ASE 结对编程作业|统计文本文件中词汇字母短语等分布
这是ASE(高级软件工程)结对编程的作业
这篇博客不讨论具体地实现,仅仅讨论一下整个项目的流程,具体地实现的代码可以参考我的Github:
https://github.com/ThomasMrY/ASE-Pair-Programing-Project
具体实现的思路,以及我们写这个工程的心路例程,请看这篇博客:
https://blog.csdn.net/qq_35001962/article/details/83627235
用户需求:英语的26 个字母的频率在一本小说中是如何分布的?某类型文章中常出现的单词是什么?某作家最常用的词汇是什么?《哈利波特》 中最常用的短语是什么,等等。 我们就写一些程序来解决这个问题,满足一下我们的好奇心。
要求:程序的单元测试,回归测试,效能测试C/C++/C# 等基本语言的运用和 debug。
题目要求:
Step-0:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
Step-1:输出单个文件中的前 N 个最常出现的英语单词。
Step-2:支持 stop words,我们可以做一个 stop word 文件 (停词表), 在统计词汇的时候,跳过这些词。
Step-3:输出某个英文文本文件中 单词短语出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
Step-4:第四步:把动词形态都统一之后再计数。
队友介绍
我们三个人一个队,结对编程解决这个问题,由于目前我们还在学校没有入职,这些工作都没有与其他联培的同学有一些讨论,我的两个队友A,与B同学,A同学是我的建模队友,以前与我在队伍中的角色分工主要是我负责编程,他负责写作,另外一位B同学是我大三的项目队友,该同学代码写的也是很溜的。考虑到目前我们最擅长的编程语言是Python,所以我们选择用Python实现上面的功能。我们都是学自动化出身,没有系统的学习软件工程,其实很多情况下,为了提高代码的效率,保证代码的正确性,在编写的过程中,我们做了许多测试,做完了开始阅读《构建之法》的时候,才意识到,原来,单元测试,回归测试我们全都做过了,但当时并不知道,没有做记录,后面想起来就需要重新做一下这些测试。
合作方式
既然是结对编程,这个项目实际上是一个合作项目,而且最后需要比较大家的运行速度,我们选择了队内竞争,对外合作的机制,我们对于每个要求,我们分开进行编程,当我们三个都完成了这个问题,我们就聚到一起对比彼此的运行时间,分享彼此编程的思路,结合我们三个所写的程序,进行效能分析,提高代码的效能结合成一个较为高效的版本,上传到GitHub社区。很多情况还是能发现一些彼此不同的思路,某些比较好的思路能够在优化的时候不需要去重新想实现方式,结合彼此最快的实现方式,就能达到最优的效果,因为在编写的时候,我们个人就已经对自己的代码进行了最大可能的优化。有时间也比较神奇大家可以收敛到同一个方法。其实这种合作方式即达到了分开编程的高效,也到达了结对编程的互相学习彼此的写法风格的目的。
讨论方式
我们讨论都是在钱学森图书馆三楼的沙龙上进行的,到目前为止我啥也没点过,有点尴尬。我们主要是先把讨论要解决的问题发到群里面,然后大家来到沙龙也有所准备,很快就进入了状态,第一次讨论主要是讨论一下代码的命名方式,和编码格式,用什么语言之类的,讨论出一种常用而且科学地方案,队友很给力,都提出了一些非常好的想法,我们通过讲述采取这个方式的优劣,最后大家一起选择一种比较科学的方案,这样就达成一致。前期主要是对比大家的运行速度,分享自己编程的思路,给其他队友讲一下自己的代码,然后进行效能分析,结对编程结合彼此的代码,产生一种最快的实现方式。解决之后,我们又针对下一个题目对题目的要求进行讨论,避免对题目的理解产生歧义。后期就是针对博客的写法,以及代码优化,对《构建之法》的理解进行相应的讨论,我们建立了一个共享文档,将自己发现的bug都写入这个文档,便于我们改进代码。
我们的讨论结果是:
工作流程:首先,每个人根据自己的想法实现作业中的几个功能;然后,比较每个人的算法在各个任务上的性能,选择最优的版本继续开发;最后,通过pair programming的方式将最终代码汇总,并作性能分析和功能优化。
