
<<高性能mysql>>笔记1
转载请注明: TheViper http://www.cnblogs.com/TheViper
<<高性能mysql>>这本书写的真的很好,只可惜本屌不才,大部分都看不懂,暂且记下与mysql优化有关,对自己有用的东西。
测试指标
- 吞吐量
吞吐量指的是单位时间内的事务处理数,单位tps(transaction per second).这一直是经典的数据库应用测试的指标。
- 响应时间或延迟
这个指标用于测试任务所需的整体时间
- 并发性
注意,web服务器并发性不等同于数据库的并发性。服务器的高并发一般也会导致数据库的高并发,但服务器所用的语言,框架,工具集对此都会有影响。一个设计良好的应用,同时可以打开成千上百个数据库服务器连接,但可能同时只有少数连接在执行查询。因此,所需要关注的是正在工作中的并发操作,或者是同时工作中的线程数或连接数。
- 可扩展性
可扩展性指的是,给系统增加一倍的工作,理想情况下,会获得两倍的吞吐量,这时,看实际增加的吞吐量是多少。
性能优化的目标--响应时间
很多人认为性能优化就是降低cpu利用率。但这是个陷阱,资源就是用来消耗并用来工作的。所以,有时候消耗更多的资源能够加快查询速度。很多时候,升级到mysql新版本后,cpu利用率会上升的很厉害。这不代表性能出了问题。相反,说明新版本对资源的利用率上升了。
另外,如果把性能优化仅仅看出是提升每秒查询量,这其实只是吞吐量优化。吞吐量的提升可以减少响应时间的副产品(倒数关系)。
优化数据类型
- 更小的通常更好
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。但是确保没有低估需要存储的值得范围。
- 简单就好
简单数据类型的操作通常需要更少的cpu周期。例如,整型比字符操作代价更低,具体的。
1.应该使用mysql内建类型而不是字符串存储日期和时间
2.应该用整型存储ip地址。
- 尽量避免null
通常情况下,最好指定列为not null,除非真的需要存储null值。如果查询中包含可为null的列,对mysql来说会更难优化,因为可为null的列使得索引,索引计算和值比较更复杂。另外,可为null的列会使用更多的存储空间。
下面具体说下数据类型
- 整数类型
有两种类型的数字,整数和实数。如果存储整数,可以使用这几种整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT,对应8,16,24,32,64位存储空间。
整数类型有UNSINGED属性,表示不允许负数,这大致可以是整数的最大值上限提高一倍。
mysql可以为整数类型指定宽度,如INT(7),但对大多数应用这时没意义的。它不会限制值的范围。对于存储来说,INT(1)和INT(10)是一样的。
2.实数类型
实数是带有小数部分的数字。但是,它们不仅可以用来储存小数部分,还可以使用DECIMAL储存比BIGINT还大的整数。
浮点类型在储存同样范围的值时,通常比DECIMAL使用更少的空间。FLOAT使用4个字节储存,DOUBLE使用8个字节储存。mysql使用DOUBLE作为内部浮点计算的类型。
注意,在数据量比较大时,例如储存财务数据,可以考虑使用BIGINT替代DECIMAL,将需要存储的货币单位,根据小数的位数乘以相应的倍数即可。这样可以同时避免浮点存储不精确和DECIMAL精确计算代价高的问题。
3.字符串类型
VARCHAR:用于存储可变长字符串。它比定长类型更节省空间,因为它仅使用必要的空间。
VARCHAR需要使用1或2个额外字节记录字符串的长度。如果列的最大长度<=255字节,则使用1个字节表示,否则使用2个字节。
由于行是变长的,在update时可能会使行变得比原来长。下面情况下使用VARCHAR比较合适。
1.字符串列的最大长度比平均长度大很多
2.列的更新很少,不会出现碎片问题。
3.使用了想utf-8这样复杂的字符集。
4.每个字符都使用不同的字节数进行存储。
CHAR:定长,mysql总是根据定义的字符串长度分配足够的空间。
在存储时,mysql会删除所有的末尾空格。CHAR适合存储很短的字符串,或所有值都接近同一长度。
例如,CHAR适合存储密码的md5值,因为它是定长的。对于经常变更的数据,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
4.blob和text类型
两者都是为存储很大的数据而设计的字符串数据类型,分别采用二进制和字符方式存储。
5.日期,时间类型
mysql能存储的最小时间粒度为秒。
DATETIME:这个类型能保存大范围的值,从1001年到9999年,精度为秒,它把日期和时间封装到格式为YYYYMMDDHHMMSS的整数中,与时区无关,使用8个字节的存储空间。
TIMESTAMP:这个类型保存了从1970年1月1日0时以来的秒数。它和unix时间戳相同。它使用4个字节储存,因此范围比DATETIME小很多,只能表示1970年到2038年。TIMESTAMP显示的值与时区有关。
创建高性能的索引
索引可以包含一个或多个列的值。如果索引包含多个列,那列的顺序十分重要,因为mysql只能高效的使用索引的最左前缀列。
最常见的B-Tree索引,按照顺序存储数据,所以mysql可以做order by和group by操作。因为数据是有序的,所以B-Tree也会将相关的列值都存储在一起。最后,因为索引中存储了实际的值,所以某些查询只使用索引,就能够完成全部查询。
策略:
1.独立的列:索引列不能是表达式的一部分,也不能是函数的参数。比如,
select id from a where id+1=5
select .... where TO_DAYS(CURRENT_DATE)-TO_DAYS(date_col)<=10
应该养成简化where条件的习惯,始终将索引列单独放在比较符号的一侧。
2.前缀索引:索引开始的部分字符。
对于像BLOB,TEXT这种很长的列,必须使用前缀索引。因为mysql不允许索引这些列的完整长度。
因此建立前缀索引的关键是,选择足够长的前缀,以保证较高的选择性,同时又不能太长。
前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。为了找出这个足够长度,需要找到最常见的值的列表,然后和最常见的前缀列表进行比较。例如

