
Spark-windows安装
Spark
目的:达到能在pycharm中测试
1.安装必要的文件:
jdk测试:java -version
Anaconda测试: 打开Anaconda Prompt输入conda list
spark测试(注意spark的安装路径不能有空格):spark-shell

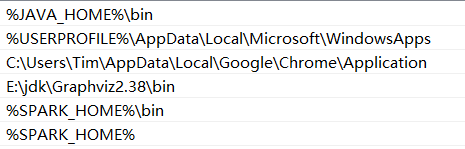
2.配置环境变量
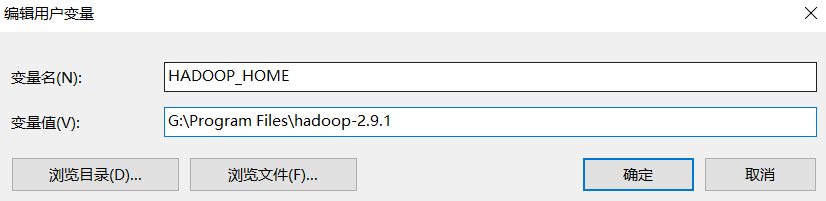
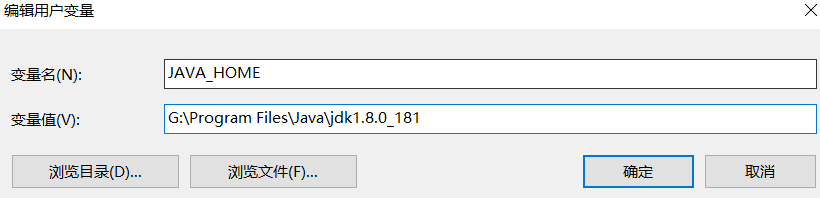
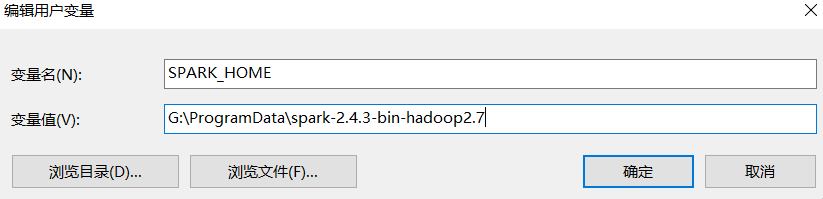
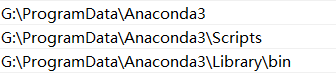
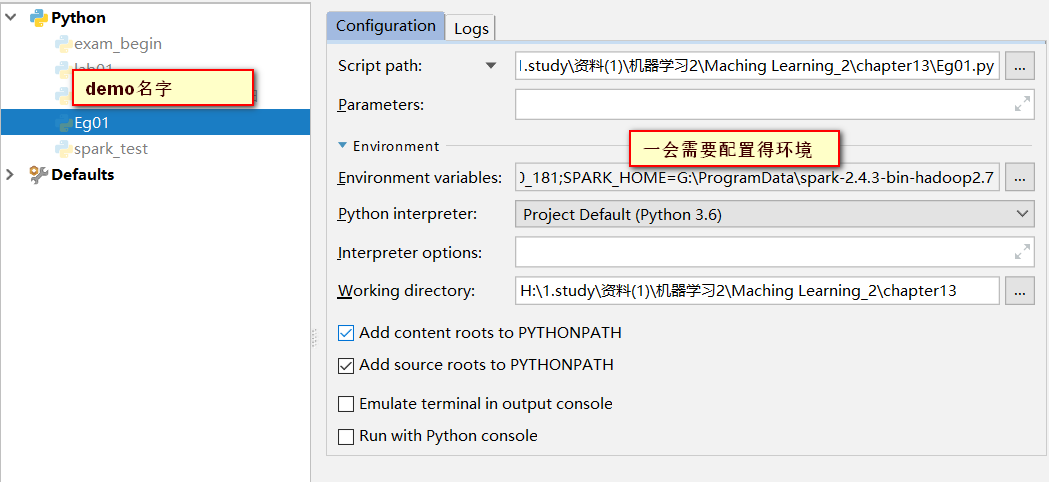
3.打开pycharm测试
import os from pyspark import SparkConf, SparkContext os.environ['JAVA_HOME']='G:\Program Files\Java\jdk1.8.0_181' conf = SparkConf().setMaster('local[*]').setAppName('word_count') sc = SparkContext(conf=conf) d = ['a b c d', 'b c d e', 'c d e f'] d_rdd = sc.parallelize(d) rdd_res = d_rdd.flatMap(lambda x: x.split(' ')).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a+b) print(rdd_res) print(rdd_res.collect())

运行结果:
G:\ProgramData\Anaconda3\python.exe "H:/1.study/资料(1)/机器学习2/Maching Learning_2/chapter13/spark_test.py" 19/07/18 17:12:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). PythonRDD[5] at RDD at PythonRDD.scala:53 [('a', 1), ('e', 2), ('b', 2), ('c', 3), ('d', 3), ('f', 1)] Process finished with exit code 0
利用spark求圆周率代码
import random import os from pyspark import SparkConf, SparkContext os.environ['JAVA_HOME']='G:\Program Files\Java\jdk1.8.0_181' conf = SparkConf().setMaster('local[*]').setAppName('word_count') sc = SparkContext(conf=conf) NUM_SAMPLES = 100000 def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, NUM_SAMPLES)).filter(inside).count() print("π粗糙的值: %f" % (4.0 * count / NUM_SAMPLES))
得到结果:
[Stage 0:============================================> (6 + 2) / 8]
π粗糙的值: 3.129680

 浙公网安备 33010602011771号
浙公网安备 33010602011771号