代码风格:我们投票决定使用python作为项目的开发语言,为了提高我们的合作效率,我们规定了代码中变量、函数的命名风格以及注释的格式使用驼峰命名法。即变量采用英文单词的组合并且第二个英文单词的首字母大写,函数则是任意首字母大写。全局变量则在前面添加g和下划线。例如:
函数:
变量:
注释风格:
########################################################################### #Name:CountLetters #Inputs:fileName # n : output the top N items in letters # stopName: the file of stopwords skipped # verbName: the file of verb dict #outputs:None #Author: ThomasY #Date:2018.10.24 ###########################################################################
队友优缺点(emmmm,没有想到给我们了一个互相吹捧以及互相吐槽的机会)
队友A:
1.A队友非常认真负责,对于自己的任务都完成的非常出色。
2.A队友很细心,对于我们的版本发现了很多小bug,顺便说一下,讨论的地方也是A队友找到的,非常赞。
3.A队友学习能力非常强,对于队友写的部分,他马上学会了,而且还做出了一些非常有意义的改动。
缺点嘛。。。Python接触的少,写起代码来,略显生疏。
队友B:
1.B队友Python写的很不错,Python写的很熟练,也会很多Python style的骚操作。
2.B队友有些反常规的想法,在Step-5实现的过程中,一般情况下构造字典我们是动词原形做key,各种时态的list作为value,但他的想法不一样,原形做value,这种时态做key,将一个遍历转成了索引,时间提高了很多。
3.B队友讨论时也有较多的想法,和他进行了很多有意义的讨论。
缺点嘛。。。B队友不太喜欢写文本的东西,以至于他的Github是最后写的(小声BB)
优化工具的使用
主要是使用两种代码优化工具对我们的工程进行优化,一种就是cprofile,另外一个就是graphviz,这两种工具分别对代码的效能进行分析,关于怎么使用这个工具,可以参考下面这篇博客:
graphviz, cprofile:https://blog.csdn.net/asukasmallriver/article/details/74356771
避免重复我就以Step-5做一个例子进行分析,如果想看一下具体地每一步的分析结果,可以看下面这篇博客:
https://blog.csdn.net/qq_35001962/article/details/83627235
最初的想法是去除掉各种乱七八糟的符号之后,使用遍历整个文本文件的每一个字母,用一个字典存储计数,每次去索引字典的值,索引到该值之后,在字典的value上加一实现。具体实现的代码如下:
这样做的代码理论上代码是正确的,为了验证代码的正确性,我们需要使用三个文本文件做单元测试,具体就是,一个空文件,一个小样本文件,和一个样本较多的文件,分别做验证,于是可以写单元测试的代码如下:
其中:
- Null.txt 是一个空的文本文件
- gone_with_the_wind.txt 是《乱世佳人》的文本文件
- Test.txt 是一个我们自己指定的内容固定的文本文件,这样就可以统计结果的正确性
经过我们的验证,这个结果是正确的。保证了结果的正确性,经过这样的验证,但还不清楚代码的覆盖率怎么样,于是我们使用工具coverage,对代码进行分析,使用如下命令行分析代码覆盖率
coverage run test.py
得到的结果如下:
Name Stmts Exec Cover --------------------------------------------- CountLetters 56 50 100% --------------------------------------------- TOTAL 56 50 100%
可以看到,在保证代码覆盖率为100%的时候,代码运行是正确的。
但程序的运行速度怎么样呢?为了更加了解清楚它的运行速度,我们使用cprofile分析性能,从而提升运行的性能, 使用cprofile运行的结果为
![]()
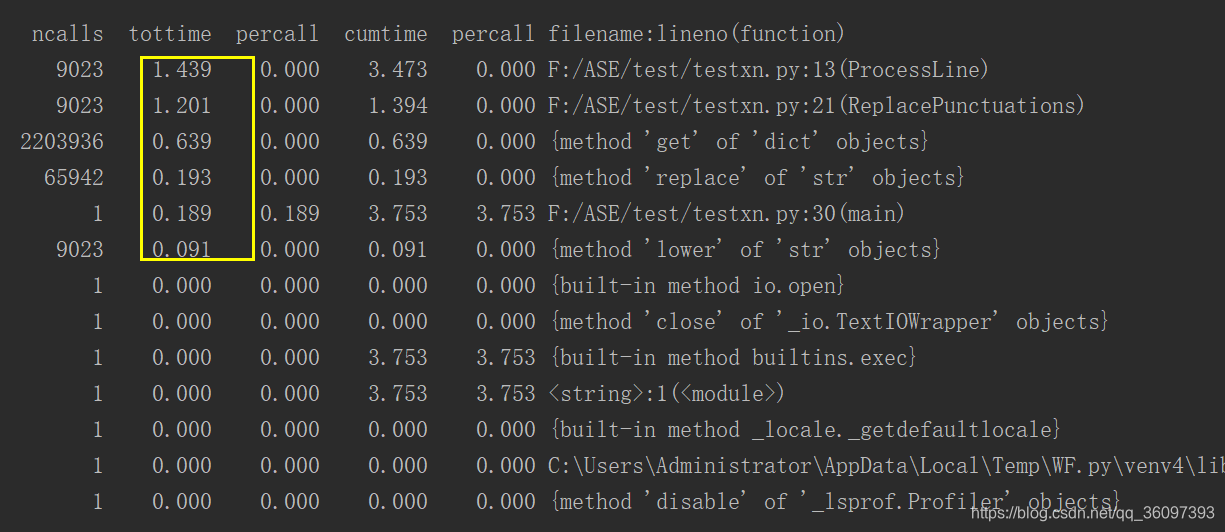
我们大致知道main,Processline,ReplacePunctuations三个模块最耗时,其中最多是ProcessLine,我们就需要看preocessLine()模块里调用了哪些函数,花费了多长时间。
最后使用图形化工具graphviz画出具体地耗时情况如下:
![]()
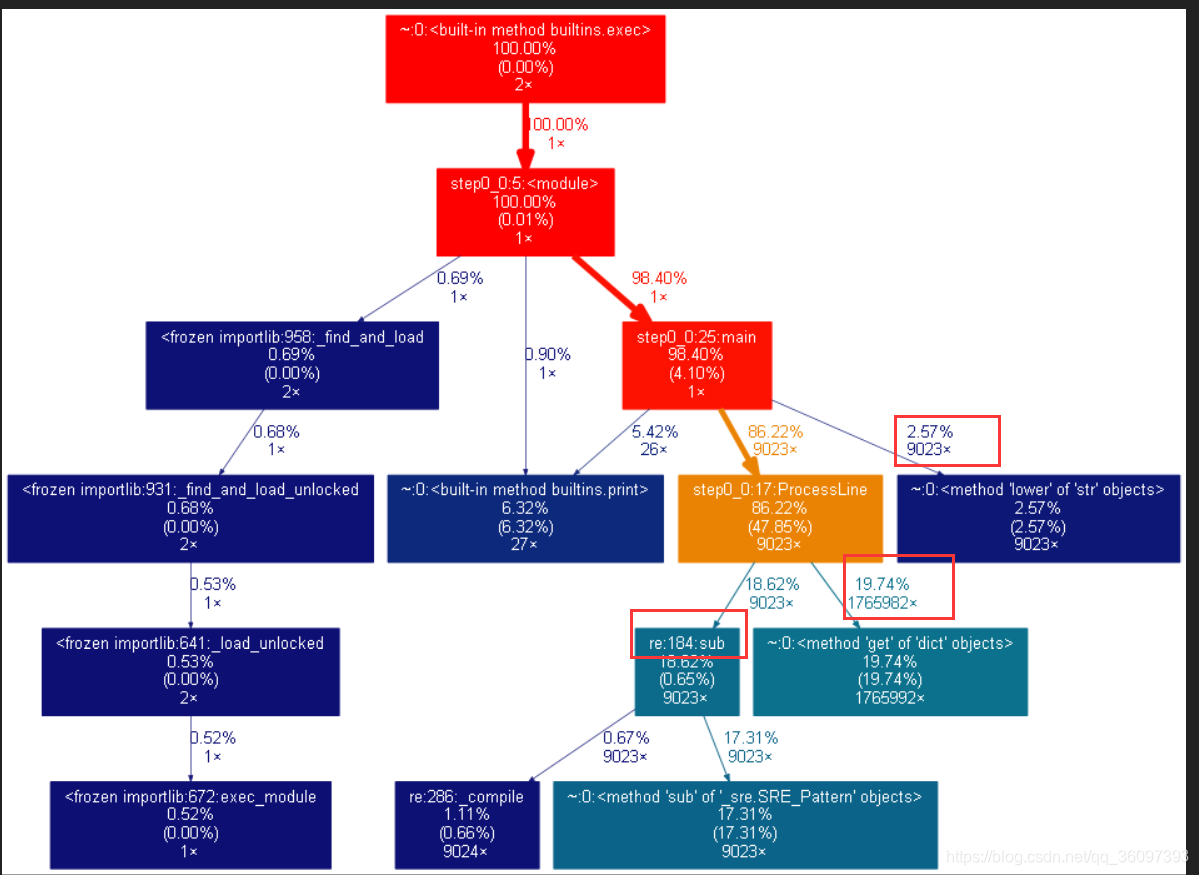
可以从上面的图像中看到文本有9千多行,low函数和re.sub被调用了9023次,每个字母每个字母的统计get也被调用了1765982次,这种一个字母一个字母的索引方式太慢了。我们需要寻求新的解决办法,于是想到了正则表达式,遍历字母表来匹配正则表达式,于是我们就得到了第二版的函数
该函数把运行时间从原来的1.14s直接降到了0.2s,通过重复刚才的单元测试以及效能分析(这里我就不重复粘贴结果了),验证了在代码覆盖率为100%的情况下,代码的运行也是正确的,并且发现运行时间最长的就是其中的正则表达式,在这样的情况下,我们又寻求新的解决方案。最终我们发现了文本自带的count方法,将正则表达式用更该方法替换之后,即将上面的代码:
dicNum[letter] = len(re.findall(letter,txt))
替换为
dicNum[letter] = txt.count(letter) #here count is faster than re
成功的将时间降到了5.83e-5s可以说提高了非常多的数量级,优化到这里,基本上已经达到了优化的瓶颈,没法继续优化了。
注:后来的版本添加了许多功能,这里的代码是添加了功能之后的代码, 如需要运行最初的功能则需要将后面的参数指定成None。
代码的回归测试
回归测试是指原来的代码经过了修改之后,不管是什么原因的修改,可能是由于添加了新的功能,可能是经过了代码优化,都有可能导致代码原来的功能可能产生一些意想不到的影响,为了避免这种影响而重新进行测试以确认没有产生新的错误,或者有没有导致其他代码产生错误。这样理论上每一次进行代码更改的时候都需要对代码进行回归测试,这样的工作对人来说无疑是非常麻烦而且耗时的,这时就需要写一个脚本来做这件事,我们采取了写一个单独的单元测试的脚本验证代码的正确性。每一次添加一个新的功能时就需要修改这个脚本,使得它的命令行的覆盖率达到100%,没有漏检的情况。下面是我们最后得到的单元测试的脚本的例子:
from CountLetters import CountLetters from CountPhrase import CountPhrases from CountPrephrase import CountVerbPre from CountWords import CountWords from CountDir import OperateInDir if (__name__ == '__main__'): # test letters CountLetters('gone_with_the_wind.txt', 10, None, None) CountLetters('gone_with_the_wind.txt', -10, None, None) CountLetters('gone_with_the_wind.txt', 10, 'stopwords.txt', 'verbs.txt') CountLetters('empty.txt', 10, None, None) CountLetters('blanks.txt', 10, None, None) # test words CountWords('gone_with_the_wind.txt', 10, None, None) CountWords('gone_with_the_wind.txt', 10, 'stopwords.txt', None) CountWords('gone_with_the_wind.txt', 10, None, 'verbs.txt') CountWords('gone_with_the_wind.txt', 10, 'stopwords.txt', 'verbs.txt') CountWords('empty.txt', 10, 'stopwords.txt', 'verbs.txt') # test phrase CountPhrases('gone_with_the_wind.txt', 10, None, None, 2) CountPhrases('gone_with_the_wind.txt', 10, None, 'verbs.txt', 2) CountPhrases('gone_with_the_wind.txt', 10, 'stopphrase.txt', 'verbs.txt', 2) CountPhrases('blanks.txt', 10, 'stopphrase.txt', 'verbs.txt', 2) # test dir OperateInDir(CountWords, 'examples', 10, 'stopwords.txt', 'verbs.txt', True) OperateInDir(CountPhrases, 'examples', 10, 'stopwords.txt', 'verbs.txt', None, 2) # test verbpre CountVerbPre('empty.txt', 10, None, 'verbs.txt', 'prepositions.txt') CountVerbPre('empty.txt', 10, 'stopverbpre.txt', 'verbs.txt', 'prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, None, 'verbs.txt', 'prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, 'stopverbpre.txt', 'verbs.txt', 'prepositions.txt')
这样的化每次运行这个脚本就可以将最初的版本到目前的所有功能都测试一遍。
代码的单元测试与覆盖率
代码的单元测试是指对软件中的最小测试单元进行测试,用来测试代码中的功能是否正确,执行这样的测试的目的是为了使得程序的输出与我们预期的结果一致,对于程序员来说,养成了单元测试的习惯,有利于我们写出高质量的代码,同时也可以降低我们的开发成本,一个好的单元测试,应该是能够准确快速,保证程序基本模块运行的正确性。这里为什么需要将单元测试与代码覆盖率一起说呢?因为带啊没的覆盖率是单元测试的其中一个结果,一个程序的正确与否,是不能脱离覆盖率来说的,因为代码覆盖率是单元测试的前提,只有在覆盖率为100%的时候,单元测试的正确性为100%的代码才是算作成功通过了单元测试的代码。同样的为了节约单元测试所用的人力物力,我们采用编写测试脚本的方式,这样庞大的测试量可以一次性完成。下面是我们对Step-5的单元测试的分析,具体的每一步的单元测试可以参考下面这篇博客:
https://blog.csdn.net/qq_35001962/article/details/83627235
from CountPrephrase import CountVerbPre from CountWords import CountWords from CountDir import OperateInDir if(__name__=='__main__'): # test dir OperateInDir(CountVerbPre, 'examples', 10, 'stopwords.txt', 'verbs.txt', True) # test verbpre CountVerbPre('empty.txt', 10, None, 'verbs.txt', 'prepositions.txt') CountVerbPre('empty.txt', 10,'stopverbpre.txt', 'verbs.txt', 'prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, None, 'verbs.txt','prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, 'stopverbpre.txt', 'verbs.txt', 'prepositions.txt')
得到的覆盖率为:

![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号