
Convolutional Neural Network(CNN卷积神经网络)
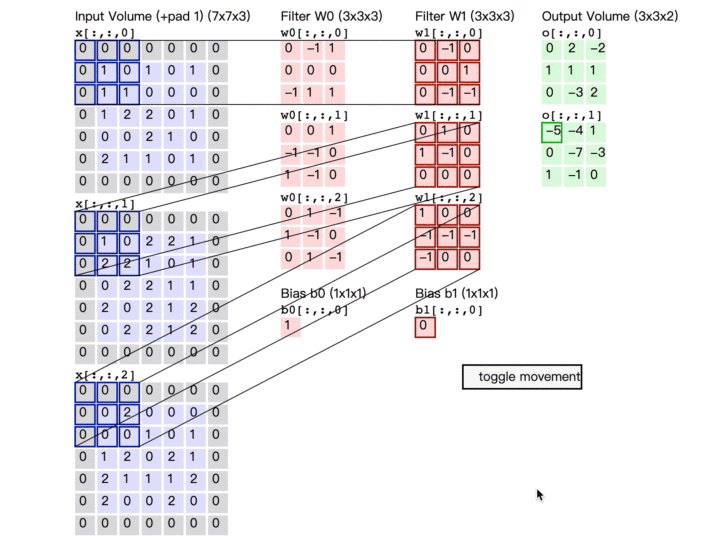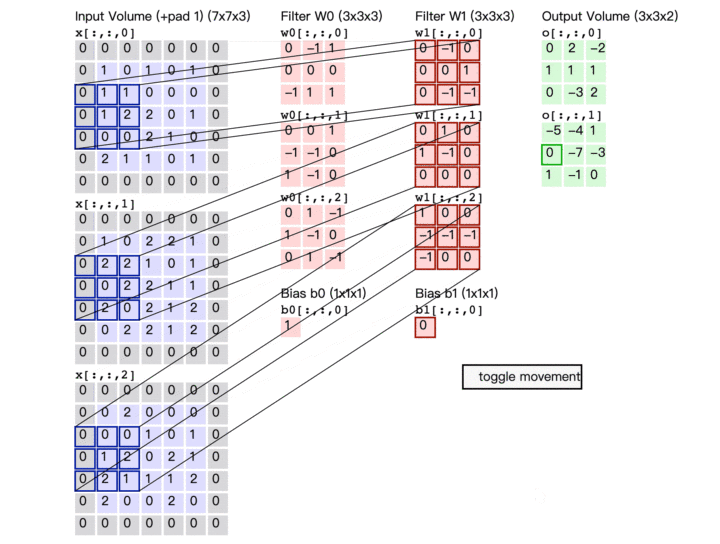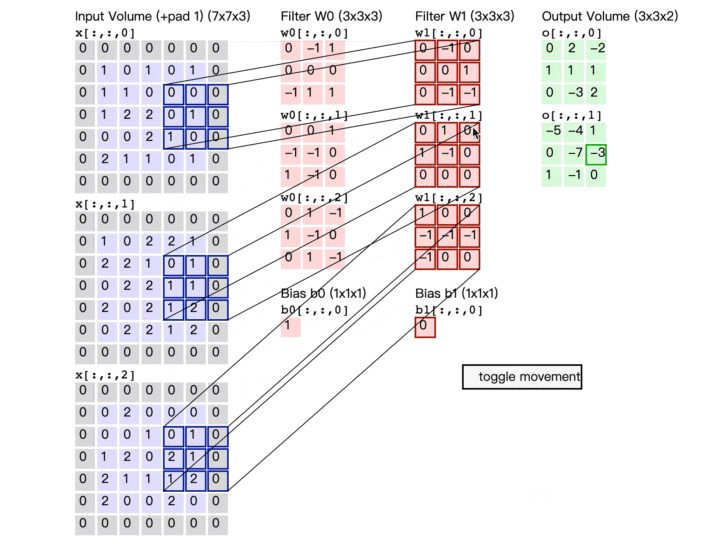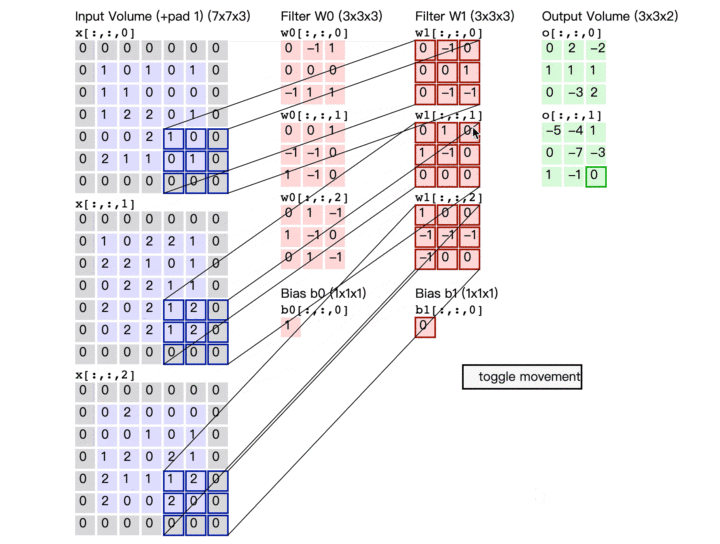
解释一
- 应用于Image classification(图像分类)
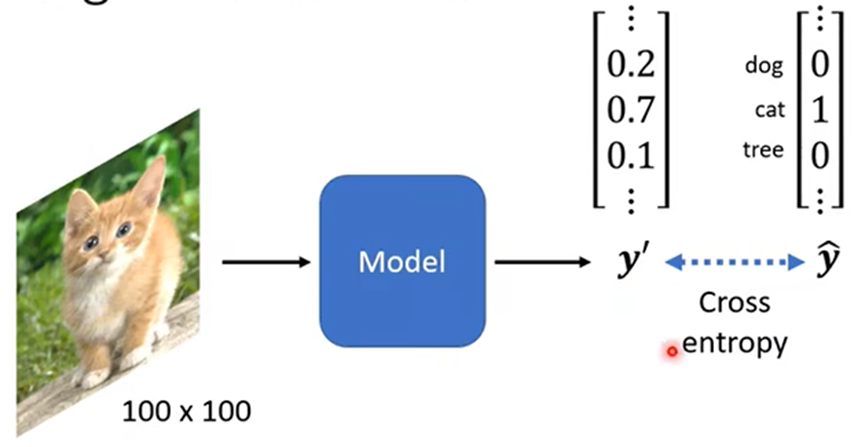
