
SparkStreaming的数据抽象 DStream
- 数据抽象
Spark Streaming的基础抽是DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种Spark算子操作后的结果数据流
1.DStream本质上就是一系列时间上连续的RDD
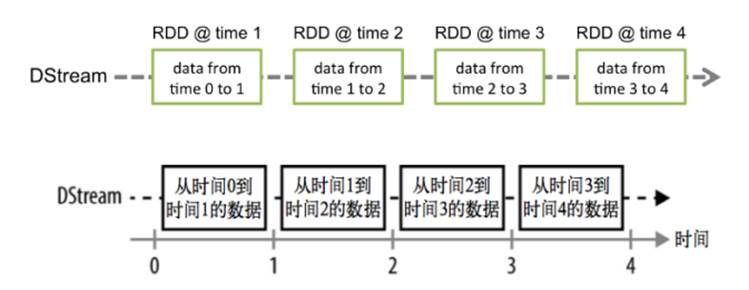
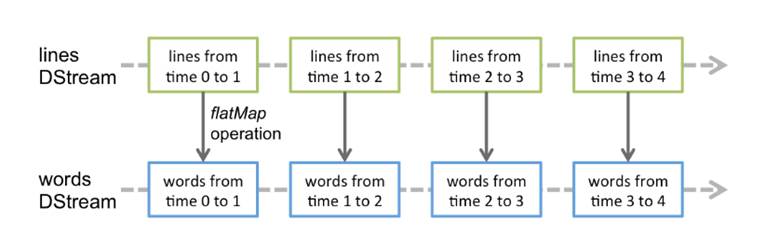
2.对DStream的数据的进行RDD操作
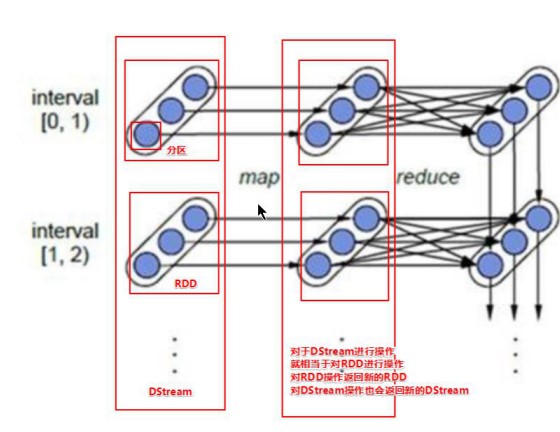
3.容错性
底层RDD之间存在依赖关系,DStream直接也有依赖关系,RDD具有容错性,那么DStream也具有容错性
如图:
- 每一个椭圆形表示一个RDD
- 椭圆形中的每个圆形代表一个RDD中的一个Partition分区
- 每一列的多个RDD表示一个DStream(图中有三列所以有三个DStream)
- 每一行最后一个RDD则表示每一个Batch Size所产生的中间结果RDD
4.准实时性(近实时)
- Spark Streaming将流式计算分解成多个Spark Job,对于每一时间段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
- 对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~5秒钟之间
- 所以Spark Streaming能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合
●总结
- 简单来说DStream就是对RDD的封装,你对DStream进行操作,就是对RDD进行操作
- 对于DataFrame/DataSet/DStream来说本质上都可以理解成RDD
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。

