
Backpropagation(反向传播)
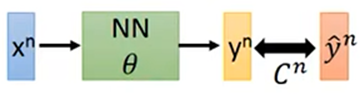
Cn为计算得出值与实际值的差距
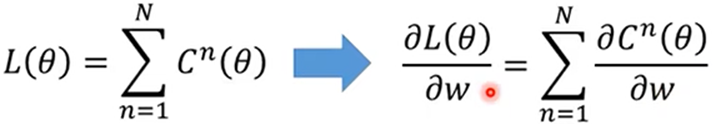
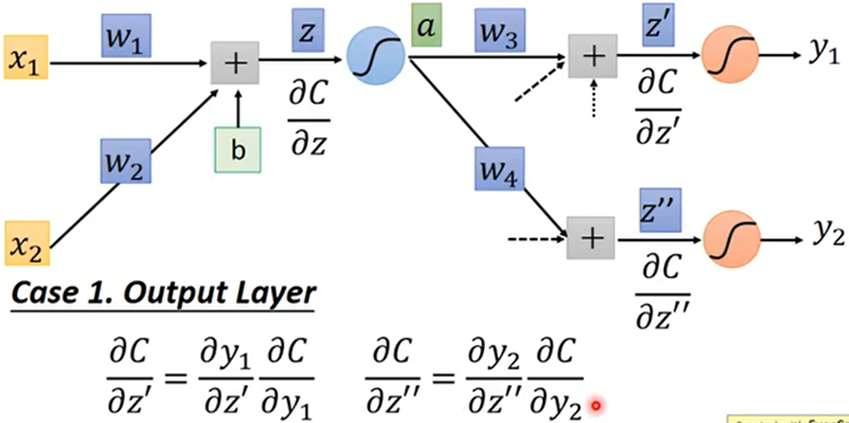
如何算出Cn对z的微分:由微分形式的不变性得,Z’为a的线性函数,可以得出Z’对a微分为w3
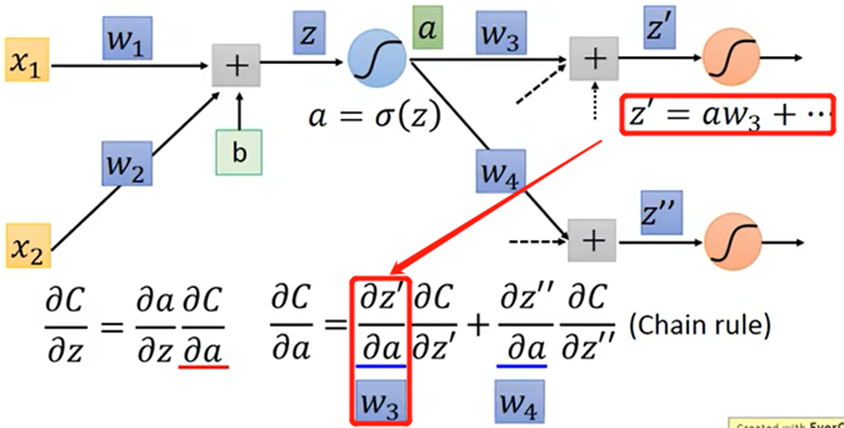
由于C(Z’,Z’’,…)是多元函数,链式求导法则得:
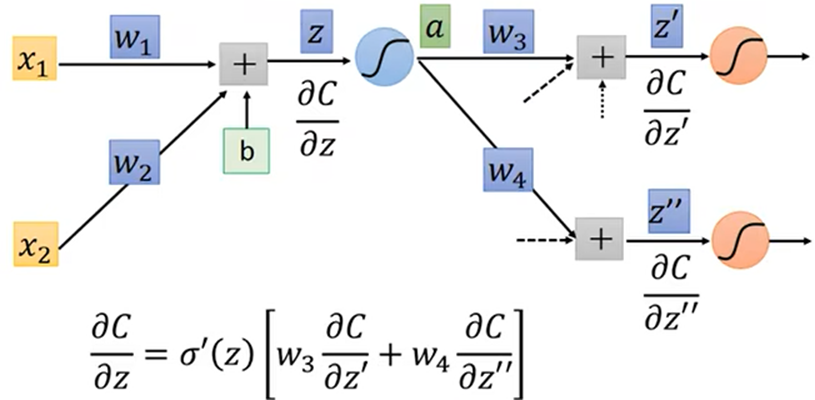
由反向计算,从右向左表示为:
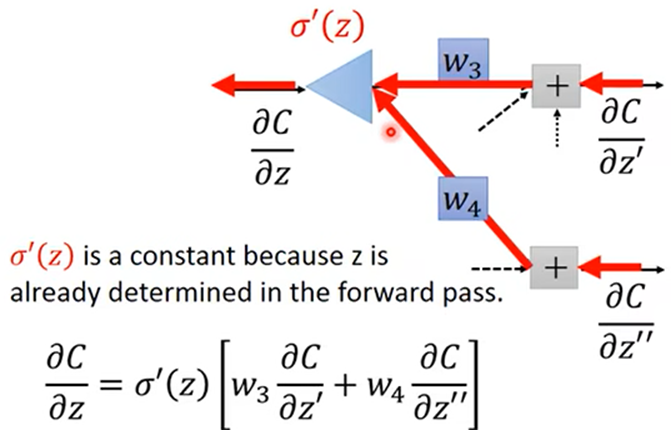
计算微分时就从最右侧输出层反向向前求微分,每一层每个神经元求微分函数Z’,Z’’,,…加和
