
机器学习—聚类5-2(轮廓系数)
使用轮廓系数评估超市客户分组效果
主要步骤流程:
- 1. 导入包
- 2. 导入数据集
- 3. 使用K-Means算法得到不同K值对应的WCSS4. 使用K-Means算法得到不同K值对应的轮廓系数
- 3.1 生成WCSS
- 3.2. 画出 K值 vs WCSS 图
-
4. 使用K-Means算法得到不同K值对应的轮廓系数
1. 导入包
In [1]:
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2. 导入数据集
In [2]:
# 导入数据集
dataset = pd.read_csv('Mall_Customers.csv')
dataset
Out[2]:
仅选取Annual Income (k$)和Spending Score (1-100)这2个字段
In [3]:
X = dataset.iloc[:, [3, 4]].values
X[:3, :]
Out[3]:
3. 使用K-Means算法得到不同K值对应的WCSS
3.1 生成WCSS
In [4]:
# 使用肘部法则选择最优的K值
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', n_init=10, max_iter=300, random_state = 0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
3.2. 画出 K值 vs WCSS 图
In [5]:
# 画出 聚类个数 vs WCSS 图
plt.figure()
plt.plot(range(1, 11), wcss, 'ro-')
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
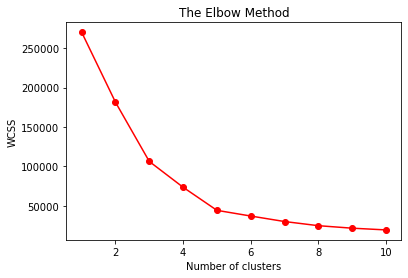
由上图可见,从K=5开始,WCSS下降不再明显
4. 使用K-Means算法得到不同K值对应的轮廓系数
In [6]:
# 聚类个数2-10时,对应的轮廓系数
from sklearn.metrics import silhouette_score
for i in range(2, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', n_init=10, max_iter=300, random_state = 0)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
silhouette = silhouette_score(X, y_kmeans)
print('当聚类个数是%d时,对应的轮廓系数是%.4f' %(i, silhouette))
由输出结果可见,聚类个数是5时,轮廓系数的值最高
结论:
- 肘部法则和轮廓系数都是确定K-Means模型中K值的方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号