
Structured Streaming曲折发展史
Structured Streaming曲折发展史
1.1. Spark Streaming
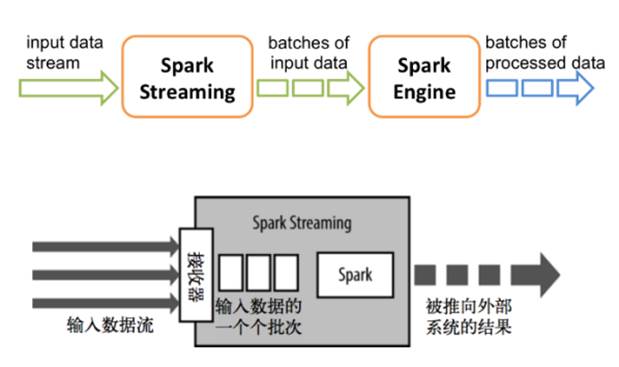
在2.0之前,Spark Streaming作为核心API的扩展,针对实时数据流,提供了一套可扩展、高吞吐、可容错的流式计算模型。Spark Streaming会接收实时数据源的数据,并切分成很多小的batches,然后被Spark Engine执行,产出同样由很多小的batchs组成的结果流。本质上,这是一种micro-batch(微批处理)的方式处理,这种设计让Spark Streaming面对复杂的流式处理场景时捉襟见肘。
其实在流计算发展的初期,市面上主流的计算引擎本质上都只能处理特定的场景,
spark streaming这种构建在微批处理上的流计算引擎,比较突出的问题就是处理延时较高(无法优化到秒以下的数量级),以及无法支持基于event_time的时间窗口做聚合逻辑。
在这段时间,流式计算一直没有一套标准化、能应对各种场景的模型,直到2015年google发表了The Dataflow Model的论文。
https://yq.aliyun.com/articles/73255
1.2. Dataflow模型
在日常商业运营中,无边界、乱序、大规模数据集越来越普遍(例如,网站日志,手机应用统计,传感器网络)。同时,对这些数据的消费需求也越来越复杂,比如说按事件发生时间序列处理数据,按数据本身的特征进行窗口计算等等。同时人们也越来越苛求立刻得到数据分析结果。
作为数据工作者,不能把无边界数据集(数据流)切分成有边界的数据,等待一个批次完整后处理。
相反地,应该假设永远无法知道数据流是否终结,何时数据会变完整。唯一确信的是,新的数据会源源不断而来,老的数据可能会被撤销或更新。
由此,google工程师们提出了Dataflow模型,从根本上对从前的数据处理方法进行改进。
1.2.1. 核心思想
对无边界,无序的数据源,允许按数据本身的特征进行窗口计算,得到基于事件发生时间的有序结果,并能在准确性、延迟程度和处理成本之间调整。
1.2.2. 四个维度
抽象出四个相关的维度,通过灵活地组合来构建数据处理管道,以应对数据处理过程中的各种复杂的场景
what 需要计算什么
where 需要基于什么时间(事件发生时间)窗口做计算
when 在什么时间(系统处理时间)真正地触发计算
how 如何修正之前的计算结果
论文的大部分内容都是在说明如何通过这四个维度来应对各种数据处理场景。
1.2.3. 相关概念
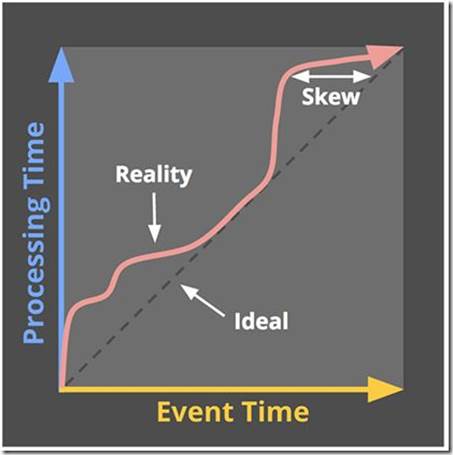
在现实场景中,从一个事件产生,到它被数据分析系统收集到,要经过非常复杂的链路,这本身就会存在一定的延时,还会因为一些特殊的情况加剧这种情况。比如基于移动端APP的用户行为数据,会因为手机信号较差、没有wifi等情况导致无法及时发送到服务端系统。面对这种时间上的偏移,数据处理模型如果只考虑处理时间,势必会降低最终结果的正确性。
●事件时间和处理时间
event_time,事件的实际发生时间
process_time,处理时间,是指一个事件被数据处理系统观察/接收到的时间
现在假设,你正在去往地下停车场的路上,并且打算用手机点一份外卖。选好了外卖后,你就用在线支付功能付款了,这个时候是12点05分。恰好这时,你走进了地下停车库,而这里并没有手机信号。因此外卖的在线支付并没有立刻成功,而支付系统一直在Retry重试“支付”这个操作。
当你找到自己的车并且开出地下停车场的时候,已经是12点15分了。这个时候手机重新有了信号,手机上的支付数据成功发到了外卖在线支付系统,支付完成。
在上面这个场景中你可以看到,支付数据的事件时间是12点05分,而支付数据的处理时间是12点15分
●窗口
