CVPR 2017:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
[1] Z. Zhou, Y. Huang, W. Wang, L. Wang, T. Tan, Ieee, See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification, 30th Ieee Conference on Computer Vision and Pattern Recognition, (Ieee, New York, 2017), pp. 6776-6785.
摘要:
监控相机广泛应用不同场景。在不同相机下识别人的需求就是行人再识别。在计算机视觉领域最近得到了日益增加的关注,但对比与基于图像的行人再识别方法很少有关注基于视频。现有的工作通常包含两个步骤,称为特征学习与度量学习。同时很多方法并没有充分利用时间信息与位置信息。在这篇论文中,我们关注与基于视频的行人再识别并建立一个端对端的深度架构来联合特征与度量的学习。我们提出的方法能够使用一个时间注意力模型自动地从给定地视频中挑选出最有区分力的帧。不仅如此,在衡量与另一个视频的相似度时,使用一个空间循环模型结合每个位置周围的信息。我们的方法使用一个联合的方式同时处理时空信息。在三个公共数据集上的实验表明了我们提出的深度网络的每个组件的有效性,超过了最先进算法的表现。
总结:
在这篇论文中,我们提出了一个端对端的深层神经网络结构,在衡量相似度时它结合了时间注意力模型来选择对有区分力的帧的关注和一个空间循环模型来利用上下文信息。我们精心设计实验来展示提出的方法的每个组件的有效性。与最先进方法相比,我们的方法表现更好,这表明提出的时间注意力模型对于特征学习,空间循环模型对于度量学习都是有效的。
在近几年,为取得行人再识别的效果提升付出了很多努力。但是,这仍然与现实应用有很大的距离。现在的问题包括严重的遮挡与光照变化,人类姿态的无规则变化,不同人物的服饰颜色与纹理相似。此外,现在是时候强调行人再识别研究的最大限制是缺少非常大尺寸的数据集,其中存在许多实际问题,特别是深层网络越来越流行。因此我们未来的工作就是尽可能收集更多的数据,覆盖尽可能多的场景。
方法概述:
整体网络结构如下图所示,采用了三元序列作为网络输入,先经过AlexNet提取特征,将fc7的输出喂入后面的时间注意力模型,时间注意力模型接受维的输入,然后产生维的输出。然后使用这块的输出构建triplet loss作为一个监督。
同时作者选择了pool5层的输出喂入到空间循环网络,一次输入正负对样本,网络的目标是判断这一对是不是属于同一个人,所以它是一个二分类模型。
最后整体的损失是这两者的叠加,测试时使用下式作为排序依据。
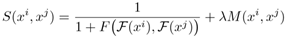

下面介绍一下作者特殊设计的时间注意力模型(TAM)与空间循环模型SRM。
TAM的结构如下所示,输入为图片序列x的fc7层的T个特征图。

这个输入首先经过一个Attention层,它的结构为:

可以看出是一个维度的矩阵,最终的输出是一个维度的矩阵,相当于经过这一步,就产生了对于原始序列的初步关注,作者使用了多个Attention块,并且针对同一输入产生的输出不同,从上图中可以看出不同的Attention块唯一不共享的权重的是前一阶段的隐藏状态。继而把这些初步关注的结果喂入到RNN中。每一步都将产生一个维的输出,之后使用时间的平均池化得到TAM的输出。
对于SRM它的目标是处理视频间的度量学习,结构如下:
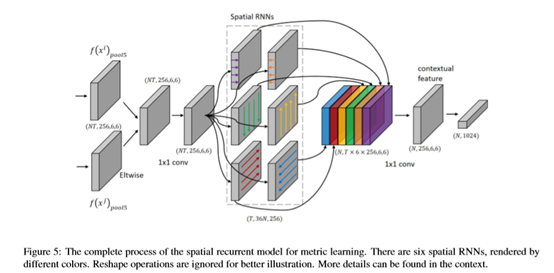
它接受pool5层的特征作为输入,对于一对特征进行相减操作,这就相当于粗略地计算了两个视频序列的不同,然后再使用后续结构对这一信息进行加工总结。
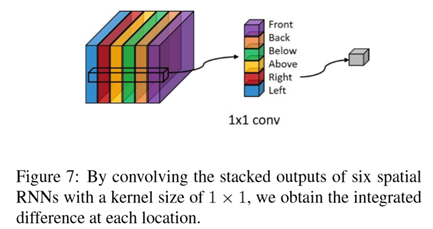
首先作者经过了6个不同方向的空间RNN,作者没有说明这里的RNN结构只说明是使用LSTM实现的,可以看到RNN输入输出两者的总维度相同,所以推断这里的LSTM应该是引出了每个循环体的输出,然后堆叠在一起,接着作者把这个六个空间RNN结果堆叠在一起,相当于每个位置的深度上表达了从六个方向提取的信息,继而使用一个1*1的卷积核总结这六个方向的信息,将其称为上下文特征。作者说这样做能够对光照变化和遮挡不那么敏感(??)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号