
机器学习是什么
- 机器学习就是让机器找出一个函数(Neural Network:神经网络)
例如输入语音,输出语音中的文字
输入:向量,矩阵(图片辨识。一张图片),序列(语音辨识,一段音频)
输出:数值,类别(分类),一段话/文章
机器学习的过程
1.猜测函数的大致形式为模型(带有未知参数的函数):Y=b+wX1;w为权重(weight),b为偏执(bias);X1为特征值(feature)
2.定义损失函数(loss:L(b,w)):输入为模型中的未知参数的值,输出是评价模型中这组参数值的好坏
- 通过用函数得出值与真实值(label)的差距(ei:误差;MAE:|y-label|标准差;MSE:(y-label)²方差)
- 通过尝试大量的测试得出误差,画出等高线图(Error Surface:错误水平)
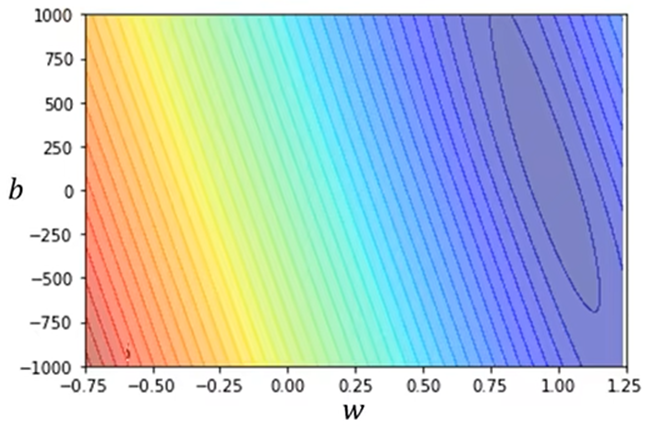
3.Optimization(w,b优化):找出使误差最小的参数值为w*,b*;
- 随机选取w0值(L的一元函数的情况),计算微分得出斜率,乘η(learning rate)作为对w0的调整得到w1*
