centos7安装ambari教程
ambari版本 :2.4.2 (不过各版本安装过程没啥差异)
目录:
- 为什么要用Ambari
- 概念概述
- 版本信息
- 原理简介
- 安装
- 创建集群
- 安装SmartSense
- 二次开发
- Ambari的升级
- 相关错误
为什么要用Ambari
Ambari 是 Apache Software Foundation 中的一个顶级项目。就 Ambari 的作用来说,就是创建、管理、监视 Hadoop 的整个生态圈产品(例如 Hive,Hbase,Sqoop,Zookeeper 等)。用一句话来说,Ambari 就是为了让 Hadoop 以及相关的大数据软件更容易使用的一个工具。
对于那些苦苦花费好几天去安装、调试 Hadoop 的初学者是最能体会到 Ambari 的方便之处的。而且,Ambari 现在所支持的平台组件也越来越多,例如流行的 Spark,Storm 等计算框架,以及资源调度平台 YARN 等,我们都能轻松地通过 Ambari 来进行部署。
概念概述
- Stack :堆 版本号 一批Service的集合
- Service:产品 如Hive,HBase等
- Module:Service中的一部分
- Alert:警告
- Host:节点 可以理解为一个虚拟机
- Ambari Agent:每个Host上的管理员
- Ambari Server:通过与每个Agent保持通话,操控并了解所有信息(host、service等运行情况和资源状态)并提供GUI
- View:ambari通过框架 Ambari Views framework ,允许第三方对组件进行扩展,如hdfs的目录管理等。目前支持Tez、Hive、Pig、Capacity Scheduler(YARN)、Files(HDFS)
版本情况
针对各版本的HortOnWork官方文档: http://docs.hortonworks.com/HDPDocuments/Ambari/Ambari-2.4.2.0/index.html
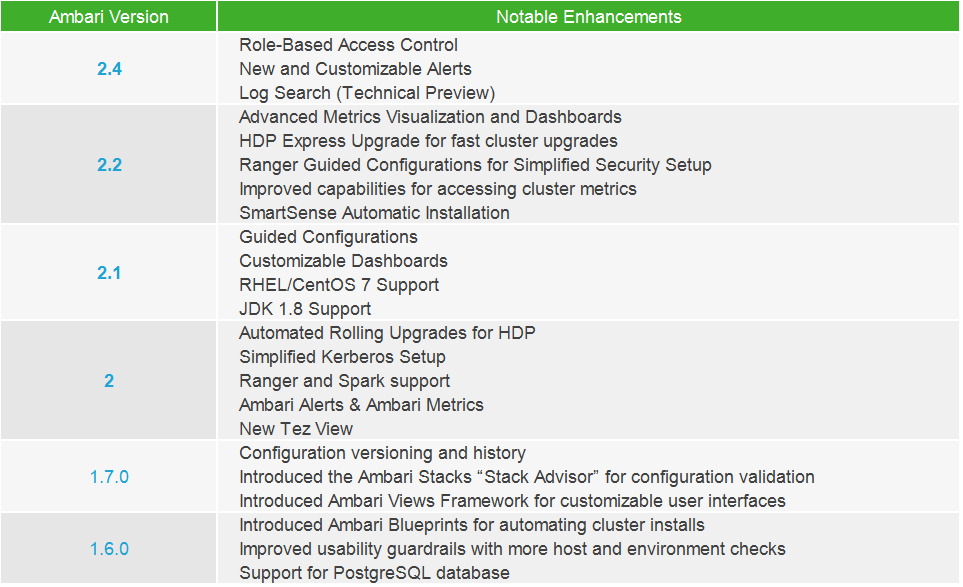
原理简介
Ambari 自身也是一个分布式架构的软件,主要由两部分组成:Ambari Server 和 Ambari Agent。简单来说,用户通过 Ambari Server 通知 Ambari Agent 安装对应的软件;Agent 会定时地发送各个机器每个软件模块的状态给 Ambari Server,最终这些状态信息会呈现在 Ambari 的 GUI,方便用户了解到集群的各种状态,并进行相应的维护。
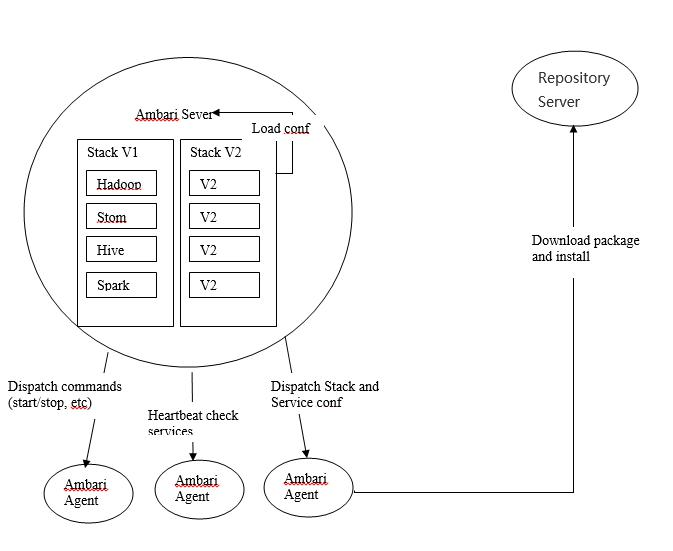
安装
安装须知:
- 所有操作都要使用root用户,且系统不要有其他用户,ssh的密钥也都是基于root用户的。否则会出现问题【Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password) 】
- hostname都要使用FQDN格式,具体参照【配置】的第三步
- 所有节点都安装ntpd服务 可参考CentOS7 中使用NTP进行时间同步
- 切记 一定要从空机装起,尤其是以前搭过hadoop环境的。
- ambari使用向导(仅仅是使用)
- ambari只能管理一个集群
- 再次说明 ambari版本:2.4.2.0;操作系统:CentOS7
开始安装:
- 在 hortonworks公共资源库 选定一个ambari版本并复制对应的repo地址(这个网页的内容加载很慢 要耐心等)。我选的是2.4.2 地址是http://s3.amazonaws.com/public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari.repo。
- 使用wget下载到节点,或者下载到物理机后上传到节点
wget http://s3.amazonaws.com/public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.4.2.0/ambari.repo #文件会下载到当前目录
- 将ambari.repo文件拷贝到 /etc/yum.repos.d/ 目录下
mv ambari.repo /etc/yum.repos.d/
- 获取该公共库的所有源文件列表
yum clean all yum list|grep ambari
- 开始安装server
yum install ambari-server
ambari-server --version #查看版本如果依赖项postgresql下载失败,需要手动下载安装;点这里 下载一个并安装就可以了
wget ftp://mirror.switch.ch/pool/4/mirror/scientificlinux/7.2/x86_64/updates/security/postgresql-libs-9.2.15-1.el7_2.x86_64.rpm; rpm -ivh postgresql-libs-9.2.15-1.el7_2.x86_64.rpm
- 安装完成后,开始进行配置(全部用默认项 全程回车)。其中有一步 需要指定用户账号,要记住使用root
ambari-server setup
- 配置完成就可以启动了,然后 就可以用8080端口访问管理页面了
ambari-server start
ambari-server status #查看server启动情况
ambari-agent status #查看agent启动情况 这个创建集群成功才能使用
创建集群:
创建集群
安装成功后,就需要在WEBUI中创建集群了。点击【Launch Install Wizard】