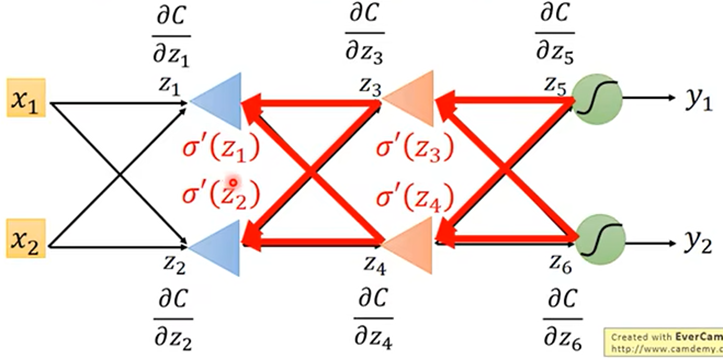
多层神经网络,嵌套计算:
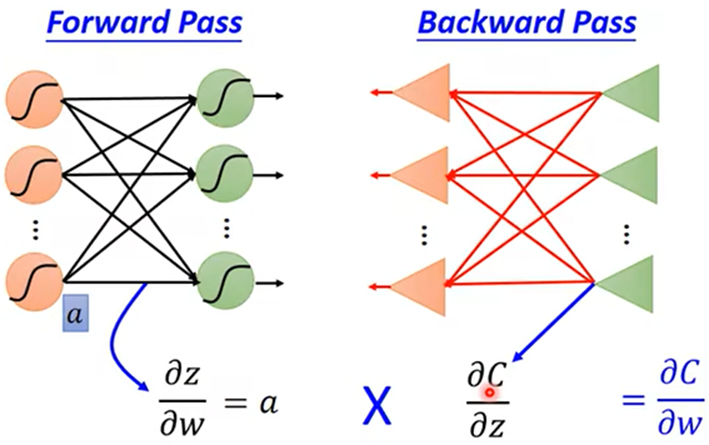
总结得出C对参数w的微分:
Model Selection(模型的选择)
- 不同的模型在训练和测试得出的数据有好有坏,复杂的模型包含简单的模型
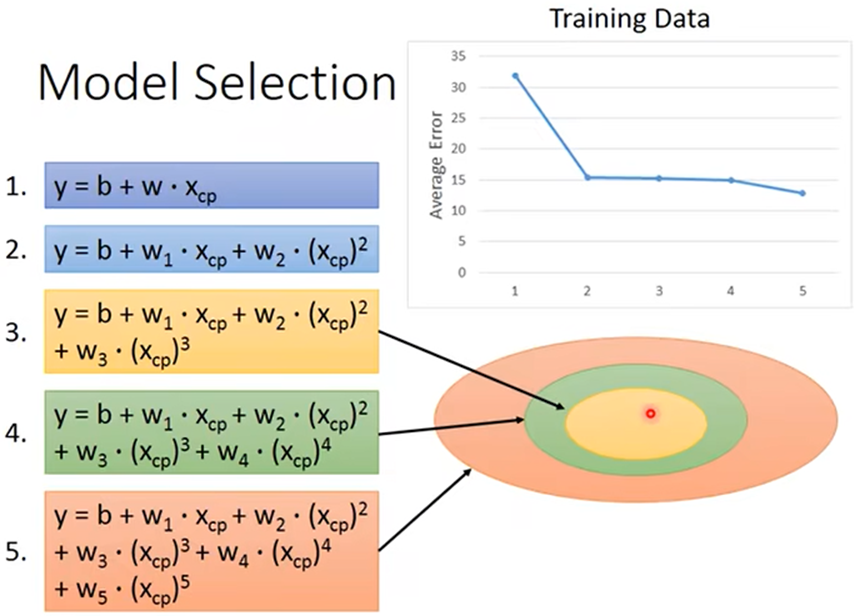
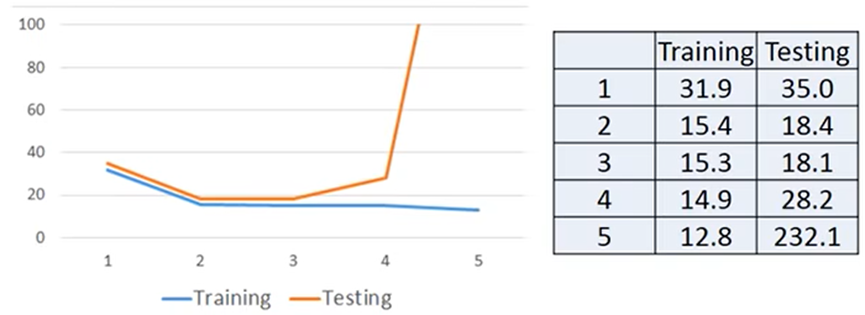
所以复杂的模型在训练中一定可以得到更好的数据,但测试中不一定能得到好的测试结果; 这就是overfitting(过度拟合):
例如,数据来源于不同的种类,不同类的数据就可能有不同的函数
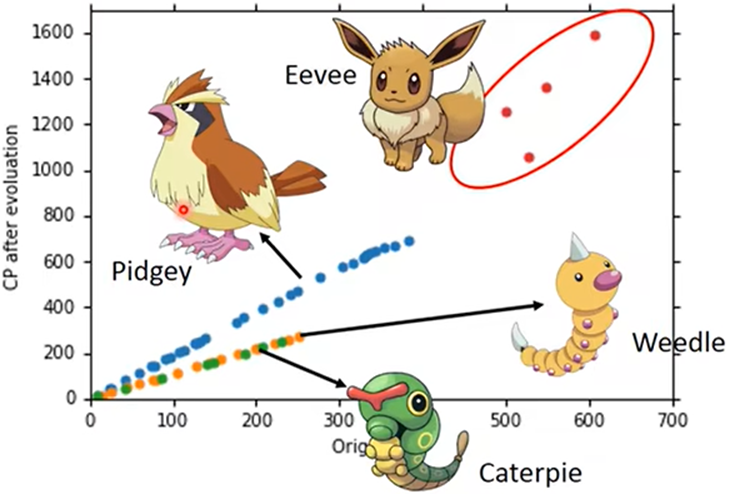
所以可以对不用种类设计不同的模型:
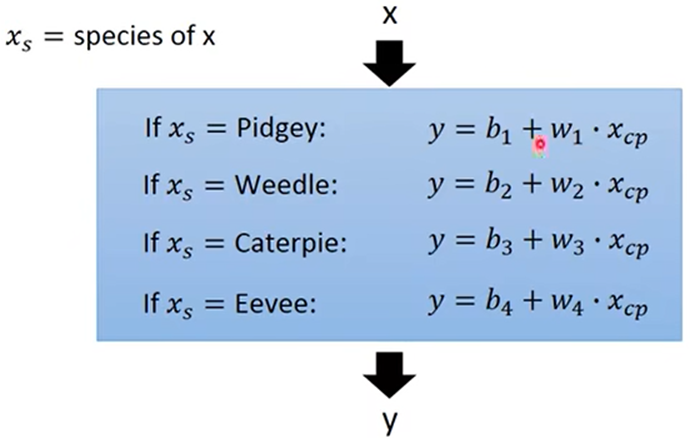
