
self attention(自注意机制)
- 输入:以往神经网络的输入都是一个向量;如果现在输入的是一排向量,并且数量不唯一,应该如何处理:
例一:一句英文
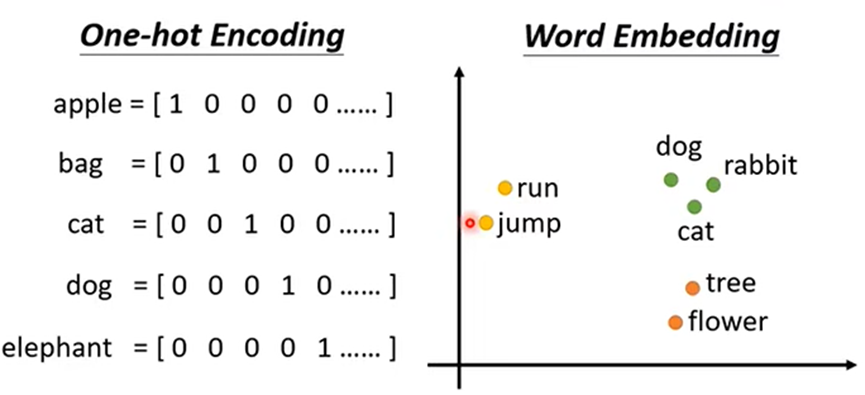
One-hot Encoding:开一个长度为世界上全部词汇数的向量表示一个词汇(缺点:词汇间没关系)
Word Embedding:给每个词汇一个坐标向量,这种方式有关系的词汇坐标距离接近
例二:声音讯号;一般会把一段声音讯号划分为一个向量(frame)(长度为25毫秒),并且每段向后移动10毫秒

例三:图;每个结点都是一个向量

- 输出:每一个输入的向量对应一个输出;

- 输出:整个序列(sequence)只输出一个标签(label),(筛选留言是正面还是反面)

- 输出:输出的标签(label)的个数不定,由机器自定

Sequence Labeling(序列标签)
- Self attention:传入整个序列(Sequence)的数据,传入几个向量就输出几个向量,输出的向量都是考虑序列全部输入向量而得出的结果;
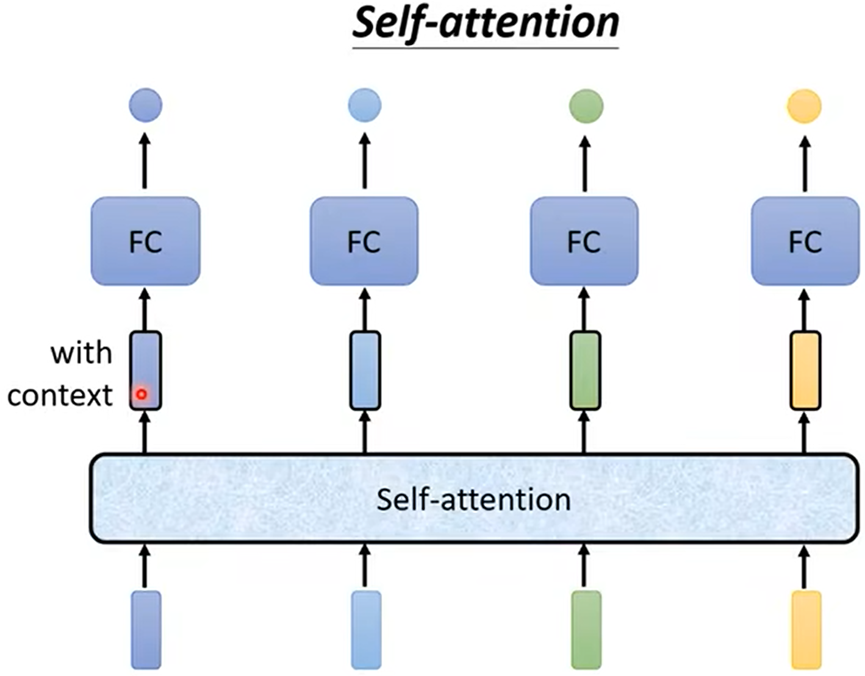
并且Self attention可以叠加多次。所以Self attention可以和FC(Fully connected network)交替使用;Self attention处理整体信息,FC专注处理某个位置的信息。
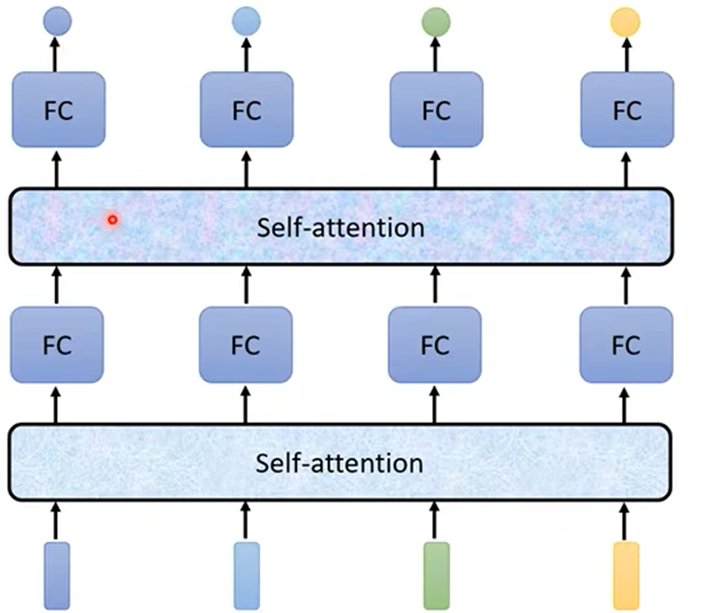
Self attention内部:
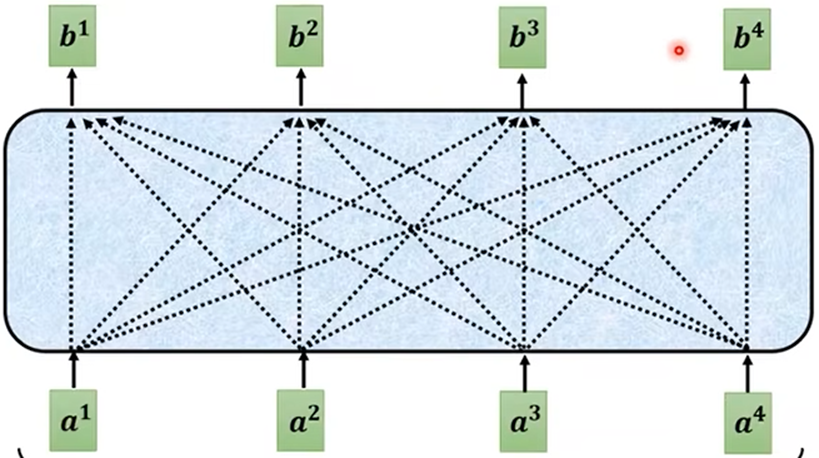
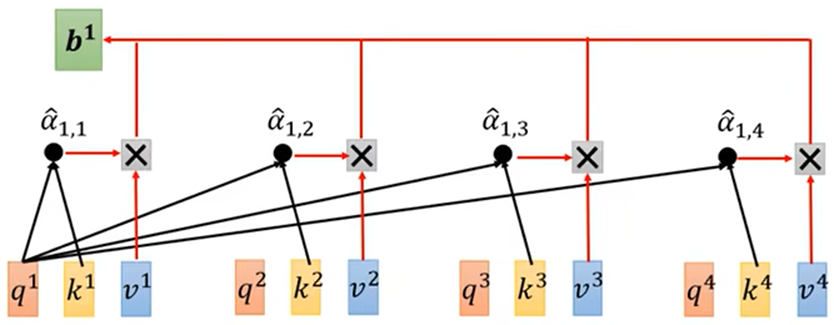
产生b1的过程:
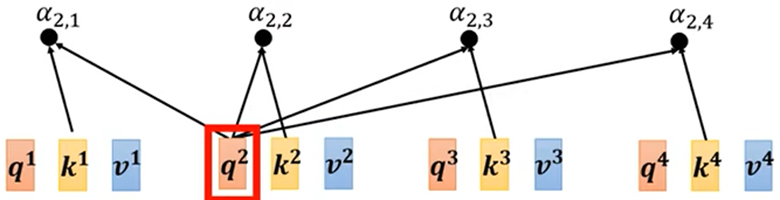
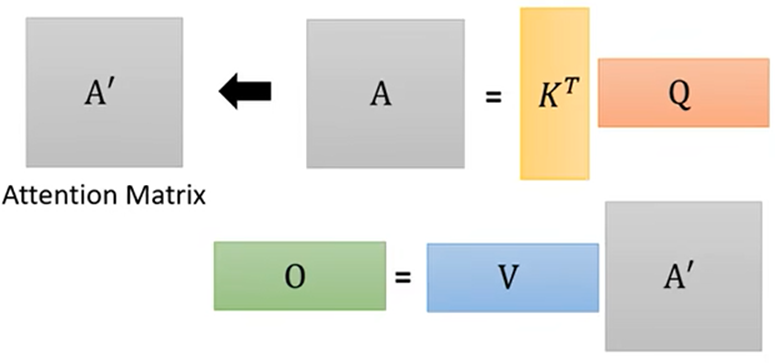
1.根据a1找出整个序列中与a1相关的其他向量的联系程度,记a1与其他几个的联系程度为α;(得到α可以用Dot product或Additive等)
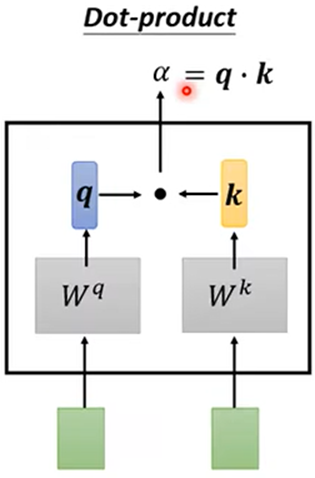
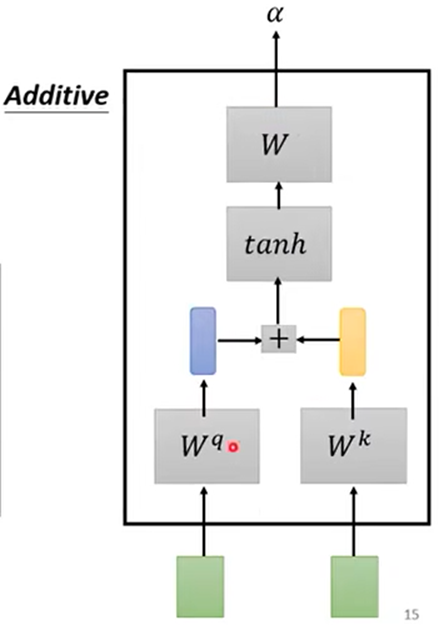
2.得到联系程度α后,再做一个Softmax或Relu等得到 α'(规范化norm),可以通过 α'抽取出序列中重要想信息
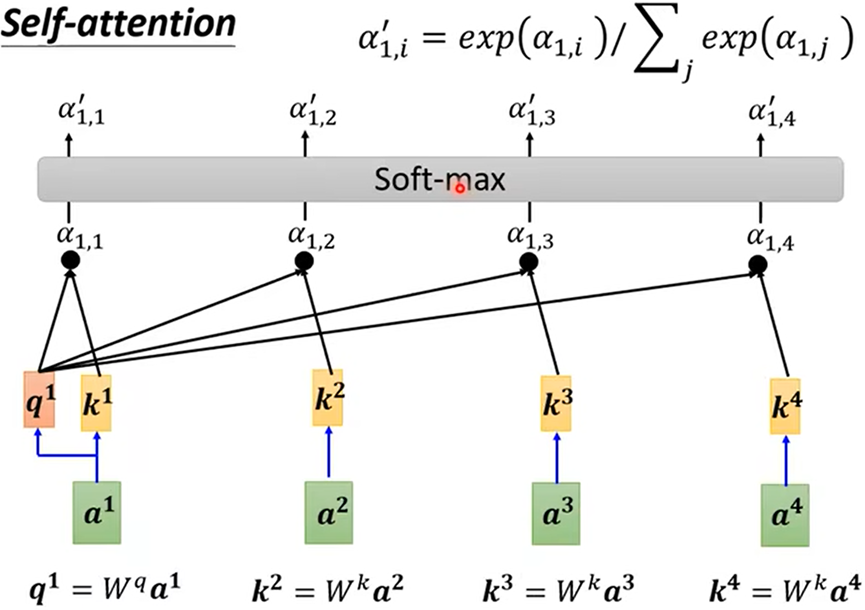
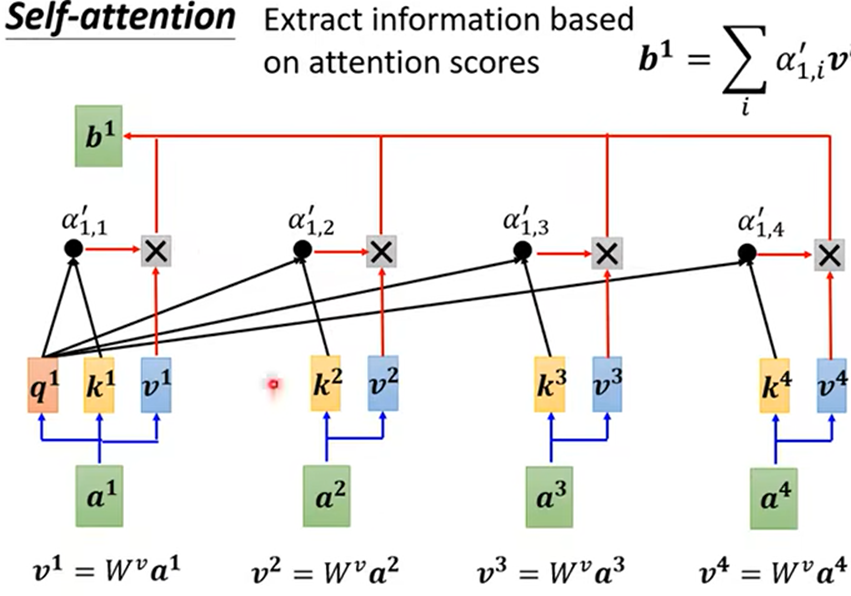
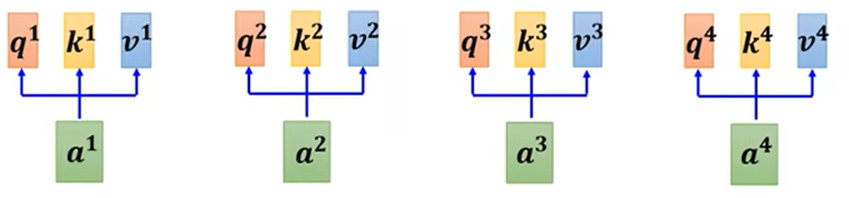
矩阵过程:
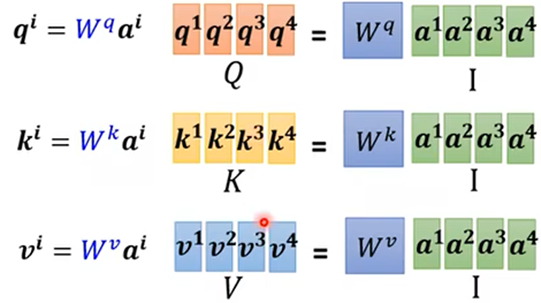
- 得到关系程度分数 α':
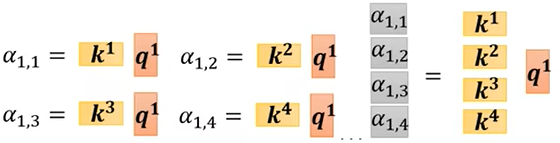

- 得出输出结果:
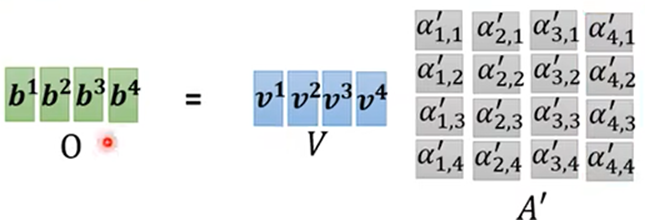
总结:
根据
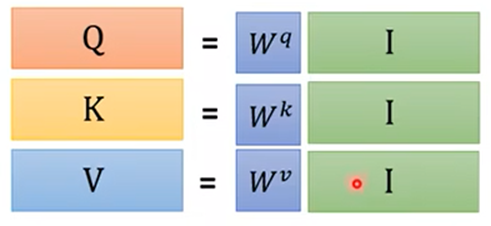
得出,需要训练得到的参数只有Wq、Wk、Wv
扩展:
- Multi head Self attention(多头自我注意),相互之间有多种相关关系
例如head=2:
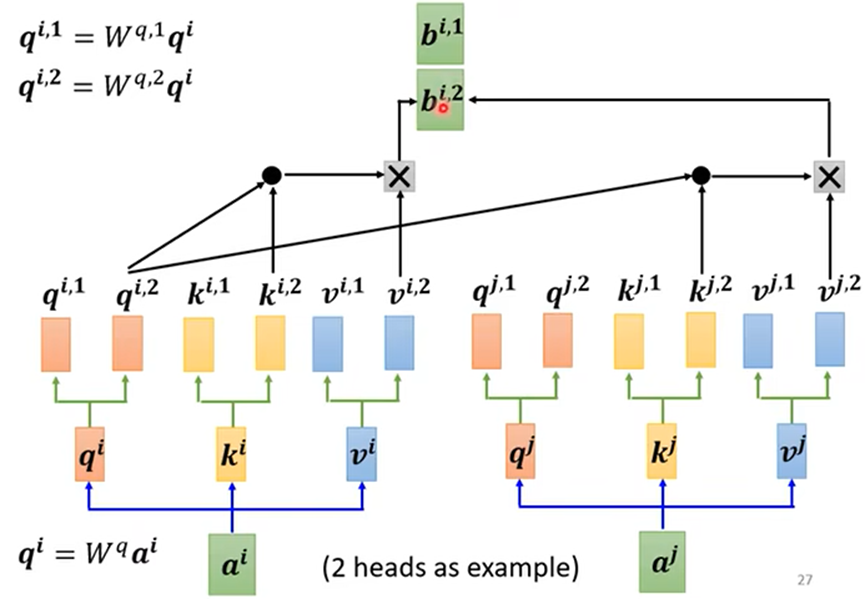
最终结果:

求法二:
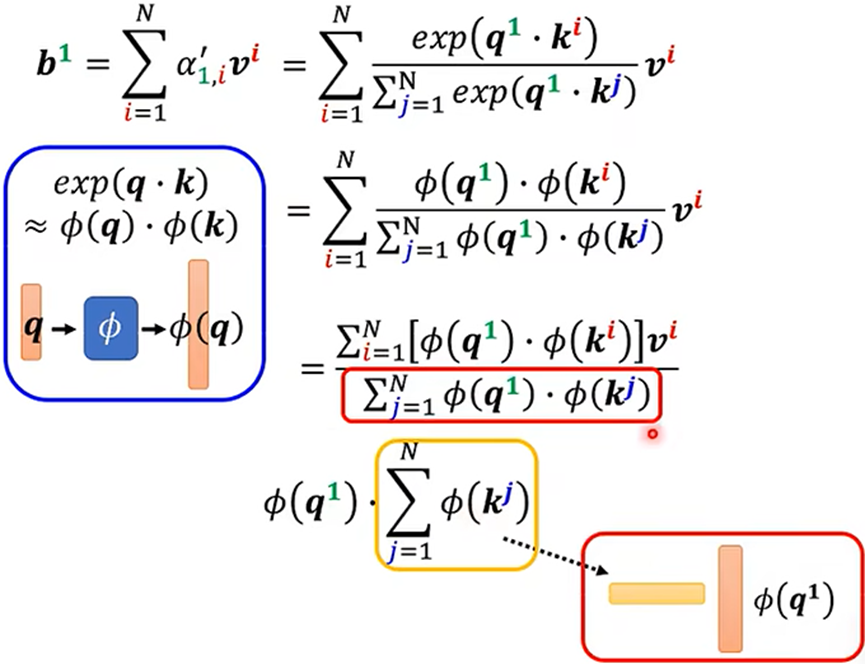