1.GetStarted 指定集群名

2.Select Version 选择HDP版本。HDP版本对应的是一组生态组件的版本。根据自己需要的组件版本选择一个即可。我选择的是HDP-2.5
下面的内容,使用公共资源库即可(推荐把资源下载到本地,然后使用本地库。Public Repo的话需要很长时间)。【Skip ……】这个也不用选,进入下一步。
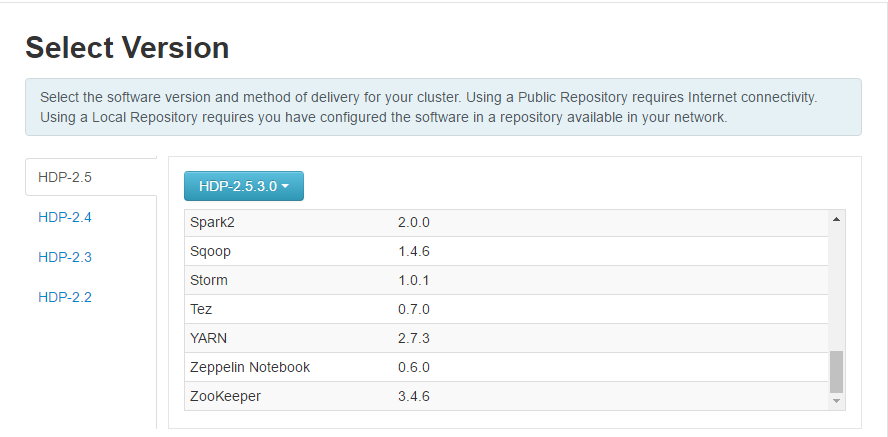