这种情况可以将不同的模型加和,根据种类值来确定用哪个模型, 这就是Linear Model(线性模型):
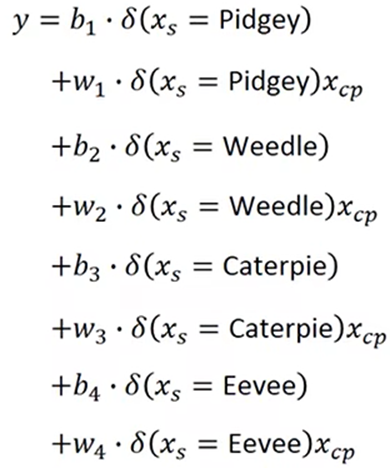
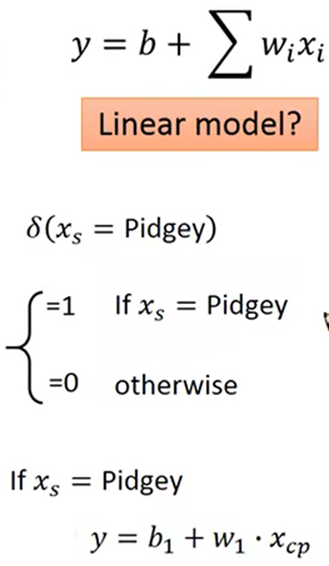
Regularization (正则化)
- 由于训练模型的数据可能有一些杂值,所以训练出的模型会受其不同程度的印象
- 一定程度内,越光滑的函数受杂值的影响也越小,为找到该模型中光滑度不同的函数,便可以对每个部分进行正则化
- 向模型中加入更多可能影响结果的值来优化模型,但进一步加入更多的特征值,也可能导致过度拟合
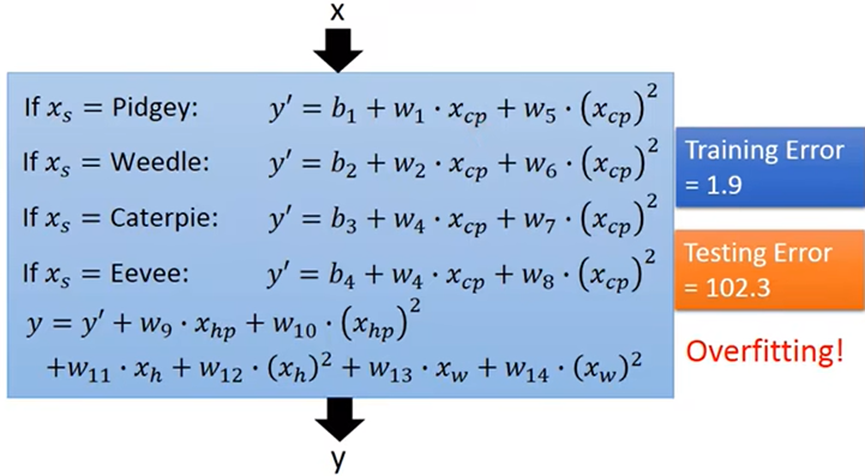
- 正则化的目的:检验重新设计模型后,对模型是好还是坏(评判不同模型的好坏)
- 正则化就是对损失函数再加一项:λ∑(wi)²,λ为手调的一个常数,wi决定模型的平滑度
