
MapReduce的Combiner组件
每一个map都可能会产生大量的本地输出,Combiner的作用就是对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量,以提高网络IO性能,是MapReduce的一种优化手段之一。
- combiner是MR程序中Mapper和Reducer之外的一种组件
- combiner组件的父类就是Reducer
- combiner和reducer的区别在于运行的位置:
- Combiner是在每一个maptask所在的节点运行
- Reducer是接收全局所有Mapper的输出结果;
- combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
- 具体实现步骤:
- 自定义一个combiner继承Reducer,重写reduce方法
- 在job中设置: job.setCombinerClass(CustomCombiner.class)
- combiner能够应用的前提是不能影响最终的业务逻辑,而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来

总结:
combiner:
- 局部聚合组件,针对每个maptask进行局部聚合运算从而进行优化
- 局部聚合之后,减少了map与reduce之间跨网络传递的数据量,减少网络IO
- 如果涉及业务,不可以使用combiner,因为局部合并会对最终结果发送改变
- combiner本身就是reduce只不过应用的范围只限于maptask输出,不是全局
- 开启combiner需要在job中进行设置
- job.setCombinerClass(WordCountReducer.class)
- combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。
- 如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
- 注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
代码举例
准备(数据):
hello tom
hello kittty
hello jerry
hello cat
hello tom5
1
hello tom
2
hello kittty
3
hello jerry
4
hello cat
5
hello tom
WordCountMapper类
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text,LongWritable >{
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text,LongWritable >.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String hang = value.toString();
String[] strings = hang.split(" ");
for(String string : strings) {
context.write(new Text(string),new LongWritable(1));
}
}
}17
1
import java.io.IOException;
2
import org.apache.hadoop.io.LongWritable;
3
import org.apache.hadoop.io.Text;
4
import org.apache.hadoop.mapreduce.Mapper;
5
6
public class WordCountMapper extends Mapper<LongWritable, Text, Text,LongWritable >{
7
protected void map(LongWritable key, Text value,
8
Mapper<LongWritable, Text, Text,LongWritable >.Context context)
9
throws IOException, InterruptedException {
10
// TODO Auto-generated method stub
11
String hang = value.toString();
12
String[] strings = hang.split(" ");
13
for(String string : strings) {
14
context.write(new Text(string),new LongWritable(1));
15
}
16
}
17
}
WordCountReducer类
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key2, Iterable<LongWritable> value2,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum=0;
for(LongWritable i :value2){
sum += i.get();
}
context.write(key2,new LongWritable(sum));
}
}19
1
import java.io.IOException;
2
import org.apache.hadoop.io.LongWritable;
3
import org.apache.hadoop.io.Text;
4
import org.apache.hadoop.mapreduce.Reducer;
5
6
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
7
8
9
protected void reduce(Text key2, Iterable<LongWritable> value2,
10
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
11
long sum=0;
12
13
for(LongWritable i :value2){
14
sum += i.get();
15
}
16
17
context.write(key2,new LongWritable(sum));
18
}
19
}
MRClient类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MRClient {
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
//设置当前作业主函数所在类
job.setJarByClass(MRClient.class);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, "c:/data.txt");
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileOutputFormat.setOutputPath(job,new Path("c:/out"));
job.setCombinerClass(WordCountReducer.class);
//提交作业,参数:true为显示计算过程,false不显示计算过程
job.waitForCompletion(true);
}
}34
1
import org.apache.hadoop.conf.Configuration;
2
import org.apache.hadoop.fs.Path;
3
import org.apache.hadoop.io.LongWritable;
4
import org.apache.hadoop.io.Text;
5
import org.apache.hadoop.mapreduce.Job;
6
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
7
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
8
9
public class MRClient {
10
11
public static void main(String[] args) throws Exception {
12
// TODO Auto-generated method stub
13
Configuration configuration=new Configuration();
14
Job job=Job.getInstance(configuration);
15
//设置当前作业主函数所在类
16
job.setJarByClass(MRClient.class);
17
18
job.setMapperClass(WordCountMapper.class);
19
job.setMapOutputKeyClass(Text.class);
20
job.setMapOutputValueClass(LongWritable.class);
21
FileInputFormat.setInputPaths(job, "c:/data.txt");
22
23
job.setReducerClass(WordCountReducer.class);
24
job.setOutputKeyClass(Text.class);
25
job.setOutputValueClass(LongWritable.class);
26
FileOutputFormat.setOutputPath(job,new Path("c:/out"));
27
28
job.setCombinerClass(WordCountReducer.class);
29
30
//提交作业,参数:true为显示计算过程,false不显示计算过程
31
job.waitForCompletion(true);
32
33
}
34
}
想要使用 combiner功能只要在组装作业时,添加下面一行代码即可:
// 设置 Combiner
job.setCombinerClass(WordCountReducer.class);1
// 设置 Combiner
2
job.setCombinerClass(WordCountReducer.class);
加入 combiner后统计结果是不会有变化的,但是可以从打印的日志看出 combiner的效果:
没有加入 combiner的打印日志:
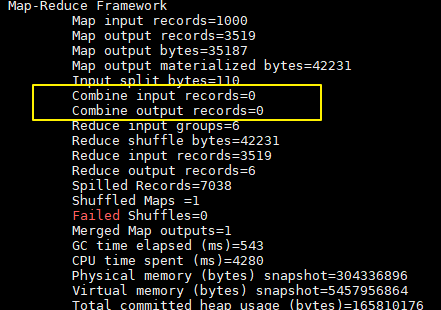
加入 combiner后的打印日志如下:
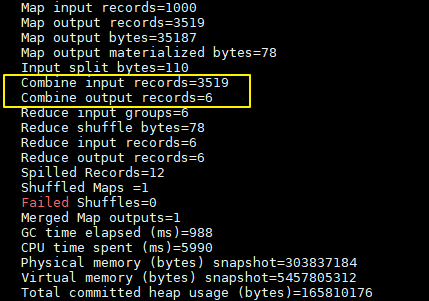
这里我们只有一个输入文件并且小于 128M,所以只有一个 Map 进行处理。可以看到经过 combiner 后,records 由 3519 降低为 6(样本中单词种类就只有 6 种),在这个用例中 combiner 就能极大地降低需要传输的数据量。
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。
