
Sequence To Sequence(序列对序列)
- 输入一个序列,输出一个序列
输出序列的长度由机器自己决定,例如:语音辨识、机器翻译、语音翻译
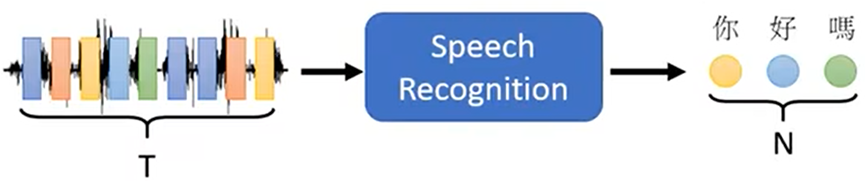


Sequence To Sequence一般分成两部分:
- Encoder:传入一个序列,由Encoder处理后传给Decoder
- Decoder:决定输出什么样的序列
Encoder
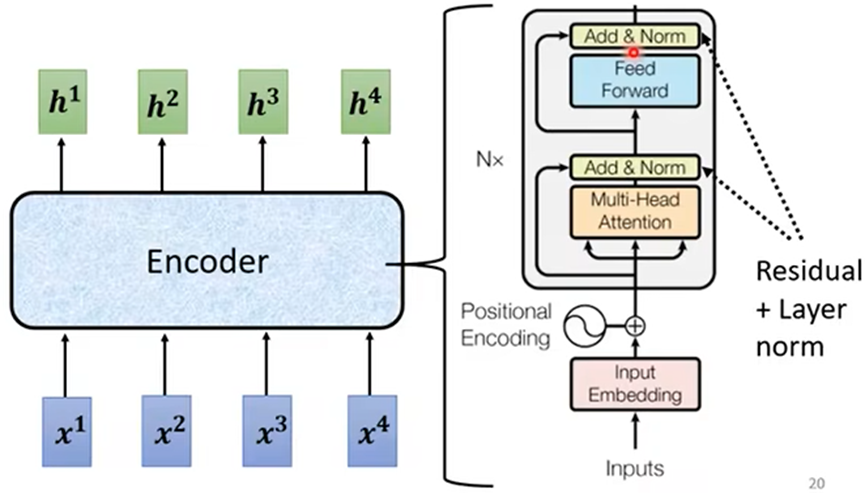
Encoder中分为多个Block,每个Block中包含多层;主要有Self attention和全连接层:
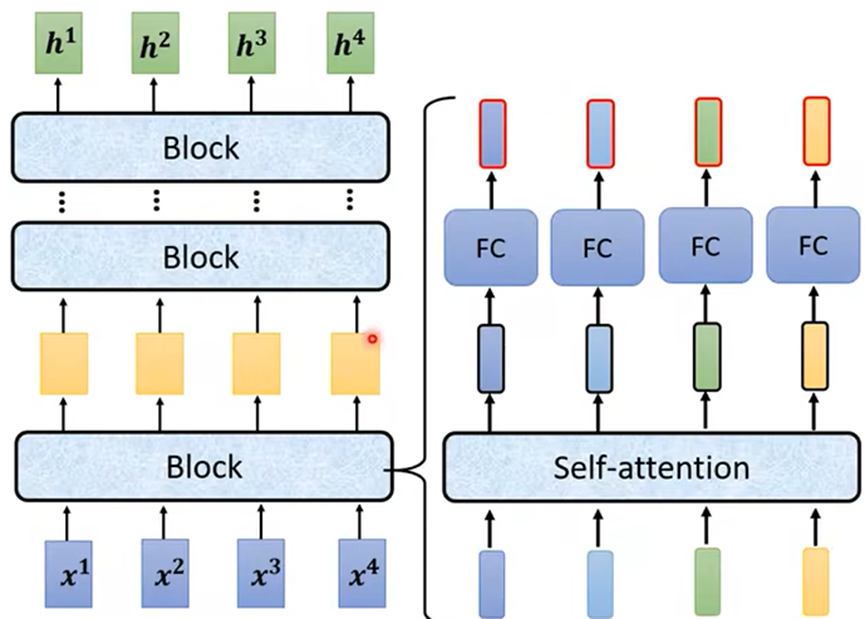
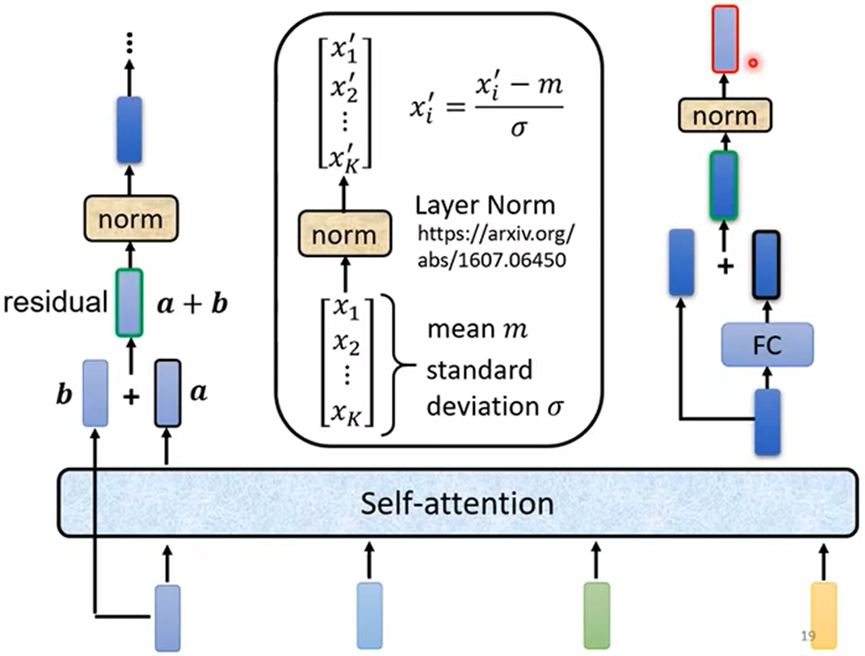
