
MapReduce数据分区
一个:
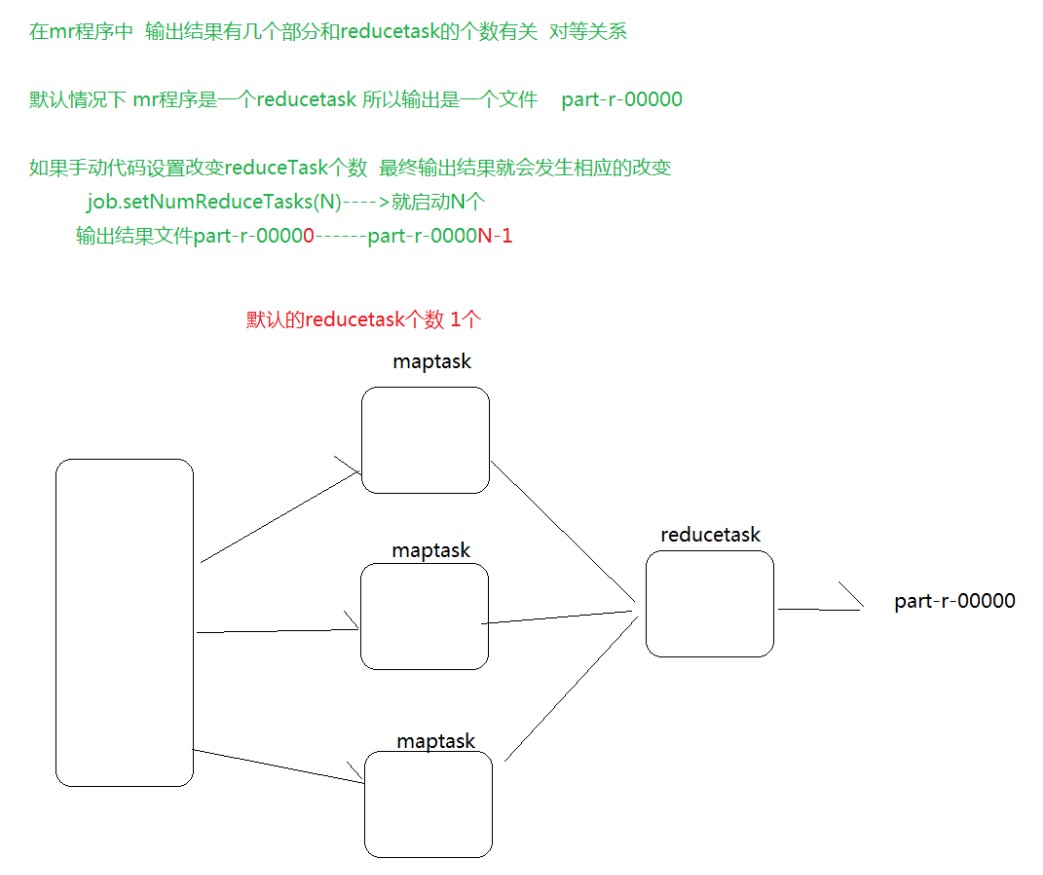
多个
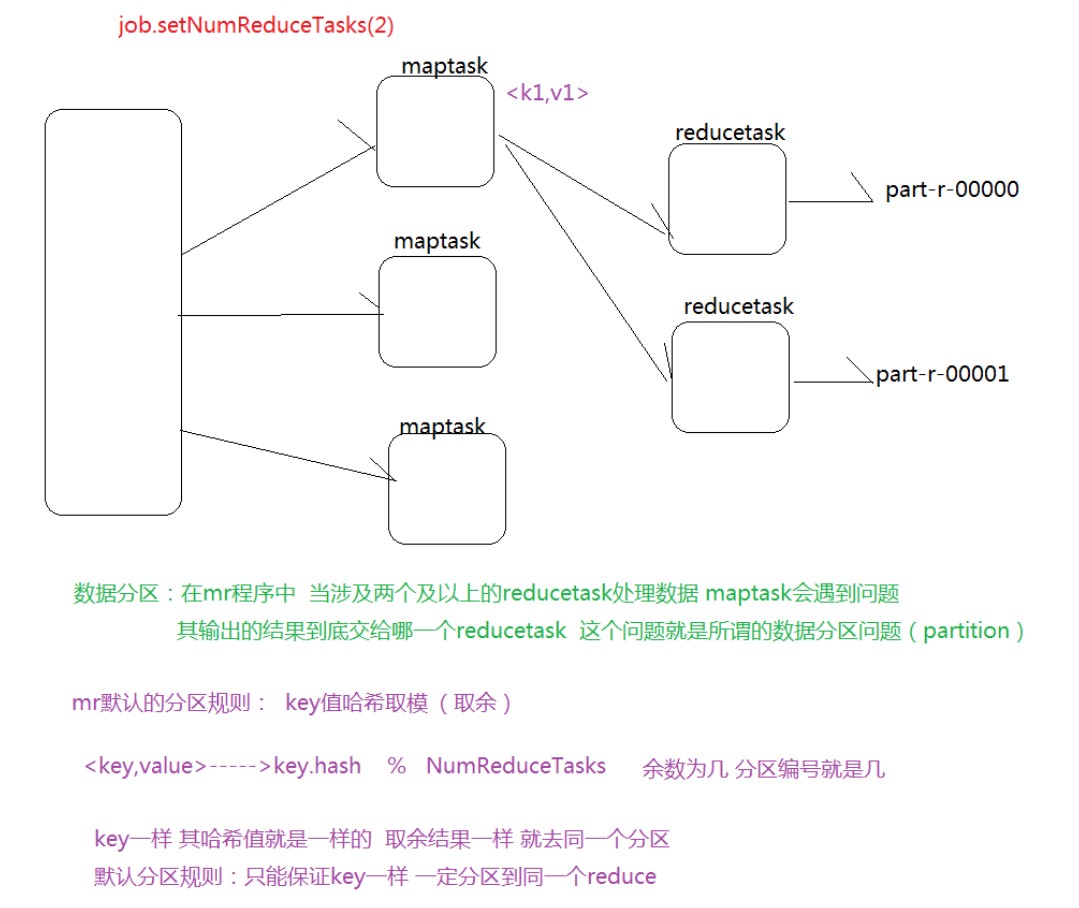
代码实现:
Mapper:
.mapreduce.Mapper.Context;
public class EmployeeMapper extends Mapper<LongWritable, Text, LongWritable, Employee> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
String str = value.toString();
//分词
String[] words = str.split(",");
Employee e = new Employee();
e.setEmpno(Integer.parseInt(words[0]));
e.setEname(words[1]);
e.setJob(words[2]);
try {
e.setMgr(Integer.parseInt(words[3]));
} catch (Exception e2) {
e.setMgr(0);
}
e.setHiredate(words[4]);
e.setSal(Integer.parseInt(words[5]));
try {
e.setComm(Integer.parseInt(words[6]));
} catch (Exception e2) {
e.setComm(0);
}
e.setDeptno(Integer.parseInt(words[7]));
//将这个员工输出
context.write(new LongWritable(e.getDeptno()),e);
}
}34
1
.mapreduce.Mapper.Context;
2
3
public class EmployeeMapper extends Mapper<LongWritable, Text, LongWritable, Employee> {
4
5
@Override
6
protected void map(LongWritable key, Text value,Context context)
7
throws IOException, InterruptedException {
8
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
9
String str value.toString();
10
//分词
11
String[] words str.split(",");
12
13
Employee e new Employee();
14
e.setEmpno(Integer.parseInt(words[0]));
15
e.setEname(words[1]);
16
e.setJob(words[2]);
17
try {
18
e.setMgr(Integer.parseInt(words[3]));
19
} catch (Exception e2) {
20
e.setMgr(0);
21
}
22
e.setHiredate(words[4]);
23
e.setSal(Integer.parseInt(words[5]));
24
try {
25
e.setComm(Integer.parseInt(words[6]));
26
} catch (Exception e2) {
27
e.setComm(0);
28
}
29
e.setDeptno(Integer.parseInt(words[7]));
30
31
//将这个员工输出
32
context.write(new LongWritable(e.getDeptno()),e);
33
}
34
}
Reducer:
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class EmployeeReducer extends Reducer<LongWritable, Employee, LongWritable, Employee> {
@Override
protected void reduce(LongWritable deptno, Iterable<Employee> values,Context context)
throws IOException, InterruptedException {
for(Employee e:values){
context.write(deptno, e);
}
}
}16
1
import java.io.IOException;
2
3
import org.apache.hadoop.io.LongWritable;
4
import org.apache.hadoop.mapreduce.Reducer;
5
6
public class EmployeeReducer extends Reducer<LongWritable, Employee, LongWritable, Employee> {
7
8
@Override
9
protected void reduce(LongWritable deptno, Iterable<Employee> values,Context context)
10
throws IOException, InterruptedException {
11
for(Employee e:values){