当wi越小时,损失函数值越小,这样得出模型的函数越平滑(对输入值敏感度越低,受杂值的干扰也越小)
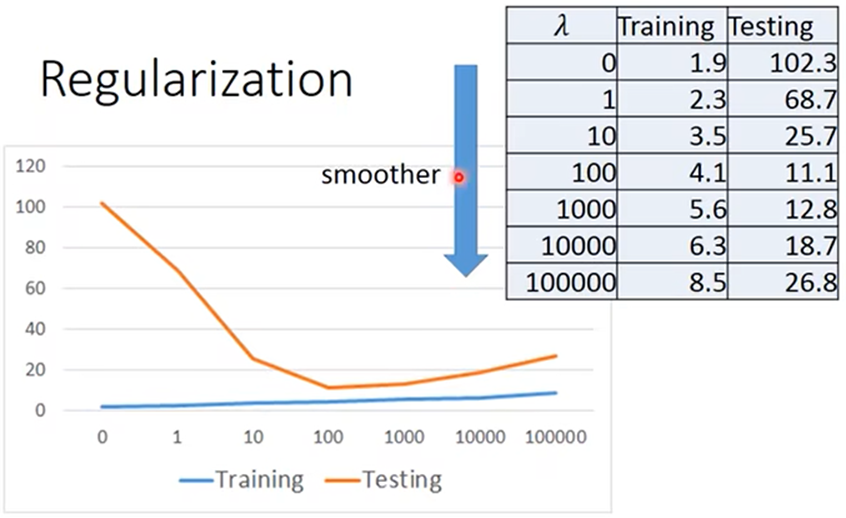
注:1.手调的λ越大时,最后找到该模型的函数就越平滑(当λ过大时,得到模型的函数就成了直线,得出的结果也就没有意义)
2.训练中得到的数据越差时,在测试中得到的数据却不一定差,所以得到λ=100时候,找到该模型的函数测试数据最好
3.手调不同的λ值时,模型没有改变,但可以找到该模型中光滑度不同的函数,这些函数的测试数据的效果也不同;因此可以找到某模型中最好的函数,也就可以评判不同的模型的好坏程度
Regression(回归)
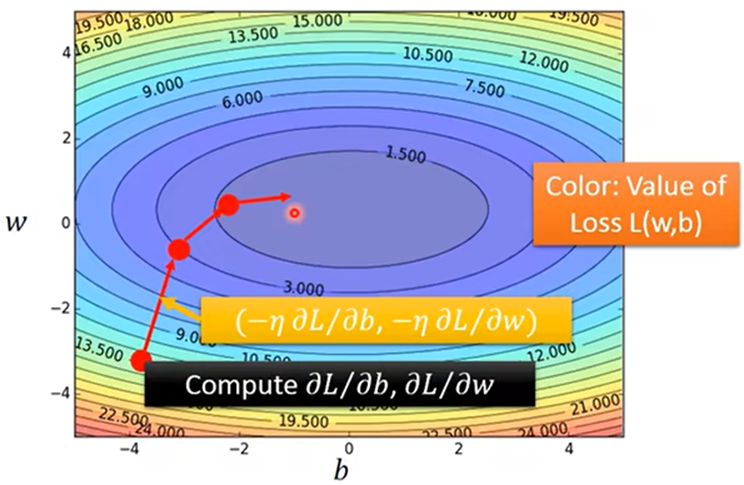
- Gradient Descent(梯度下降法):通过梯度*η改进参数,得到w*,b*

改进参数的方向为Loss函数等高线图该点处法线方向
- 由于该损失函数有local optimal(局部最优解),所以给的w0、b0不同,可能得出不同的结果:

Linear Regression(线性回归)
- Loss function(损失函数) L是convex(凸,没有局部最优解),不管给出的w0,b0为何值,都得出唯一的结果:
Classification (分类)
线性回归
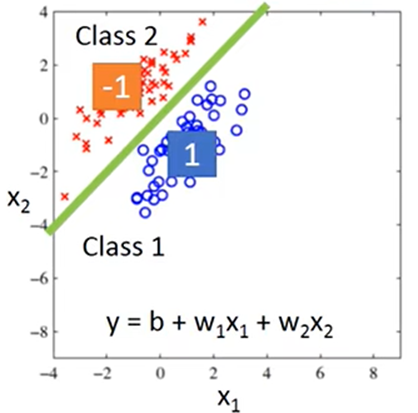
- 为每个类划分不同的结果域,把特征值代入函数,得出的结果属于哪个域,则属于哪个类
例如:带入特征值得出函数的结果大于0,则归为第1类;小于0,则归为第2类
两个类别中数据都相近时可得到不错的结果:
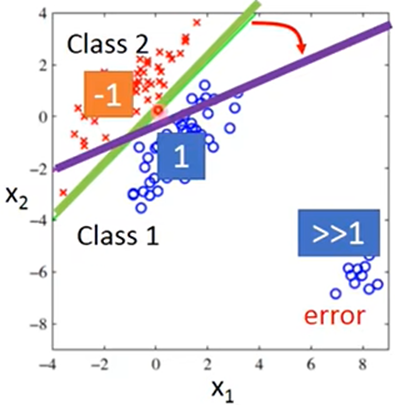
当某一类有一些差别较大的特征值(杂值),则会在模型中找到的函数会受其影响,分类效果较差:
这也是二元分类的理想选择:
- 模型的方法f(x)中,内接一个方法g(x),当g(x)得出结果>0,则f(x)输出第一类,否则输出第二类.