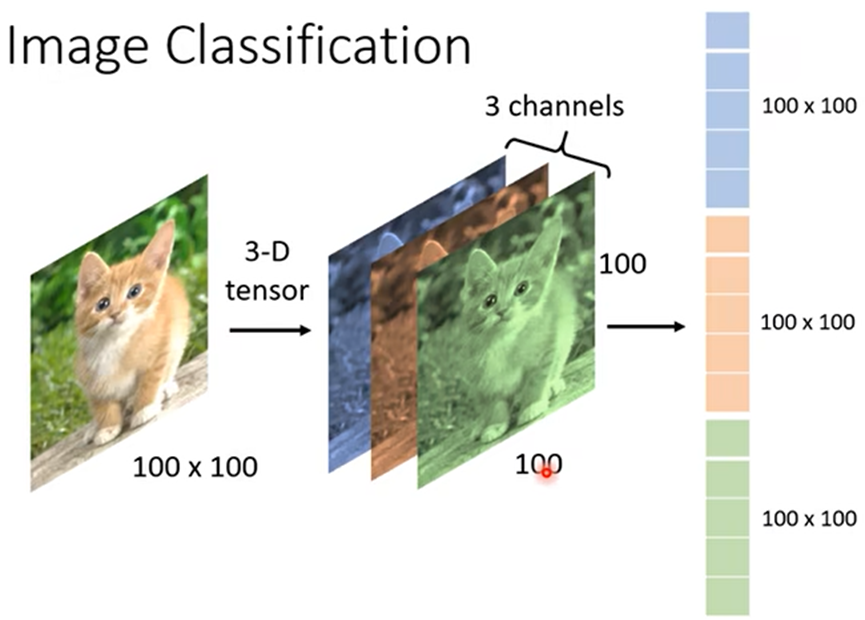
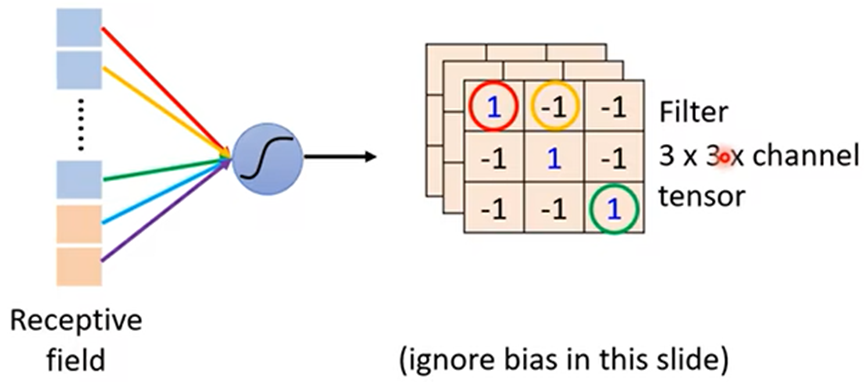
- 一张图片如何作为一个模型的输入:一张图片可以当成三维的Tensor(维度大于等于2的矩阵),三维分别代表图片:宽、高、channels(宽高代表像素,channels代表RGB三色)
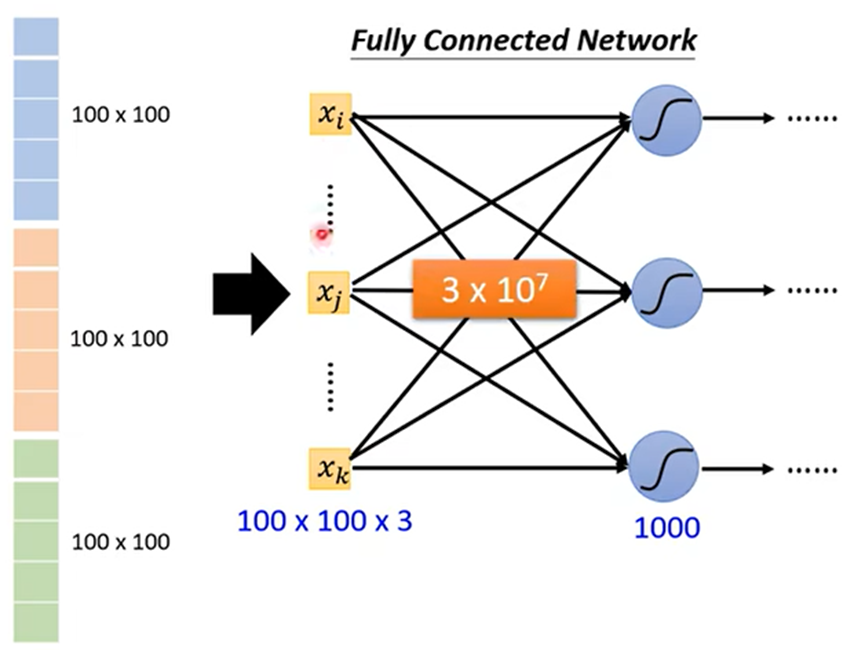
- 参数过多,模型弹性越大,越容易过度拟合
减少参数
观察一:由于可以识别一些关键特征得到结果,所以可对特征值做简化
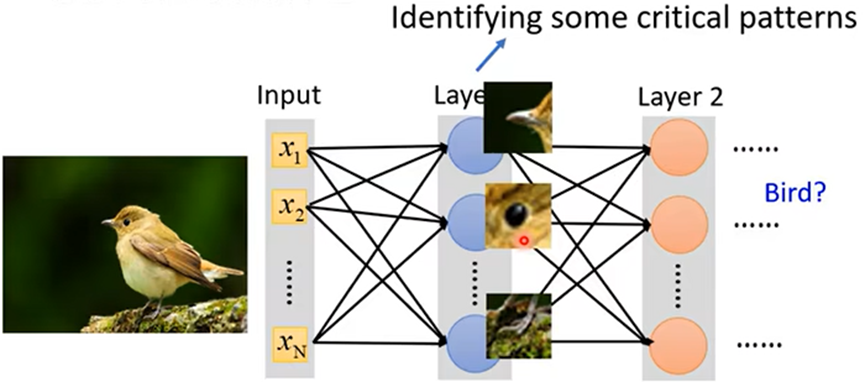
