题也是关联规则的一个难点。
基于隐语义模型
隐语义模型通过矩阵分解建立用户和隐类之间的关系,物品和隐类之间的关系,最终得到用户对物品的偏好关系。
利用隐语义模型主要解决了以下问题
分类的可靠性。分类来自对用户行为的统计,代表了用户对物品分类的看法。
可控制分类的粒度。允许我们自己指定有多少个隐类。
将一个物品多类化。通过统计用户行为来决定某物品在每个类中的权重。
其他算法
-
基于效用推荐
建立在对用户使用项目的效用情况上计算的,其核心问题是怎么样为每一个用户去创建一个效用函数,因此,用户资料模型很大 程度上是由系统所采用的效用函数决定的。基于效用推荐的好处是它能把非产品的属性,如提供商的可靠性和产品的可得性等考虑到效用计算中。
-
基于知识推荐
在某种程度是可以看成是一种推理技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因 它们所用的功能知识不同而有明显区别。效用知识是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以 是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
-
组合推荐
最简单的做法就是分别用基于内容的方法和协同过滤推荐方法 去产生一个推荐预测结果,然后用某方法组合其结果。尽管从理论上有很多种推荐组合方法,但在某一具体问题中并不见得都有效,组合推荐一个最重要原则就是通 过组合后要能避免或弥补各自推荐技术的弱点。
先验知识
首先理解用户的行为将会推荐产生什么样的作用:

对于不同的用户和不同的商品我们如何计算相似度是个问题.
欧几里得距离
![]()
皮尔逊相关系数
对于皮尔逊相关系数的求解我们需要了解:
协方差
皮尔逊相关系数
它是通过协方差出于两个变量的标准差得到的,如果p>0正相关p<0负相关
余弦相似度
![]()
推荐系统的目标
-
用户满意性:首当其冲的,推荐系统主要就是为了满足用户的需求,因此准确率是评判一个推荐系统好坏的最关键指标。
-
多样性:虽然推荐系统最主要还是满足用户的兴趣,但是也要兼顾内容的多样性,对于权重不同的兴趣都要做到兼顾。
-
新颖性:用户看到的内容是那些他们之前没有听说过的物品。简单的做法就是在推荐列表去掉用户之前有过行为的那些内容。
-
惊喜度:和新颖性类似,但新颖性只是用户没看到过的但是确实是和他行为是相关的,而惊喜度是用户既没有看过和他之前的行为也不相关,但用户看到后的确是喜欢的。
-
实时性:推荐系统要根据用户的上下文来实时更新推荐内容,用户的兴趣也是随着时间而改变的,需要实时更新。
-
推荐透明度:对于用户看到的最终结果,要让用户知道推荐此内容的原因。比如,“买过这本书的人同时也买过”、”你购买过的xx和此商品类似”。
-
覆盖率:挖掘长尾内容也是推荐系统很重要的目标。因此,推荐的内容覆盖到的内容越多越好。
推荐方式
-
热门推荐:就是热门排行榜的概念。这种推荐方式不仅仅在IT系统,在平常的生活中也是处处存在的。这应该是效果最好的一种推荐方式,毕竟热门推荐的物品都是位于曝光量比较高的位置的。
-
人工推荐:人工干预的推荐内容。相比于依赖热门和算法来进行推荐。一些热点时事如世界杯、nba总决赛等就需要人工加入推荐列表。另一方面,热点新闻带来的推荐效果也是很高的。
-
相关推荐:相关推荐有点类似于关联规则的个性化推荐,就是在你阅读一个内容的时候,会提示你阅读与此相关的内容。
-
个性化推荐:基于用户的历史行为做出的内容推荐。也是本文主要讲述的内容。
其中,前三者是和机器学习没有任何关系的,但却是推荐效果最好的三种方式。一般说来,这部分内容应该占到总的推荐内容的80%左右,另外20%则是对长尾内容的个性化推荐。
构建方式

在线构建
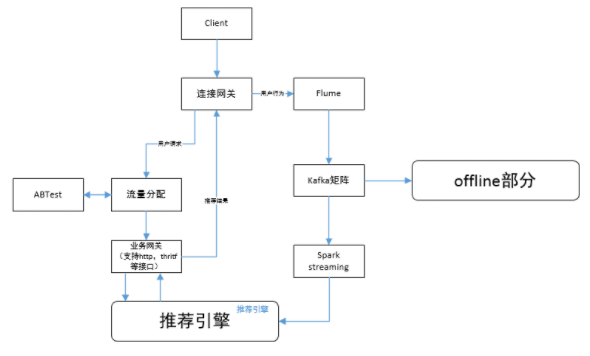
在线推荐系统核心模块
-
业务网关,推荐服务的入口,负责推荐请求的合法性检查,组装请求响应的结果。
-
推荐引擎,推荐系统核心,包括online逻辑,召回、过滤、特征计算、排序、 多样化等处理过程。
构建一个推荐系统
如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?

