第一次个人编程作业
论文查重
orz只能说柯老板柯老师题目选的妙啊,直接开始递归式学习了
- 先附上作业github链接:GitHub链接
- 论文查重程序是test.py,其他程序负责测试数据生成、单元测试等工作
使用语言以及代码原理
看到题目的第一反应就是要去看NLP(Natural Language Processing 自然语言处理)相关的知识,既然要用到模型,那从个人角度,python相对写的方便一些,因为可以直接安装对应的库,码量上也会少一些
人生苦短,我用python
我递归式地看了一些模型,例如TF-IDF,TextRank,word2vec,Bert等等,也查了一些论文查重的原理,最终选择用jieba分词+gensim模型计算相似度的方式。
不了解jieba和gensim的同学可以先看看这边:
文本的相似度计算公式如下:
- 所有文本都只保留汉字
- 其中pi指的是分段文本的相似度,wi指分段文本的权重(在比对文本文字的占比)
总的代码设计图如下:
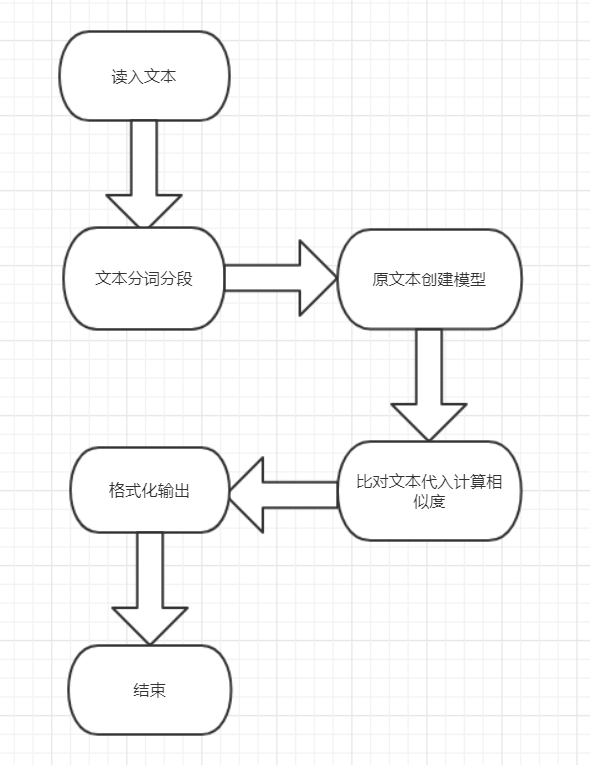
接下来将对各个模块进行介绍
模块介绍
代码主要分为计算模块和字符串处理模块两部分
1.计算模块
计算模块为cal_sentence_weight和cal_similarity_tfidf两个函数。
cal_sentence_weight为计算分段文本的权重,容易实现这里不再赘述
cal_similarity_tfidf函数介绍如下:
-
对已被处理过的原文本我们利用gensim库建立语料库和模型,模型这边我目前采用的是TF-IDF模型
-
代码部分如下:
# 对原始文本用gensim库中的doc2bow和corpora进行处理,采用tfidf模型 # 生成词典 dictionary = corpora.Dictionary(orig_items) # 通过doc2bow稀疏向量生成语料库 corpus = [dictionary.doc2bow(item) for item in orig_items] # 通过TF模型算法,计算出tf值 tf = models.TfidfModel(corpus) # 通过token2id得到特征数(字典里面的键的个数) num_features = len(dictionary.token2id.keys()) # 计算稀疏矩阵相似度,建立一个索引 index = similarities.MatrixSimilarity(tf[corpus], num_features=num_features) -
建立好相似度索引后,我们对于处理过的待比对文本我们做如下操作:对每个分段文本我们计算它在原文本被分段文本的最大相似度(相似度越大说明和这个文本越接近),进行加权累加获得总文本的相似度。
为什么这么取呢?因为在debug过程中我发现同样的分段处理,比对文本分出来的段的内容不一定和原文本一一对应,例如dis后缀的文本直接乱序排(同学们可以试着用全文字向量的方式去计算它们的相似度,dis后缀的文本全是1.0也就是完全一样hhhhh,所以可以直接断定是乱序排列了),如果一一对应有可能出现下标超界的错误,所以改用取最大相似度,这能保证这个分段文本能找到与他最相似的文本,一定程度上可以保证一一对应的关系。
同时对于相似度低于0.25%的我采取舍弃处理,判定他是与语料库中任何一个文本都不相似的。
具体代码如下:
ans = 0.0 for i in range(0,len(orig_sim_items)): #把每个分好词的句子建立成新的稀疏向量并代入模型计算相似度 orig_sim_vec = dictionary.doc2bow(orig_sim_items[i]) sim = index[tf[orig_sim_vec]] sim_max = max(sim) if sim_max < 0.0025:#对于相似度低于0.25%的句子我们直接视为不相关 continue ans += max(sim) * array[i]#显然我们这里要取最高相似度而不是一一对应,可能会有下标超界的错误查重计算原理这边有参照这篇README。
2.字符串处理模块
-
由函数create_jieba_list负责该模块。
-
显然相比全文本直接分词比对计算相似度,分段后再进行分词和计算得出来的相似度会更为精确。然而具体该如何分段又成了问题。
-
试过了好几种方法,去除空格回车+句号分割啊,每15个字算一段啊,逗号分割啊啥的,目前得出的结论是:
-
在遍历的过程中只记录汉字,遇到句号分割为一个段
-
具体代码如下:jieba.lcut可以把文本分词后存为list
def create_jieba_list(test_data):#将文本分句并且每个句子进行分词 test_sentence = [] s = "" for i in range(0,len(test_data)): if '\u4e00' <= test_data[i] <= '\u9fff':#只记录汉字 s += test_data[i] elif test_data[i] == '。':#以句号作为分句标准 #print(s) if s != "":#防止出现一连串符号 test_sentence.append(s) s = "" if s != "":#可能还有文本需要加上 #print(s) test_sentence.append(s) s = "" test_items = [[i for i in jieba.lcut(item)] for item in test_sentence] return test_items
模块具体有何独到之处的话emmm……分段分词勉强算吧,老面向网络编程了= =
运行结果
这里直接放单元测试版本(只含作业样例)的了(头秃):
开始单元测试……
正在载入orig_0.8_add.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.595 seconds.