Self attention会输入的序列分别对应输出一个序列,在Transformer中加入了一些设计(residual):
- 对输出的序列加上输入序列,作为新输出;再进行标准化(norm)输出后传入全连接层
- 全连接层也有residual的设计,再次标准化(norm)输出;最终结果才是一个Block过程
Decoder
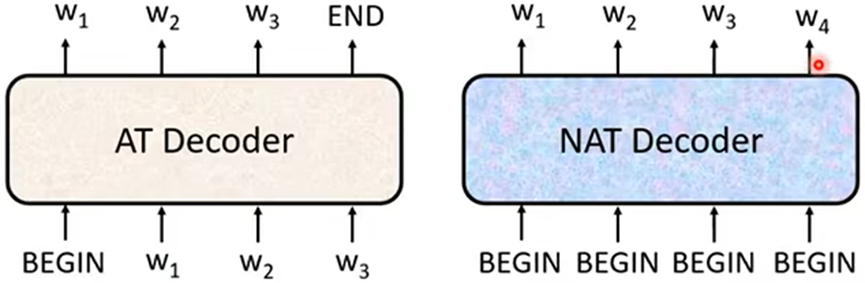
Autoregressive(AT自回归)
例如:语音辨识的Decoder;
1.首先先给其设置一个特殊符号,代表开始;Decoder会输出一个向量,长度为可能输出字的长度,向量元素的值为对应字的概率,向量的输出为概率最大的字;
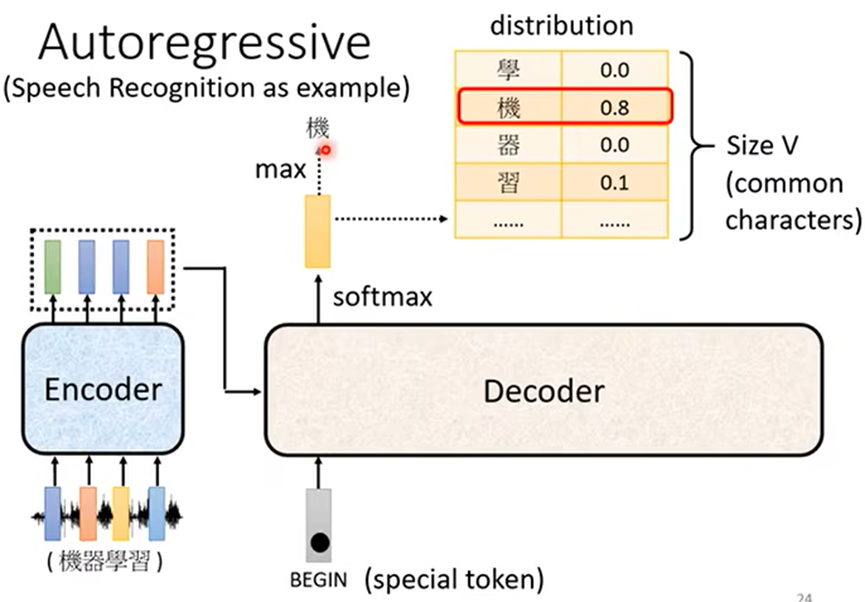