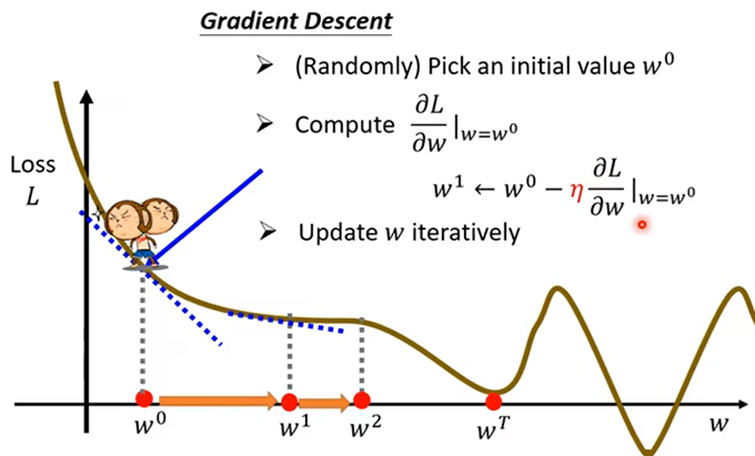
改进模型
- 当前模型得不到满意的结果时,就需要改进模型:Y=b+∑wi*Xi;(Linear nodels:直线)
- 拟合分段折线函数:Piecewise Linear Curves(分段线性曲线)=constant(常数)+∑hard sigmoid(近似折线段)
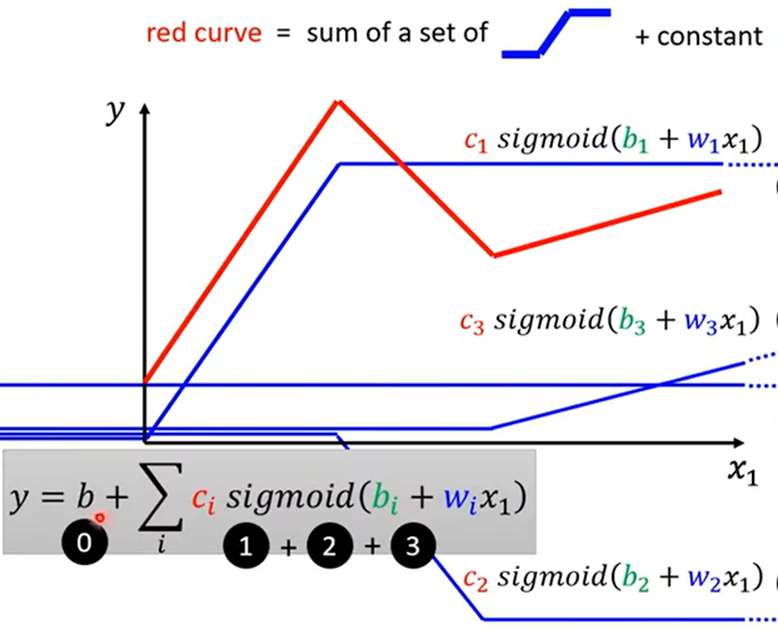
- 拟合光滑曲线:在光滑曲线中选大量点连线组成折线分段函数,用Piecewise Linear Curves拟合
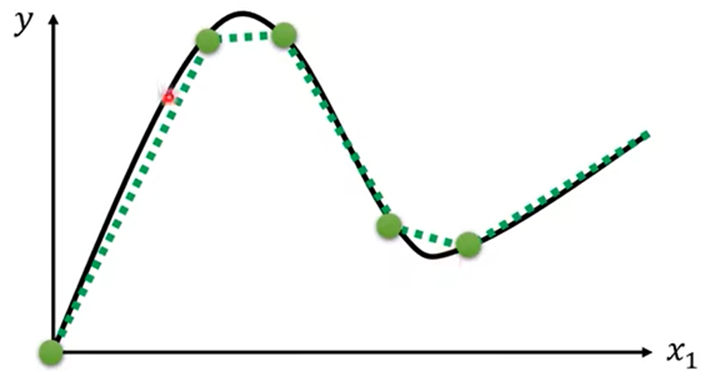
折线在计算机表示
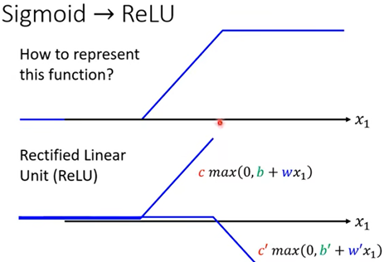
- 折线函数在计算机中无法直接表示,需要用形似的σ函数替代,或ReLU组合表示
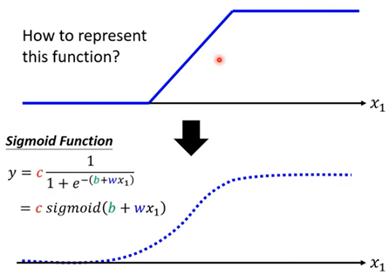
用Sigmoid Function(双弯曲函数)近似代表
两个ReLU函数相加
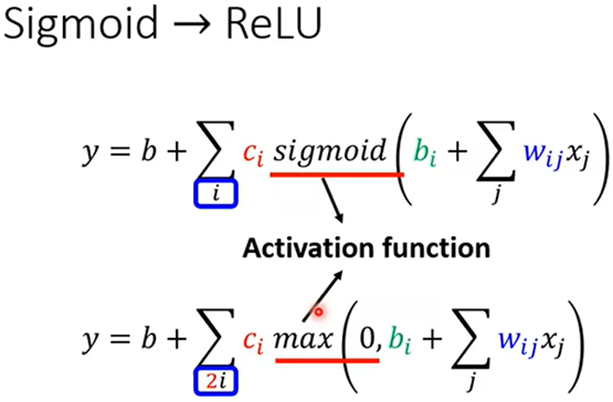
