
Yarn HA高可用
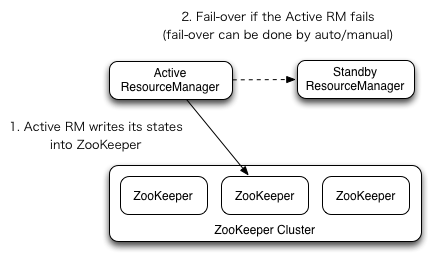
Yarn作为资源管理系统,是上层计算框架(如MapReduce,Spark)的基础。在Hadoop 2.4.0版本之前,Yarn存在单点故障(即ResourceManager存在单点故障),一旦发生故障,恢复时间较长,且会导致正在运行的Application丢失,影响范围较大。从Hadoop 2.4.0版本开始,Yarn实现了ResourceManager HA,在发生故障时自动failover,大大提高了服务的可靠性。
ResourceManager(简写为RM)作为Yarn系统中的主控节点,负责整个系统的资源管理和调度,内部维护了各个应用程序的ApplictionMaster信息、NodeManager(简写为NM)信息、资源使用等。由于资源使用情况和NodeManager信息都可以通过NodeManager的心跳机制重新构建出来,因此只需要对ApplicationMaster相关的信息进行持久化存储即可。
在一个典型的HA集群中,两台独立的机器被配置成ResourceManger。在任意时间,有且只允许一个活动的ResourceManger,另外一个备用。切换分为两种方式:
手动切换:在自动恢复不可用时,管理员可用手动切换状态,或是从Active到Standby,或是从Standby到Active。
自动切换:基于Zookeeper,但是区别于HDFS的HA,2个节点间无需配置额外的ZFKC守护进程来同步数据。
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。
