TensorFlow笔记-文件读取
这些只用于可以完全加载到内存中的小型数据集:
1,储存在常数中
2,储存在变量中,初始化后,永远不改变它的值
training_data = ... training_labels = ... with tf.Session(): input_data = tf.constant(training_data) input_labels = tf.constant(training_labels)
training_data = ... training_labels = ... with tf.Session() as sess: data_initializer = tf.placeholder(dtype=training_data.dtype, shape=training_data.shape) label_initializer = tf.placeholder(dtype=training_labels.dtype, shape=training_labels.shape) input_data = tf.Variable(data_initalizer, trainable=False, collections=[]) input_labels = tf.Variable(label_initalizer, trainable=False, collections=[]) ... sess.run(input_data.initializer, feed_dict={data_initializer: training_data}) sess.run(input_labels.initializer, feed_dict={label_initializer: training_lables})
设定collections=[]可以防止GraphKeys.VARIABLES收集后做为保存和恢复的中断点。设定这些标志,是为了减少额外的开销。
文件读取:
标准TensorFlow格式
TensorFlow还提供了一种内置文件格式TFRecord,二进制数据和训练类别标签数据存储在同一文件。模型训练前图像等文本信息转换为TFRecord格式。TFRecord文件是protobuf格式。数据不压缩,可快速加载到内存。TFRecords文件包含 tf.train.Example protobuf,需要将Example填充到协议缓冲区
-
tf.train.string_input_producer(string_tensor, num_epochs=None, shuffle=True, seed=None, capacity=32, name=None)
产生指定文件张量
文件阅读器类
-
class tf.TextLineReader
阅读文本文件逗号分隔值(CSV)格式
-
tf.FixedLengthRecordReader
要读取每个记录是固定数量字节的二进制文件
-
tf.TFRecordReader
读取TfRecords文件
由于从文件中读取的是字符串,需要函数去解析这些字符串到张量
-
tf.decode_csv(records,record_defaults,field_delim = None,name = None)将CSV转换为张量,与tf.TextLineReader搭配使用
-
tf.decode_raw(bytes,out_type,little_endian = None,name = None) 将字节转换为一个数字向量表示,字节为一字符串类型的张量,与函数tf.FixedLengthRecordReader搭配使用
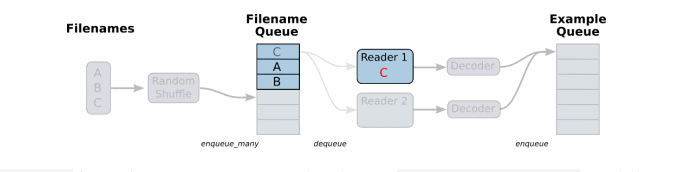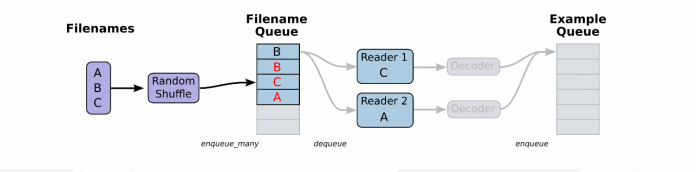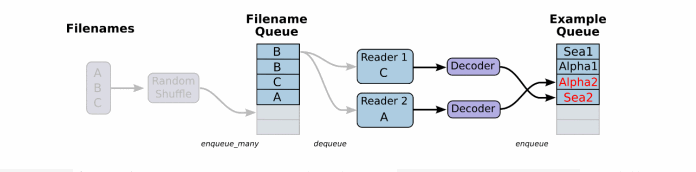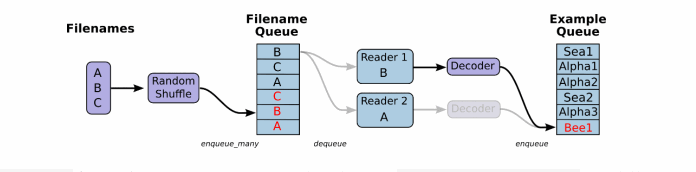
string_input_producer来生成一个先入先出的队列,文件阅读器会需要它们来取数据。string_input_producer提供的可配置参数来设置文件名乱序和最大的训练迭代数,QueueRunner会为每次迭代(epoch)将所有的文件名加入文件名队列中,如果shuffle=True的话,会对文件名进行乱序处理。
一过程是比较均匀的,因此它可以产生均衡的文件名队列。
这个QueueRunner工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。
根据你的文件格式,选择对应的文件阅读器,然后将文件名队列提供给阅读器的 read 方法。阅读器的read方法会输出一个键来表征输入的文件和其中纪录(对于调试非常有用),同时得到一个字符串标量,这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
# 读取CSV格式文件 # 1、构建文件队列 # 2、构建读取器,读取内容 # 3、解码内容 # 4、现读取一个内容,如果有需要,就批处理内容 import tensorflow as tf import os def readcsv_decode(filelist): """ 读取并解析文件内容 :param filelist: 文件列表 :return: None """ # 把文件目录和文件名合并 flist = [os.path.join("./csvdata/",file) for file in filelist] # 构建文件队列 file_queue = tf.train.string_input_producer(flist,shuffle=False) # 构建阅读器,读取文件内容 reader = tf.TextLineReader() key,value = reader.read(file_queue) record_defaults = [["null"],["null"]] # [[0],[0],[0],[0]] # 解码内容,按行解析,返回的是每行的列数据 example,label = tf.decode_csv(value,record_defaults=record_defaults) # 通过tf.train.batch来批处理数据 example_batch,label_batch = tf.train.batch([example,label],batch_size=9,num_threads=1,capacity=9) with tf.Session() as sess: # 线程协调员 coord = tf.train.Coordinator() # 启动工作线程 threads = tf.train.start_queue_runners(sess,coord=coord) # 这种方法不可取 # for i in range(9): # print(sess.run([example,label])) # 打印批处理的数据 print(sess.run([example_batch,label_batch])) coord.request_stop() coord.join(threads) return None if __name__=="__main__": filename_list = os.listdir("./csvdata") readcsv_decode(filename_list)
如果输入的参数有缺失,record_default参数可以根据张量的类型来设置默认值。在调用run或者eval去执行read之前,你必须调用tf.train.start_queue_runners来将文件名填充到队列。否则read操作会被阻塞到文件名队列中有值为止。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号