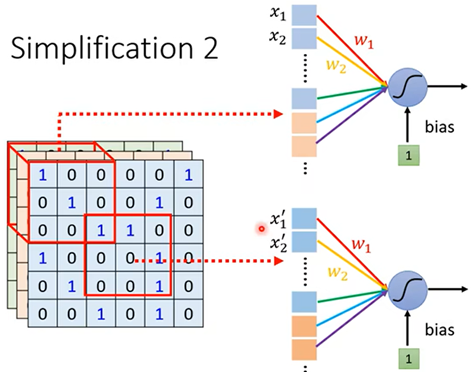
简化一:划分接受域(Receptive Field),将每个接受域中特征值做神经网络得到输出作为下一层神经网络的输入;
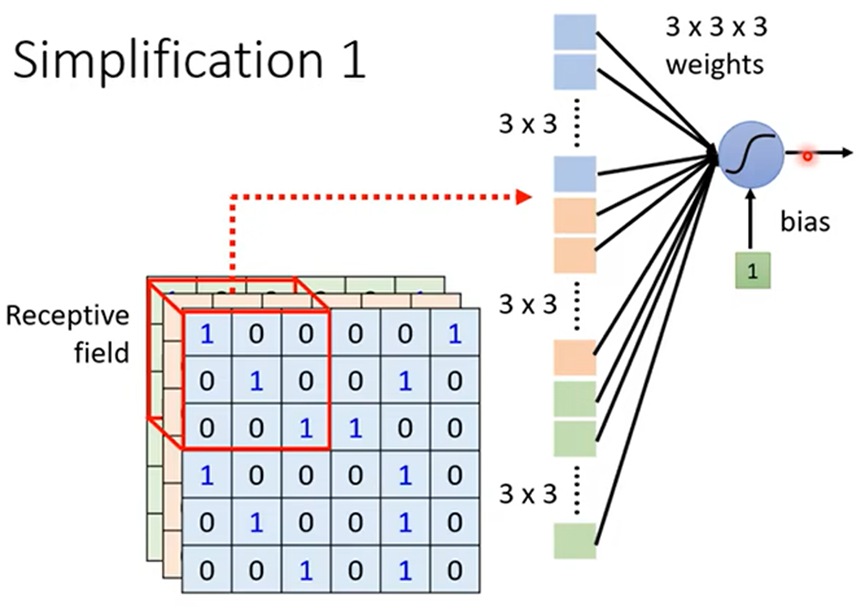
并且,接受域之间可以重叠,甚至同一个接受域可以为两个神经网络的输入
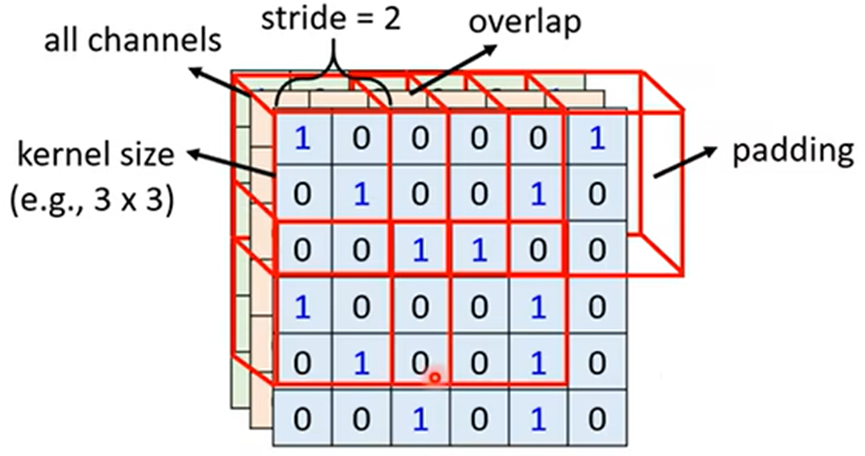
设置接受域的内核大小(kernel size)为3*3,步长(stride)为2,就可出现重叠(overlap),当超出边界时可以填充值(padding)
