
机器学习—降维-特征选择6-3(PCA)
使用PCA对糖尿病数据集降维
主要步骤流程:
- 1. 导入包
- 2. 导入数据集
- 3. 数据预处理
- 3.1 检测缺失值
- 3.2 生成自变量和因变量
- 3.3 拆分训练集和测试集
- 3.4 特征缩放
- 4. 使用PCA降维
- 4.1 使用 PCA 生成新的自变量
- 4.2 验证PCA转换规则
- 4.2.1 打印旧的自变量与新的自变量的转换系数
- 4.2.2 增加转换系数的可读性
- 4.2.3 检验X_train_pca的由来
- 4.3 选择PCA个数
- 4.3.1 打印 pca 的方差解释比率
- 4.3.2 画出新的自变量的个数 VS 累计方差解释
- 4.4 使用 PCA 降维
- 5. 构建逻辑回归模型
- 5.1 使用原始数据构建逻辑回归模型
- 5.2 使用降维后数据构建逻辑回归模型
- 6. 可视化PCA降维效果
- 6.1 选择2个主成分
- 6.2 可视化2个主成分
1. 导入包
In [30]:
# 导入包 import numpy as np import pandas as pd import matplotlib.pyplot as plt
2. 导入数据集
In [31]:
# 导入数据集
dataset = pd.read_csv('pima-indians-diabetes.csv')
dataset
Out[31]:
3. 数据预处理
3.1 检测缺失值
In [32]:
# 检测缺失值
null_df = dataset.isnull().sum()
null_df
Out[32]:
3.2 生成自变量和因变量
In [33]:
# 生成自变量和因变量
X = dataset.iloc[:,0:8].values
y = dataset.iloc[:,8].values
3.3 拆分训练集和测试集
In [34]:
# 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
3.4 特征缩放
In [35]:
# 特征缩放
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
4. 使用PCA降维
4.1 使用 PCA 生成新的自变量
In [92]:
# 使用 PCA 生成新的自变量
from sklearn.decomposition import PCA
pca = PCA(n_components = None) # 新的自变量的个数
X_train_pca = pca.fit_transform(X_train)
X_train_pca.shape
Out[92]:
In [37]:
X_test_pca = pca.transform(X_test)
4.2 验证PCA转换规则
4.2.1 打印旧的自变量与新的自变量的转换系数
In [93]:
# 打印旧的自变量与新的自变量的转换系数
print('旧的自变量与新的自变量的转换系数是:\n', pca.components_)
4.2.2 增加转换系数的可读性
In [39]:
# 增加转换系数的可读性
old_columns = list(dataset)[:-1]
new_columns = ['pc' + str(i) + '_component' for i in range(X_train.shape[1])]
components_df = pd.DataFrame(pca.components_, columns = old_columns, index = new_columns)