损失函数设为分类错误的次数,但该损失函数不能求导

Logistic Regression (逻辑回归)
- 从概率的方面解决:用贝叶斯概率分析,出自某类别的概率
- 模型:计算每个类别出现待测个体特征值的概率,最大概率的类型就是输出的结果
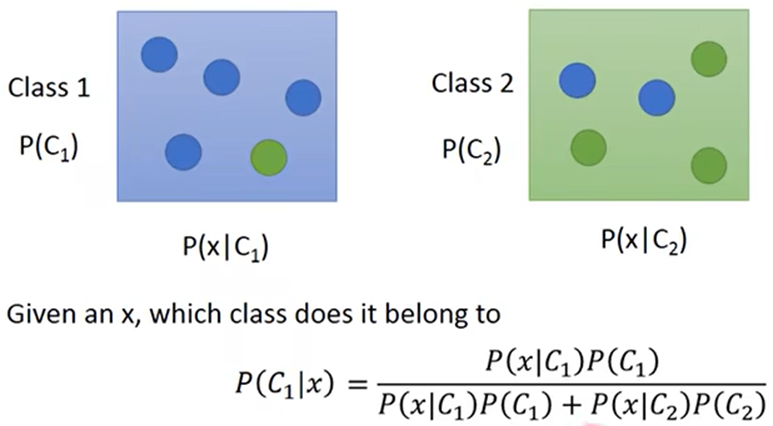
类别为C1、C2,P(x|C1)为C1中产生x数据的概率,通过贝叶斯公式即可求出x这个数据是出自C1、C2类的概率
对概率函数进行变换:

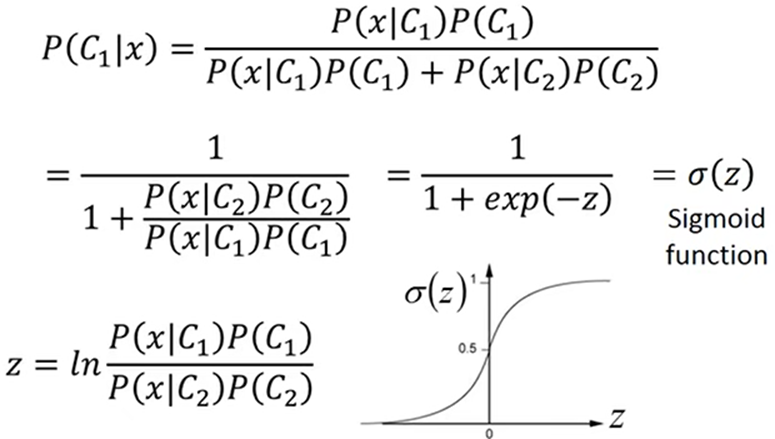
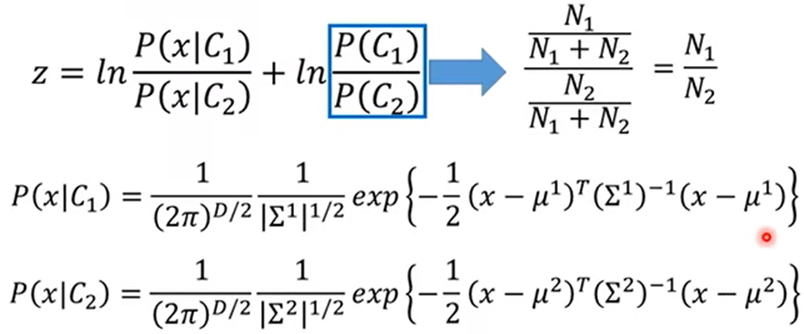
由上式化简得:

由此得出概率可以用线性模型可以表示
由于用概率的方法解决分类问题中,逻辑回归就是使P(Ci|x)为:
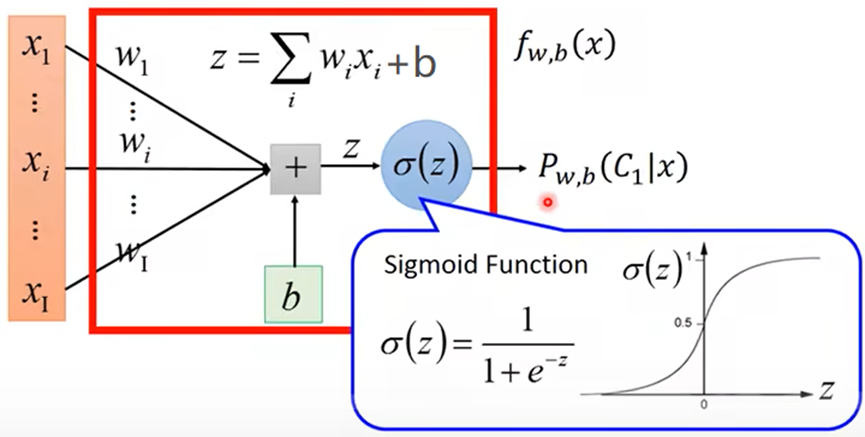
所以设概率模型为:
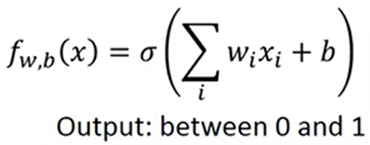
训练数据为:
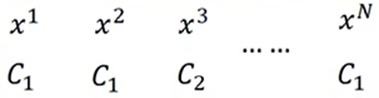
利用训练数据求概率模型中w、b的最大似然估计值就是w*、b*
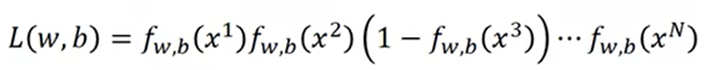
将类型投影到具体数值上:
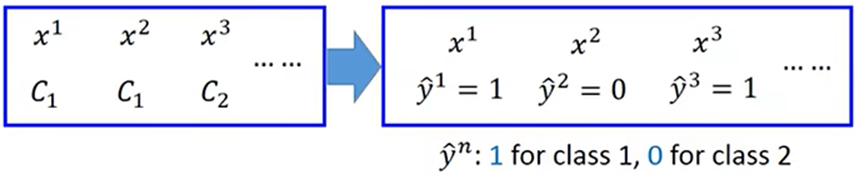
所以将类型的数值代入可得:
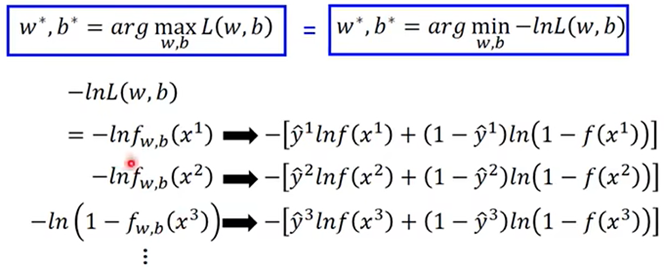
对L求导:
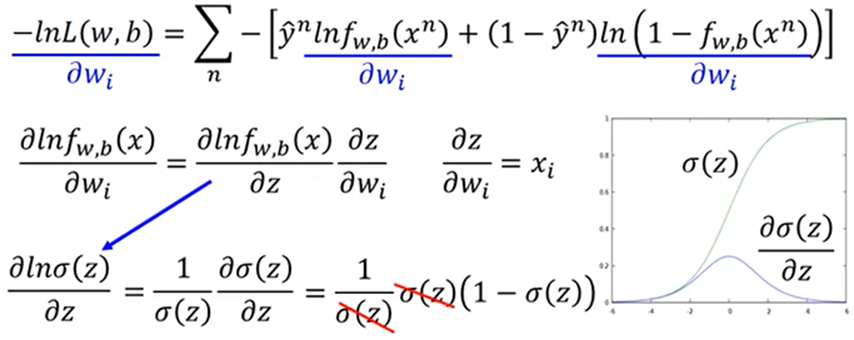
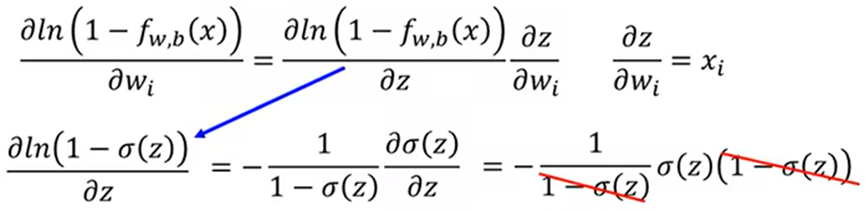
综上得:
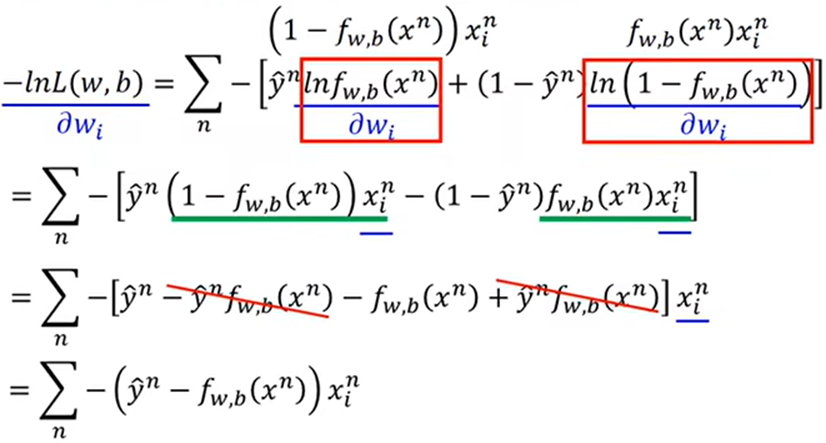
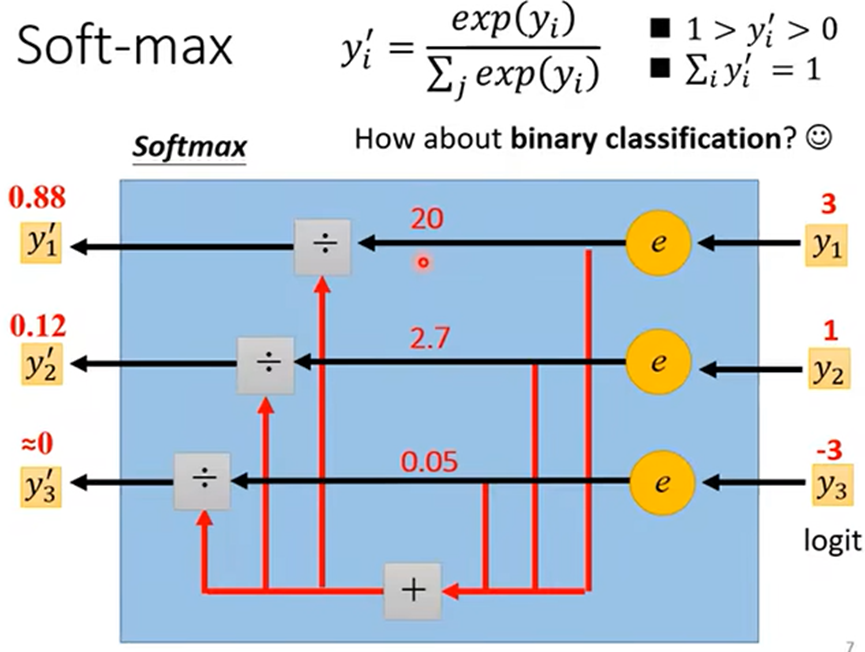