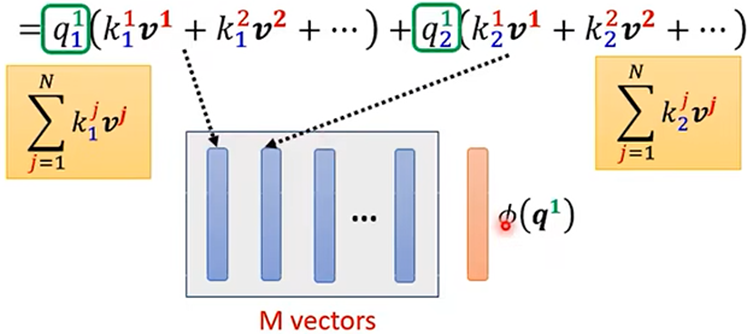
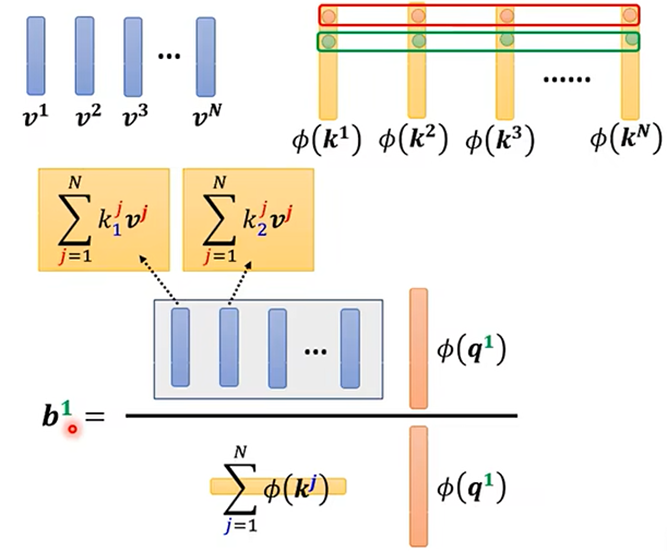
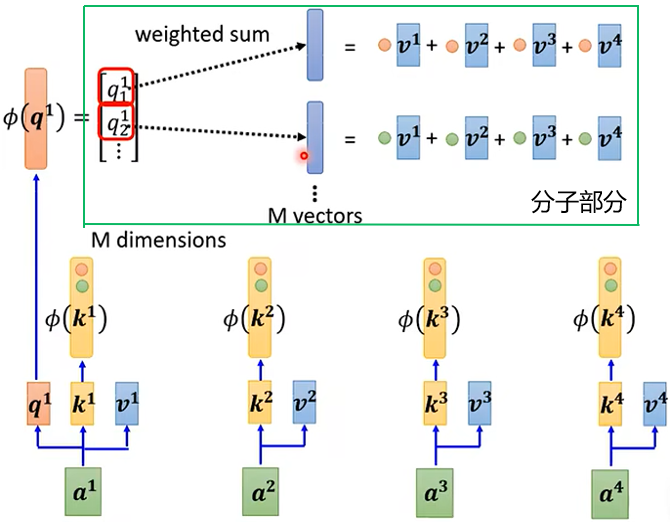
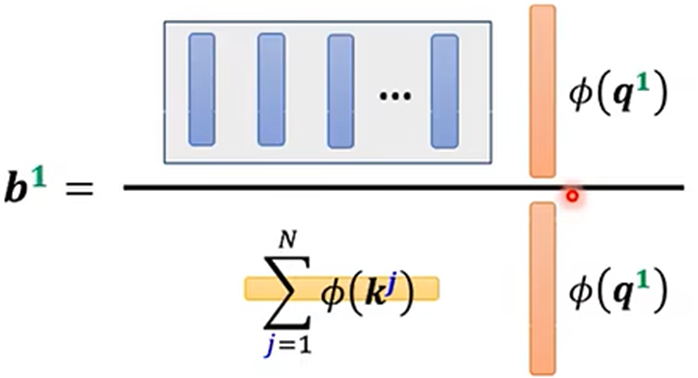
法二的计算量比法一的计算量较少
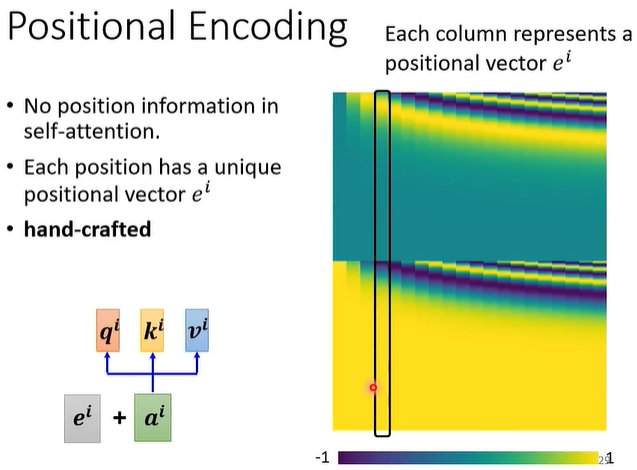
Positional Encoding
- 对每个ai加一个向量ei,ei用于标志该a的位置
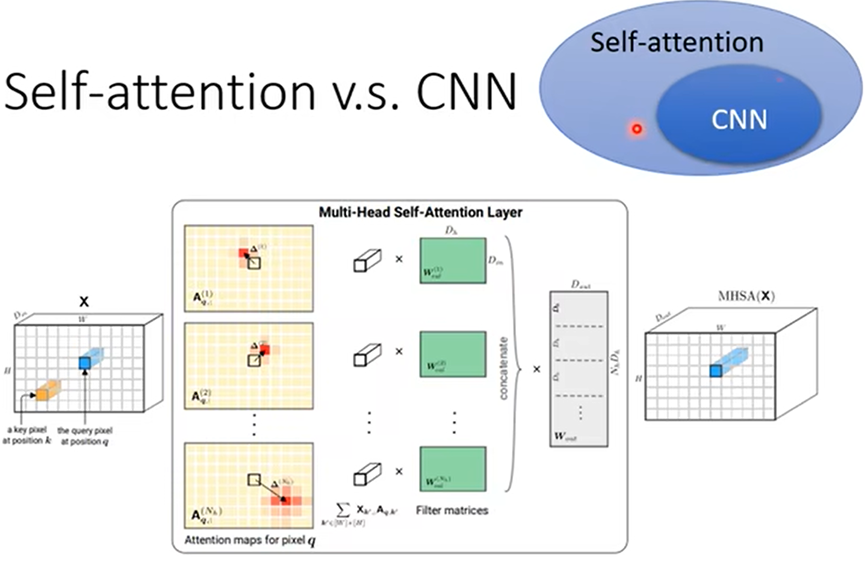
Self attenton和CNN
- Self attenton是考虑序列中全部的向量得出某向量的输出向量
- CNN(卷积神经网络Convolutional neural network)则是只考虑该向量及其周围的几个向量
Recurrent Neural Network(循环神经网络)
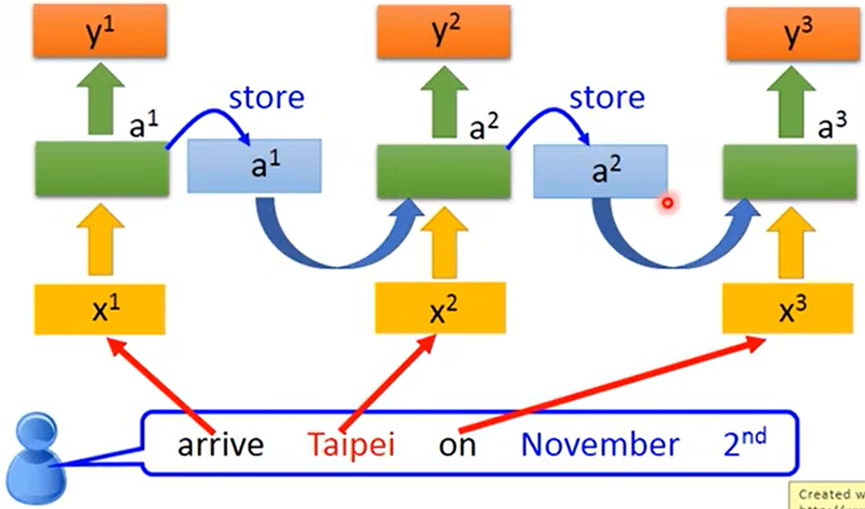
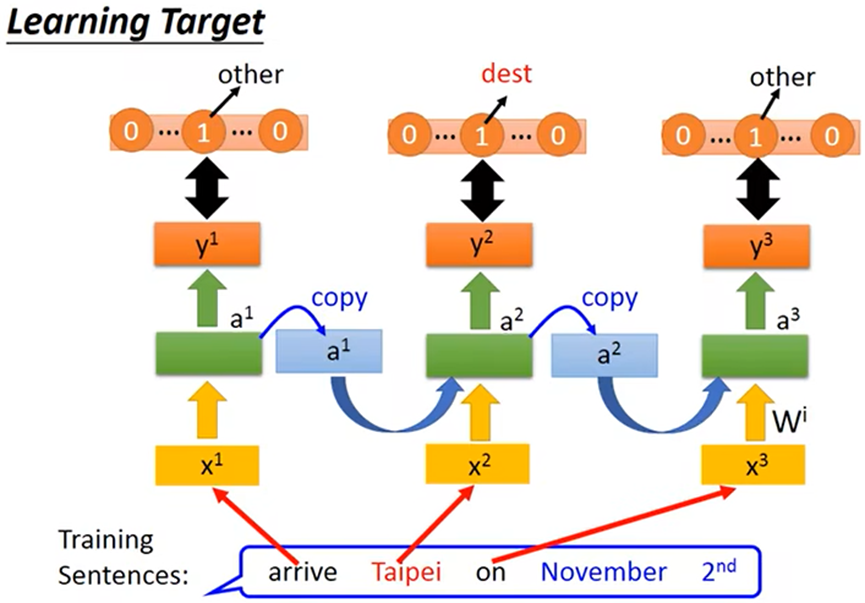
例:当分析一句话中各词汇是什么词性,往往需要结合前一个词汇一起分析,并且一句话中相同的词汇可能得出不同的结果;这时就需要RNN(循环神经网络)
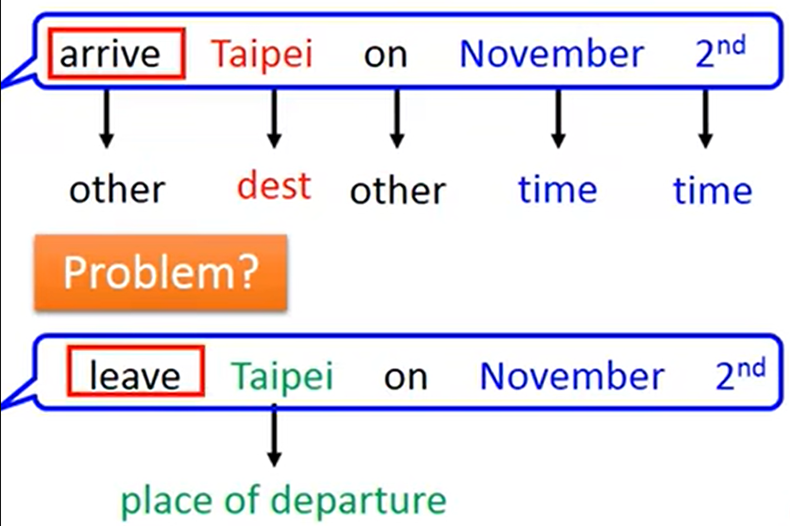
- RNN(循环神经网络):是有记忆力的,上图中同样是Taipei,要得出不同的结果就需要结合之前的一个词汇
- 刚开始给memory赋初始值,之后会把前一个词汇的输出存入memory,达到有记忆力的效果
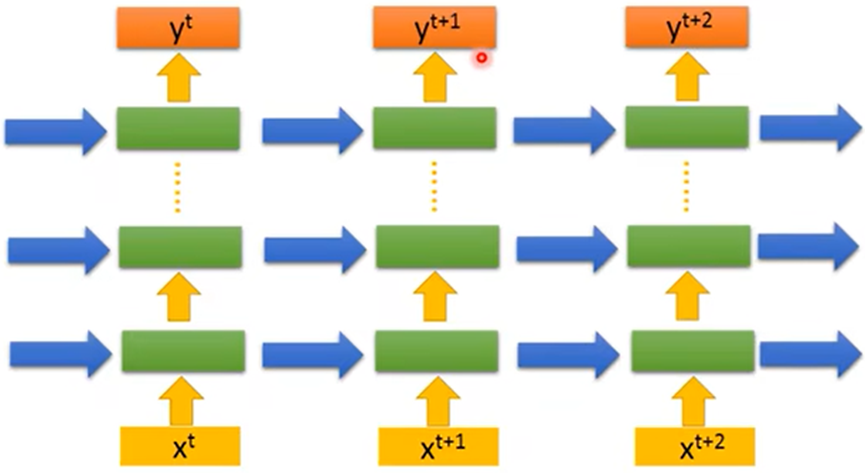