Prefix dict has been built successfully.
orz查重结果为0.84
已结束测试
开始单元测试……
正在载入orig_0.8_del.txt
..orz查重结果为0.71
已结束测试
开始单元测试……
正在载入orig_0.8_dis_1.txt
.orz查重结果为0.95
已结束测试
开始单元测试……
正在载入orig_0.8_dis_10.txt
orz查重结果为0.80
已结束测试
开始单元测试……
正在载入orig_0.8_dis_15.txt
..orz查重结果为0.57
已结束测试
开始单元测试……
正在载入orig_0.8_dis_3.txt
.orz查重结果为0.91
已结束测试
开始单元测试……
正在载入orig_0.8_dis_7.txt
.orz查重结果为0.87
已结束测试
开始单元测试……
正在载入orig_0.8_mix.txt
.orz查重结果为0.86
已结束测试
开始单元测试……
正在载入orig_0.8_rep.txt
.orz查重结果为0.71
已结束测试
开始单元测试……
正在载入orig.txt
orz查重结果为1.00
已结束测试
.
----------------------------------------------------------------------
Ran 10 tests in 3.555s
OK
算是比较符合预期的,dis系列的文本的相似度随着乱序程度的增大而减少(仅个人猜测,目前来看估计有进行别的修改操作),其他的文本也没有太低或者太高
性能分析与优化
性能分析
Python有几个性能分析工具,对于这次作业我用的是pycharm自带的Profile工具:
- Profile工具有一点不是很好,就是当我们函数调用关系复杂的时候他的函数调用图就非常缩略了orz:
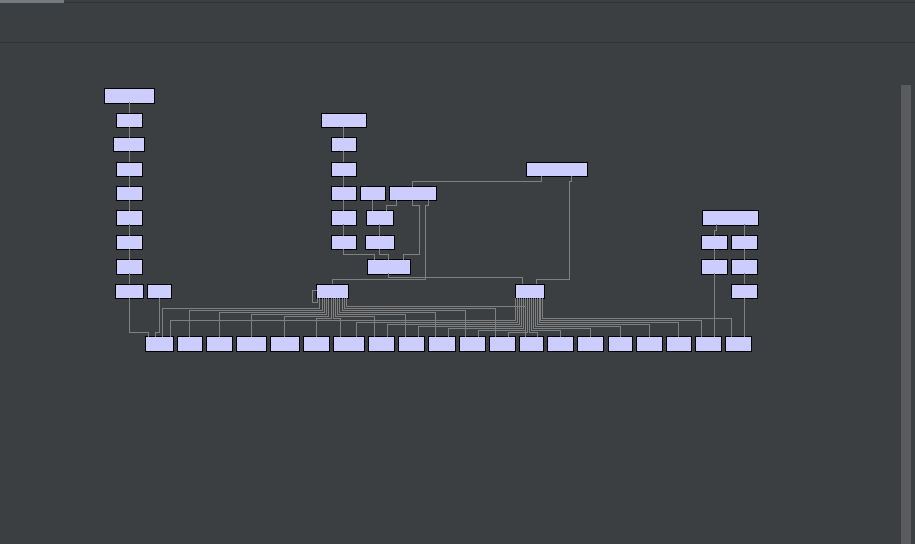