3.Install Options 安装配置。这一步要谨慎
Target Hosts要指定Hosts列表,这个hostname的格式必须是Fully Qualified Domain Name (FQDN),简单点说,必须是一个域名的格式,如下图所示。
这里输入的hostname必须与/etc/hosts一致。同时,每个节点的hostname与/etc/hosts中的设定也必须要一致。
Host Registration Information 这里要选择使用私钥,并上传作为Ambari的主机的私钥,当然也可以直接粘贴私钥的内容(建议使用文件,因为拷贝的内容会有格式问题) 注:id_dsa是私钥,id_dsa.pub 是公钥。UserAccount使用root 端口不用改
4.Confirm Hosts
从上一步过来后,在这一步会自动节点注册,并会显示进度及注册状况
可以点击①查看有哪些注册过程中缺少的内容


一般来讲这里最可能出现的就是时间没有同步(ntpd),以及THP的设置。
具体解决:
安装启动ntpd
yum -y install ntpd ntpdate time.nist.gov service ntpd start chkconfig ntpd on
禁用THP(参考 Linux 关于Transparent Hugepages的介绍)
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
5.Choose Services 选择集群中需要安装的服务
有些服务是必须得,或者是被依赖的,如果没选的 点击下一步的时候会有提示。
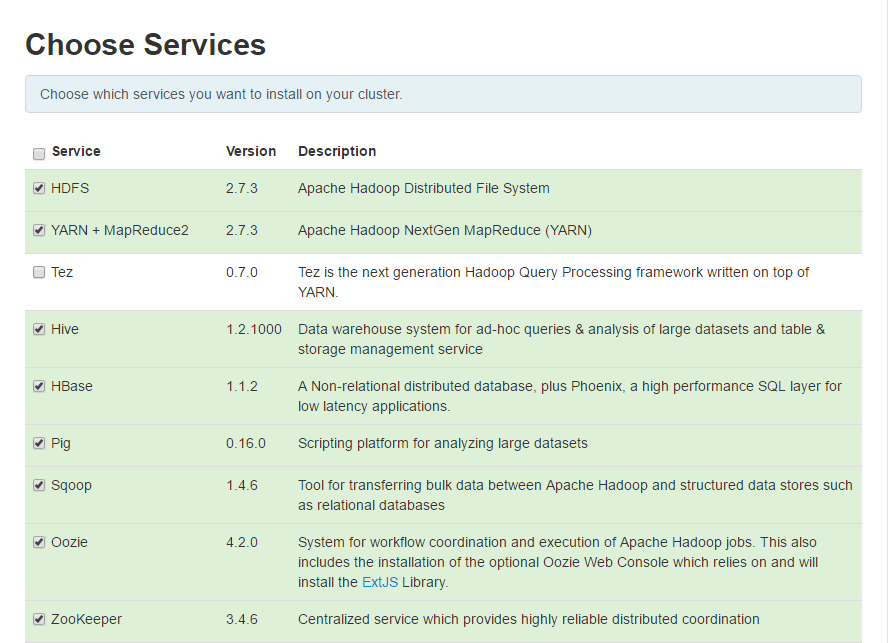
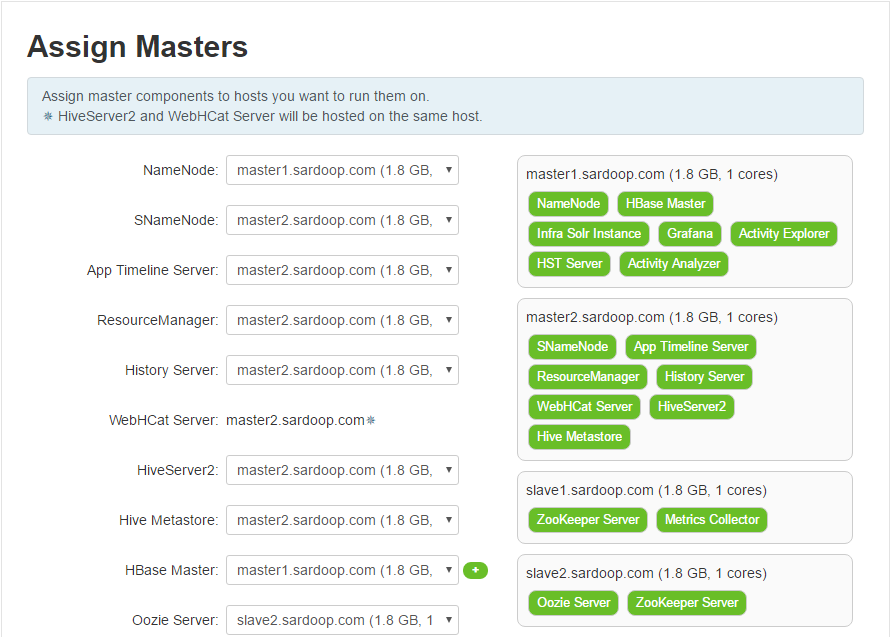
6.Assign Masters 给各节点组件分配资源,这个自己看着来就行