如何确定一个用户是不是和你有相似的品位?如何将邻居们的喜好组织成一个排序的目录?
协同过滤
协同过滤,是首次被用于推荐系统上的技术,至今仍是最简单且最有效的。协同过滤的过程分为这三步:
-
开始,收集用户信息,
-
以此生成矩阵来计算用户关联,
-
最后作出高可信度的推荐。
这种技术分为两大类:一种基于用户,另一种则是基于组成环境的物品。
协同过滤
基于用户的协同过滤

基于用户的协同过滤本质上是寻找与我们的目标用户具有相似品味的用户。也就是基于用户的协同过滤要解决的问题
-
已知用户评分矩阵Matrix R(一般都是非常稀疏的)
-
推断矩阵中空格empty cells处的值
因此基于用户的协同过滤存在两个问题:
-
稀疏问题
-
人是善变的
-
数百万的用户计算
-
对于一个新用户,很难找到邻居用户。
-
对于一个物品,所有最近的邻居都在其上没有多少打分。
基础解决方案
-
相似度计算最好使用皮尔逊相似度
-
考虑共同打分物品的数目,如乘上min(n,N)/N n:共同打分数 N:指定阈值
-
对打分进行归一化处理
-
设置一个相似度阈值
基于物品的协同过滤
基于物品的协同过滤过程很简单。两个物品的相似性基于用户给出的评分来算出。
对于基于用户而言基于物品的计算性能高,通常用户数量远大于物品数量可预先计算保留,物品并不善变。
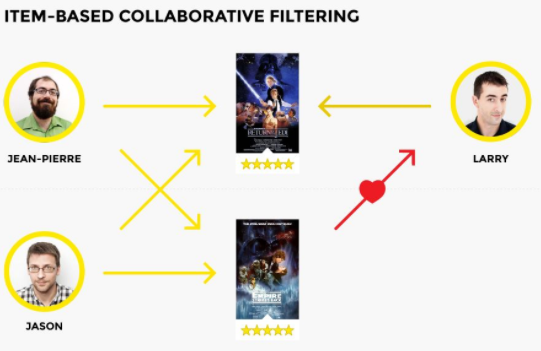
这里的相似度是根据列而不是行来计算的(与上面的用户-电影矩阵中所见的不同)。基于物品的协同过滤常常受到青睐,因为它没有任何基于用户的协同过滤的缺点。首先,系统中的物品(在这个例子中物品就是电影)不会随着时间的推移而改变,所以推荐会越来越具有关联性。
下面看一下再基于物品推荐的系统中,相似度的计算方式:
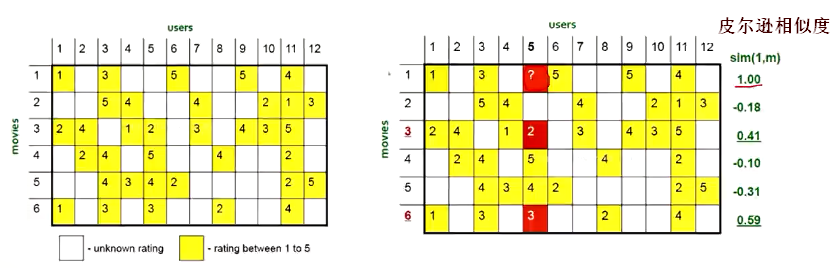
比如上图最右面是1号电影与其他电影的皮尔逊相似度。
对于上图3号电影和六号电影最相似,所以可以进行权重化处理:
如果2.6大于阈值就推荐,小于阈值不推荐。
冷启动问题
用户冷启动问题
-
引导用户把自己的一些属性表达出来
-
利用现有的开放数据平台
-
根据用户注册属性
-
推荐排行榜单
物品冷启动问题
-
文本分析
-
主题模型
-
打标签
-
推荐排行榜单
协同过滤的比较
| 基于用户 | 基于商品 | |
|---|---|---|
| 性能 | 适用于用户较少 | 适用于物品明显小于人数的场合 |
| 领域 | 用户个性化兴趣需求不高 | 用户个性化需求强烈 |
| 实时性 | 不一定 | 一定 |
| 冷启动 | 用户对少量物品产生行为后,不会立即计算,因为用户相似度是离线计算的。 | 新用户只要对物品产生欣慰,就会进行物品推荐。 |
| 推荐理由 | 很难提供让用户信服的推荐解释。 | 根据用户历史行为归纳推荐理由。 |
| 使用场所 | 时事新闻,突发状况 | 图书,电子商务,电影 |
隐语义模型
隐语义模型的核心思想是通过隐含特征联系用户兴趣和物品,采取基于用户行为统计的自动聚类。
从数据出发,进行个性化推荐,研究的是用户和物品之间有着隐含的联系,所以只要计算机能理解隐含因子就好,简单来说将用户和物品通过中介隐含因子联系起来。
隐语义模型需要解决四个问题:
-
如何给物品进行分类
-
如何确定用户对哪些类的物品感兴趣以及感兴趣的程度
-
对于一个给定的类,选择哪些属于这个类的物品推荐给用户
-
如何确定物品在一个类中的权重
解决的过程分两步:
1,分解:

2,组合:
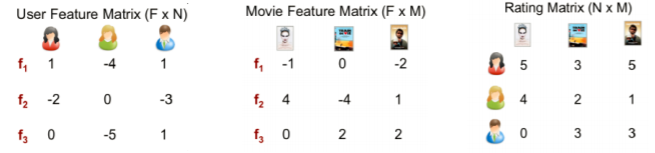
隐语义模型的公式:
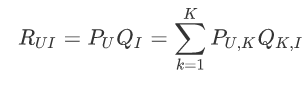
其中P(U,K)代表用户U对于第k个隐类的兴趣度量,Q(K,I)代表第k个隐类和物品I之间的关系,对每个用户,要保证正负样本的平衡(数目相似)。 对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。
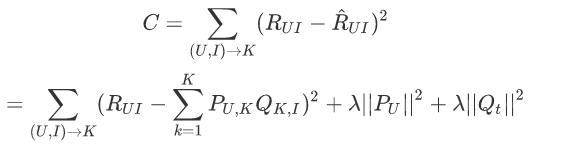
很类似于svd或者特征分解:

对于隐语义模型我们可以把它当作一般的机器学习的模型进行求解:
梯度下降方向:

迭代求解:
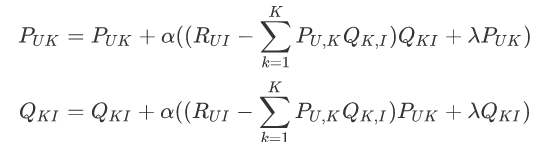
隐语义模型负样本选择
-
对每个用户,要保证正负样本的平衡(数目相似)
-
选取那些很热门,而用户却没有行为的物品
-
对于用户—物品集K {(u,i)}其中如果(u, i)是正样本,则有 𝑟 𝑢𝑖 = 1,负样本则𝑟 𝑢𝑖 = 0
隐语义模型参数选择
-
隐特征的个数F,通常F=100
-
学习速率alpha,别太大
-
正则化参数lambda,别太大
-
负样本/正样本比例 ratio
协同过滤和隐语义模型的比较
| 原理 | 空间复杂度 | 实时推荐 | 可解释性 | |
|---|---|---|---|---|
| 协同过滤 | 基于统计 | 大 | 难 | 较好 |
| 隐语义模型 | 基于建模 | 小 | NaN | 无法解释 |
关联规则
关联分析中最有名的例子是“尿布与啤酒”。据报道,美国中西部的一家连锁店发现,男人们会在周四购买尿布和啤酒。这样商店实际上可以将尿布与啤酒放在一块,并确保在周四全价销售从而获利。当然,这家商店并没有这么做。
模型的评估
准确率

召回率
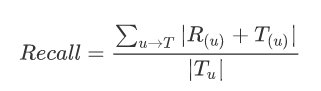
覆盖率
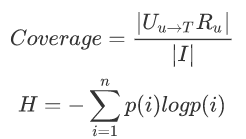
多样性