2.之后把前一个输出的字作为开始符号输出,再次输出之后的字,直至最后输出结束符号:
注:如果中间某个输出有误,则会使下一个输入错误,可能影响后面全部的结果
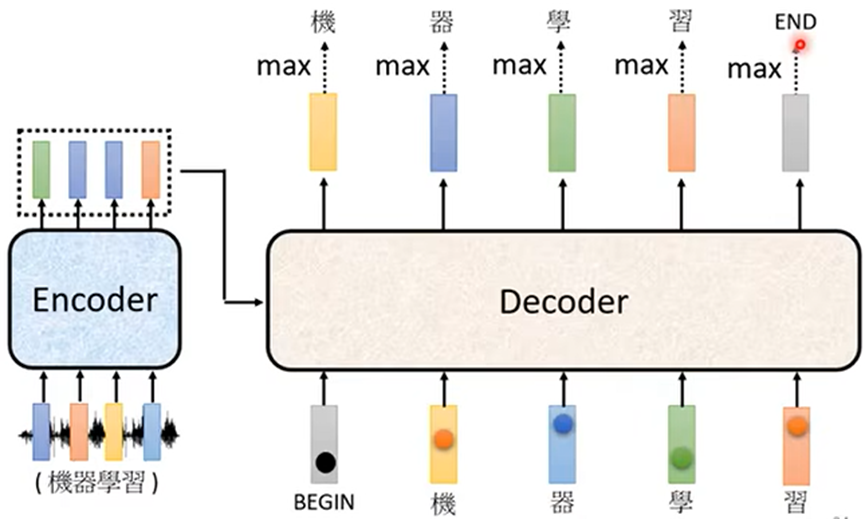
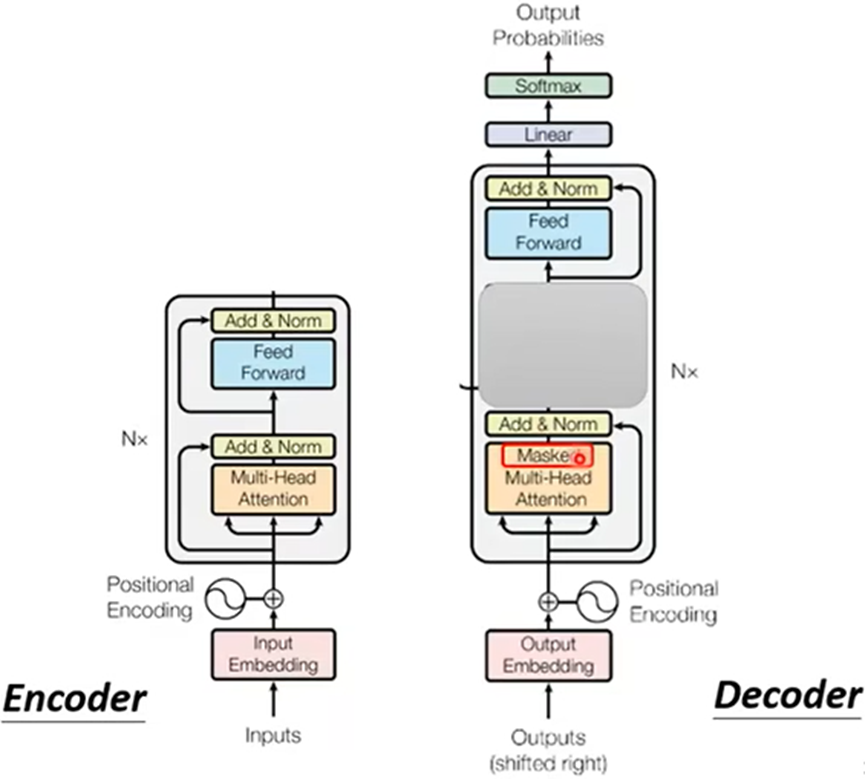
可以看出Encoder和Decoder比较相似
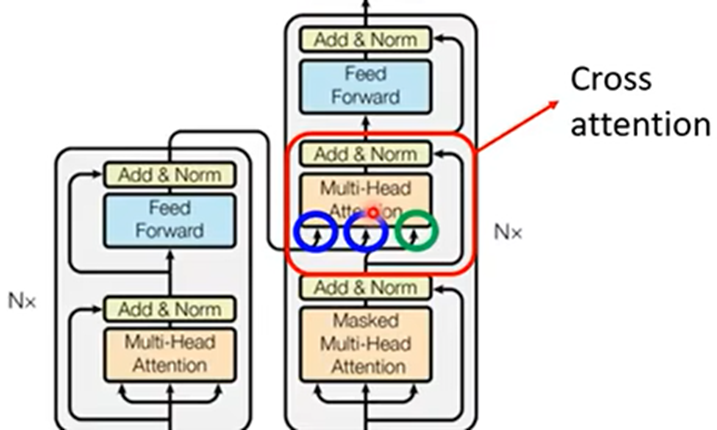
Masked self attention与self attention的区别:
- self attention:每个输出都考虑全部的输出序列
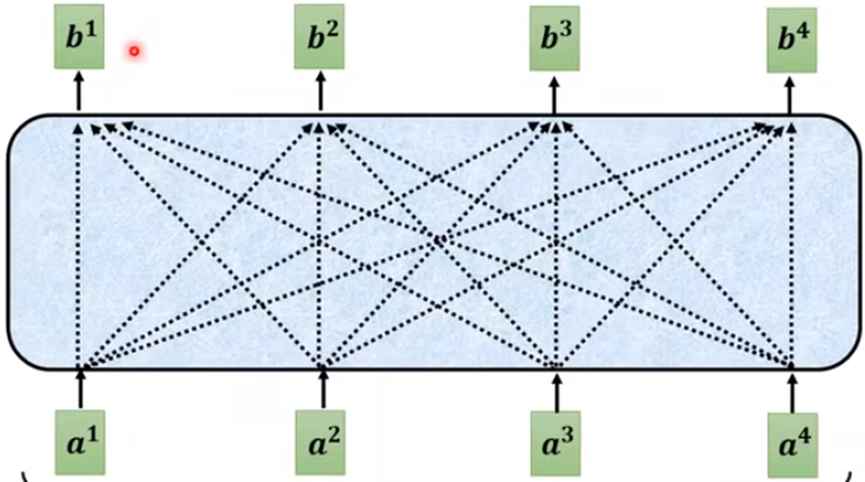