除了一些无状态的计算逻辑(如过滤,映射等),经常需要把无边界的数据集切分成有限的数据片以便于后续聚合处理(比如统计最近5分钟的XX等),窗口就应用于这类逻辑中,常见的窗口包括:
sliding window,滑动窗口,除了窗口大小,还需要一个滑动周期,比如小时窗口,每5分钟滑动一次。
fixed window,固定窗口,按固定的窗口大小定义,比如每小时、天的统计逻辑。
固定窗口可以看做是滑动窗口的特例,即窗口大小和滑动周期相等。
sessions,会话窗口,以某一事件作为窗口起始,通常以时间定义窗口大小(也有可能是事件次数),发生在超时时间以内的事件都属于同一会话,比如统计用户启动APP之后一段时间的浏览信息等。
论文中远不止这些内容,还有很多编程模型的说明和举例,感兴趣的同学可以自行阅读。https://yq.aliyun.com/articles/73255
除了论文,google还开源了Apache Beam项目,基本上就是对Dataflow模型的实现,目前已经成为Apache的顶级项目,但是在国内使用不多。国内使用的更多的是后面要学习的Flink,因为阿里大力推广Flink,甚至把花7亿元把Flink收购了
我们今天学习的Structured Streaming也是为了后面学习Flink做铺垫
1.3. Structured Streaming
1.3.1. 介绍
●官网
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
●简介
也许是对Dataflow模型的借鉴,也许是英雄所见略同,spark在2.0版本中发布了新的流计算的API,Structured Streaming/结构化流。
Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎。统一了流、批的编程模型,你可以使用静态数据批处理一样的方式来编写流式计算操作。并且支持基于event_time的时间窗口的处理逻辑。
随着数据不断地到达,Spark 引擎会以一种增量的方式来执行这些操作,并且持续更新结算结果。可以使用Scala、Java、Python或R中的DataSet/DataFrame API来表示流聚合、事件时间窗口、流到批连接等。此外,Structured Streaming会通过checkpoint和预写日志等机制来实现Exactly-Once语义。
简单来说,对于开发人员来说,根本不用去考虑是流式计算,还是批处理,只要使用同样的方式来编写计算操作即可,Structured Streaming提供了快速、可扩展、容错、端到端的一次性流处理,而用户无需考虑更多细节
默认情况下,结构化流式查询使用微批处理引擎进行处理,该引擎将数据流作为一系列小批处理作业进行处理,从而实现端到端的延迟,最短可达100毫秒,并且完全可以保证一次容错。自Spark 2.3以来,引入了一种新的低延迟处理模式,称为连续处理,它可以在至少一次保证的情况下实现低至1毫秒的端到端延迟。也就是类似于 Flink 那样的实时流,而不是小批量处理。实际开发可以根据应用程序要求选择处理模式,但是连续处理在使用的时候仍然有很多限制,目前大部分情况还是应该采用小批量模式。
1.3.2. API
1.Spark Streaming 时代
Spark Streaming 采用的数据抽象是DStream,而本质上就是时间上连续的RDD,对数据流的操作就是针对RDD的操作

2.Structured Streaming 时代
Structured Streaming是Spark2.0新增的可扩展和高容错性的实时计算框架,它构建于Spark SQL引擎,把流式计算也统一到DataFrame/Dataset里去了。
Structured Streaming 相比于 Spark Streaming 的进步就类似于 Dataset 相比于 RDD 的进步
1.3.3. 主要优势