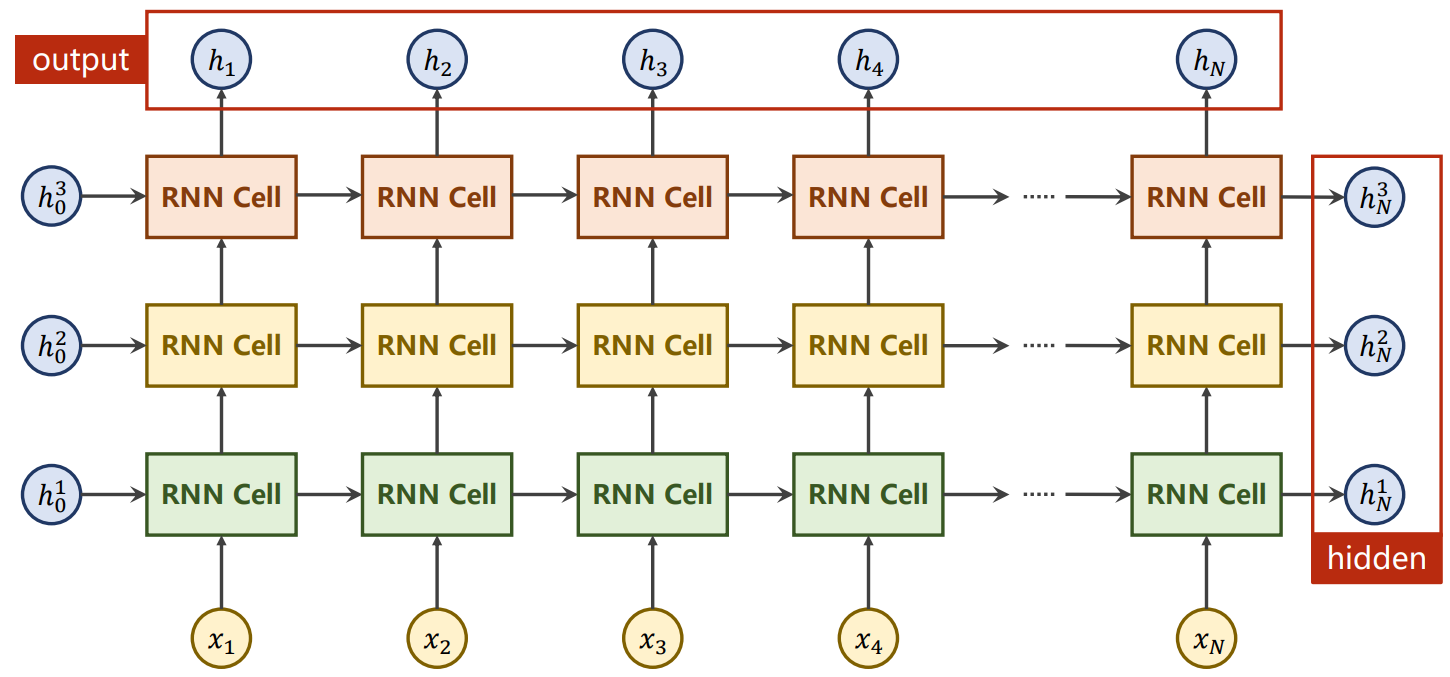
并且可以叠多层:
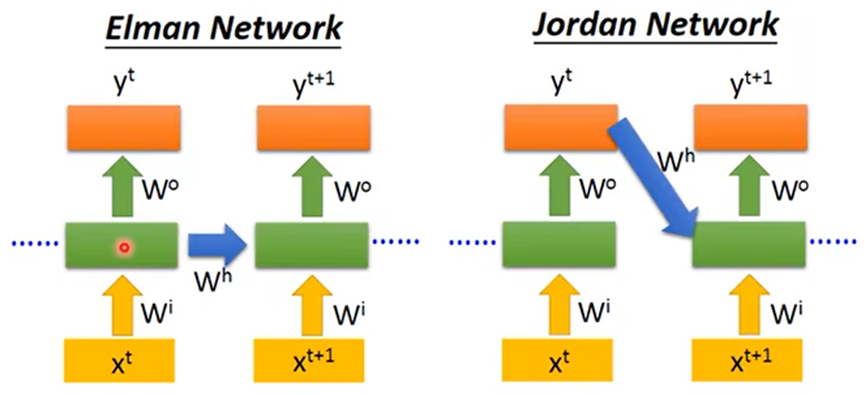
RNN由分为Elman和Jordan
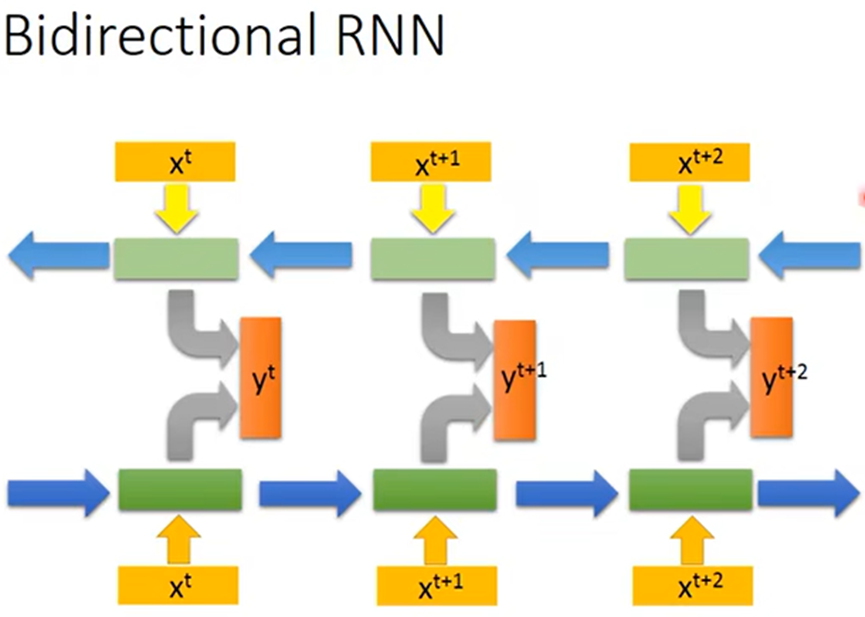
Bidirectional RNN(双向RNN)
RNN
RNN中的特征参数:
- num_layers:RNN中Cell的层数
- seq_Len:一个X样本中包含多少个x序列,也就是多少个时刻
- batch_Size:Batch块的大小,批处理同时计算多少个样本X
- input_Size:样本X的一个序列x维度
- hidden_Size:要Cell中要输出的h维度
- RNN内部的循环层是RNNCell
- RNNCell实例化时输入的参数为xt和ht的维度大小,即input_size和hidden_size
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
- 但调用RNNCell实例化对象时,传入的参数是xt和ht数据,返回ht+1,由于要用Batch同步计算,所以都是二维度;x(batch_size,input_size),h(batch_size,hidden_size)
- 使用RNNCell可以构建自定义的RNN循环方式,并且每一次循环的loss应该相加返回作为作为自定义RNN的loss
h=torch.zeros(batch_size,hidden_size) #h.shape=(batch_size,hidden_size) #X.shape=(seq_len,batch_size,input_size) #x.shape=(batch_size,input_size) for x in X: h=cell(x,h)