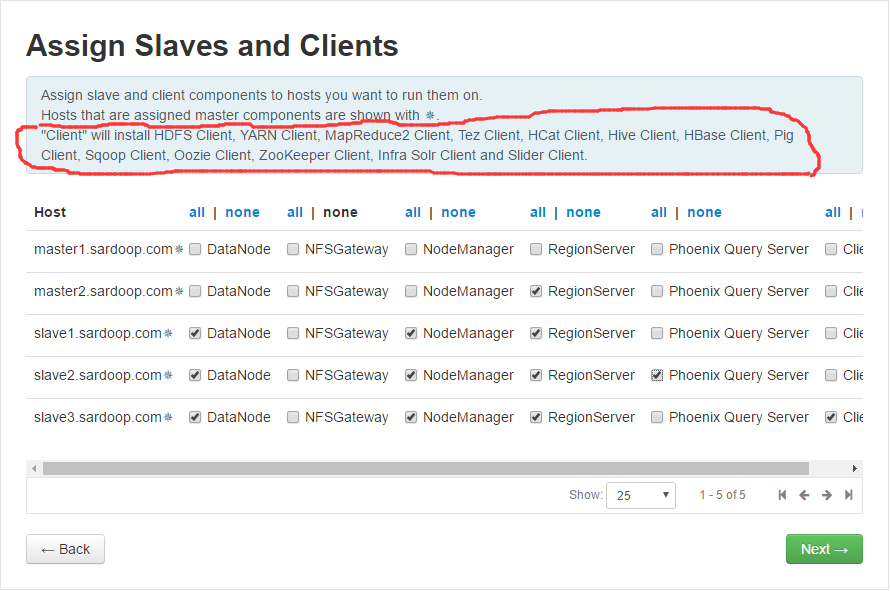
7.Assign Slaves and Clients 配置从节点和客户端。注意最后一列的Client指的是各种客户端,而不是某一种。
8.Customize Service 服务的自定义设置
这一步里大部分都可以使用默认项,少部分需要改动和设置,如Hive和Oozie需要指定数据库密码等