就只能放大来看函数用时和占比orz。
运行时间是比较符合我预期的,没有太慢但是也没有多快(测试组发的所有样例都在这个时间上下):
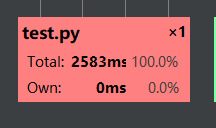
贴一下时间消耗较大的函数以及他们的调用次数的图片:
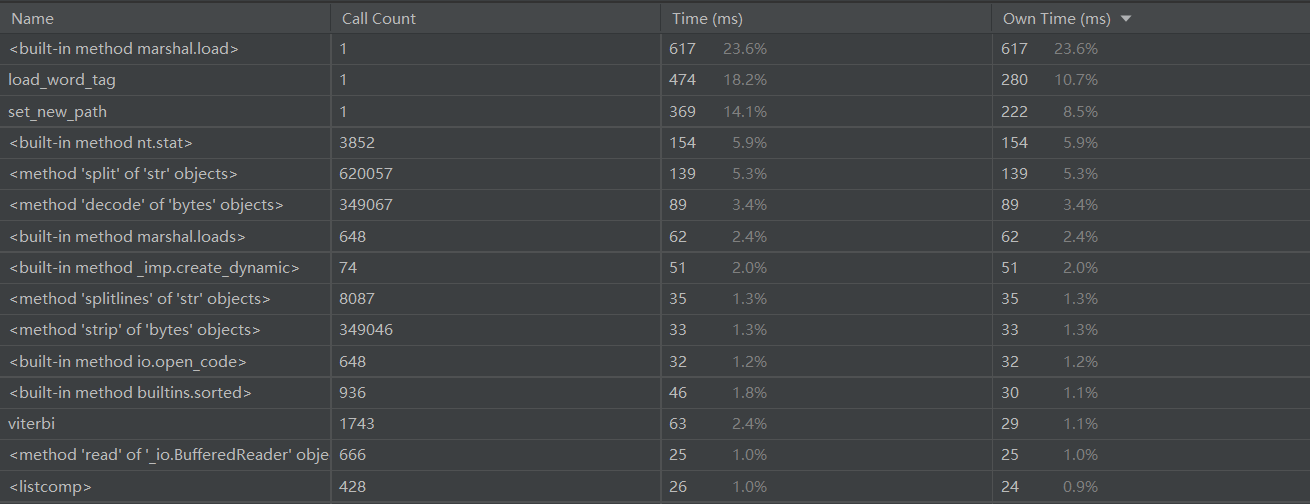
emmmm感觉分析的不够全,因为没有内存统计这块,所以我用了intel性能分析工具
大家感兴趣的话可以装一装,学生申请和安装intel全家桶
国内关于intel全家桶除Vtune外性能分析工具介绍的博客并不是很多,很难找,所以只能挂个官方文档大🔥看看了:
intel性能分析工具官方文档,左上角Profiler&Analyzers都是
- Vtune跑的时候我是一脸懵逼的……因为他直接转成c了= =,具体截图就不放了,挺裂开的……
- 这是关于Vtune的介绍Intel Vtune Profiler
- 所以我直接去跑APS快照了:
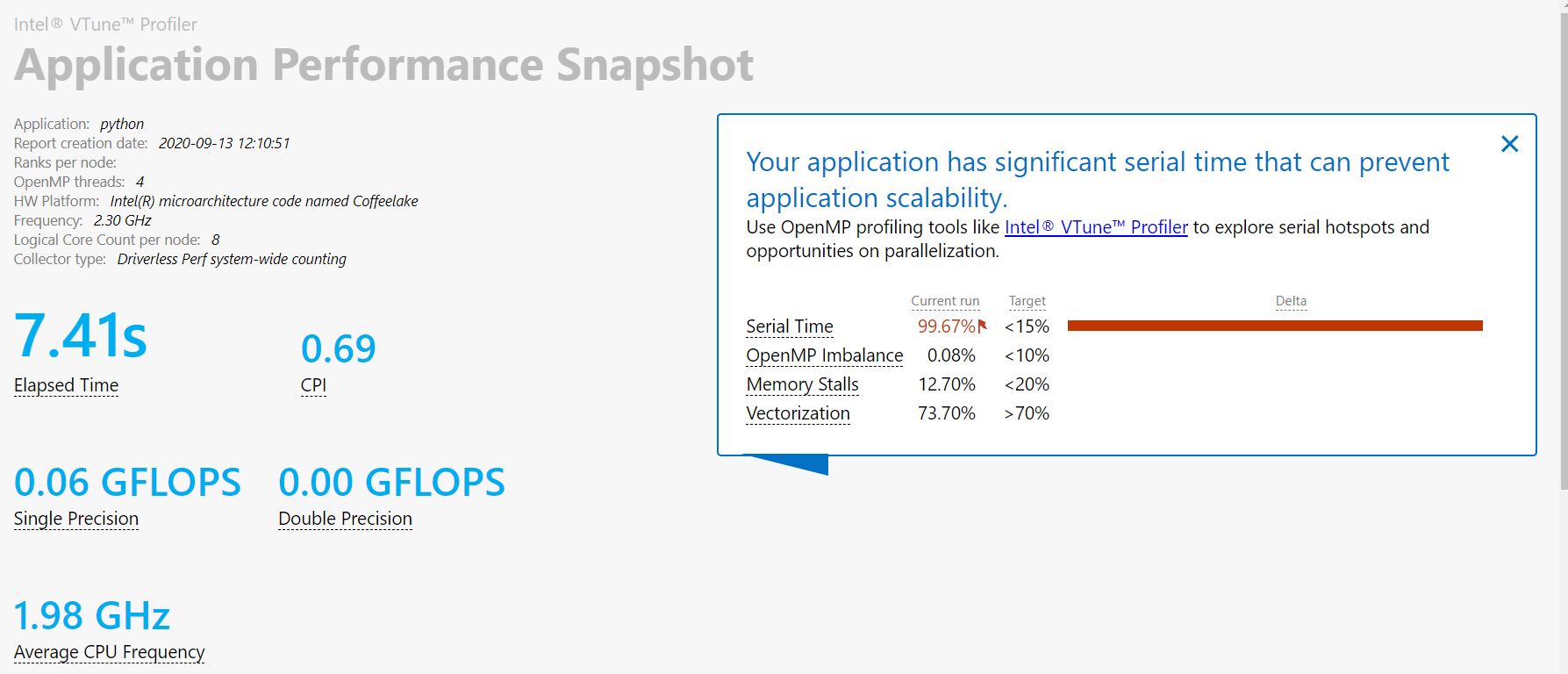
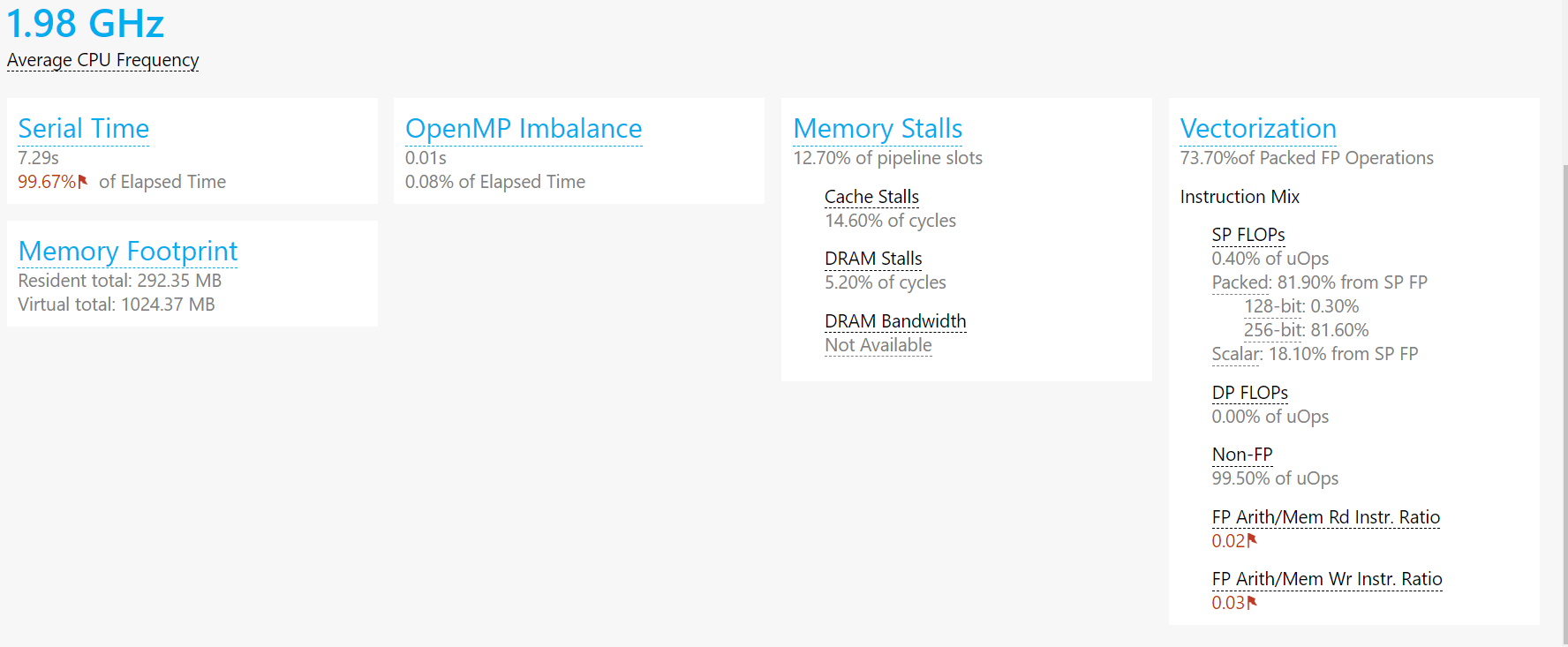
可以看到我们的内存消耗也不是很大,符合自己的预期
然后发现了很奇葩的事情……就是我这个代码已经用了多线程了,甚至还有向量化(挠头),所以后续的优化方向基本有个底了= =,看看多线程这边能不能调一些参数。
优化方面
- 。。。目前算法和代码上没有做什么优化,查了很多博客很多都是在介绍模型emmmm,前面主要是在找比较好的模型或者是一些比较暴力的字符串匹配方法(例如字向量,当然只这么做余弦相似度计算基本0.9以上甚至1.0)还有原算法上分段的凭据。
- 目前是准备往多线程方向看看能不能在循环上处理加个速调调参数这样orz。
2020.9.14(更新)