- 将神经网络得出的值y转为概率:y'(分别两个类时常用Sigmoid(σ),两个及以上可用Softmax)
逻辑回归与线性回归比较:
- 线性回归:对内接函数值域划分区域,输出内接函数输出值所属的类
- 逻辑回归:内接函数计算测试数据属于各个类型的概率,输出概率最大的类型

损失函数
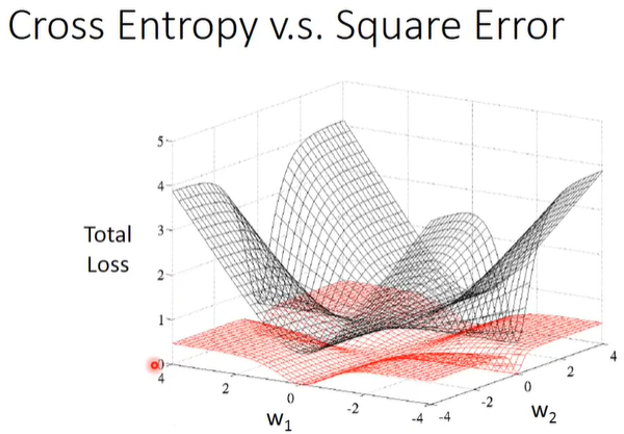
- Cross Entropy或者Mean Squared Error

- Mean Squared Error当离结果较近或者较远时,梯度都接近0,所以使用Cross Entropy一定程度更容易训练
优化算法



训练过程


神经网络验证循环



模型的存储和调用
- 训练好的模型可以用save函数保存起来,使用时也可以使用load函数调用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号