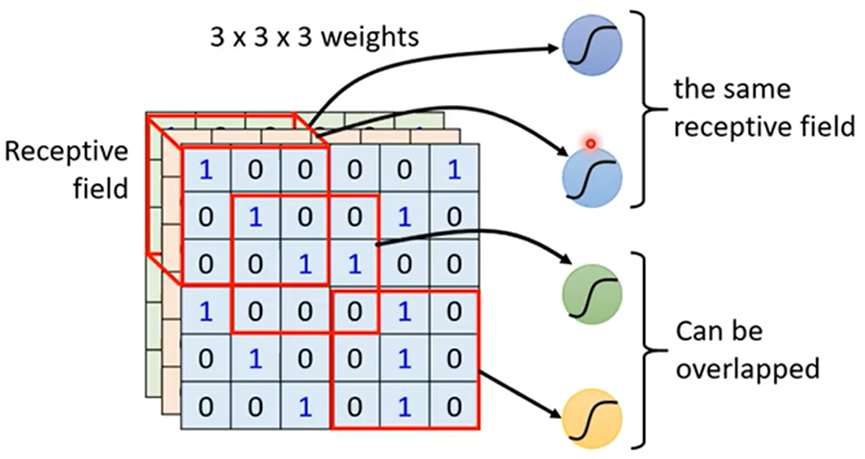
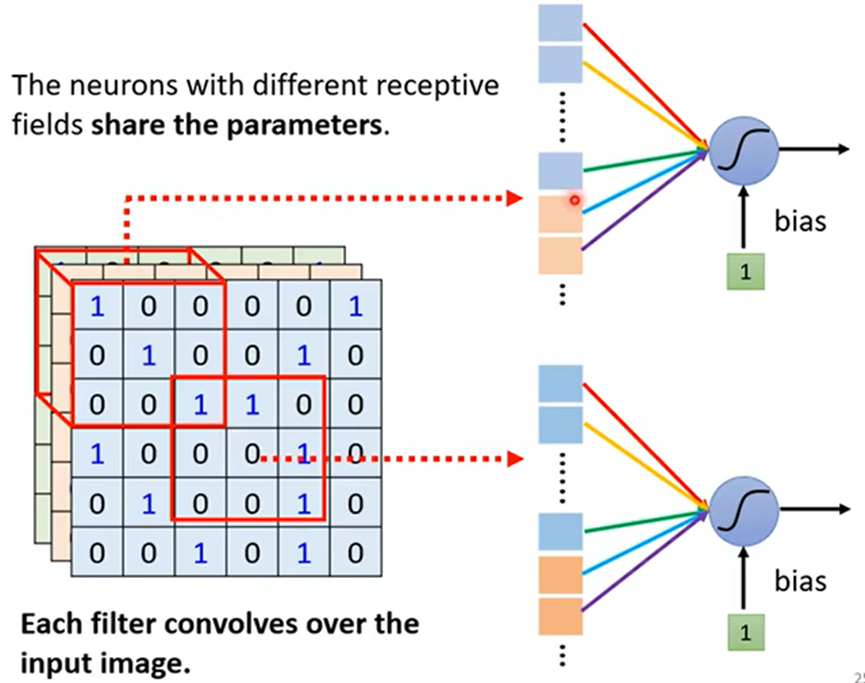
观察二:关键模式可能出现在不同位置,由于每个区域都被某个接受域(receptive field)包含
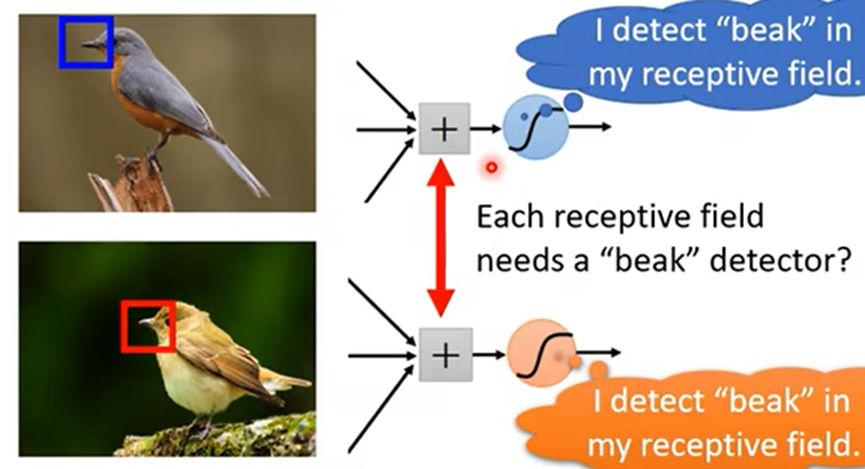
简化二:让不同接收域的神经网络共享参数(parameter sharing)
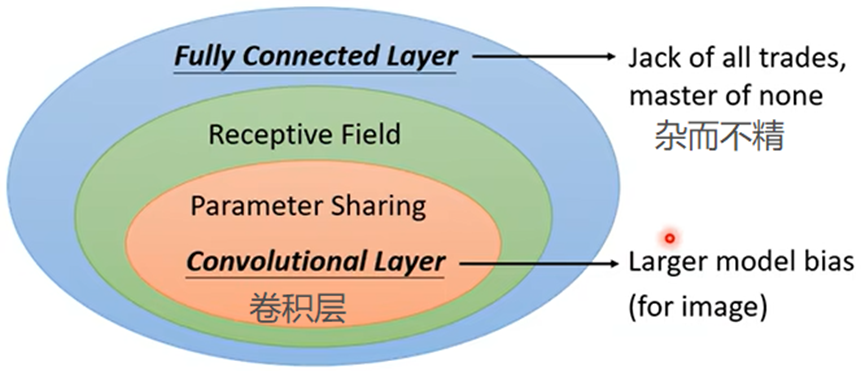
卷积层的优点:
解释二
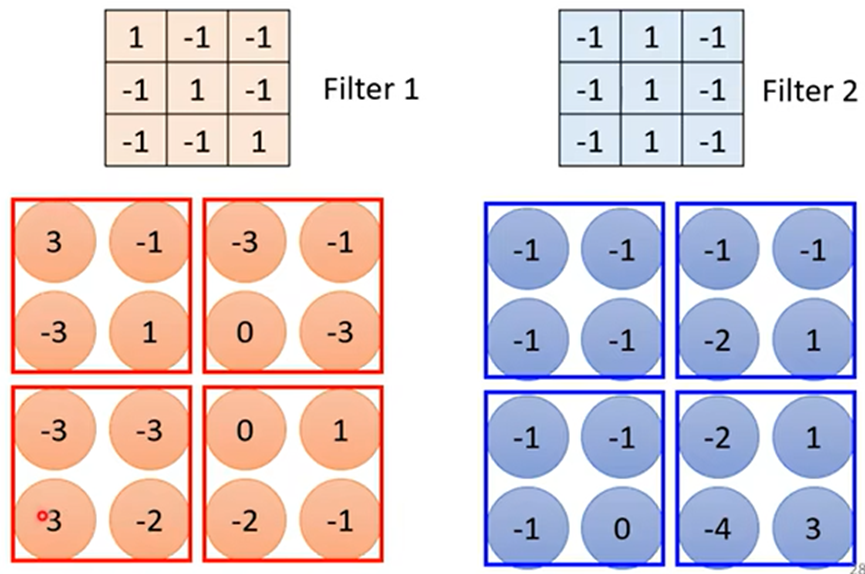