可以看到每个值都在45到65之间,区分度不好。下面取3个前缀字符

这次区分度就要好点了,下面继续增加前缀长度,最后发现前缀长度为7时比较合适

计算合适前缀长度的另一个方法是计算完整列的选择性,并使前缀的选择性接近于完整列的选择性,具体的

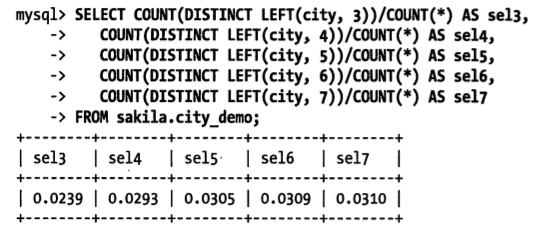
3.多列索引
一个常见的错误是,为每个列创建一个单独的索引,或按照错误的顺序创建多列索引。
关于索引列的顺序,正确的顺序依赖于使用该索引的查询,同时还要考虑是否满足排序和分组的需要。
一个经验:将选择性最高的列放在索引的最前列。这个经验在不需要考虑排序和分组的时候效果很好。这时候索引的作用只是在优化where条件的查找。
事实上,性能不只是依赖于所有索引列的选择性,也和查询条件的具体值有关,也就是和值分布有关,这和前面说的选择最佳前缀长度需要考虑的地方一样。换句话说,可能需要根据那些运行频率最高的查询来调整索引列的顺序。
使用索引扫描排序
mysql有两种方式生成有序结果,通过排序操作或按索引顺序扫描。如果explain出来的type列的值为index,说明使用了索引扫描做排序。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接的下一条记录。但如果索引不能覆盖查询所需的全部列,那就不得不每扫描一条索引记录就回表查询一次对应的行。这基本上都是随机的io.因此按索引顺序读取数据的速度通常比顺序的全表扫描慢,尤其是在io密集型的工作负载中。
mysql可以使用同一个索引既满足排序,又用于查找行。因此,如果可能,设计索引时应该尽可能的满足这两种任务最好。
只有当索引的顺序和order by子句的顺序完全一致,并且所有列的排列方向都一样时,mysql才能使用索引对结果排序。
如果查询需要关联多张表,则只有当order by子句引用的字段全部为第一个表时,才能使用索引做排序。
order by子句和查找性查询的限制是一样的,需要满足索引的最左前缀的要求,否则,mysql都需要执行排序操作。
有一种情况可以不满足索引的最左前缀要求,依然可以使用索引排序。那就是当前导量为常数时。例如
在一个表上,建立索引(a,b,c)。
select ... where a=“2014-12-21” order by b,c.
这时索引的第一列被指定为常数,可以使用索引。下面的也可以使用索引
select ... where a>"2014-12-21" order by b
select ... where a>"2014-12-21" order by a,b
这两个刚好用了索引的前缀,所以也可以。
下面是一些不能使用索引进行排序的查询
select ... where a="2014-12-21" order by b DESC,c ESC
查询使用了两种不同的排序方向,但是索引列都是正序排序的。
select ... where a="2014-12-21" order by b,d
引用了一个不在索引中的列
select ... where a="2014-12-21" order by c
where和order by中的列无法组成索引的最左前缀,因为跳过了b这个列
select ... where a>"2014-12-21" order by b,c
第一列是范围查询
select ... where a>"2014-12-21" and b in(1,2) order by c
b列上有多个等于条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号