java hashcode方法
什么是hashcode方法?
hashCode()方法作用是返回一个int类型的数值,也就是哈希值,该方法的主要作用就是在散列的储存结构中确定对象的储存地址,哈希值相同的对象会存放在同一个桶里,所以哈希值相同不代表两个对象就相等了。
对象的hashcode怎么得到?
hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置。hashcode只是代表了在hash表中的位置,和对象实际上的地址是不等同的,所以hashcode就是对象的地址的说法是错误的,一个对象肯定有它的物理地址,物理地址说的才是对象在内存中的地址。hashcode是通过对象的物理地址转换为的一个整数,然后该整数通过hash函数算法才得到的hashcode,这个hashcode对应对象在哈希表中的位置。
具体过程是如何实现的呢?举例,假如哈希表中有6个位置,分别为1,2,3,4,5,6一个对象的物理地址转换为整数13,13%6=1,那么,它就被分配到哈希表1这个位置,它的hashcode也为1,同理,别的对象如果hashcode也为1那么它也会被分配到哈希表的1位置。
为什么hashcode不直接写物理地址呢,还要另外用一张hash表来代表对象的地址?
因为HashCode的存在主要是为了查找的快捷性,如Hashtable,HashMap等HashCode是用来在散列存储结构中确定对象的存储地址的(后半句说的用hashcode来代表对象就是在hash表中的位置)
从Object角度看,JVM每new一个Object,它都会将这个Object丢到一个Hash表中去,这样的话,下次做Object的比较或者取这个对象的时候(读取过程),它会根据对象的HashCode再从Hash表中取这个对象。这样做的目的是提高取对象的效率。若HashCode相同再去调用equal。
至于为什么hashcode查找效率高,可以举一个例子,1000个空位存放1000个不重复的数,最直接粗暴的方法就是每存一个数就对之前的数进行遍历,看看有没有重复的,这样效率是非常低下的。我们可以用hash表来提高效率,假如哈希表有8个位置1、2、3、4、5、6、7、8,存第一个数它对应哈希表中1的位置,如果已经存了100个不相同的数,位置1里有10个,那么101个数的hashcode为1,那么只需要与hashcode为1位置的其它10个数进行比较即可,不用遍历其它所有数,当哈希表的位置越多那么你比较的次数就会越少。
equals()方法与hashcode()
我们可以用equals方法来验证哈希值相同不代表两个对象的内容相同。
public static void main(String[] args) {
String s1="通话";
String s2="重地";
System.out.println("s1="+s1.hashCode() + ":s2=" + s2.hashCode());
System.out.println(s1.equals(s2));
}
执行结果:
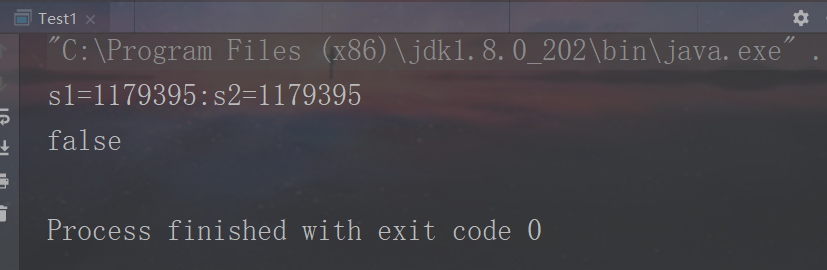
虽然s1和s2的hashhcode值相同,但是它们的内容很显然是不一样的,equal()方法的作用是判断对象内容是否相同,结果是false,所以,两个对象的哈希值相等,并不一定能得出两个对象的值也相等。
对此,可以得出结论:
- 如果两个对象equals相等,那么这两个对象的HashCode一定也相同
- 如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置,也可以理解为放在同一个桶中