红色数字标志表示这一项有需要手动设置的内容。
此外,如果Hive和Oozie使用Mysql的话,还需要先安装MySql,然后创建hive,oozie用户并赋予权限,当然 还有hive、oozie数据库
具体操作可参考 CentOS7minimal MySql的卸载及安装
还要在ambari server通过以下命令设置驱动(如果没有执行这一句的话 测试hive或oozie数据库连接时会出现错误 coercing to Unicode: need string or buffer, NoneType found )
ambari-server setup --jdbc-db=mysql --jdbc-driver=[/path/to/mysql/mysql-connector-java.jar]
如果有不合适的参数,是无法进入下一步的,点击下一步的时候系统会提示需要改成的值。
9.Review 提供一个总结的安装列表,供用户审阅并提供打印功能
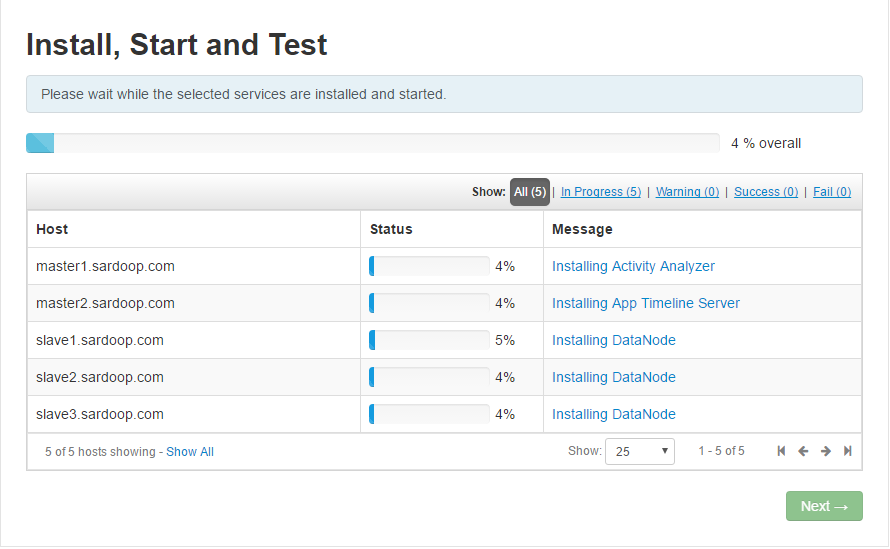
10.Install,Start and Test 开始安装和测试。这一步会花费较长时间,因为需要在线下载安装各种组件。
这一步可能会失败多次,不过不要慌 这基本是网络因素,不断重试就可以了
11.Summary 安装情况总览

我的NameNode没有启动成功,所以有警告,暂不知道是否有影响
手动修改服务配置
集群创建完了也还是有很多要手动修改的地方(如hive、oozie的元数据存储数据库)
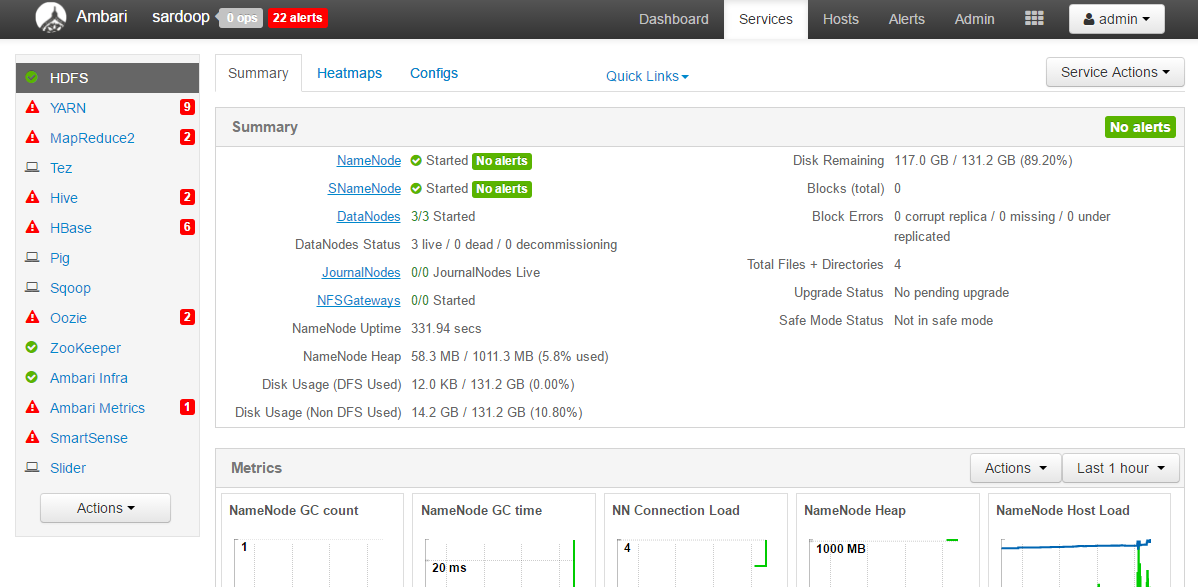
这些红彤彤的标志 都是启动失败的服务。
最开始HDFS那一项也是红的,找了一下午的错误,最终发现是因为之前的系统变量 $HADOOP_HOME 没有删掉 导致路径出现问题
明明已经unset过了 结果一重启机器又出现,并且还找不到在哪里设置的。没办法,只能设了一个软链接搞定。
又过了半天 终于弄好了 太不容易了