12
context.write(deptno, e);
13
}
14
}
15
16
}
Employee:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
public class Employee implements Writable{
private int empno;
private String ename;
private String job;
private int mgr;
private String hiredate;
private int sal;
private int comm;
private int deptno;
public Employee(){
}
@Override
public String toString() {
return "Employee [empno=" + empno + ", ename=" + ename + ", job=" + job
+ ", mgr=" + mgr + ", hiredate=" + hiredate + ", sal=" + sal
+ ", comm=" + comm + ", deptno=" + deptno + "]";
}
@Override
public void readFields(DataInput in) throws IOException {
this.empno = in.readInt();
this.ename = in.readUTF();
this.job = in.readUTF();
this.mgr = in.readInt();
this.hiredate = in.readUTF();
this.sal = in.readInt();
this.comm = in.readInt();
this.deptno = in.readInt();
}
@Override
public void write(DataOutput output) throws IOException {
////7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
output.writeInt(empno);
output.writeUTF(ename);
output.writeUTF(job);
output.writeInt(mgr);
output.writeUTF(hiredate);
output.writeInt(sal);
output.writeInt(comm);
output.writeInt(deptno);
}
public int getEmpno() {
return empno;
}
public void setEmpno(int empno) {
this.empno = empno;
}
public String getEname() {
return ename;
}
public void setEname(String ename) {
this.ename = ename;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public int getMgr() {
return mgr;
}
public void setMgr(int mgr) {
this.mgr = mgr;
}
public String getHiredate() {
return hiredate;
}
public void setHiredate(String hiredate) {
this.hiredate = hiredate;
}
public int getSal() {
return sal;
}
public void setSal(int sal) {
this.sal = sal;
}
public int getComm() {
return comm;
}
public void setComm(int comm) {
this.comm = comm;
}
public int getDeptno() {
return deptno;
}
public void setDeptno(int deptno) {
this.deptno = deptno;
}
}119
1
import java.io.DataInput;
2
import java.io.DataOutput;
3
import java.io.IOException;
4
5
import org.apache.hadoop.io.Writable;
6
import org.apache.hadoop.io.WritableComparable;
7
8
//7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
9
public class Employee implements Writable{
10
11
private int empno;
12
private String ename;
13
private String job;
14
private int mgr;
15
private String hiredate;
16
private int sal;
17
private int comm;
18
private int deptno;
19
20
public Employee(){
21
22
}
23
24
@Override
25
public String toString() {