昨晚组内有个同学问我相似度计算的问题,然后我发现这段代码同样可以作用于LDA和LSI模型,然后效果都不是很好,有丶高:
正在载入orig.txt
orzLDA模型查重结果为1.00
正在载入orig_0.8_add.txt
..orzLDA模型查重结果为0.99
正在载入orig_0.8_del.txt
orzLDA模型查重结果为0.93
正在载入orig_0.8_dis_1.txt
..orzLDA模型查重结果为1.00
正在载入orig_0.8_dis_3.txt
orzLDA模型查重结果为0.99
正在载入orig_0.8_dis_7.txt
..orzLDA模型查重结果为0.99
正在载入orig_0.8_dis_10.txt
.orzLDA模型查重结果为0.97
正在载入orig_0.8_dis_15.txt
.orzLDA模型查重结果为0.90
正在载入orig_0.8_mix.txt
orzLDA模型查重结果为0.98
正在载入orig_0.8_rep.txt
..orzLDA模型查重结果为0.94
正在载入orig.txt
.orzLSI模型查重结果为1.00
正在载入orig_0.8_add.txt
orzLSI模型查重结果为0.96
正在载入orig_0.8_del.txt
..orzLSI模型查重结果为0.87
正在载入orig_0.8_dis_1.txt
.orzLSI模型查重结果为0.99
正在载入orig_0.8_dis_3.txt
orzLSI模型查重结果为0.97
正在载入orig_0.8_dis_7.txt
..orzLSI模型查重结果为0.96
正在载入orig_0.8_dis_10.txt
.orzLSI模型查重结果为0.93
正在载入orig_0.8_dis_15.txt
orzLSI模型查重结果为0.82
正在载入orig_0.8_mix.txt
..orzLSI模型查重结果为0.95
正在载入orig_0.8_rep.txt
.