1.简洁的模型。Structured Streaming 的模型很简洁,易于理解。用户可以直接把一个流想象成是无限增长的表格。
2.一致的 API。由于和 Spark SQL 共用大部分 API,对 Spaprk SQL 熟悉的用户很容易上手,代码也十分简洁。同时批处理和流处理程序还可以共用代码,不需要开发两套不同的代码,显著提高了开发效率。
3.卓越的性能。Structured Streaming 在与 Spark SQL 共用 API 的同时,也直接使用了 Spark SQL 的 Catalyst 优化器和 Tungsten,数据处理性能十分出色。此外,Structured Streaming 还可以直接从未来 Spark SQL 的各种性能优化中受益。
4.多语言支持。Structured Streaming 直接支持目前 Spark SQL 支持的语言,包括 Scala,Java,Python,R 和 SQL。用户可以选择自己喜欢的语言进行开发。
1.3.5. 未来展望
Structured Streaming 决定使用 Dataset/DataFrame API 最主要的一个原因就是希望用户不再需要分别为批处理和流处理编写不同代码,而是直接使用同一套代码。
类似于 Dataset/DataFrame 代替 Spark Core 的 RDD 成为为 Spark 用户编写批处理程序的首选,Dataset/DataFrame 未来也将替代 Spark Streaming 的 DStream,成为Spark 用户编写流处理程序的首选。
有了 Structured Streaming,意味着 Spark 不仅具有卓越的批处理能力,也同时具备了优秀的流处理能力,可以用 Spark 来构建统一批处理和流处理的大数据平台。这样的大数据平台更能适应未来人工智能快速发展,满足更大数据量、更多样化的数据处理的需求
Google 之前有一篇 paper ( "Hidden Technical Debt in Machine Learning Systems" Google NIPS 2015)提到了,在一个机器学习系统中的机器学习代码只占一小部分,有很大一部分是用来进行数据收集、清理、验证、特征提取、分析等各种操作。而后面这些工作都是 Spark 所擅长的。
不过需要注意的是尽管在2.2.0以后 Structured Streaming 被标注为稳定版本,生产环境中可以使用了,但是,相对来说,Structured Streaming还处于比较初级的阶段,很多功能与dataflow相比还是有差距,比如对于exactly once语义的保障,要求外部数据源具备offset定位的能力,还不支持session window,且Append模式更新只能支持无聚合操作的场景,还有对于join等操作还有各种限制等等,这些部分和dataflow已实现的功能还有较大的差距。
最后,相信凭借正确的设计理念,spark广大的使用群体、活跃的社区,Structured Streaming在未来可能会有更好的发展。



总结:
1-问题的引入:
- SparkStreaming只能做的秒级的近实时对于毫秒级输出处理,还有对于复杂事件处理都捉襟见肘
- 如对于以下数据特征不能很好的进行处理
- event-time-事件的发生时间
- process-time-事件的处理时间
- data-延迟数据
2-论文的诞生
- google的 dataflow论文中提到的很多思想能够解决以上问题并有相应的开源实现 Apache Bean(目前国内不太流
- Spark借鉴了 dataflow论文的思想诞生了 Structured streaming
3-StructuredStreaming
- StructuredStreaming是基于 SparkSQL的一套统一了流计算和批计算的AP| Data Frame/Data Set
- 未来会成为 Spark应用开发的首选AP
4-未来发展趋势:
