
Hadoop2.x的安装与配置

- 安装JDK
hadoop集群搭建
-
hadoop发行版本
-
- 社区版:官方版本 apache社区维护
- 优点:功能最新的 免费
- 缺点:稳定性 兼容性不好
https://archive.apache.org/dist/hadoop/common/
hadoop-2.6.0-src.tar.gz 官方提供的源码包
hadoop-2.6.0.tar.gz 官方预编译安装包
- 商业版:商业公司在社区版本至少进行商业化开发 架构 api 配置不会发生改变 主要改变bug和兼容性
- 优点:稳的一批 兼容性极好
- 缺点:花钱 某些软件可能版本不高 不能使用最新的功能
http://archive.cloudera.com/cdh5/cdh/5/
hadoop-2.6.0-cdh5.14.0-src.tar.gz cdh版本源码包
hadoop-2.6.0-cdh5.14.0.tar.gz cdh版本预编译安装包只要保证cdh版本号是一致的 该版本号中所有的生态圈软件之间都是兼容的
- 使用cdh最稳定的一个版本 cdh5.14.0--hadoop 2.6.0
- 社区版:官方版本 apache社区维护
-
hadoop自身版本发展
-
- 历经了1.X 2.X 3.X
- 当下企业中使用最多的是2系列高阶版本 2.5~2.8 稳定兼容性最好
-
hadoop集群介绍
-
- hadoop分为两个集群 hdfs集群 yarn集群
- hdfs集群 分布式文件存储
- 主角色:namenode(nn)
- 从角色:datanode(dn)
- 主角色辅助角色(秘书角色):secondarynamenode(snn)
- yarn集群 集群资源管理 任务调度
- 主角色:resourcemanager(rm)
- 从角色:nodemanager(nm)
-
hadoop部署模型
-
- 单机模式 所有的进程在一个机器上运行 过家家
- 伪分布模式 每个进程独立 在一台机器上 模拟分布式执行环境
- 分布式集群模式:多个进程多台机器 生成环境中的模式
- HA高可用集群: 主要解决了单点故障 保证集群稳定 可靠
-
hadoop安装环境检测
-
- jdk是否正常安装 环境变量
- 时间是否同步
- 防火墙是否关闭
iptables selinux
- 主机名 ip映射
- 免密登录 ssh
-
hadoop源码编译
-
- 为什么某些软件需要编译源码
软件的运行依赖于操作系统平台 操作系统之间存在着差异性 下载源码结合具体平台进行编译
修改源码中某些组件的逻辑 - 什么叫做编译
以java语言来说 把.java 编译成.class --->jar 便于程序运行
- 如何编译源码
在每个版本的hadoop 源码包中 building.txt 里面描述了该版本的编译需要配置的依赖软件
最终只需要执行mvn -pachage 进行编译
保证编译过程中网络的顺畅 jar可以下载 推荐使用课程中提供cdh编译需要的jar仓库
- 为什么某些软件需要编译源码
- 集群规划(站在架构的角度规划服务器集群分配)
- 根据软件自己 软件之间的工作特性结合服务器的硬件特性 合理安排软件运行在不同的机器上
- 原则:
- 优先满足软件需要的硬件资源
- 尽量避免有冲突的软件不在一起
- 有工作上依赖的软件尽量部署在一起
NodeManager和Datanode通常部署在一台机器上。
node-1: NameNode DataNode | ResourceManager NodeManager
node-2: DataNode SecondaryNameNode| NodeManager
node-3: DataNode | NodeManager如何扩展hadoop集群
node-4 DataNode NodeManager
node-5 DataNode NodeManager
node-6 DataNode NodeManager
.......
-
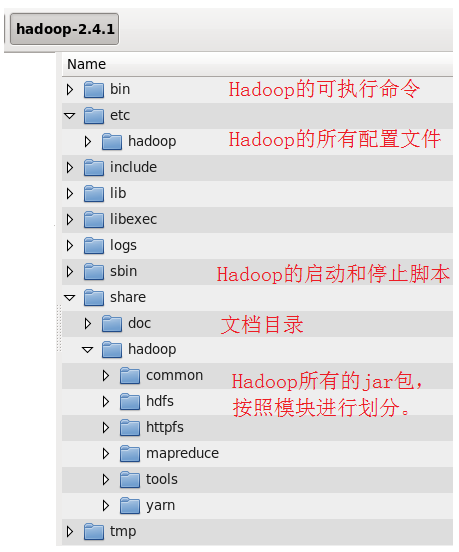
hadoop 安装目录结构
-
bin hadoop集群管理的基本脚本
etc 配置文件路径
include
lib
libexec
sbin hadoop集群启动关闭的脚本(单节点逐个 一键启动)
share hadoop 编译之后的jar 官方自带示例
-
hadoop配置修改
-
- 第一类 shell脚本 hadoop-env.sh
导入java_home 保证hadoop运行的时候一定可以正确的加载jdk环境变量
vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_65 - 第二类配置文件 4个 xml文件(分别配置了 hdfs mapreduce yarn common)
- core-site.xml common模块
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:8020</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoopdata</value>
</property> - hdfs-site.xml hdfs模块
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-2:50090</value>
</property> - mapred-site.xml mr模块
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> - yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node-1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- core-site.xml common模块
- 第三类配置文件 slaves
- 配合一键启动脚本 到slaves指定的机器上启动hdfs和yarn集群的从角色
- 通过 dfs.hosts 指定的slaves文件中的机器才可以加入hadoop集群 白名单
- 一个写一个ip或者主机名
node-1
node-2
node-3
- 第一类 shell脚本 hadoop-env.sh
-
把主节点上配置 好的安装包scp给其他节点上
-
cd /export/servers/
scp -r hadoop-2.6.0-cdh5.14.0/ node-2:$PWD
scp -r hadoop-2.6.0-cdh5.14.0/ node-3:$PWD - 添加hadoop的环境变量
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
安装部署的三种模式
- 本地模式
| 参数文件 | 配置参数 | 参考值 |
|---|---|---|
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
- 伪分布模式
| 参数文件 | 配置参数 | 参考值 |
|---|---|---|
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
| hdfs-site.xml | dfs.replication | 1 |
| ... | dfs.permissions | false |