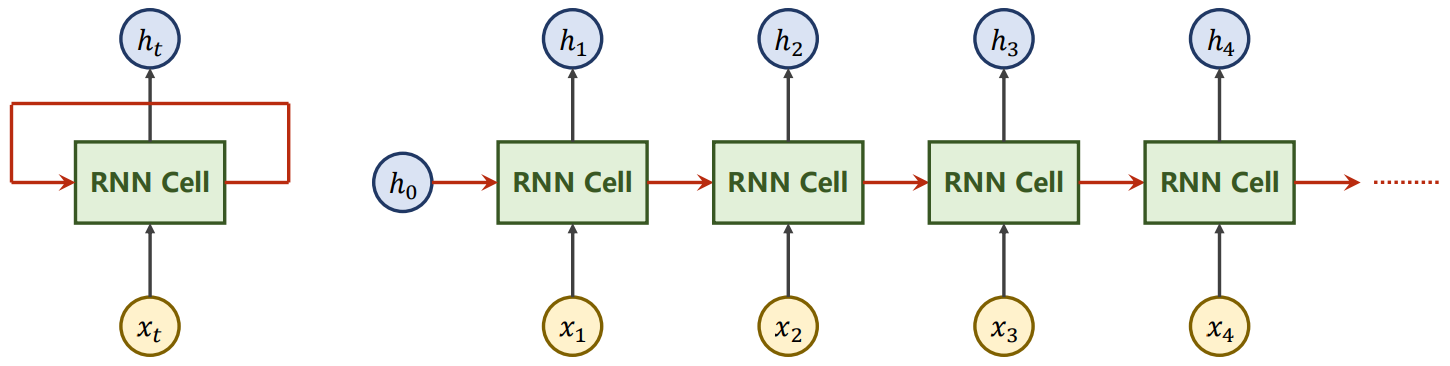
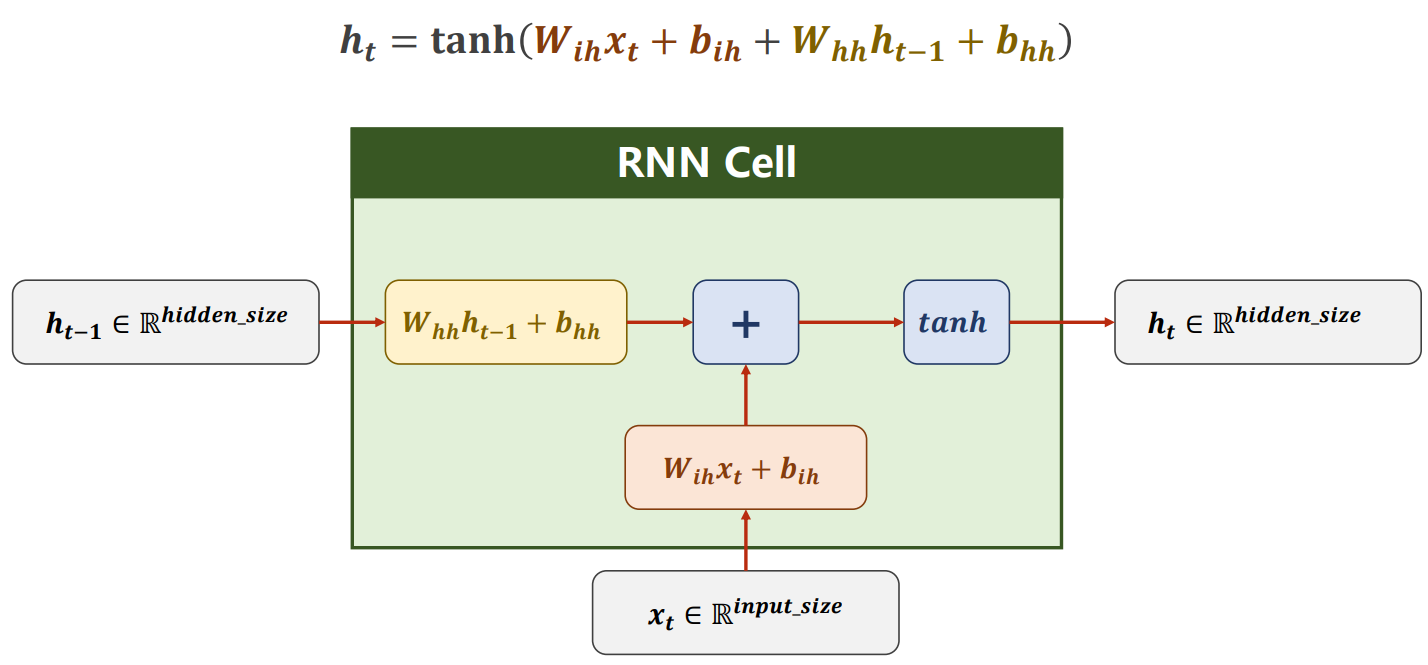
- RNN实例化时输入的参数为xt、ht的维度大小和内部Cell的层数num_layers,即input_size、hidden_size和num_layers
rnn=torch.RNN(input_size=input_size,hidden_size=hidden_size,num_lauers=num_layers)
- 也可以再加入batch_first、nonlinearity;用于标志batch_size是否作为第一维度,和指定非线性函数
rnn=torch.RNN(input_size=input_size,hidden_size=hidden_size,num_lauers=num_layers,batch_first=False,nonlinearity='tanh')
- 还可以设置bidirectional,设置其值1为单向,2为双向,双向循环神经网络ht又分为htf和htb
- 最后输出out为htf和htb拼接后的结果,hidden则是 [ htf,htb ]
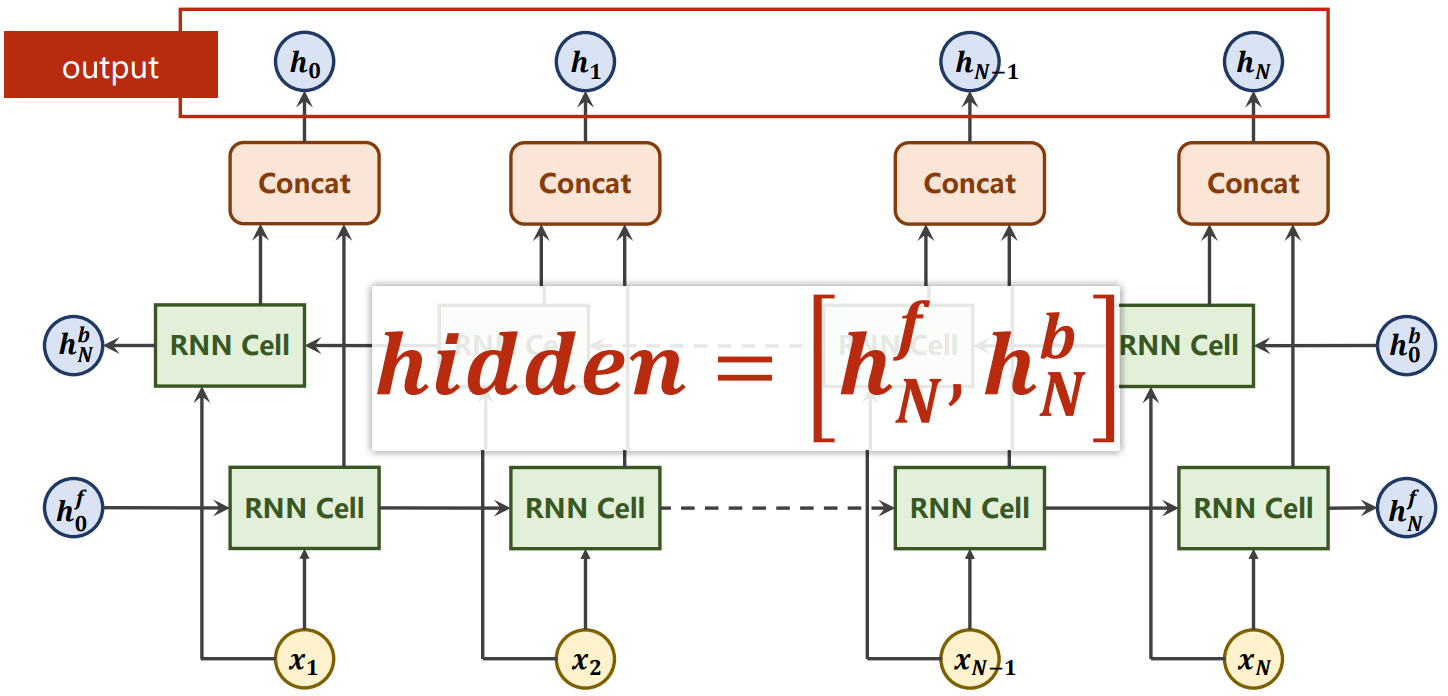
#构造 n_directions=2 rnn=torch.nn.RNN(input_size,hidden_size,layer_size,bidirectional=n_directions) #使用实例化对象 #X.shape=(seq_len,batch_size,input_size) #h0.shape=(layer_size*n_directions,batch_size,hidden_size) #out.shape=(seq_len,batch_size,hiddent_size*n_directions) #hn.shape=(layer_size*n_directions,batch_size,hidden_size) h0=torch.zeros(layer_size*n_directions,batch_size,hidden_size) out,hn=rnn(X,h0) #out中内部已经拼接,对hn拼接 #hn中数据:[lay1_hf,lay1_hb,lay2_hf,lay2_hb,...] # ayi_h:[batch1,batch2,batch3,...] #hn_cat.shape=(batch_size,hidden_size*n_directions) #hn_cat就是将最高层的layer中hf、hb拼接 if n_directions==2: hn_cat=torch.cat([hn[-1],hn[-2]],dim=1) else: hn_cat=hn[-1]
- 调用RNN实例化对象时,传入的参数是X和H0数据,返回output、hidden
h0=torch.zeros(num_layers,batch_size,hidden_size) #X.shape=(seq_len,batch_size,input_size) #h0.shape=(num_layers,batch_size,hidden_size) #out.shape=(seq_len,batch_size,hidden_size) #hn.shape=(num_layers,batch_size,hidden_size) #out和X的维度相似,只是最低维的x的维度通过RNN从input_size转换成了hidden_size #h0和hn的维度完全一样,因为cell循环中hn也是由h0转换而来 out,hn=rnn(X,h0)