简单设计一个feed流推荐系统
从框架的角度看,推荐系统基本可以分为数据层、召回层、排序层。
数据层包括数据生成和数据存储,主要是利用各种数据处理工具对原始日志进行清洗,处理成格式化的数据,落地到不同类型的存储系统中,供下游的算法和模型使用。
sessionlog:对原始数据进行清洗合并,sessionlog一般就是清洗合并后的数据,后续的算法和统计都是根据sessionlog进行再加工。
userprofile:对用户属性和行为等信息进行采集和统计,为后续算法提供特征支持。
itemDoc:对视频、商品等属性、曝光、点击等字段进行统计, 为后续算法提供特征支持。
召回层主要是从用户的历史行为、实时行为等角度利用各种触发策略产生推荐的候选集,对不同的策略和算法产生的候选集进行融合并按照产品规则进行过滤,一般融合和过滤后的候选集还是比较多的,一次线上请求过来之后线上系统无法对那么多的候选集进行排序,所以在召回层一般还会有粗排序,对融合的候选集进行一次粗排序,过滤掉粗排分数较低的候选集。
排序层主要是利用机器学习的模型对召回层筛选出来的候选集进行精排序。
参考链接:
https://www.cnblogs.com/redbear/p/8594939.html
代码实现
首先下载模块:
pip install numpy
pip install surprise
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
解决链接:
https://devblogs.microsoft.com/python/unable-to-find-vcvarsall-bat/