- 由于Decoderd的过程,每个输入都为上一个输出,所以Masked self attention:每个输出都考虑对应及之前的输出序列
Non Autoregressive(NAT非自回归)
- AT:输入开始符号,输出第一个字,上一次输出作为这次输入传入得到输出,直至输出结束符号
- NAT:一次性产生出整个句子
由于NAT事先不知道输出序列的长度,所以有两种方法:
- 另外做一个神经网络层设置输出,传入全部序列,输出这个NAT Decoder应该输出字的长度
- 设置输出字数的上限,最终只输出到第一个结束符号为止;
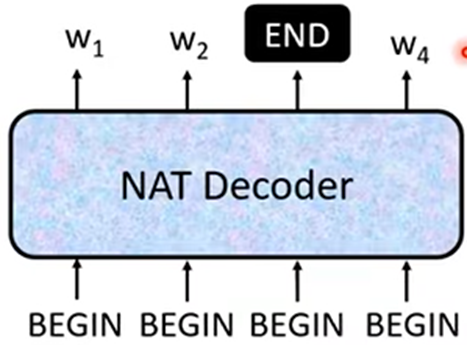
所以NAT的速度比AT的速度快
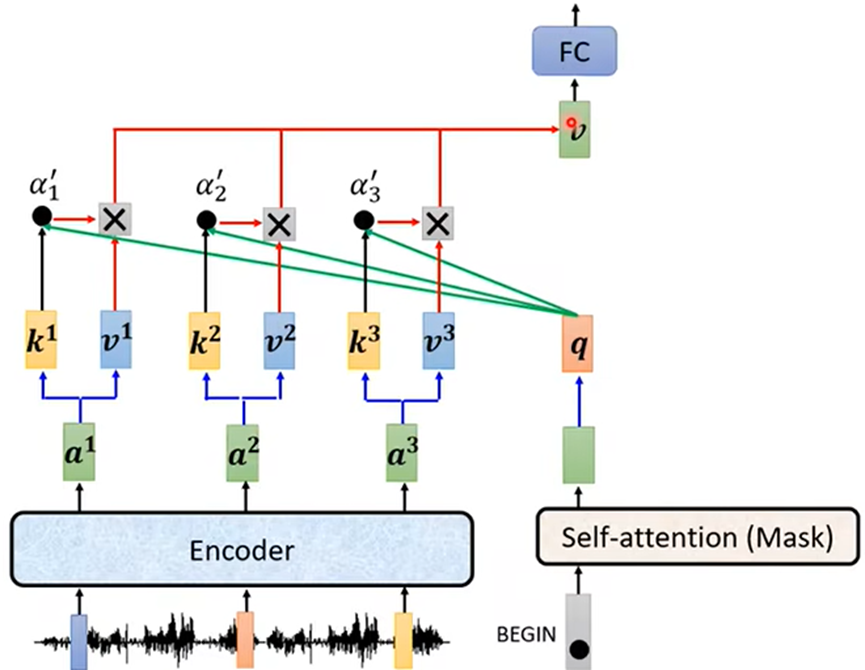
Decoder与Encoder不同
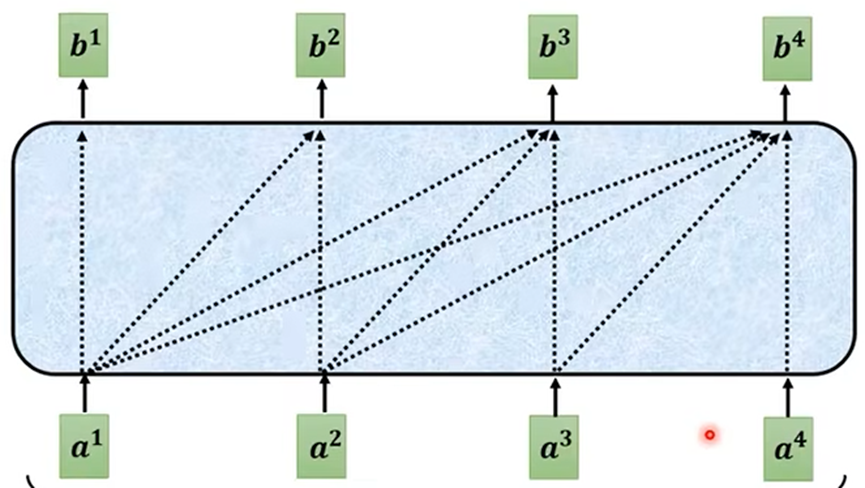
