
HDFS总结
是什么?
分布式文件存储系统(是一个跨多台机器的文件存储系统)
HDFS设计,特性:
- 分布式:标准的主从架构(NameNode DataNode)
- 一次写入多次读取:数据侧重于分析
- 注重数据吞吐量,交互延迟高,不适合做网盘
- 侧重于大文件存储,不利于小文件,小文件吃内存
基本原理:
对外如同一个黑盒子,用户用户不用关心内部的细节,只关心文件存储提取是否便利
对内是一个标准的主从架构,各司其职,共同配合,对外提供服务
文件上传下载流程:
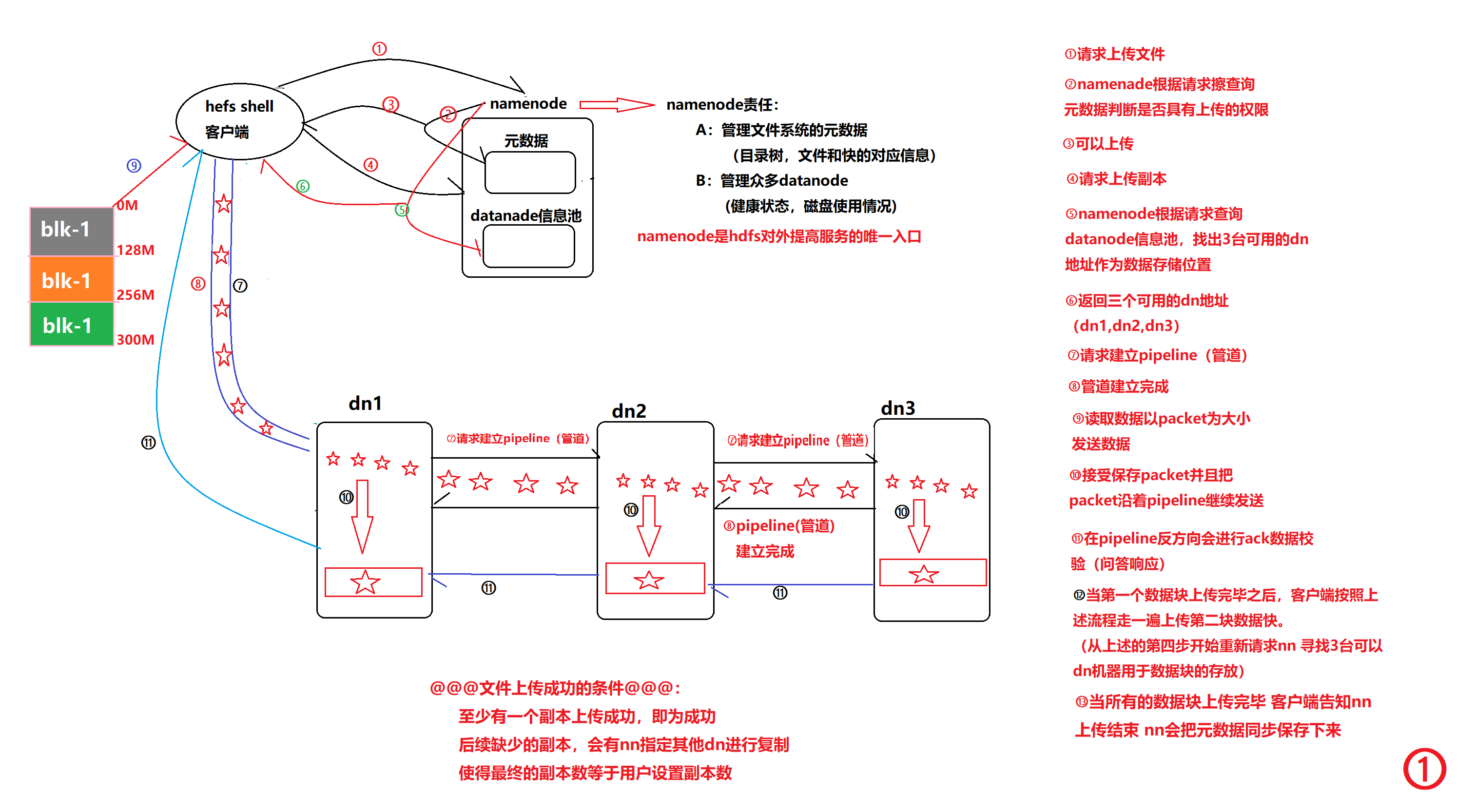

nn职责:
管理命名空间namespace(目录树结构) 文件和可以对应信息
管理众多的Datanode
成为访问HDFS的唯一访问路径
元数据保存在内容 工作机器需要大量RAM随机存取存储器(random access memory的缩写
nm职责:
负责具体的数据存储
配合nn完成文件存储服务
但是向nn发送心跳 3秒 汇报块信息 6小时
HDFS操作:
shell命令: put:上传操作,从本地到目标
get:下载操作,将文件下载到本地文件系统
mkdir:创建空白文件
appendToFile:把多个文件追加到已经存在文件的末尾
getMerge rm -r:下载合并,合并下载多个文件
Java api
类:FileSystem.get() 文件系统实例 Configuration 配置对象类
客户端身份:客户端设置身份符合hdfs权限
本地环境:winutils.exe hadoop在windows配置环境变量
其他辅助功能:
Hadoop Archive 档案:将小批文件合并成一个大文件的档案