components_df = components_df.T # 转置,增加可读性
print('打印旧的自变量与新的自变量的转换系数是:\n', components_df)
4.2.3 检验X_train_pca的由来
In [40]:
print(X_train.shape)
In [41]:
components = components_df.values
print(components.shape)
In [42]:
# 检验x_train_pca的由来
verify_matrix = X_train.dot(components)
In [43]:
print(verify_matrix)
In [44]:
print(X_train_pca)
verify_matrix 和 X_train_pca一模一样
4.3 选择PCA个数
4.3.1 打印 pca 的方差解释比率
In [45]:
# 打印 pca 的方差解释比率
print('PCA的方差解释比率是:\n', pca.explained_variance_ratio_)
4.3.2 画出新的自变量的个数 VS 累计方差解释
In [55]:
np.cumsum(pca.explained_variance_ratio_)
Out[55]:
In [58]:
# 画出新的自变量的个数 VS 累计方差解释
plt.plot([i for i in range(1, X_train.shape[1] + 1)],
np.cumsum(pca.explained_variance_ratio_), c='orange')
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance')
h=6
plt.vlines(h, 0.2, 1, colors = "c", linestyles = "dashed")
plt.hlines(np.cumsum(pca.explained_variance_ratio_)[h-1], 8, 1,
colors='c', linestyles='dashed')
plt.show()
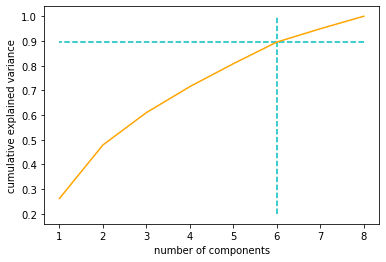
当降维后的自变量的个数是6时,能解释90%的方差。所以选择降维后自变量的个数是6。
4.4 使用 PCA 降维
In [19]:
# 使用 PCA 降维
pca = PCA(n_components = 6) # 6由上一步选出
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
print(X_train_pca)
5. 构建逻辑回归模型
5.1 使用原始数据构建逻辑回归模型
In [20]:
# 构建模型
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(penalty='l2', C=1,
class_weight='balanced', random_state = 0)
classifier.fit(X_train, y_train)
Out[20]:
In [21]:
# 预测测试集 y_pred = classifier.predict(X_test)
In [22]:
# 评估模型性能
from sklearn.metrics import accuracy_score
print(accuracy_score(y_test, y_pred))
5.2 使用降维后数据构建逻辑回归模型