----------------------------------------------------------------------
Ran 30 tests in 31.319s
OK
orzLSI模型查重结果为0.88
相比之下还是TF-IDF靠谱点= =所以单元测试和总代码继续保留TFIDF模型的计算
计算模块部分单元测试展示
我本来写了个“测试程序”顺序执行了所有的样例,结果网上冲浪的时候发现了unittest模块,一口老血吐了出来,马上转用unittest了
不过使用unittest前要把我们整个计算相似度的程序封装成一个函数,这样写unittest测试程序会比较好写。
test.py->test_as_function.py:
import jieba
import sys
import test#引用一下计算程序,不然代码属实太长
from gensim import corpora, models, similarities
import os
import time
def orig_solve(orig_position):
orig = open(orig_position, 'r', encoding='UTF-8')
orig_text = orig.read()
orig.close()
# 1.将原始文本分句并每句用jieba_lcut分词
orig_items = test.create_jieba_list(orig_text)
return orig_items
def text_solve(text_position):
text = open(text_position, 'r', encoding='UTF-8')
test_text = text.read()
text.close()
# 1.将原始文本分句并每句用jieba_lcut分词
text_items = test.create_jieba_list(test_text)
array = test.cal_sentence_weight(test_text)
return text_items,array
def write_dir(ans,ans_position):
str1 = str('0.2f' %ans)
ans_text = open(ans_position,'w',encoding='UTF-8')
ans_text.write(str1)
ans_text.close()
#print('0')
def solve(orig_position,text_position,ans_position):
orig_items = orig_solve(orig_position)
text_items,array = text_solve(text_position)
ans = test.cal_similarity(orig_items,text_items,array)
write_dir(ans,ans_position)
print('orz查重结果为%.2f' %ans)
测试代码如下(展示tf-idf类):
import unittest
import test_as_function # 引用一下计算程序,不然代码属实太长
from BeautifulReport import BeautifulReport
class TestForAllTextTfIdf(unittest.TestCase):
@classmethod
def setUp(self):
print("开始单元测试……")
@classmethod
def tearDown(self):
print("已结束测试")
def test_self_tfidf(self):
print("正在载入orig.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig.txt', 'ans.txt')
def test_add_tfidf(self):
print("正在载入orig_0.8_add.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt','sim_0.8\orig_0.8_add.txt','ans.txt')
def test_del_tfidf(self):
print("正在载入orig_0.8_del.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_del.txt', 'ans.txt')
def test_dis_1_tfidf(self):
print("正在载入orig_0.8_dis_1.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_1.txt', 'ans.txt')
def test_dis_3_tfidf(self):
print("正在载入orig_0.8_dis_3.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_3.txt', 'ans.txt')
def test_dis_7_tfidf(self):
print("正在载入orig_0.8_dis_7.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_7.txt', 'ans.txt')
def test_dis_10_tfidf(self):
print("正在载入orig_0.8_dis_10.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_10.txt', 'ans.txt')
def test_dis_15_tfidf(self):
print("正在载入orig_0.8_dis_15.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_15.txt', 'ans.txt')
def test_mix_tfidf(self):
print("正在载入orig_0.8_mix.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_mix.txt', 'ans.txt')
def test_rep_tfidf(self):
print("正在载入orig_0.8_rep.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_rep.txt', 'ans.txt')
def test_rep_tfidf_NoChineseError(self):
print("正在载入orig_NoChinese.txt")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_rep.txt', 'ans.txt')
def test_rep_tfidf_TextSameError(self):
print("正在载入")
def test_My_database1_add(self):
print("正在载入My_database1\\orig_add.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_add.txt', 'ans.txt')
