
HDFS写流程
1.1. HDFS写数据流程
详细步骤解析:
1、client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、client请求第一个 block该传输到哪些DataNode服务器上;
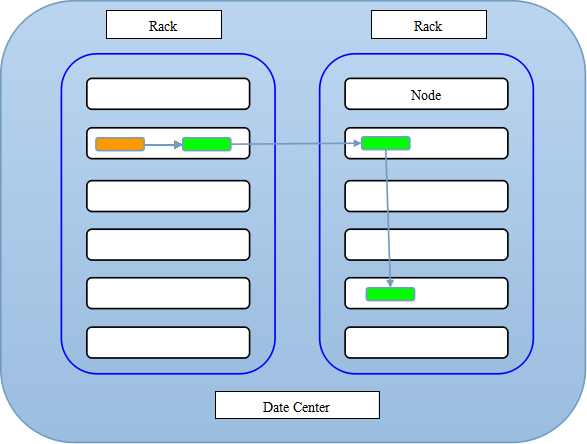
3、NameNode根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的DataNode的地址,如:A,B,C;
注:默认存储策略由BlockPlacementPolicyDefault类支持。也就是日常生活中提到最经典的3副本策略。
1st replica如果写请求方所在机器是其中一个datanode,则直接存放在本地,否则随机在集群中选择一个datanode.
2nd replica第二个副本存放于不同第一个副本的所在的机架.
3rd replica第三个副本存放于第二个副本所在的机架,但是属于不同的节点
4、client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline(管道)),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,后逐级返回client;
5、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet(数据包)为单位(默认64K),A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答。
6、数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点A将pipeline ack发送给client;
7、当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。

<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
