
HDFS读流程
1.1. HDFS读数据流程
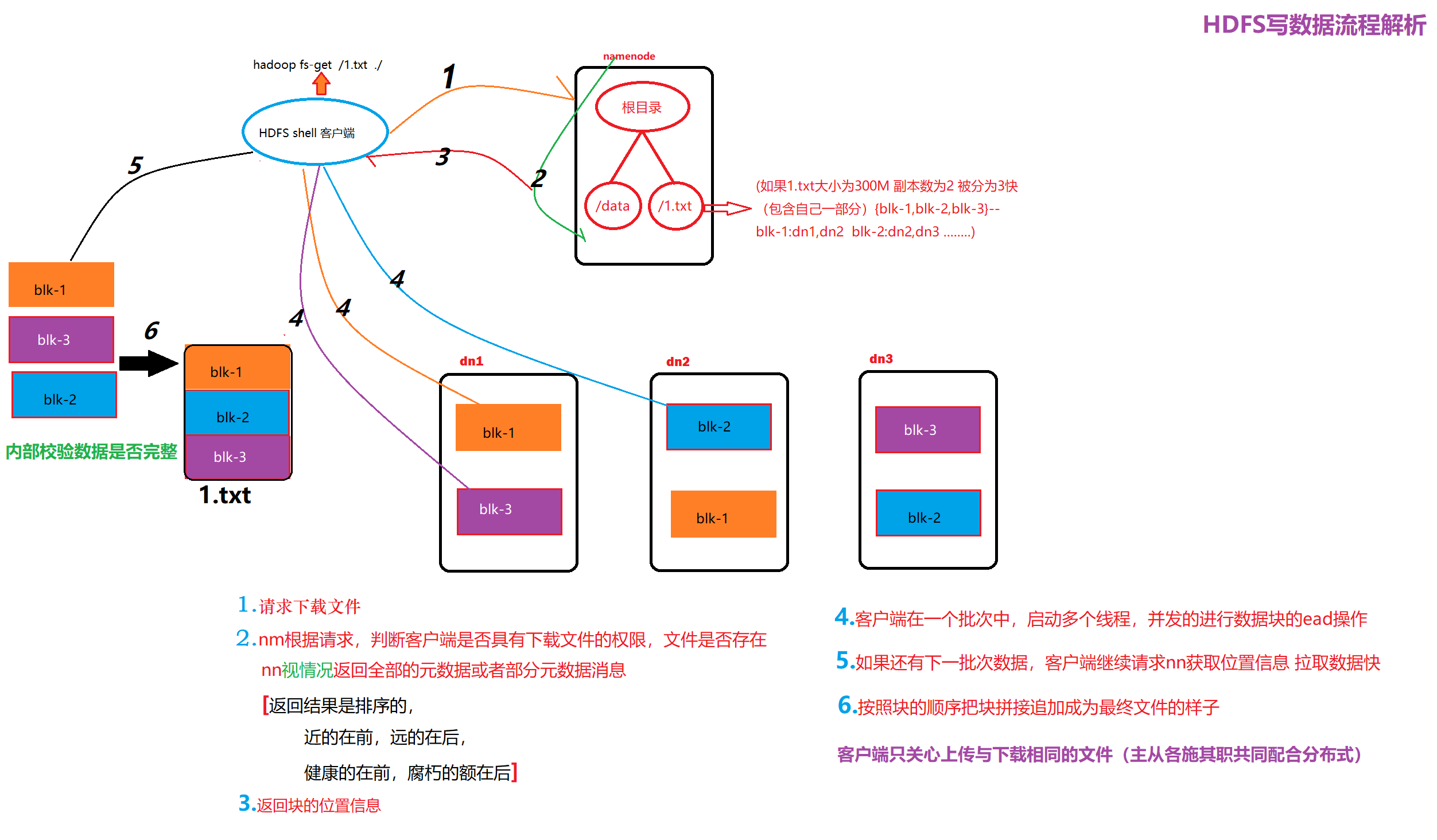
详细步骤解析:
1、 Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址;
3、 这些返回的DN地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离Client近的排靠前;心跳机制中超时汇报的DN状态为STALE,这样的排靠后;
4、 Client选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
5、 底层上本质是建立Socket Stream(FSDataInputStream),重复的调用父类DataInputStream的read方法,直到这个块上的数据读取完毕;
6、 当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;
7、 读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读。
8、 read方法是并行的读取block信息,不是一块一块的读取;NameNode只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
9、 最终读取来所有的block会合并成一个完整的最终文件。
详细步骤图:
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。