hdfs snapshot:先允许设置(disamain)快照 然后才可以创建快照
可以指定某个文件夹设置备份。
1、hdfs的组成部分有哪些,分别解释一下:namenode(管理文件系统元数据) datanode(负责具体数据块存储 服务于namenode)
2、hdfs的高可靠如何实现:分块存储,副本机制
3、hdfs的常用shell命令有哪些 -put -get appendToFile getmerge
4、hdfs的常用java api有哪些 :略
5、请用shell命令实现目录、文件的增删改查
增:hadoop fs -get <路径>
删:hadoop fs -rm [-skipTrash] <路径>
改:hadoop fs -put <路径>
查:hadoop fs -cat <路径>
6、请用java api实现目录、文件的增删改查:去看api总结
6、请用java api实现目录、文件的增删改查:去看api总结
元素管理机制:
谁来管理:
namenode
元数据分类:
按类型:
目录树结构,文件和块的对应信息 ,datanode状态信息
按存储介质:
内存元数据(最完整),磁盘:fsimage镜像文件 edits编辑日志
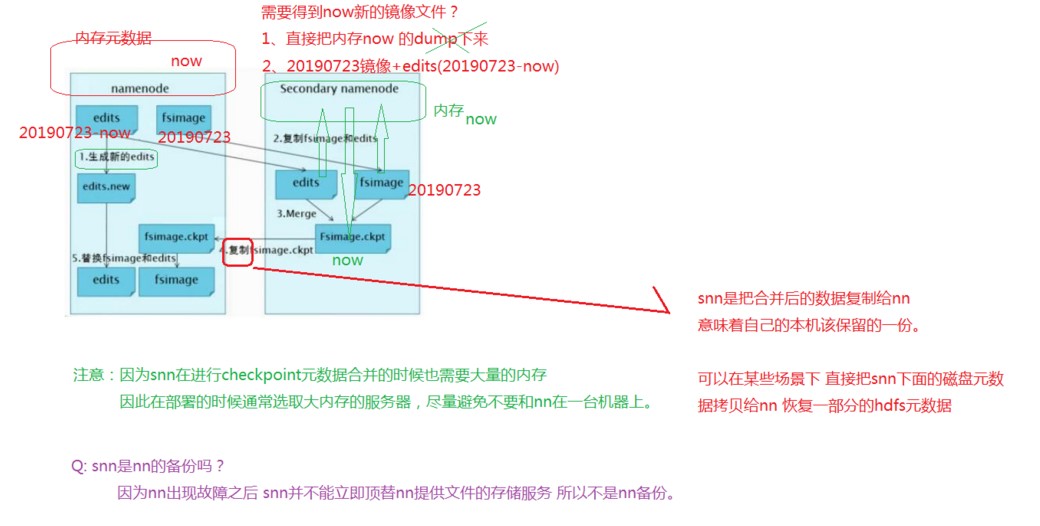
Secondarynamenode:
定位:
主角是的辅助角色。
职责:
定期帮助nameNode合并镜像文件和编辑日志
机制:
checkpoint 检查点:(如图)
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。

