初识JDBC-篇四
一、什么是连接池
我们之前在使用jdbc操纵数据库的时候每一个CRUD操作都要创建一个数据库连接对象,普通的JDBC数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将 Connection 加载到内存中,然后再验证用户名和密码花费时间0.05s~1s左右。每次CRUD操作就向数据库要一个连接,执行完成后再断开连接。这样的方式将会消耗大量的资源和时间。数据库的连接资源并没有得到很好的重复利用,若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。
为了解决上述提出的问题,我们提出了数据库连接池的概念。
- 池 保存对象的容器
- **连接池 ** 保存数据库连接对象的容器
- 作用
初始化时创建一定数量的对象。需要时直接从池中取出一个空闲对象,用完后并不直接释放掉对象,而是再放到对象池中以方便下一次对象请求可以直接复用。池技术的优势是,可以消除对象创建所带来的延迟,从而提高系统的性能。 - 数据库连接池
数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接对象,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接,可以通过连接池的管理机制监视数据库的连接的数量﹑使用情况,为系统开发﹑测试及性能调整提供依据。
连接池参考示意图:
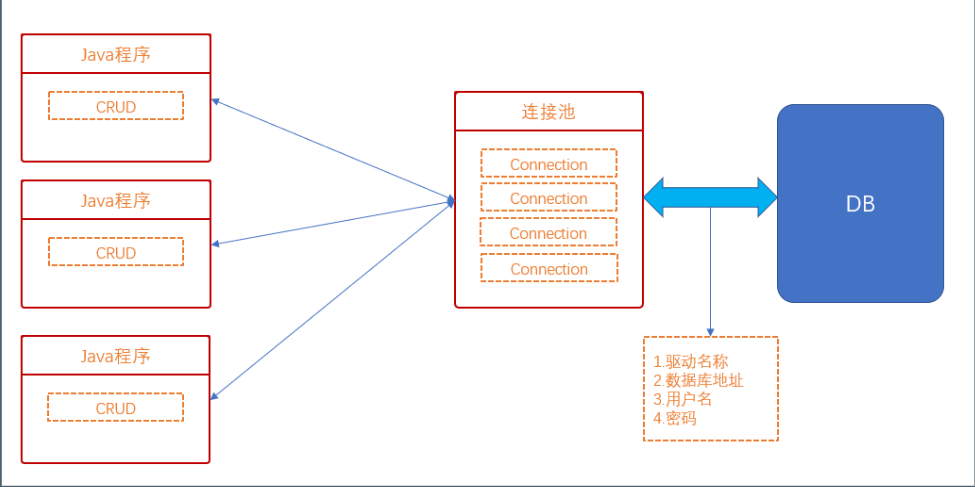
连接池就是一个容器,里面存储着有限的连接对象(Connection),每次我们的java程序想要进行数据库连接进行CURD操作时就只要从连接池中取出一个Connection对象即可。当java程序用完时便将连接对象返还给池中即可。连接池中的对象是以链表的形式存储的,我们每次是在头部取出Connection对象,在尾部返还对象。
连接池中的属性:
合理的设置连接池的属性,会提高连接池的性能
- 连接数据库时需要的4个要素
驱动名称,数据库地址,用户名,密码 - 初始化连接数
初始化时,连接池当中创建多少个Connection对象 - 最大连接数
连接池当中最多存储多少个Connection对象 - 最小连接数
连接池当中最少得存多个少Connection对象 - 最大的空闲时间
如果一个获取了连接对象,在指定时间内没有任何动作,就会自动释放链接 - 最大等待时间
在指定时间内,尝试获取连接,如果超出了指定时间,就会提示获取失败
二、连接池的使用
连接池是使用javax.sql.DataSource接口来表示连接池,DataSource和jdbc一样,也是只提供一个接口,由第三方组织来提供
1.常见连接池
- DBCP
Spring推荐,Tomcat的数据源使用的就是DBCP - C3P0
C3P0是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate一起发布
从2007年就没有更新了,性能比较差。 - Druid
阿里巴巴提供的连接池-德鲁伊-号称最好的连接池,它里面除了这些, 还有更多的功能。
2.使用连接池和不适用连接池的区别
-
获取方式不同
传统:Connection conn = DriverManager.getConnection(url.userName,pwd); 连接池:
Conneciton conn = DataSource对象.getConnection(); -
释放资源不同
传统:和数据库断开conn.close();
连接池:把数据库连接对象还给连接池,还可以给下一个人来使用
3.连接池操作
主要是学习如何创建DataSource对象,再从DataSource对象中获取Connection对象。这些都是第三方提供者给我们提供好的直接使用就行。获取连接对象之后,其余的操作和以前是一样的。不同的数据库连接池,就是在创建DataSource上不一样。
1.DBCP
- 在项目中使用连接池我们首先需要导入jar包
- 在项目中使用连接池来获取连接,获取连接连接池数据源,通过数据源获取连接对象
public static void main(String[] args) throws Exception {
String url = "jdbc:MySQL://localhost:3306/jdbc_db?serverTimezone=UTC&characterEncoding=utf-8&rewriteBatchedStatements=true";
String user = "root";
String pwd = "123456";
String driver = "com.mysql.cj.jdbc.Driver";
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName(driver);
ds.setUsername(user);
ds.setPassword(pwd);
ds.setUrl(url);
Connection conn = ds.getConnection();
String sql = "select * from stu;";
Statement st = conn.createStatement();
ResultSet res = st.executeQuery(sql);
while(res.next()) {
int id = res.getInt("id");
int age = res.getInt("age");
String name = res.getString("name");
System.out.println(id + " " + name + " " + age);
}
JDBCUtil.close(conn, st, res);
}
上面代码只是简单的使用DBCP的示例,我们同样可以利用ds设置最大连接数等等功能,然后我们可以将这些代码封装进我们之前写的工具类当中。
2.druid
druid基本兼容DBCP,操作与DBCP十分类似,但是性能比DBCP好很多
4.读取配置文件
之前我们的代码中都是在java代码中直接写用户名、密码、url的,即便是我们已经将其抽取到了工具类已经方便我们使用很多了。但是这还是不好的方法,这样不利于后期的维护,同样也不利于服务器的部署。因为每次我们都需要进入代码去修改这些内容,那这样那些不熟悉我们项目代码的人就很容易误改了我们的代码,导致项目的奔溃。所以,我们便需要将这些内容单独抽取出来写成一个配置文件
1.配置文件的书写
我们一般将数据库配置文件写成db.properties,内部是以key-value的形式存放。并且我们在开发当中一般会将配置文件放在resource(source folder)文件夹当中
userName=root
password=1234
2.java读取配置文件
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
InputStream in = new FileInputStream("resource/db.properties");
properties.load(in);
System.out.println(properties);
System.out.println(properties.get("user"));
System.out.println(properties.get("url"));
System.out.println(properties.get("pwd"));
}
3.改写DBCP
DBCP读取配置文件我们需要按一定的格式去书写配置文件
配置文件:
url=jdbc:MySQL://localhost:3306/jdbc_db?serverTimezone=UTC&characterEncoding=utf-8&rewriteBatchedStatements=true
username=root
password=123456
driverClassName=com.mysql.cj.jdbc.Driver
加载配置文件:
static {
try {
Properties p = new Properties();
InputStream in = new FileInputStream("resource/db.properties");
p.load(in);
ds = BasicDataSourceFactory.createDataSource(p);
} catch (Exception e) {
e.printStackTrace();
}
}
使用Druid只需要将
ds = BasicDataSourceFactory.createDataSource(p);
换成:
ds = DruidDataSourceFactory.createDataSource(p);
三、总结
jdbc学到这基本都学完了,但是前面几篇文章的代码还可以继续重构,之前的代码结构并不合理。但是我累了,重构就不写了。JDBC部分就到此结束吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号