- 卷积层:就是里面有很多filter(过滤器)
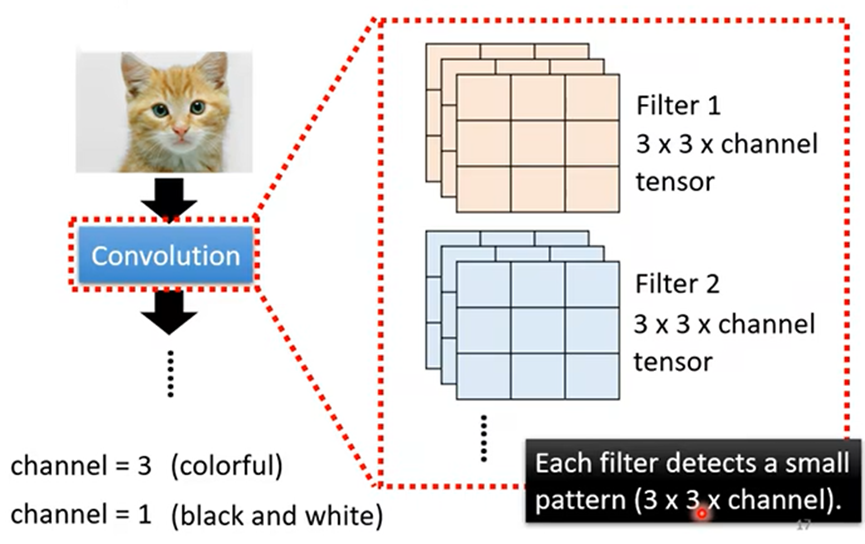
例如:6*6的黑白图片被两个Filter(大小:3*3,步长:1)过滤后得到有两层数据的feature map(特征映射)
此时的feature map(特征映射)可以看做一张新的图片,此图片的channel(通道)不是RGB,而channel=2,每个channel就对应一个Filter

- Convolutional Layer(卷积层)可以叠多层,并且这层卷积层的Filter的个数应该等于上一层图片的channel;