def test_My_database1_del(self):
print("正在载入My_database1\\orig_del.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_del.txt', 'ans.txt')
def test_My_database1_dis_1(self):
print("正在载入My_database1\\orig_dis_1.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_dis_1.txt', 'ans.txt')
def test_My_database1_dis_3(self):
print("正在载入My_database1\\orig_dis_3.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_dis_3.txt', 'ans.txt')
def test_My_database1_dis_7(self):
print("正在载入My_database1\\orig_dis_7.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_dis_7.txt', 'ans.txt')
def test_My_database1_dis_10(self):
print("正在载入My_database1\\orig_dis_10.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_dis_10.txt', 'ans.txt')
def test_My_database1_dis_15(self):
print("正在载入My_database1\\orig_dis_15.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_dis_15.txt', 'ans.txt')
def test_My_database1_mix(self):
print("正在载入My_database1\\orig_mix.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_mix.txt', 'ans.txt')
def test_My_database1_rep(self):
print("正在载入My_database1\\orig_rep.txt")
test_as_function.solve_tfidf('My_database1\orig.txt', 'My_database1\orig_rep.txt', 'ans.txt')
if __name__ == '__main__':
#unittest.main()
suite = unittest.TestSuite()
suite.addTest(TestForAllTextTfIdf('test_self_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_add_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_del_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_dis_1_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_dis_3_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_dis_7_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_dis_10_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_dis_15_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_mix_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_rep_tfidf'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_add'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_del'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_dis_1'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_dis_3'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_dis_7'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_dis_10'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_dis_15'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_mix'))
suite.addTest(TestForAllTextTfIdf('test_My_database1_rep'))
runner = BeautifulReport(suite)
runner.report(
description='论文查重测试报告', # => 报告描述
filename='nlp_TFIDF.html', # => 生成的报告文件名
log_path='.' # => 报告路径
)
emmm目前是作业的那几组只动了20%数据的文本加上我自己生成的测试数据,基本是对着测试组的数据“照虎画猫”(有意这么写,不是不会成语orz),自己的测试数据原文本是用狗屁不通文章生成器生成的两个文章放在一起,两万多字。
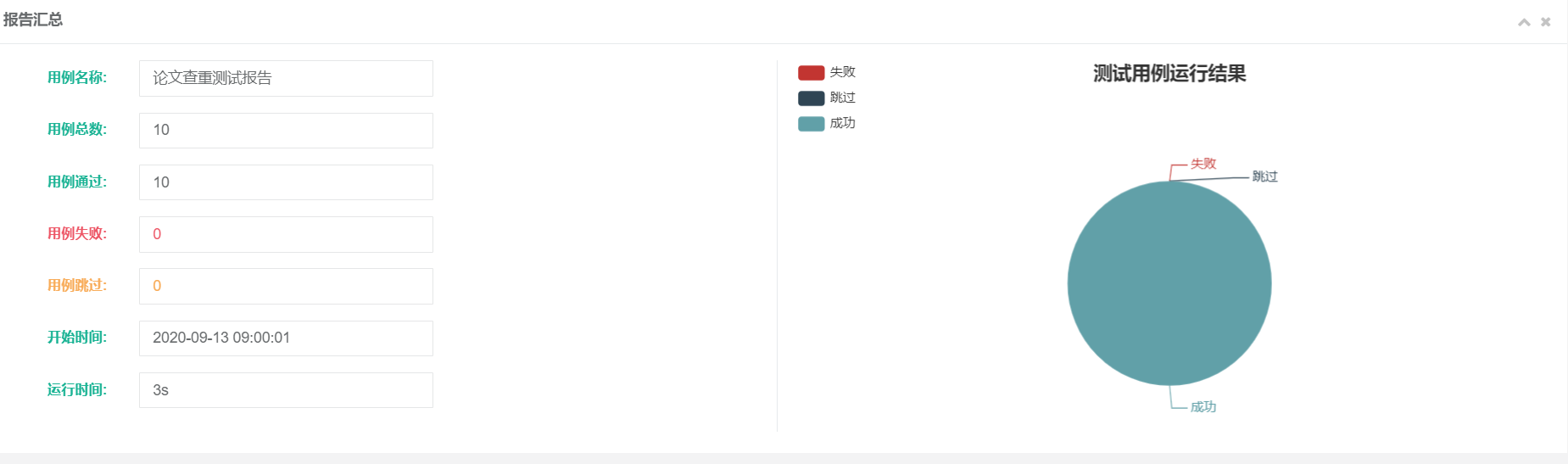
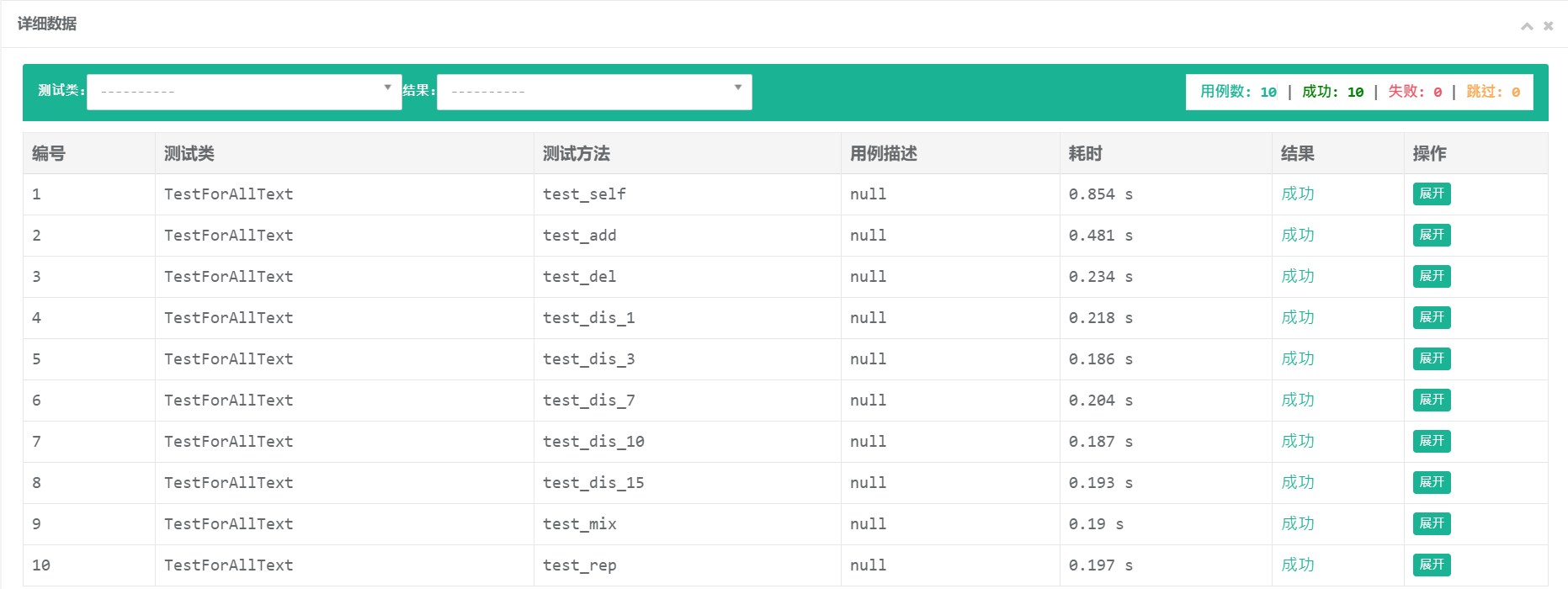
orz不知道为啥Pycharm自带的unittest框架看不到每个样例具体的通过结果和运行时间,只好动用黑科技——BeautifulReport了,这个模块可以生成样例测试html格式的报告,报告内详细介绍了每个样例的运行细节以及对应时间。
这篇Unittest-测试运行:查看测试结果介绍了三种看报告结果的方法,推荐大家试一下(不过后面两种要用的包pip都装不了得自己解压到sites-package目录下hhhh)
测试覆盖率截图:
然后是自己生成的数据的



很显然dis系列(也就是乱序)的文本并不能如预期一样乱序次数越多查重率越低,测试组的数据应该是用了其他方法,我这个乱序文本的生成程序做的还不够有代表性
当然当前的测试还有缺点:
- 应该还有其他生成相似文章的方式,加入这些样例测试覆盖率会更广
- 乱序程序的乱序程度有点大,多次乱序相似度不存在大小关系,需要再修改方法
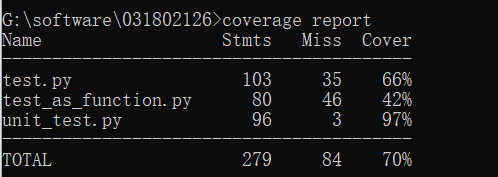
