
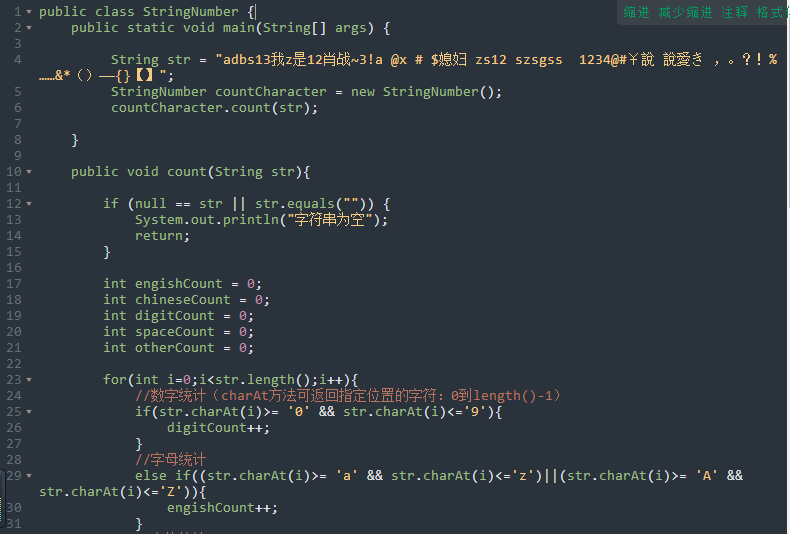
一、思路
1、不需要同时判断中文字符和特殊字符:
数字:str.charAt(i)>= '0' && str.charAt(i)<='9'
字母:str.charAt(i)>= 'a' && str.charAt(i)<='z')||(str.charAt(i)>= 'A' && str.charAt(i)<='Z'
空格:str.charAt(i) ==' '
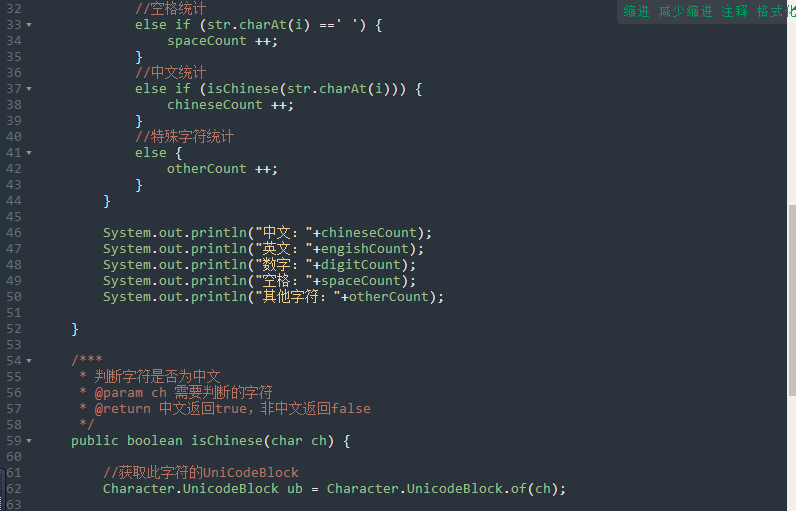
2、需要判断字母时可以用Java Character 实现Unicode字符集判断是否是中文字符
二、代码

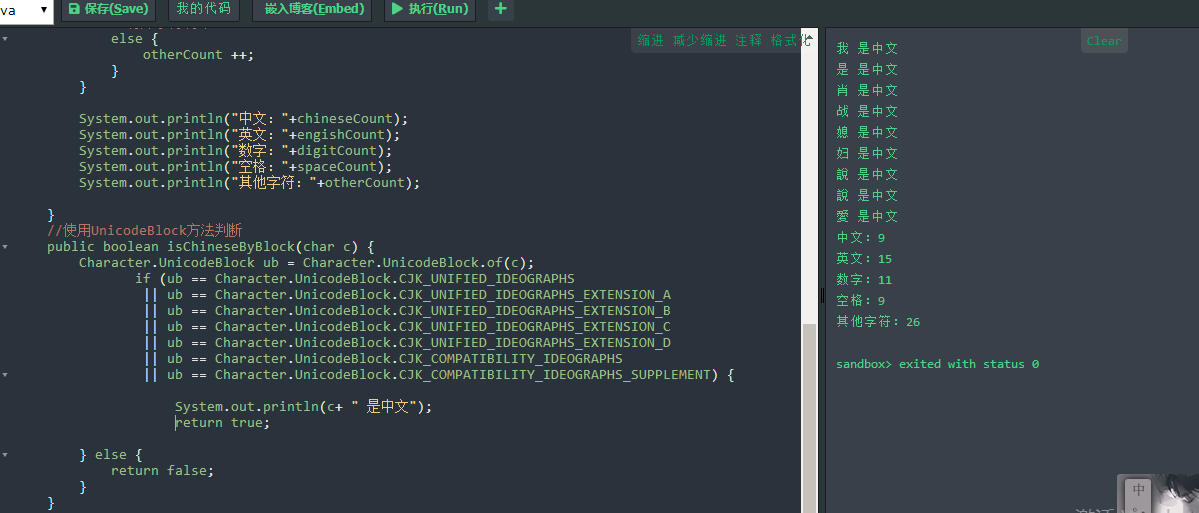
输出结果:

转载于:https://blog.csdn.net/weixin_34363171/article/details/92339890
三、知识拓展
在Java中,经常会遇到如何判断一个字是否是中文,或者是否是中文的标点符号等。所以主要使用 Character类处理字符有关功能UnicodeBlock 和 UnicodeScript类可以帮助我们判断字符类型。
1、UnicodeBlock:Unicode标准协会组织unicode码的一个基本单位,实际上一个 UnicodeBlock代表一片连续的Unicode号码段,UnicodeBlock之间不重叠。例如,通常我们利用Unicode编码是否在 0x4E00–0x9FCC 来判断某字符是否为汉字,就是因为,有个UnicodeBlock 专门划分为存储汉字 (准确的说是 CJK统一汉字),这个UnicodeBlock叫做 CJK Unified Ideographs,总共定义了 74,617 个汉字。