所以任意函数可 Y=b+∑ci sigmoid (bi+wi*X1) 近似表示
多特征值:Y=b+∑ci sigmoid(bi+∑wij*Xj)
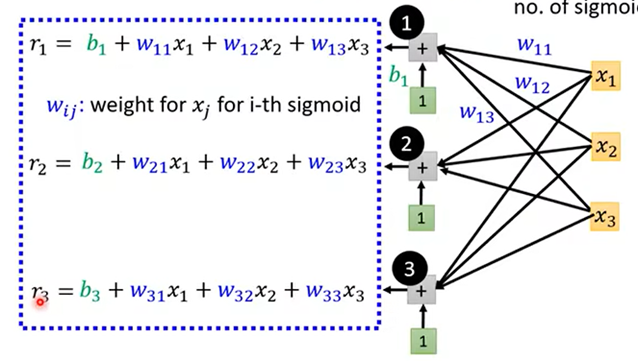

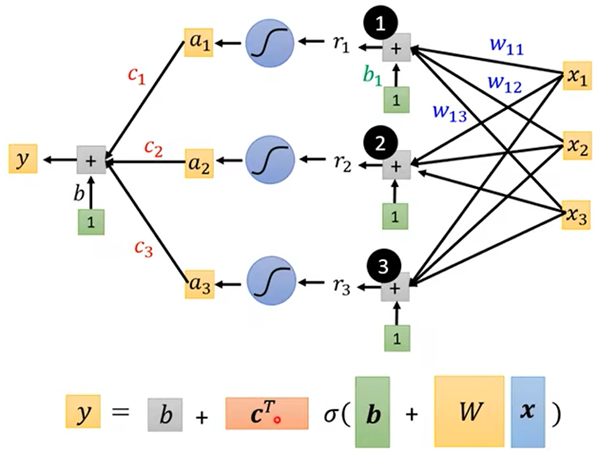
x为特征值列向量,W为权重矩阵,b(绿)为bi的列向量,σ为Sigmoid函数,CT 为行向量,b为数值
- 将所有未知参数记为θ={θ1,θ2,…};定义L(θ),优化θ:
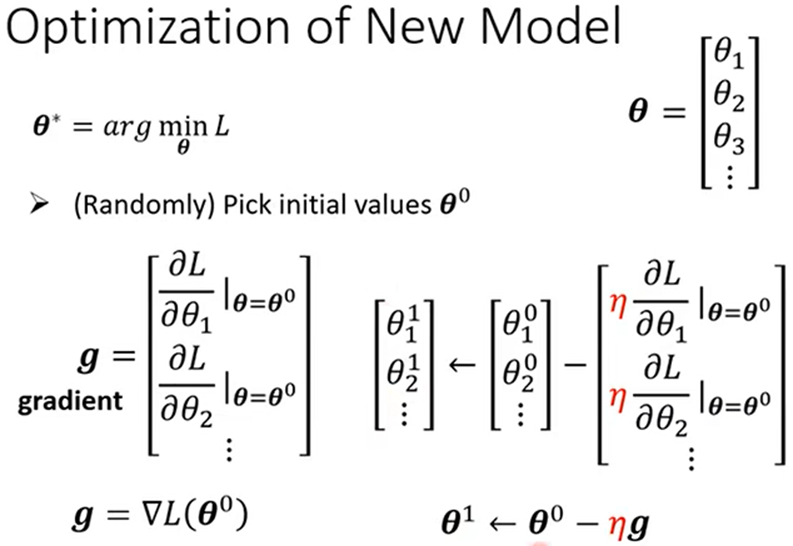
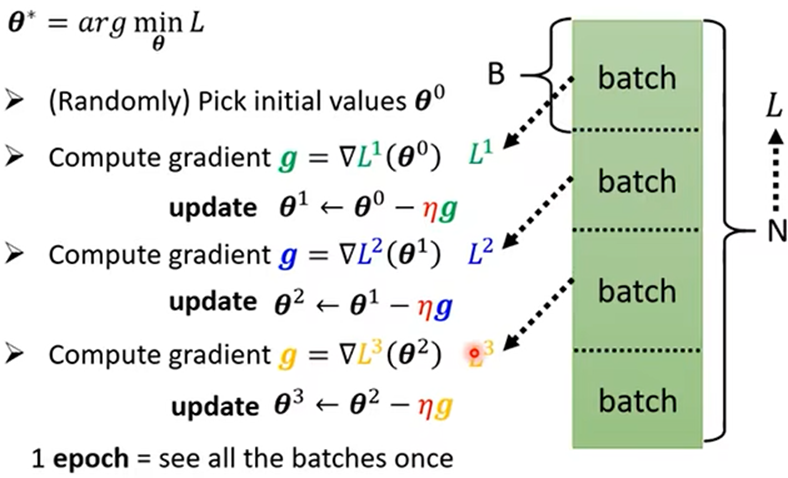
当θ参数较多时,可分成n块,依次计算Li(θi),得出全部θ
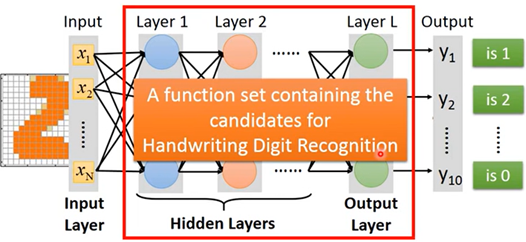
- 每个结点就是神经元(Neuron),一层就是神经网络;对应也就有多层神经网络
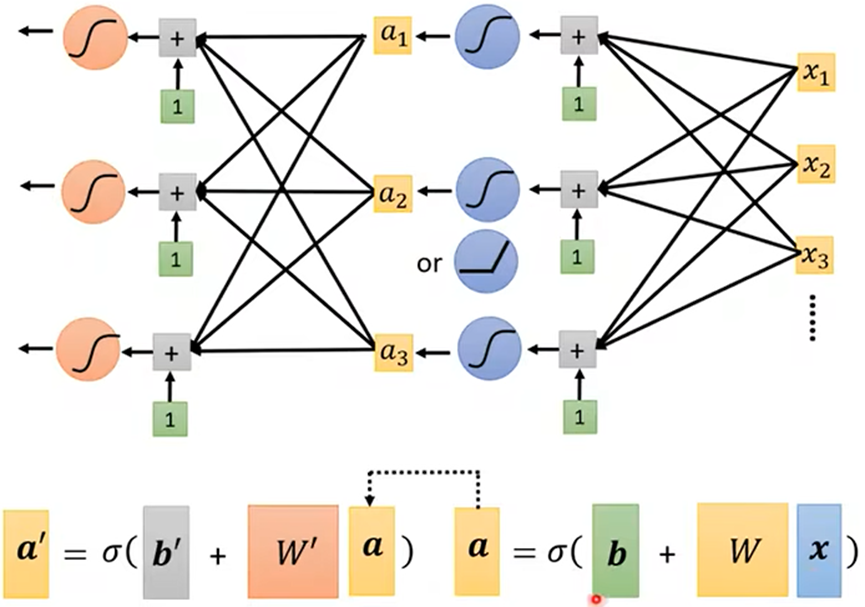
例如:手写数字辨识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号