Yuan-1.0论文笔记
Yuan-1.0论文笔记
模型架构
LM
transformers的decoder,生成类任务效果较好,理解类效果较差,原因在于生成的token只依赖之前的单词,会对后面进行结构掩蔽
PLM
生成一个可见的注意力掩蔽,所以在NLG和NLU任务表现都很好
并行策略
张量并行

在张量并行算法中,模型的层次在节点内的设备之间进行划分。张量并行度的原理如图2所示。在Transformer中,注意和多层感知器(MLP)的张量在向前和向后计算时按行或列分割。输入张量被广播到每个加速器,进行正向传播。当Attention或MLP的前向传递完成时,执行全减少。然后在所有设备上更新结果并发送到下一层。在每一层的前向和后向传播中有四个全约简操作。
一句话概括就是把张量分配到多个设备上去算
流水线并行
数据并行
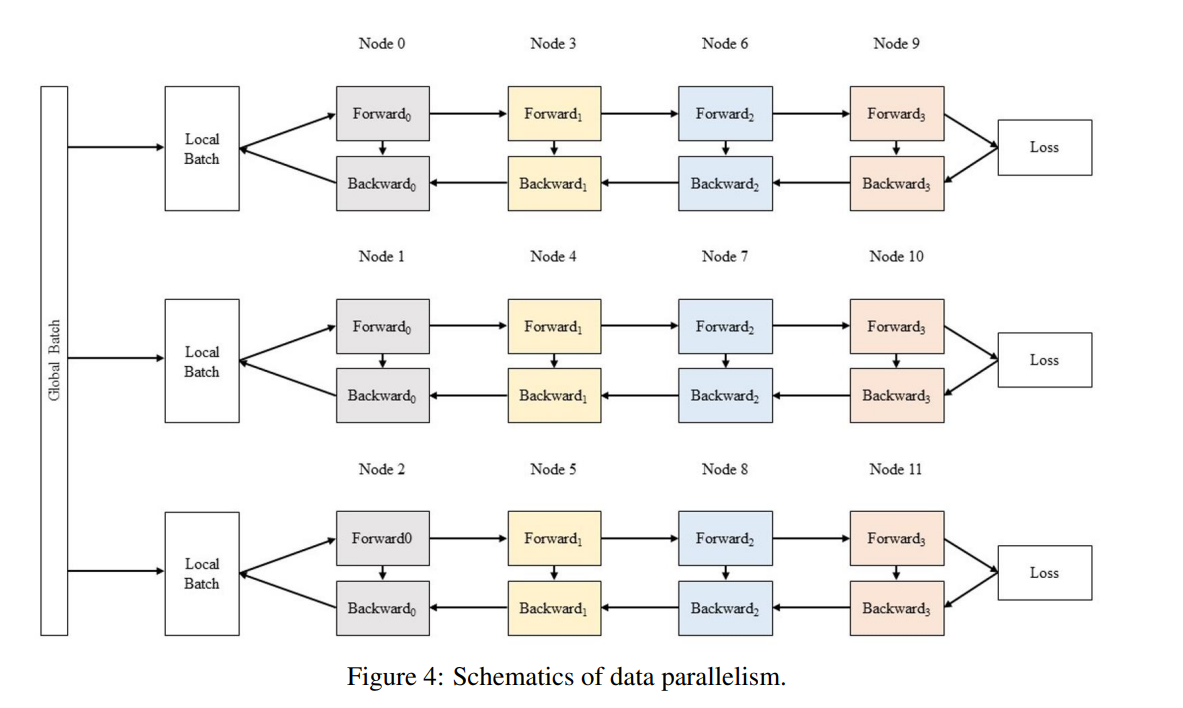
增加了全局批处理
下游任务
Text Classfication
Eprstmt: 情感分类,二分类问题
Tnews, Iflytek and Csldcp:多分类问题
标签在文档末尾,连接提示词
Winograd Schema task
一个确定代词指代哪个名词的歧义任务,本质上还是二分类问题
Natural Language Inference
Ocnli和Bustm数据集,判断两个句子,前者是不是后者的前提,后者是不是前者的假设
交叉熵损失
Reading Comprehension
Chid数据集:中文习语,挖空填词
Csl数据集:一个摘要和四个关键词,判断关键词是否都和摘要一致,可以看作二分类问题
交叉熵损失
Gereration tasks
CMRC2018:根据问题去文档中提取含有答案的相关句子
WebQA:单纯QA
EM和F1是评测指标

 浙公网安备 33010602011771号
浙公网安备 33010602011771号