

Hadoop综合大作业
本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
前言
本次作业是在《爬虫大作业》的基础上进行的,在《爬虫大作业》中,我主要对拉勾网python岗位的招聘信息进行的数据爬取,最终得到了18813条数据存在一个名为ctt.xls中。本次作业的任务主要有以下三点:
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
2.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据
3.用Hive对爬虫大作业产生的进行数据分析
大数据分析
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS

其次,我们把ctt.csv文件放到下载这个文件夹中,并使用命令把ctt.csv文件拷贝到我们刚刚所创建的文件夹中,如图:


启动hadoop,如图:
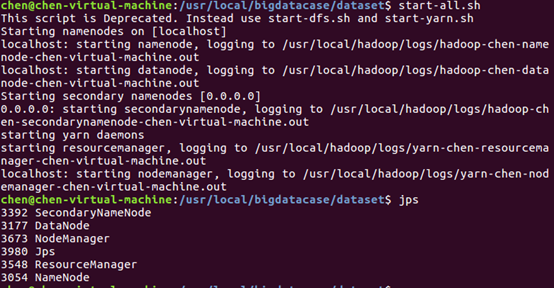
最后,我们把本地的文件上传至HDFS中,如图:
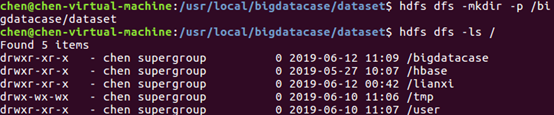

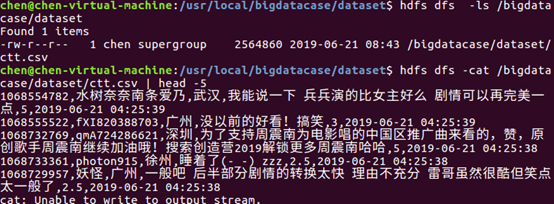
2.把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,如图:

其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,如图:

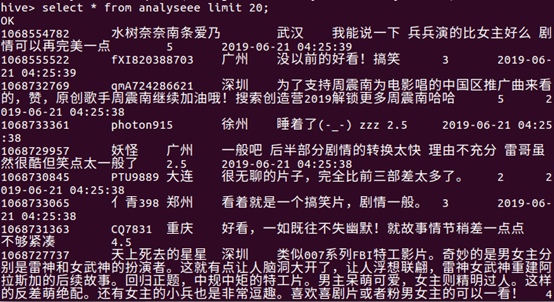
3.用Hive对爬虫大作业产生的进行数据分析
①.用户满意度分析:
通过查询用户评分每个分值的数量统计,然后进行分析,获取的数据如图所示:
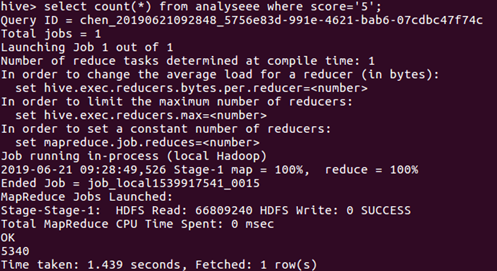
评分为“5”的统计
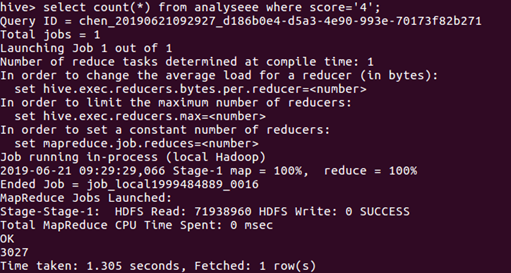
评分为“4”的统计
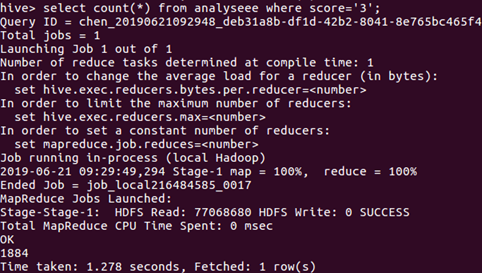
评分为“3”的统计

评分为“2”的统计
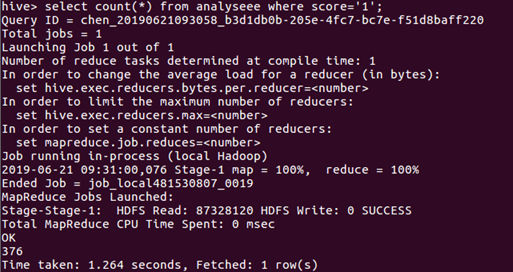
评分为“1”的统计
根据上述统计,对分析数据进行了饼图的统计,如图:
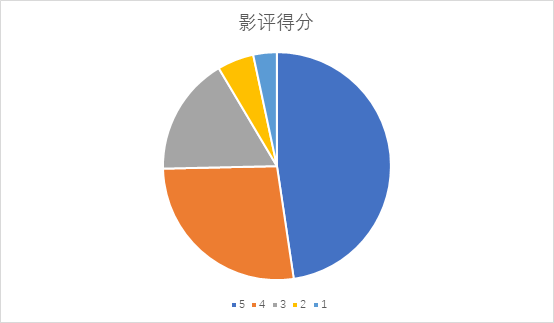
由上图可得,该影片得到五分的评价占绝大部分的。
在通过平均得分来分析该影片是否被大众喜爱,如图:

由统计可得,该影片平均评价得分为3.6,属中上得分,说明这部影片还是被绝大部分观众所认可的。
2.用户所在城市分析
统计出粉丝所在城市数量最多的20个城市,如图:

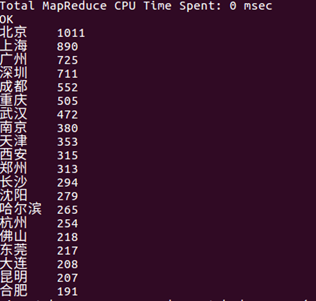
评分星级大于4的粉丝集中所在的排名前20的城市。

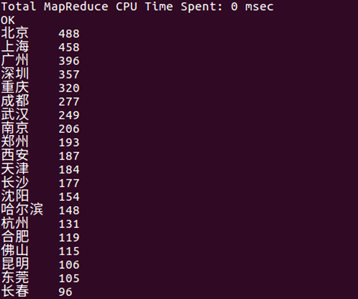
从数据可以看出发表影评的绝大部分为一二线城市,他们为该电影票房提供了不少的GDP。
3.观众对影片的关注度
一部电影一般分为预售期和放映期,而这些影评绝大部分会发生在预售阶段和放映阶段,而这些影评则会成为该电影的应该评分标准。
同时在首映当天绝大部分可以体现出该电影的好坏程度。票房也可以通过首映体现。故对该影片首映前后的评价进行了统计:
首映前:

首映后:
由此可知,在首映前大家关注明显还不是很高,放映后随着时间的积累关注度也在上升。
4.观众观看时间分析
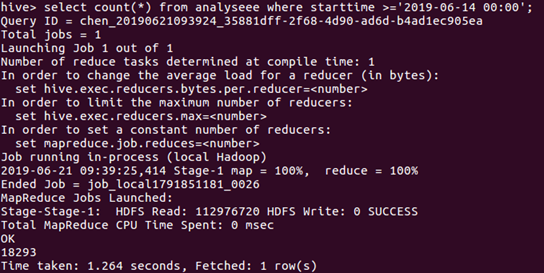
根据首映时间已经城市影评量进行了首映前十影评量的城市的统计:

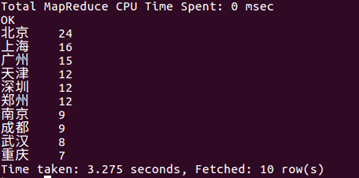
由此可知,一线城市首映当天的影评量最高。
于是接着统计一下上映6天每天的数量,由于数据中的日期数据类型比较特殊,如果直接统计需要进行数据类型转化有点麻烦,故我各自统计了每天的数量
由图下的语句进行统计6月14日的数量,类推得到6天每天的数量。
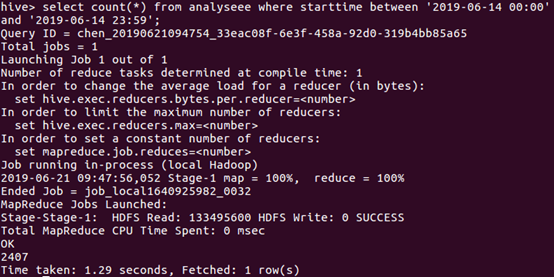
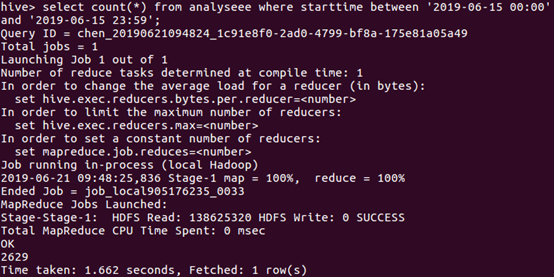
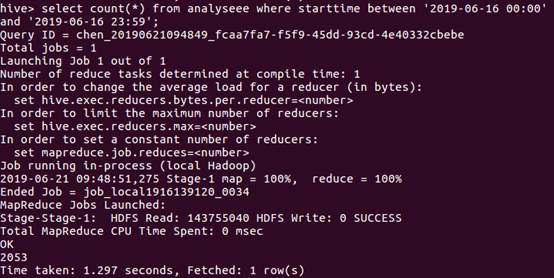
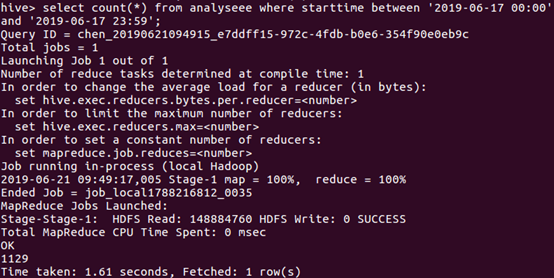
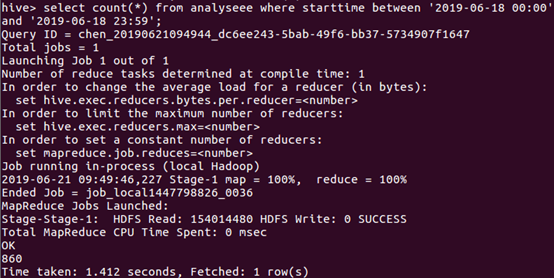

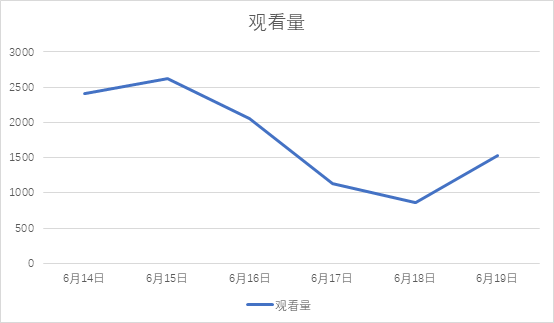
由上统计出折线图反馈每天的观看量:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号