26
return "Employee [empno=" empno ", ename=" ename ", job=" job
27
", mgr=" mgr ", hiredate=" hiredate ", sal=" sal
28
", comm=" comm ", deptno=" deptno "]";
29
}
30
31
@Override
32
public void readFields(DataInput in) throws IOException {
33
this.empno in.readInt();
34
this.ename in.readUTF();
35
this.job in.readUTF();
36
this.mgr in.readInt();
37
this.hiredate in.readUTF();
38
this.sal in.readInt();
39
this.comm in.readInt();
40
this.deptno in.readInt();
41
}
42
43
@Override
44
public void write(DataOutput output) throws IOException {
45
////7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
46
output.writeInt(empno);
47
output.writeUTF(ename);
48
output.writeUTF(job);
49
output.writeInt(mgr);
50
output.writeUTF(hiredate);
51
output.writeInt(sal);
52
output.writeInt(comm);
53
output.writeInt(deptno);
54
}
55
56
public int getEmpno() {
57
return empno;
58
}
59
60
public void setEmpno(int empno) {
61
this.empno empno;
62
}
63
64
public String getEname() {
65
return ename;
66
}
67
68
public void setEname(String ename) {
69
this.ename ename;
70
}
71
72
public String getJob() {
73
return job;
74
}
75
76
public void setJob(String job) {
77
this.job job;
78
}
79
80
public int getMgr() {
81
return mgr;
82
}
83
84
public void setMgr(int mgr) {
85
this.mgr mgr;
86
}
87
88
public String getHiredate() {
89
return hiredate;
90
}
91
92
public void setHiredate(String hiredate) {
93
this.hiredate hiredate;
94
}
95
96
public int getSal() {
97
return sal;
98
}
99
100
public void setSal(int sal) {
101
this.sal sal;
102
}
103
104
public int getComm() {
105
return comm;
106
}
107
108
public void setComm(int comm) {
109
this.comm comm;
110
}
111
112
public int getDeptno() {
113
return deptno;
114
}
115
116
public void setDeptno(int deptno) {
117
this.deptno deptno;
118
}
119
}
Partitioner:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class EmployeePartition extends Partitioner<LongWritable, Employee> {
@Override
public int getPartition(LongWritable key2, Employee e, int numPartition) {
// 分区的规则
if(e.getDeptno() == 10){
return 1%numPartition;
}else if(e.getDeptno() == 20){
return 2%numPartition;
}else{
return 3%numPartition;
}
}
}17
1
import org.apache.hadoop.io.LongWritable;
2
import org.apache.hadoop.mapreduce.Partitioner;
3
4
public class EmployeePartition extends Partitioner<LongWritable, Employee> {
5
6
@Override
7
public int getPartition(LongWritable key2, Employee e, int numPartition) {