In [23]:
# 构建模型
classifier = LogisticRegression(penalty='l2', C=1,
class_weight='balanced', random_state = 0)
classifier.fit(X_train_pca, y_train)
Out[23]:
In [24]:
# 预测测试集
y_pred = classifier.predict(X_test_pca)
In [25]:
# 评估模型性能
print(accuracy_score(y_test, y_pred))
降维后,模型性能提升了0.006
6. 可视化PCA降维效果
可视化时,选择2个主成分。选择2个主成分信息有损失,这里目的仅仅是可视化
6.1 选择2个主成分
In [94]:
# 使用 PCA 降维
pca = PCA(n_components = 6)
X_train_pca = pca.fit_transform(X_train)
In [95]:
import seaborn as sns
ne=pd.concat([pd.DataFrame(X_train_pca),pd.DataFrame(y_train)],axis=1).reset_index(drop=True)
ne.columns = ['a', 'b', 'c', 'd', 'e','f','g']
antV = ['#1890FF', '#2FC25B']
sns.pairplot(ne,palette=antV,hue='g')
Out[95]:
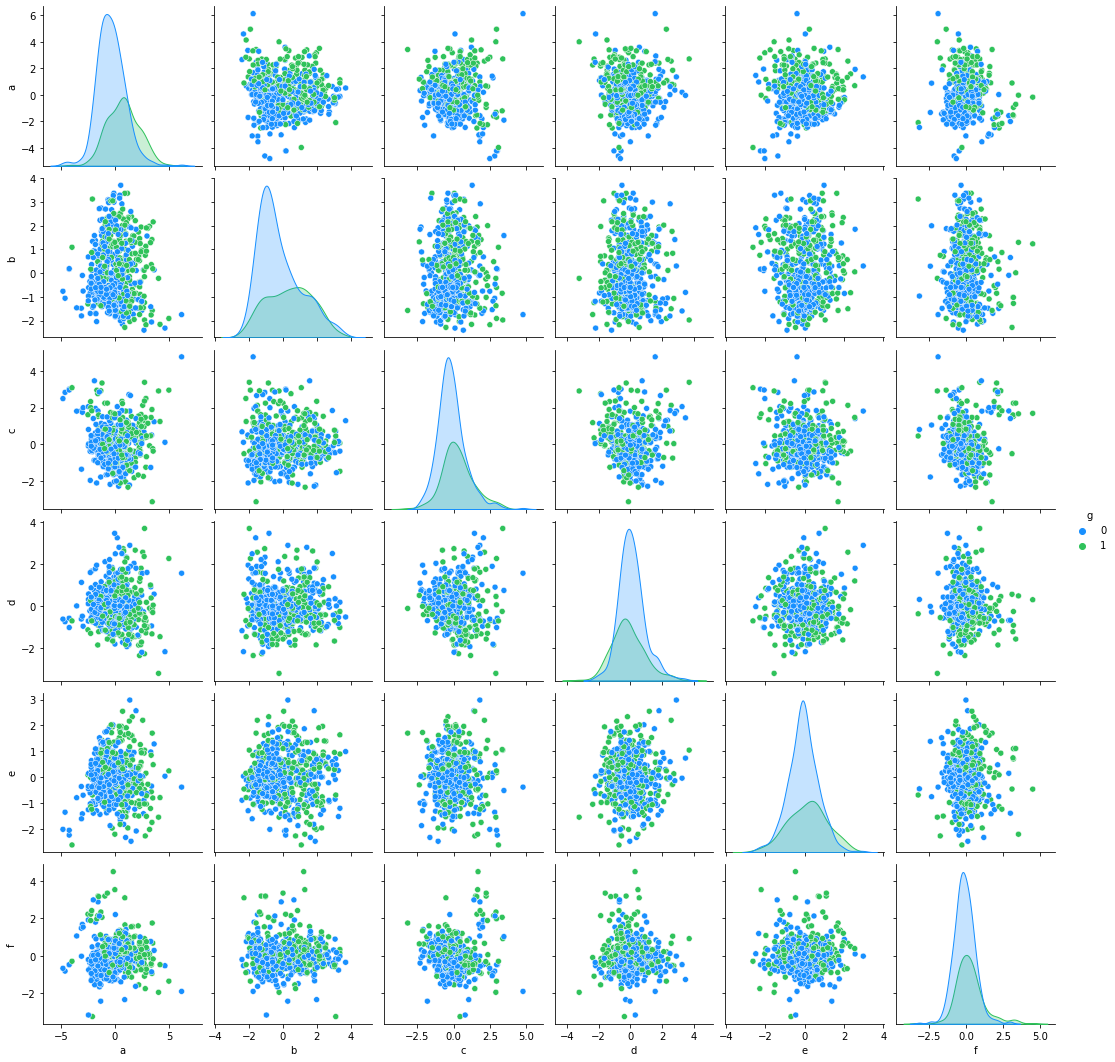
6.2 可视化2个主成分
In [101]:
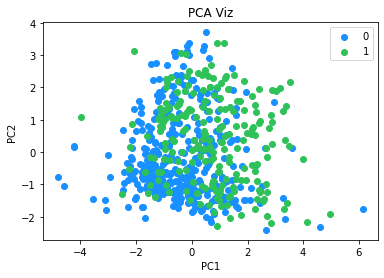
from matplotlib.colors import ListedColormap
X_set, y_set = X_train_pca, y_train
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
color = ListedColormap(['#1890FF', '#2FC25B'])(i), label = j)
plt.title('PCA Viz')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show()
In [99]:
# 使用 PCA 降维
pca = PCA(n_components = 2)
X_train_pca = pca.fit_transform(X_train)
import seaborn as sns
ne=pd.concat([pd.DataFrame(X_train_pca),pd.DataFrame(y_train)],axis=1).reset_index(drop=True)
ne.columns = ['a', 'b','c']
antV = ['#1890FF', '#2FC25B']
sns.pairplot(ne,palette=antV,hue='c')
Out[99]:
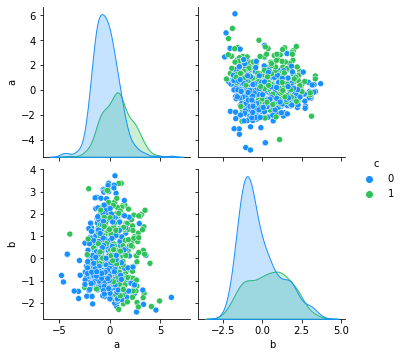
经过PCA降维,自变量由8个变为2个。
将降维后的2个主成分可视化,可以看到,如果以2个主成分训练逻辑回归模型,模型性能会较差,因为肉眼可见,2个类别之间没有明显的界限。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号