看到上方的红数字消失,无比激动
NameNode HA
默认安装的集群 NameNode是单点的,我们自然要给升级为HA
1.如果启动了HBase的话,我们要先关闭HBase服务
2.HDFS->Service Actions -> Enable NameNode HA

3.Get Started 指定service ID
4.Select Hosts 选择作为备用NameNode以及作为JournalNode的host
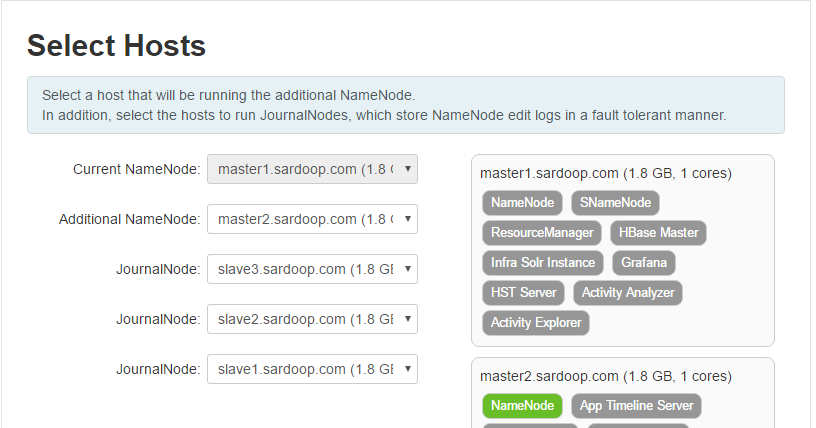
5.Review 确认上一步的设定。配置不用改动,直接下一步

6.Create Checkpoint

这一步的操作需要手动完成(启用Safe mode)。
如图所示,在NameNode所在Host先后执行两条命令
sudo su hdfs -l -c 'hdfs dfsadmin -safemode enter' sudo su hdfs -l -c 'hdfs dfsadmin -saveNamespace'


执行成功之后 Next 会自动变得可点击

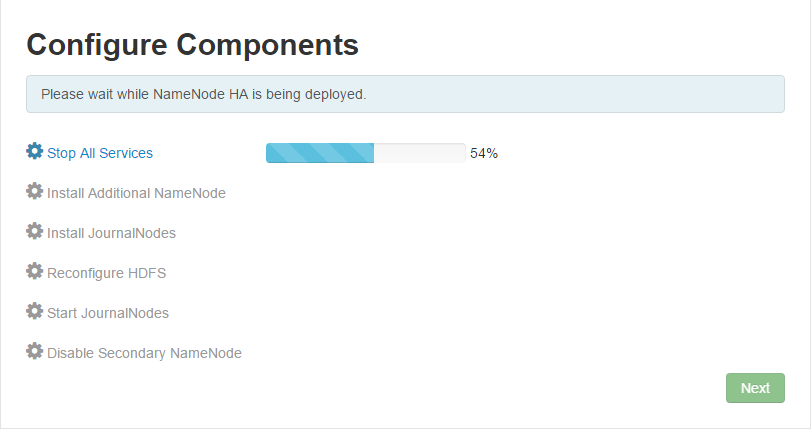
7.Configure Components 开始重新配置各个组件服务
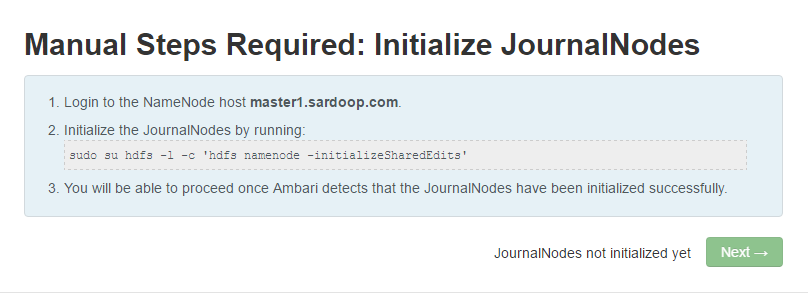
8.Manual Steps Required 又是一个需要手动的环节
9.Start Components 启动各组件