8
// 分区的规则
9
if(e.getDeptno() 10){
10
return 1numPartition;
11
}else if(e.getDeptno() 20){
12
return 2numPartition;
13
}else{
14
return 3numPartition;
15
}
16
}
17
}
Driver:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PartitionMain {
public static void main(String[] args) throws Exception {
// 求员工工资的总额
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指明程序的入口
job.setJarByClass(PartitionMain.class);
//指明任务中的mapper
job.setMapperClass(EmployeeMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Employee.class);
//设置分区的规则
job.setPartitionerClass(EmployeePartition.class);
job.setNumReduceTasks(3);
job.setReducerClass(EmployeeReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Employee.class);
//指明任务的输入路径和输出路径 ---> HDFS的路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//启动任务
job.waitForCompletion(true);
}
}38
1
import org.apache.hadoop.conf.Configuration;
2
import org.apache.hadoop.fs.Path;
3
import org.apache.hadoop.io.LongWritable;
4
import org.apache.hadoop.io.NullWritable;
5
import org.apache.hadoop.mapreduce.Job;
6
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
7
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
8
public class PartitionMain {
9
10
public static void main(String[] args) throws Exception {
11
// 求员工工资的总额
12
Configuration conf new Configuration();
13
Job job Job.getInstance(conf);
14
15
//指明程序的入口
16
job.setJarByClass(PartitionMain.class);
17
18
//指明任务中的mapper
19
job.setMapperClass(EmployeeMapper.class);
20
job.setMapOutputKeyClass(LongWritable.class);
21
job.setMapOutputValueClass(Employee.class);
22
23
//设置分区的规则
24
job.setPartitionerClass(EmployeePartition.class);
25
job.setNumReduceTasks(3);
26
27
job.setReducerClass(EmployeeReducer.class);
28
job.setOutputKeyClass(LongWritable.class);
29
job.setOutputValueClass(Employee.class);
30
31
//指明任务的输入路径和输出路径---> HDFS的路径
32
FileInputFormat.addInputPath(job, new Path(args[0]));
33
FileOutputFormat.setOutputPath(job, new Path(args[1]));
34
35
//启动任务
36
job.waitForCompletion(true);
37
}
38
}
总结:
思路:自定义一个类,继承Partitioner<K,V>重写getPartition
根据需求,把相同的 数据返回同一标号的分区,使其相同的数据在同一分区
分区个数应该和reducetask的个数保持一致!
自定义分区类的生效?
job进行设置!
//这里指定使用我们自定义的分区组件
job.setPartitionerClass(ProvincePartitioner.class);2
1
//这里指定使用我们自定义的分区组件
2
job.setPartitionerClass(ProvincePartitioner.class);
分区分组的区别?
分区:发生在map阶段,决定了数据到哪一个reduce
分组:发生在reduce阶段,决定了一个reduce中的key相同的数据去调用reducec方法
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。