- Decoder多一个Ceoss attention,为Decoder与Encoder连接的桥梁,从Encoder传入Decoder两个参数;
具体为:
- Decoder中Masked self attention输出向量(序列)乘一个矩阵得到向量q
- Encoder输出分别乘两个矩阵得到Ki、Vi
- 计算Ki与q的关系分数αi,然后αi与Vi相乘再相加得到 v ,即为全连接层的输入;
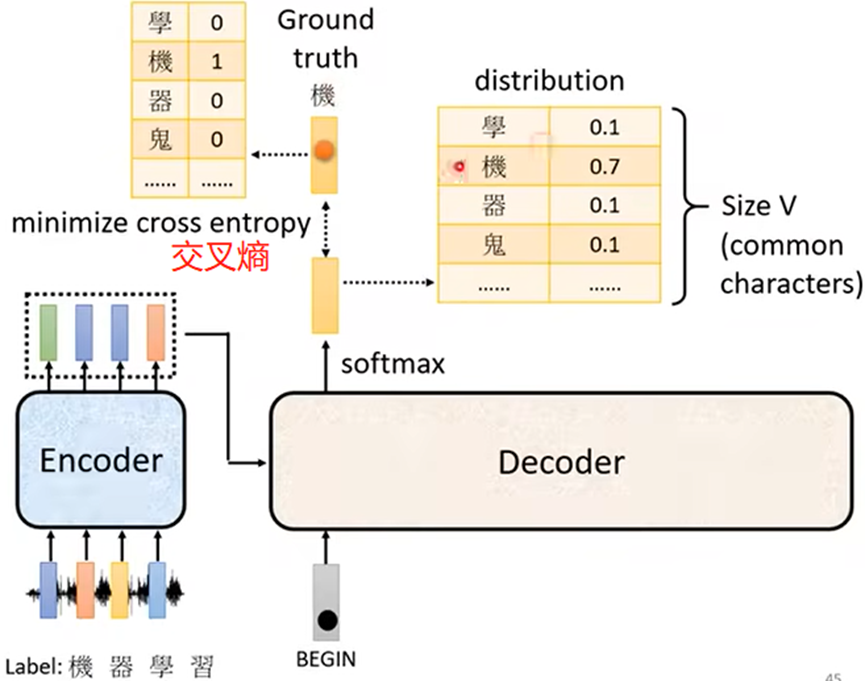
Training(训练):
例如:语音辨识的训练
使Decoder输出的序列(字的概率分布)与正确输出字的序列越接近越好(类似分类问题)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号