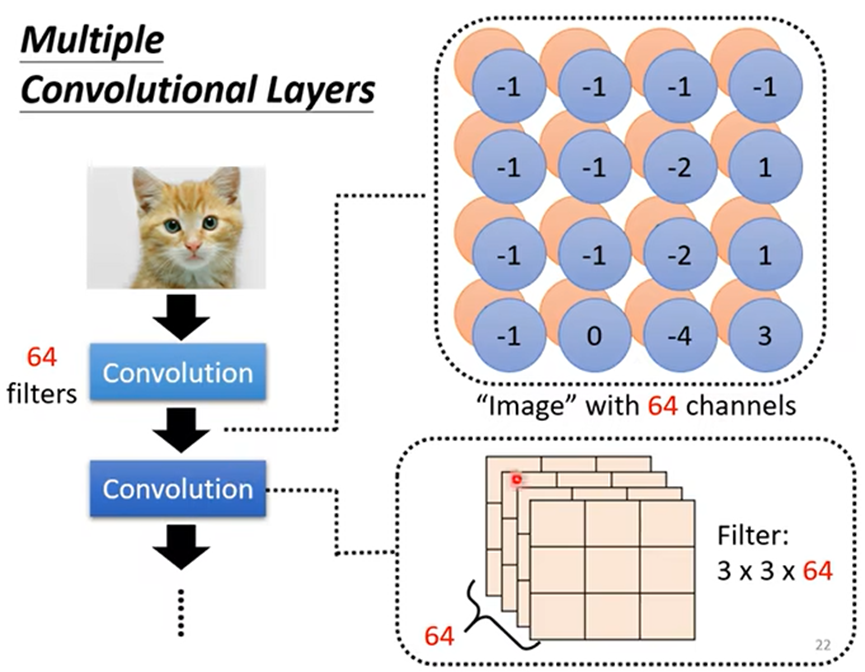
结:解释一中的Neural(神经网络)会共用参数,对应解释二中就是Filter(过滤器)
不同的Neural共享参数,对应不同的接受域,共享参数的意思也就是一个Filter扫过一张图片的过程,这个过程就叫Convolutional(卷积)
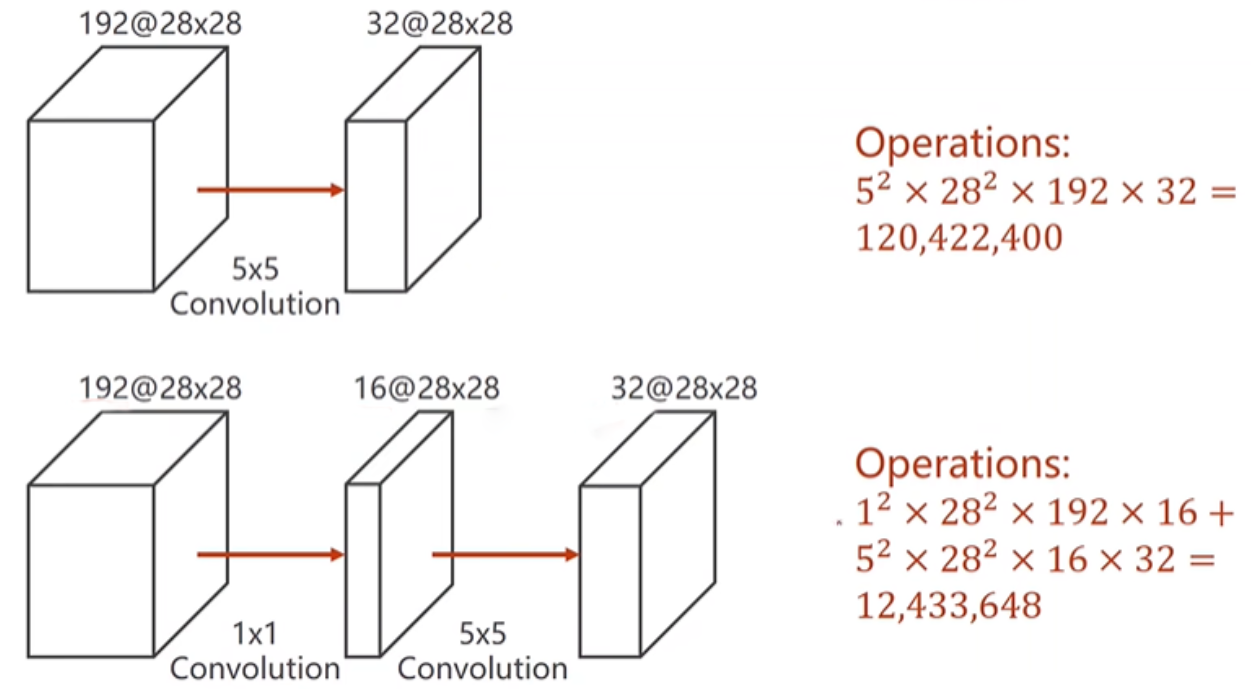
卷积中降低计算量
- 卷积中可穿插1*1的Filter减少输入的channel的数量,从而降低卷积的计算量
- 1*1的Filter还可以综合同一位置不同channel的数据
Pooling(池化)