- 由于输入的x类别较多,使整个模型需要输入的参数量过于庞大;例如:英语单词有数万种,x代表某个单词时候就需要数万维
- Embedding:为减少参数量,把x从高维度稀疏的样本转换成低纬度稠密的样本(降维)
RNN神经网络插入Embedding
Embedding参数构造函数的参数主要有num_embeddings、embedding_dim
- num_embedding:读入x向量维度数
- embedding_dim:转换后x'的维度,也是下一层RNN构造的 input_size
emb=nn.Enbedding(num_embedding=input_size,embedding_dim=embedding_dim)

调用Embedding实例化对象时,传入长整性数(代表所属类的序号),返回转换后的结果
#X.shape=(seq_len,batch_size) #x为一个长整性数值,所以X只有两维 #inputs.shape=(seq_len,batch_size,embedding_dim) inputs=emb(X)
- 先建立嵌入层(Embed)把读入向量变成稠密的表示,经过RNN,在加一个线性层用于把隐层输出维度转回成和分类数一致
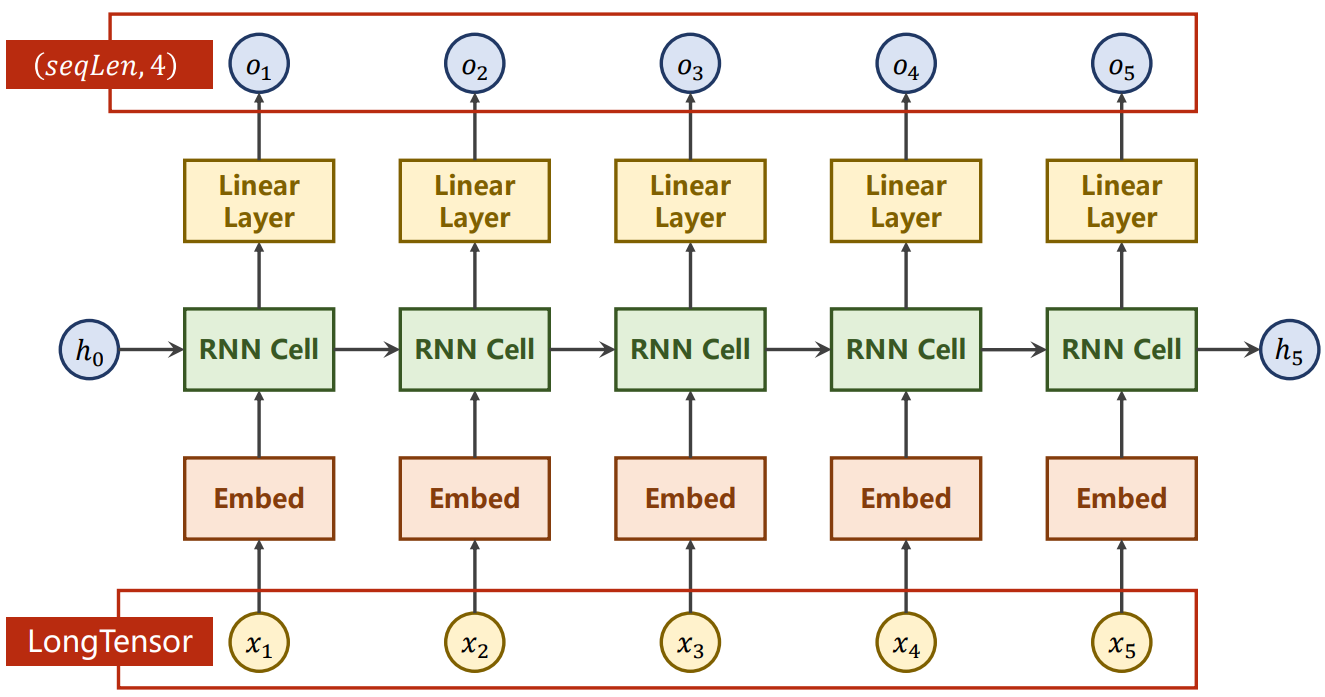
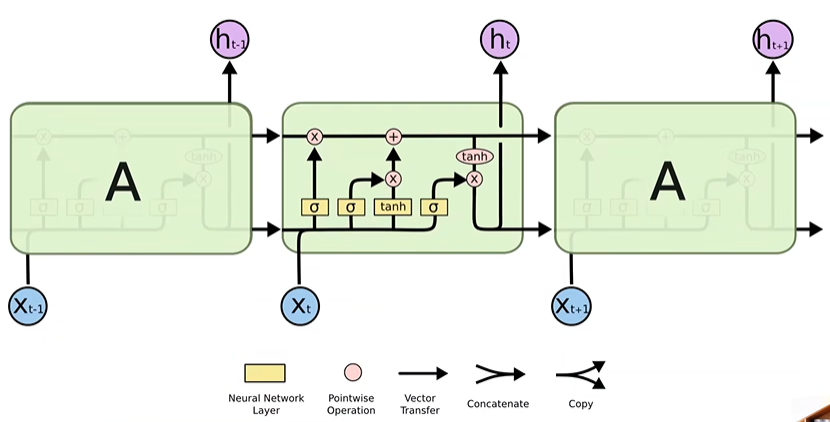
LSTM
- 学习能力强,但运算复杂,运算性能较低,时间复杂度较高