10.Manual Steps Required: Initialize NameNode HA Metadata 手动初始化NameNode HA的元数据

在主NameNode上执行
sudo su hdfs -l -c 'hdfs zkfc -formatZK'
在备用NameNode上执行
sudo su hdfs -l -c 'hdfs namenode -bootstrapStandby'
11. Finalize HA Setup 启动最终配置

安装SmartSence
启动后发现会有一个SmartSence服务,并且一直是启动不成功。查看错误显示 【Please configure a vaid SmartSense ID to proceed.】
SmartSence是 HORTONWORKS 公司的一款增值服务产品,为hadoop集群提供指导帮助,SmartSence是无法像Ambari其他服务一样安装的。
而这个SmartSenseID需要安装之后才会由官方提供。
具体安装参考 https://docs.hortonworks.com/HDPDocuments/SS1/SmartSense-1.1.0/bk_smartsense_admin/content/ch01s02s05s01.html
Ambari的升级
具体还没有做过线上Ambari的升级,有机会升级的话补上这一节
相关错误:
1.ambari启动后,hbase服务正常,但是之后时不时的挂掉一两个节点,去挂掉的节点上查看日志
内容如下
2016-12-12 10:47:03,487 WARN [regionserver/slave1.sardoop.com/192.168.0.37:16020] wal.ProtobufLogWriter: Failed to write trailer, non-fatal, continuing...
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /apps/hbase/data/oldWALs/Node1%2C16020%2C1481510498265.default.1481510529594 (inode 25442): File is not open for writing. Holder DFSClient_NONMAPREDUCE_1762492244_1 does not have any open files.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkLease(FSNamesystem.java:3536)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalDatanode(FSNamesystem.java:3436)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getAdditionalDatanode(NameNodeRpcServer.java:877)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getAdditionalDatanode(ClientNamenodeProtocolServerSideTranslatorPB.java:523)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2313)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2309)
解决方法:
到Ambari的HBase服务下修改配置hbase-env.sh两处
修改前:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -Xmn{{regionserver_xmn_size}} -XX:CMSInitiatingOccupancyFraction=70 -Xms{{regionserver_heapsize}} -Xmx{{regionserver_heapsize}} $JDK_DEPENDED_OPTS"
修改后:
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:MaxTenuringThreshold=3 -XX:SurvivorRatio=8 -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:InitiatingHeapOccupancyPercent=75 -XX:NewRatio=39 -Xms{{regionserver_heapsize}} -Xmx{{regionserver_heapsize}} $JDK_DEPENDED_OPTS"
修改前:
export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC -XX:ErrorFile={{log_dir}}/hs_err_pid%p.log -Djava.io.tmpdir={{java_io_tmpdir}}"
修改后:
export HBASE_OPTS="$HBASE_OPTS -XX:ErrorFile={{log_dir}}/hs_err_pid%p.log -Djava.io.tmpdir={{java_io_tmpdir}}"
2.HDFS的权限问题
在Ambari上安装好集群之后 自然要使用,无论是在页面上往查看目录,还是在命令行操作文件或目录,经常会出现如下问题:
【Permission denied: user=dr.who, access=READ_EXECUTE, inode="/tmp/hive":ambari-qa:hdfs:drwx-wx-wx】
黑体部分依次是 HDFS目录、目录拥有者、目录拥有者所在组。
解决方式有两种:
①修改目录权限
sudo -u hdfs hadoop dfs -chmod [-R] 755 /user/hdfs #红字部分是指该命令的执行用户,这里使用目录所有者
这种方式破坏了原有的权限设计,个人不建议
②使用对应的用户去执行命令,如
sudo -u hdfs hadoop dfs -ls /user/hive #即 根据目录的权限,选择使用对应的用户
要注意的是,如果要上传文件,最好先用 su someuser 登录,然后再执行(这样路径才不会出错,否则会找不到路径)
其实还有另外一种添加超级权限用户组的方式,感兴趣可参考 HDFS Permissions: Overcoming The "Permission Denied" AccessControlException
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号