点击安装Visual C++ Build Tools 2015
Surprise 使用
Surprise里有自带的数据集,自带的数据集加载方法和加载自己数据集的方法不同。加载项目提供的数据集就不多说了,这里重点说下Surprise怎么加载自己本地的数据集以及经常使用的方法。
官方API提供了加载本地数据集的方法:
上面说到如何加载自己的数据集,如果要加载自己的数据集,提供了两种加载方式:
-
可以使用官方定义的split()方法来定义k次交叉实验
-
如果你自己以及分割好k次实验的数据集,那么可以定义一个list来进行训练和测试
事实上,我们更倾向于使用第一种方法,因为系统自动给你进行k次实验,不用我们分割数据集,简单又方便
下面是Surprise的官网,自行学习:
https://surprise.readthedocs.io/en/stable/index.html
它是个开源的项目,现在已经3327颗星了:
https://github.com/NicolasHug/Surprise
from surprise import KNNBasic,SVD from surprise import Dataset from surprise import evaluate, print_perf # http://surprise.readthedocs.io/en/stable/index.html # http://files.grouplens.org/datasets/movielens/ml-100k-README.txt # 加载movielens-100k数据 data = Dataset.load_builtin('ml-100k') # 三折的交叉验证 data.split(n_folds=3) # 使用KNNBasic算法. algo = KNNBasic() # 直接对模型进行评估 模型 数据 评估方法 perf = evaluate(algo, data, measures=['RMSE', 'MAE']) # 打印三者交叉验证的结果 print_perf(perf)
没有的话会自行下载:
Dataset ml-100k could not be found. Do you want to download it? [Y/n] Y
Trying to download dataset from http://files.grouplens.org/datasets/movielens/ml-100k.zip...
Done! Dataset ml-100k has been saved to C:\Users\Tim/.surprise_data/ml-100k
Evaluating RMSE, MAE of algorithm KNNBasic.
Fold 1
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9912
MAE: 0.7841
------------
Fold 2
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9856
MAE: 0.7779
------------
Fold 3
Computing the msd similarity matrix...
Done computing similarity matrix.
RMSE: 0.9901
MAE: 0.7820
------------
------------
Mean RMSE: 0.9890
Mean MAE : 0.7813
------------
------------
Fold 1 Fold 2 Fold 3 Mean
RMSE 0.9912 0.9856 0.9901 0.9890
MAE 0.7841 0.7779 0.7820 0.7813
进行网格搜索,调参:
from surprise import GridSearch param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005], 'reg_all': [0.4, 0.6]} grid_search = GridSearch(SVD, param_grid, measures=['RMSE', 'FCP']) data = Dataset.load_builtin('ml-100k') data.split(n_folds=3) grid_search.evaluate(data)
Running grid search for the following parameter combinations:
{'n_epochs': 5, 'lr_all': 0.002, 'reg_all': 0.4}
{'n_epochs': 5, 'lr_all': 0.002, 'reg_all': 0.6}
{'n_epochs': 5, 'lr_all': 0.005, 'reg_all': 0.4}
{'n_epochs': 5, 'lr_all': 0.005, 'reg_all': 0.6}
{'n_epochs': 10, 'lr_all': 0.002, 'reg_all': 0.4}
{'n_epochs': 10, 'lr_all': 0.002, 'reg_all': 0.6}
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.6}
Resulsts:
{'n_epochs': 5, 'lr_all': 0.002, 'reg_all': 0.4}
{'RMSE': 0.99752355169672, 'FCP': 0.6828764038256762}
----------
{'n_epochs': 5, 'lr_all': 0.002, 'reg_all': 0.6}
{'RMSE': 1.0036114298079644, 'FCP': 0.6864820271919688}
----------
{'n_epochs': 5, 'lr_all': 0.005, 'reg_all': 0.4}
{'RMSE': 0.9739881040534231, 'FCP': 0.6943239599723144}
----------
{'n_epochs': 5, 'lr_all': 0.005, 'reg_all': 0.6}
{'RMSE': 0.9828300722598335, 'FCP': 0.6951684436793814}
----------
{'n_epochs': 10, 'lr_all': 0.002, 'reg_all': 0.4}
{'RMSE': 0.978251611036654, 'FCP': 0.6922462083497581}
----------
{'n_epochs': 10, 'lr_all': 0.002, 'reg_all': 0.6}
{'RMSE': 0.9864443833611268, 'FCP': 0.6937794974063309}
----------
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}
{'RMSE': 0.9640842837533002, 'FCP': 0.6979378525887773}
----------
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.6}
{'RMSE': 0.9739328313566187, 'FCP': 0.6985452018436566}
# RMSE score的最好值 print(grid_search.best_score['RMSE']) # RMSE score最好的时候对应的参数 print(grid_search.best_params['RMSE']) # FCP score的最好值 print(grid_search.best_score['FCP']) # FCP score最好的时候对应的参数 print(grid_search.best_params['FCP'])
0.9640842837533002
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}
0.6985452018436566
{'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.6}
import pandas as pd # 把数据形成DataFrame查看 results_df = pd.DataFrame.from_dict(grid_search.cv_results) results_df
from __future__ import (absolute_import, division, print_function, unicode_literals) import os import io from surprise import KNNBaseline from surprise import Dataset def read_item_names(): file_name = ('./ml-100k/u.item') rid_to_name = {} name_to_rid = {} with io.open(file_name, 'r', encoding='ISO-8859-1') as f: for line in f: line = line.split('|') rid_to_name[line[0]] = line[1] name_to_rid[line[1]] = line[0] return rid_to_name, name_to_rid # 加载数据 data = Dataset.load_builtin('ml-100k') # 转换成标准的矩阵形式 trainset = data.build_full_trainset() # 选择皮尔逊相似度,我们对user_based =False 使用物品过滤 sim_options = {'name': 'pearson_baseline', 'user_based': False} algo = KNNBaseline(sim_options=sim_options) # 训练数据集 algo.train(trainset) # 构建一个函数通过名字找到rid rid_to_name, name_to_rid = read_item_names() toy_story_raw_id = name_to_rid['Now and Then (1995)'] #根据rid找到该数据再原来矩阵中的inner_id toy_story_inner_id = algo.trainset.to_inner_iid(toy_story_raw_id) # 找到最近的10个电影inner_id toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=10) print(toy_story_neighbors) # 进行推荐 # 将inner_id 转换 rid toy_story_neighbors = (algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors) # 将rid转换成na'me toy_story_neighbors = (rid_to_name[rid] for rid in toy_story_neighbors) print() print('The 10 nearest neighbors of Toy Story are:') for movie in toy_story_neighbors: print(movie)
The 10 nearest neighbors of Toy Story are:
While You Were Sleeping (1995)
Batman (1989)
Dave (1993)
Mrs. Doubtfire (1993)
Groundhog Day (1993)
Raiders of the Lost Ark (1981)
Maverick (1994)
French Kiss (1995)
Stand by Me (1986)
Net, The (1995)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号