2、UnicodeBlock 与 UnicodeScript 关系:UnicodeScript 是从语言书写规则层次对Unicode字符的分类,这是用使用角度划分,而UnicodeBlock是从硬的编码角度划分。
1). UnicodeBlock是简单的数值范围 (其中可能有些Block中会有一些尚未分配字符的“空号”)。
2). 在一个UnicodeScript中的字符可能分散在多个UnicodeBlock中;
3). 一个UnicodeBlock中的字符可能会被划进多个UnicodeScript中。
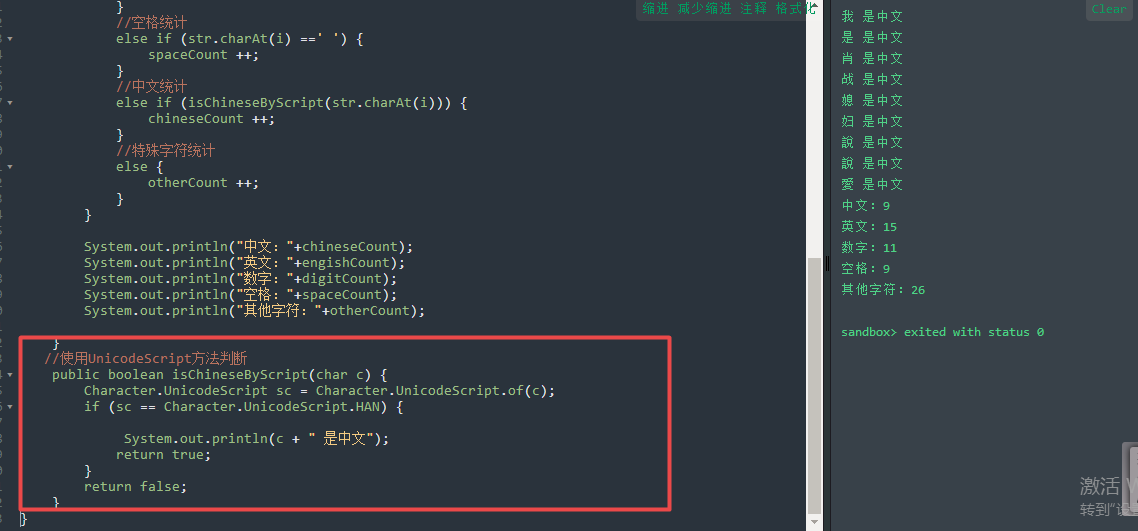
注意的是UnicodeScript实现是在Java 7中新引入的,如果使用JDK1.7,那么UnicodeScript方法会更方便。
3、例子:
3.1 文字判断
(1)使用UNICodeblock方法:
(2)使用UnicodeScript方法判断
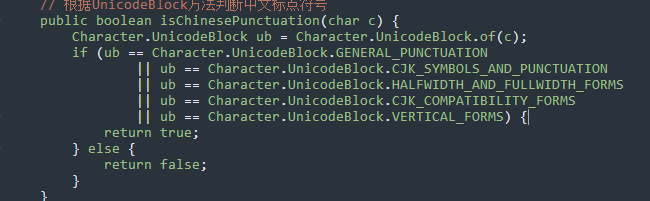
3.2 字符判断:中文的标点符号主要存在于以下5个UnicodeBlock中
● U2000-General Punctuation (百分号,千分号,单引号,双引号等)
● U3000-CJK Symbols and Punctuation ( 顿号,句号,书名号,〸,〹,〺 等;PS: 后面三个字符你知道什么意思吗? : ) )
● UFF00-Halfwidth and Fullwidth Forms ( 大于,小于,等于,括号,感叹号,加,减,冒号,分号等等)
● UFE30-CJK Compatibility Forms (主要是给竖写方式使用的括号,以及间断线﹉,波浪线﹌等)
● UFE10-Vertical Forms (主要是一些竖着写的标点符号, 等等)
转载于:https://www.cnblogs.com/zztt/p/3427452.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号