- 把一张大的图片子采样缩小,不影响图片的内容

每个Filter都产生一堆数据,做Pooling时就是将这些数据几个分成一组,每组中选一个代表来简化这组数据
Max pooling:
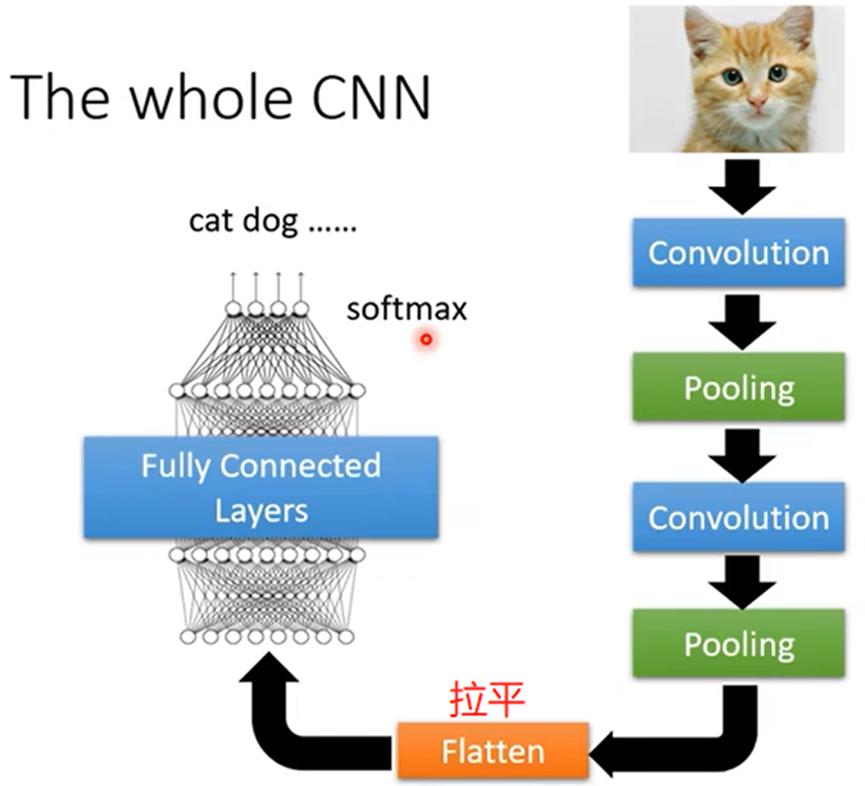
图像辨识的过程
- 经过多次处理的图片,Flatten(拉平)之后变成向量,作为特征值传入全连接的神经网络,得到结果,可再次softmax得出结果
CNN还适合做围棋,做分类预测下一步落子位置在哪里最好
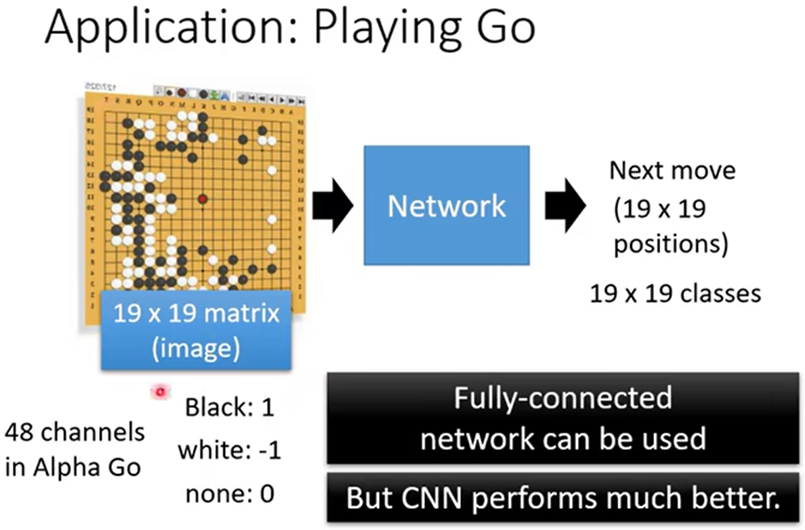
围棋和影象的共同点