| core-site.xml | fs.defaultFS | hdfs://<hostname>:9000 |
| ... | hadoop.tmp.dir | /root/training/hadoop-2.7.3/tmp |
| mapred-site.xml | mapreduce.framework.name | yarn |
| yarn-site.xml | yarn.resourcemanager.hostname | <hostname> |
| ... | yarn.nodemanager.aux-services | mapreduce_shuffle |
- 全分布模式
| 参数文件 | 配置参数 | 参考值 |
|---|---|---|
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.8.0_144 |
| hdfs-site.xml | dfs.replication | 2 |
| ... | dfs.permissions | false |
| core-site.xml | fs.defaultFS | hdfs://<hostname>:9000 |
| ... | hadoop.tmp.dir | /root/training/hadoop-2.7.3/tmp |
| mapred-site.xml | mapreduce.framework.name | yarn |
| yarn-site.xml | yarn.resourcemanager.hostname | <hostname> |
| ... | yarn.nodemanager.aux-services | mapreduce_shuffle |
| slaves | DataNode的ip地址或主机名 | qujianlei001 |
如果出现以下警告信息:

只需要在以下两个文件中增加下面的环境变量,即可:
- hadoop-env.sh 脚本中:
export JAVA_HOME=/root/training/jdk1.8.0_144export HADOOP_HOME=/root/training/hadoop-2.7.3export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
- yarn-env.sh 脚本中:
export JAVA_HOME=/root/training/jdk1.8.0_144export HADOOP_HOME=/root/training/hadoop-2.7.3export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
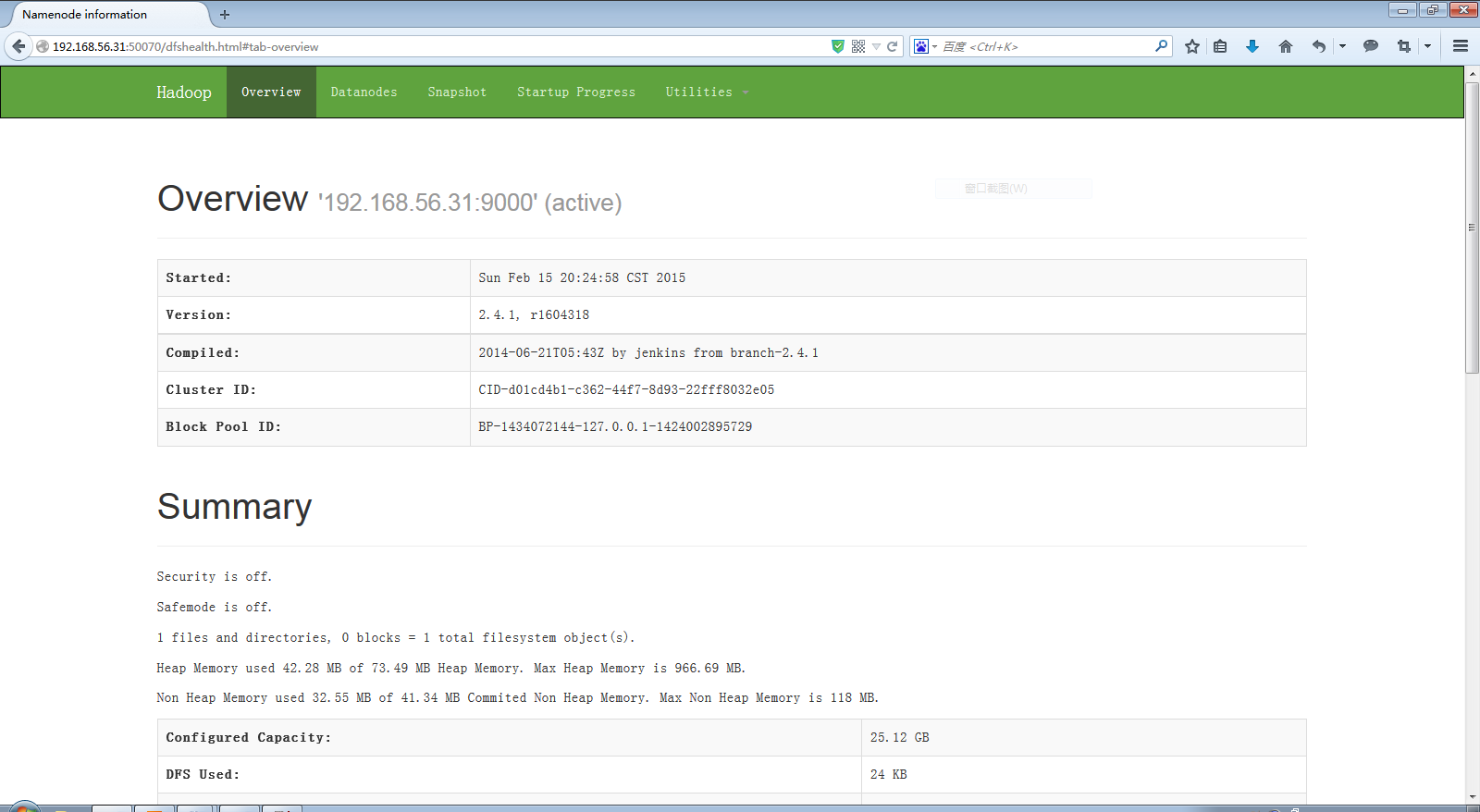
(四)验证Hadoop环境
- HDFS Console:http://192.168.157.11:50070
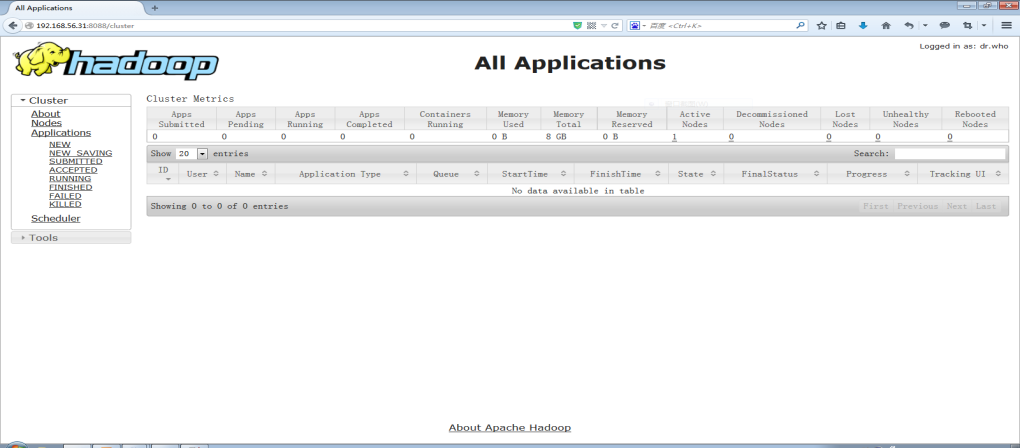
- Yarn Console:http://192.168.157.11:8088
(五)配置SSH免密登录
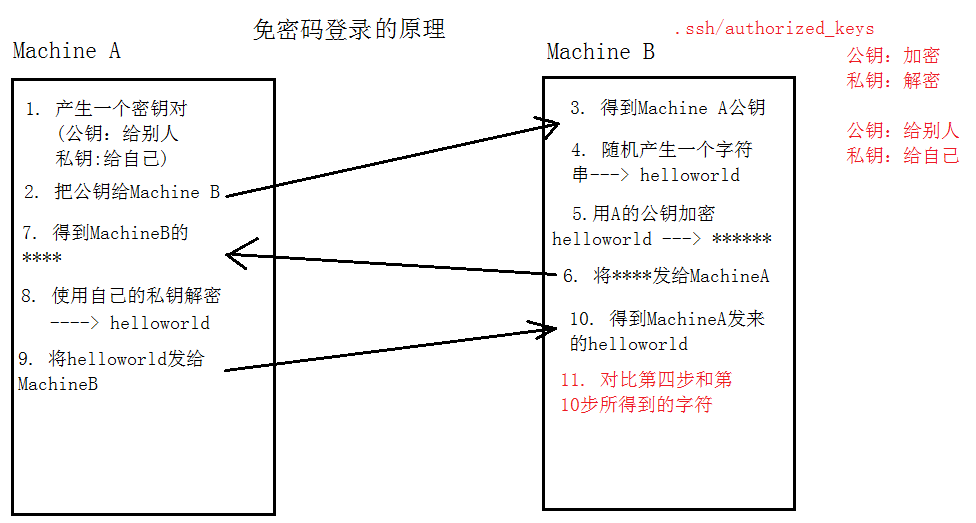
详细操作见:https://blog.csdn.net/a909301740/article/details/84147035
附件列表