#构造 lstm=nn.LSTM(input_size,hidden_size,layer_size) #使用实例化对象 #X.shape=(seq_len,batch_size,input_size) #out.shape=(seq_len,batch_size,hidden_size) #h0.shape=c0.shape=hn.shape=cn.shape=(layer_size,batch_size,hidden_size) h0=torch.zeros(layer_size,batch_size,hidden_size) c0=torch.zeros(layer_size,batch_size,hidden_size) out,(hn,cn)=lstm(X,(hn,cn))
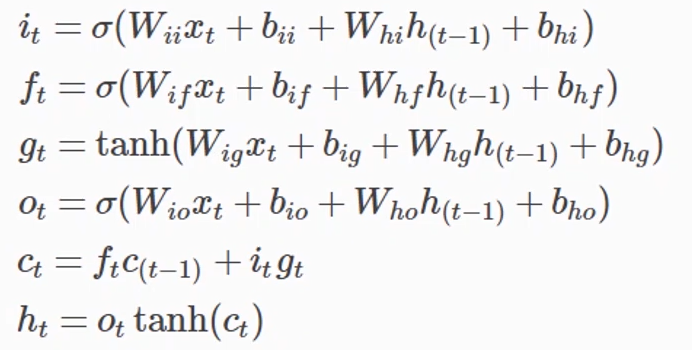

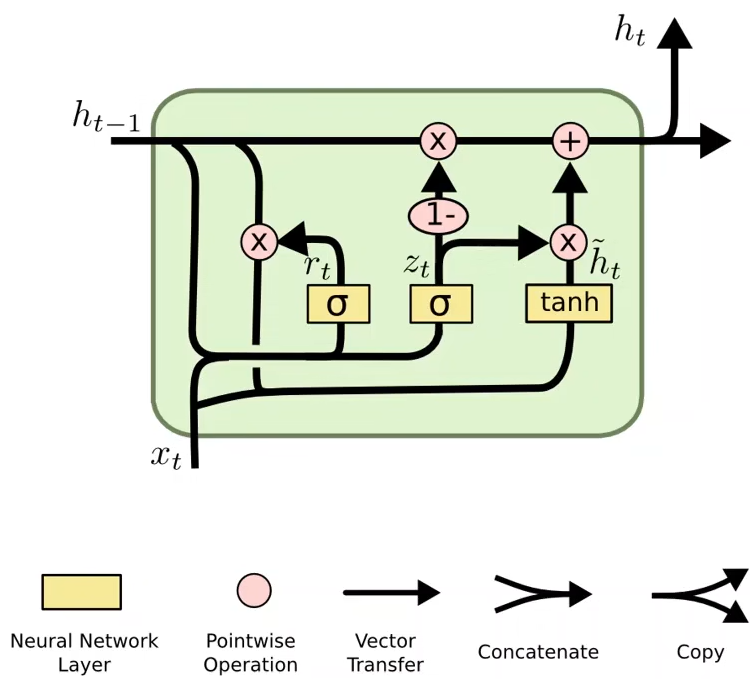
GRU
#构造 gru=nn.GRU(input_size,hidden_size,layer_size) #使用实例化对象 #X.shape=(seq_len,batch_size,input_size) #out.shape=(seq_len,batch_size,hidden_size) #h0.shape=hn.shape=(layer_size,batch_size,hidden_size) h0=torch.zeros(layer_size,batch_size,hidden_size) out,hn=gru(X,h0)
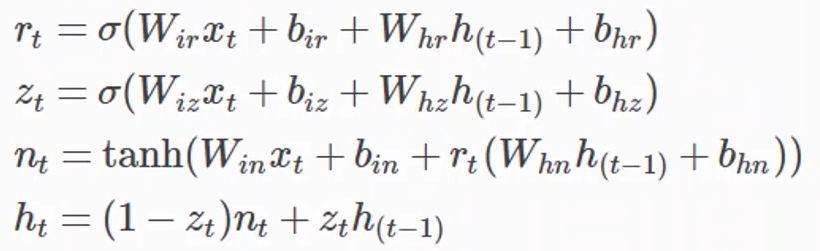
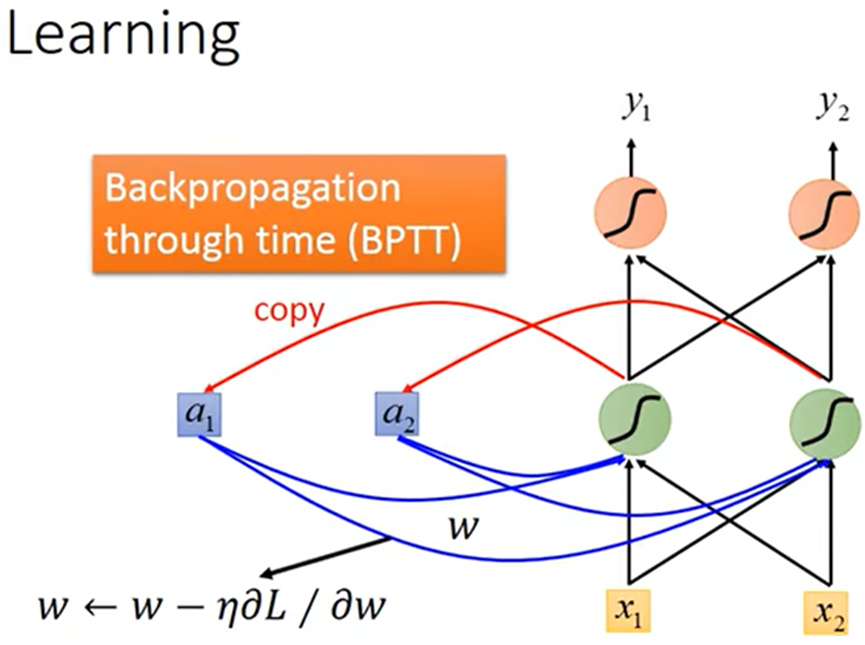
RNN的训练
- 计算L对w的偏微分;用Gradient Descent(梯度下降法)优化参数
Graph Neural Networks(图神经网络)
。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号