- 都有很多重要的pattern(模式、特征),只需要看小范围就可以
- 相同的pattern(模式)可出现在不同的区域
注意:CNN不能处理影像放大、缩小或者旋转的情况,spatial transformer layer(空间变压器层)可以
spatial transformer Layer
- 对图片数据做旋转缩放的方法:变化后数据的每个值都由原数据的全部值通过计算得出
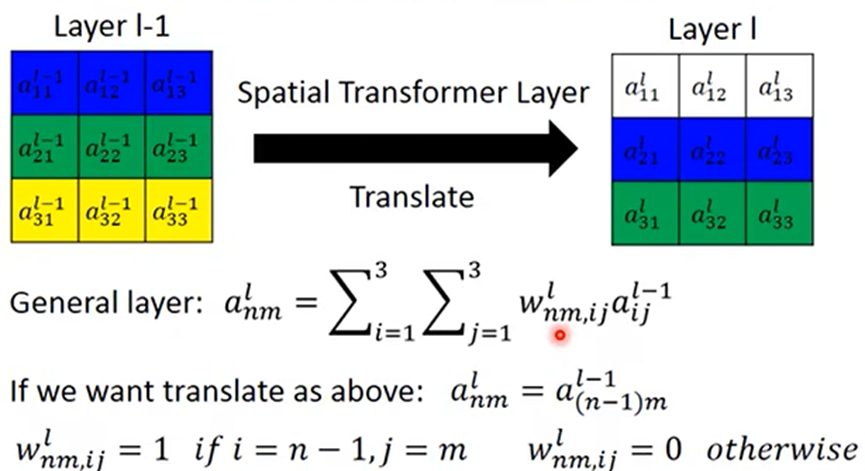
- 转化就是将图片中像素值改变位置
例如:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号