
Hadoop总结:
Hadoop是什么?
- 狭义上:
HDFS:分布式文件存储系统
MapReduce:分布式计算框架
YARN:资源管理任务调度
- 广义上:
特指apache一款由java开发,开源的大户数据处理平台软件
hadoop生态圈,提供大数据一站式解决方案,大数据软件几乎都有!
hadoop 的发展:
Google三篇论文 之父--cutting(卡大爷)
hadoop集群的搭建:
Hadoop集群介绍:
发行版本:
社区版:apache官方版
商业版:cloudera---CDH
版本演化:
1.x--2.x(高阶版本)---3.x
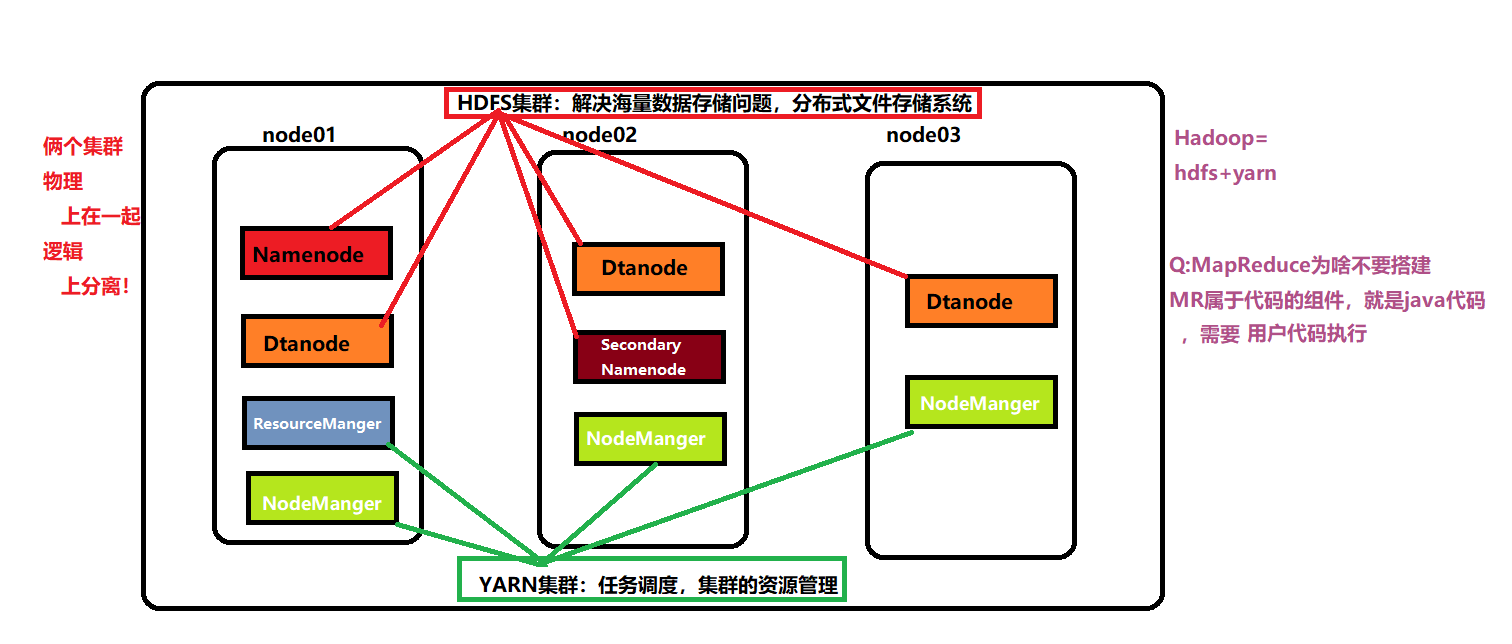
hadoop集群:【都是标准的主从集群 逻辑上分离 物理上在一起】
hdfs集群(解决分布式文件存储问题):
主角色:namenode
从角色:detanode
主角是辅助角色:secondarynamenode
yarn集群(资源调度任务管理):
主角是:resourcemanager
从角色:nodemanager
MR集群(其实没有):
是在代码层面组件,本身就是java程序
1:服务器环境准备
时间同步 防火墙 免密登录 hosts映射 jdk
2:安装包编译
2.1:为什么要编译
- 官方只提供源码包 需要自己编译
- 软件运行某些特性跟操作系统相关 结合具体操作系统编译符合它版本的软件
- 修改源码中某些属性
3:安装包目录结构
基本管理脚本目录------------bin
启动关闭脚本-----------------sbin
配置文件目录-------------------etc
编译后jar 官方自带示例----share
4:配置文件
shell脚本---------hadoop-env.sh 导入java_home
xml文件------------core hdfs mapred yarn---site.xml(用户自定义配置文件) xxx---default.xml(默认配置文件)
slaves-------------配合脚本一键启动 hosts白名单机制
5:namenode format
首次启动hdfs 只能一次 namenode所在机器上
hadoop namenode -format
初始化操作 创建hadoop工作相关目录和文件
6:hadoop集群启动
单节点逐个启动
hadoop-daemon.sh start|stop 进程名字
yarn-daemon.sh start|stop 进程名字
脚本一键启动
免密登录 slaves
start-dfs.sh
start-yarn.sh
start-all.sh
7:web ui
hdfs namenode 50070
yarn resourcemanager 8088
hadoop功能:
jobhistory:查看已经运行历史的job程序
hdfs垃圾回收机制:
开启垃圾回收站 把删除的文件首先放置在回收站中 等待配置的时间结束 进行真正的数据删除
如何模拟实现分布式文件系统:
分布式:
元数据管理:
分块存储:
副本机制:
抽象目录树结构:
画图介绍:

本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。