代码覆盖率截图:
测试数据生成程序
按照作业样例txt命名的字面意思以及我自己的文本操作,推测出几个相似文本构建方式,我可以实现相对简单的测试数据生成程序:
-
加式文本:每隔固定长度我们增加固定个数的随机汉字。这样生成的数据代表性肯定没作业样例强,因为在看orig_0.8_add.txt的时候其实可以看到测试组的同学很用心的把增加的字加在了词之间,破坏了词的结构。这样对我们比对来说相似度不会太高也不会太低。
-
删式文本:每隔固定长度我们删除固定个数的随机汉字。
-
乱序文本:三个模式:1.逗号分割句子让句子乱序若干次 2.句号分割让句子乱序若干次 3.每隔固定长度字符让段落乱序若干次
以上三个模式都把符号算入计数范畴。
关于数组乱序有一篇相对比较好的博客,他的第三种方法挺好的,O(n)的复杂度,大佬估计想得到orz:如何让一个数组乱序
-
混合文本:增删结合
-
代表(rep)文本:增删改结合
然后我们要做的就是读入我们的文本就行啦!
我github链接上也有这个代码,create_sample.py就是
import random def add(test_text):#增字,目前只支持每隔固定距离添加固定长度随机汉字 a,b = eval(input("请输入划分段的字数以及要添加随机汉字的长度,用逗号隔开:")) s = "" cnt = 0 for i in range(0,len(test_text)): s += test_text[i] cnt += 1 if cnt == a: cnt = 0 for j in range(0,b): s+=chr(random.randint(0x4e00, 0x9fbf)) return s def delete(test_text):#删字,目前只支持每隔固定距离删除固定长度随机汉字 a, b = eval(input("请输入划分段的字数以及要删除随机汉字的长度,用逗号隔开:")) s = "" cnt = 0 for i in range(0, len(test_text)): if cnt == a: cnt = 0 for j in range(0, b): i += 1 if i == len(test_text): break if i == len(test_text): break s += test_text[i] cnt += 1 return s def swap(a,b): temp = a a = b b = temp return a,b def chaos_sort(str1): str1_len = len(str1) list1 = list(str1) for i in range(0,str1_len): k = random.randint(0, str1_len-i-1) #print(list1[k],list1[str1_len-i-1]) list1[k],list1[str1_len-i-1] = swap(list1[k],list1[str1_len-i-1]) #print(list1[k], list1[str1_len-i-1]) str1 = "" for i in range(0, str1_len): str1+=list1[i] #print(str1) return str1 def dis(test_text):#乱序,目前只支持逗号分割,句号分割以及每隔一段距离n次乱序的操作 a,b = eval(input("请输入划分模式(1表示逗号分割,2表示句号分割,3表示自己定分段字数)以及每次乱序的次数:")) s = "" temp = "" if a == 1 or a == 2: if a == 1: str1 = ',' elif a == 2: str1 = '。' for i in range(0, len(test_text)): temp += test_text[i] if test_text[i] == str1: for j in range(0,b): temp = chaos_sort(temp) #print(temp) s += temp temp = "" if temp != "" : for j in range(0, b): chaos_sort(temp) s += temp temp = "" else: c = eval(input("请输入分段长度:")) cnt = 0 for i in range(0, len(test_text)): temp += test_text[i] cnt += 1 if cnt == c: for j in range(0,b): chaos_sort(temp) print(temp) s += temp cnt = 0 temp = "" if temp != "" : for j in range(0, b): chaos_sort(temp) s += temp temp = "" return s def mix(test_text):#增删结合 str1 = add(test_text) str1 = delete(str1) return str1 def rep(test_text):#增删乱序结合 str1 = add(test_text) #print(str1) str1 = delete(str1) #print(str1) str1 = dis(str1) return str1 if __name__ == '__main__': test = open("My_database1\\orig.txt",'r',encoding = 'UTF-8') test_text = test.read() test.close() str1 = input("请输入创造相似文本的模式(add,del,dis,mix,rep):") str1.upper() if str1 == "ADD": change_text = add(test_text) elif str1 == "DEL": change_text = delete(test_text) elif str1 == "DIS": change_text = dis(test_text) elif str1 =="MIX": change_text = mix(test_text) else: change_text = rep(test_text) #print(change_text) change = open("My_database1\\orig_rep.txt",'w',encoding = 'UTF-8') change.write(change_text) change.close() print("已按%s模式生成相应文本:D",str1) print(0)
异常处理
说实话我一开始看到要写这个的时候是一脸懵逼的……毕竟只有文本查重,但是自己思考+向柯老师询问后,还是有几个异常要写的orz
- 不一样的文本相似度却是100%
- 一样的文本相似度却不是100%
- 某些文本没有汉字
- 处理过程中可能会有下标超界的情况
因为第四个python自带,所以我对前三个异常进行了编写:
class TextSameError(Exception): # 文本不同相似度却100%
def __init__(self):
print("文本不一样为什么会完全一样捏?")
def __str__(self, *args, **kwargs):
return "再检查一下代码哦"
class TextDifferentError(Exception): # 文本一致相似度不是100%
def __init__(self):
print("自己和自己比,怎么会不一样呢?")
def __str__(self, *args, **kwargs):
return "再检查一下代码哦"
class NoChineseError(Exception): # 比对文本压根没有汉字,相似度直接判0
def __init__(self):
print("汉字都没有比对🔨呢")
ans_txt = open(sys.argv[3], 'w', encoding='UTF-8')
sim = str(0.00)
ans_txt.write(sim)
ans_txt.close()
print("0")
def __str__(self, *args, **kwargs):
return "找篇有汉字的来吧"
2020.09.16更新
具体用法:
# 计算权重
if sum == 0:
raise NoChineseError
else:
for i in range(0, len(array)):
array[i] = array[i] * 1.0 / sum
return array
try:
ans += max(sim) * array[i] # 显然我们这里要取最高相似度而不是一一对应,可能会有下标超界的错误
except IndexError:
print("orz下标超界了")
else:
continue
if abs(ans - 1.00) <= 0.000001 :
raise TextSameError
else:
ans_txt = open(sys.argv[3], 'w', encoding='UTF-8')
sim = str('%.2f' % ans)
ans_txt.write(sim)
ans_txt.close()
print(0)
异常测试样例:
# 异常处理,IndexError和TextDifferentError是在调试过程中使用的,目前程序已经没有这个问题
def test_NoChineseError_tfidf(self):
print("开始无汉字异常测试QAQ:")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_NoChinese.txt', 'ans.txt')
def test_TextSameError_tfidf(self):
print("开始文本相同异常测试QAQ:")
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_copy.txt', 'ans.txt')
测试结果如下(orz下标超界是因为原来的异常处理是作用于test.py文件的,要写到命令行传参的文件上所以会报错):
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
开始单元测试……
开始无汉字异常测试QAQ:
Loading model cost 0.581 seconds.
Prefix dict has been built successfully.
E汉字都没有比对🔨呢
已结束测试
开始单元测试……
开始文本相同异常测试QAQ:
文本不一样为什么会完全一样捏?
已结束测试
E
======================================================================
ERROR: test_NoChineseError_tfidf (__main__.TestForAllTextTfIdf)
----------------------------------------------------------------------
Traceback (most recent call last):
File "G:/software/031802126/unit_test.py", line 92, in test_NoChineseError_tfidf
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_NoChinese.txt', 'ans.txt')
File "G:\software\031802126\test_as_function.py", line 95, in solve_tfidf
text_items,array = text_solve(text_position)
File "G:\software\031802126\test_as_function.py", line 83, in text_solve
array = test.cal_sentence_weight(test_text)
File "G:\software\031802126\test.py", line 82, in cal_sentence_weight
raise NoChineseError
File "G:\software\031802126\test.py", line 34, in __init__
ans_txt = open(sys.argv[3], 'w', encoding='UTF-8')
IndexError: list index out of range
======================================================================
ERROR: test_TextSameError_tfidf (__main__.TestForAllTextTfIdf)
----------------------------------------------------------------------
Traceback (most recent call last):
File "G:/software/031802126/unit_test.py", line 96, in test_TextSameError_tfidf
test_as_function.solve_tfidf('sim_0.8\orig.txt', 'sim_0.8\orig_copy.txt', 'ans.txt')
File "G:\software\031802126\test_as_function.py", line 98, in solve_tfidf
raise test.TextSameError
test.TextSameError: 再检查一下代码哦
----------------------------------------------------------------------
Ran 2 tests in 0.811s
FAILED (errors=2)
总结
- 感觉自己学习能力上还是要有待提高……很多模型看了理解不来,像word2vec,LDA这些我看了都挺懵逼的,也不知道怎么用,如果能理解这些模型的话程序应用应该会更精确一些
- 很久没打python了,码了这么多感觉自己熟练度上还是没落下。
不过打C的时候会习惯性加冒号和不写分号 - 当我把注意力放在编写需求程序以外的部分的时候,我才发现软工实践还有这么多东西要做,我们要编写的代码不仅仅只是我们的需求程序,我们还需要写测试程序还有测试数据生成程序,当然如果项目大点应该还要写点其他的。这让我意识到软工实践的魅力所在,它要求我们完成的是一个流程,而不是单个子任务,每个板块都是密不可分的。
- 和以往写算法题目不一样,debug并不只是在某个代码段输出对应值来找到代码漏洞那么简单,我们可以用相应的模块载入测试数据来衡量程序的严谨性和效果
- 代码还不够规范hhhhh,以后尽量按PEP8标准来写
(下划线声明变量选手表示很折磨)
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| Planning(计划) | 192 | 200 |
| Estimate(估计时间) | 192 | 100 |
| Development(开发) | 1968 | 1680 |
| Analysis(需求分析(包括学习新技术)) | 144 | 100 |
| Design Spec(生成设计文档) | 120 | 84 |
| Design Review(设计复审) | 96 | 68 |
| Coding Standard(代码规范 ) | 72 | 51 |
| Design(具体设计) | 240 | 168 |
| Coding(具体编码) | 864 | 804 |
| Code Review(代码复审) | 168 | 118 |
| Test(测试(自我测试,修改代码,提交修改)) | 312 | 400 |
| Reporting(报告) | 216 | 500 |
| Test Report(测试报告) | 72 | 380 |
| Size Measurement(计算工作量) | 48 | 50 |
| Postmortem & Process Improvement Plan(事后总结, 并提出过程改进计划) | 72 | 70 |
| Total(合计) | 2400 | 2593 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号