
Nifi:初识nifi
写在前面:
第一次接触这一系统的时候,只有github上的一坨源码和官方的英文文档,用起来只能说是一步一个坑,一踩一个脚印,现在回想那段血泪史,只想 ***,现在用起来算是有了一些经验和总结,这里就做一下记录。
对于Nifi的认知
Nifi是什么
个人一直觉得,当我们首次接触某个新东西时,不论是否要学习它,应该先对这个东西有个清晰的定义边界,比如我们学习tomcat,我们要知道它是个服务容器,主要的任务边界就是对JavaWeb的服务提供支持,所以对于小白入手Nifi,我们应该首先搞清楚它是什么。
先来介绍一下这个东西的背景吧;
2006年,Nifi由M国国家安全局(NSA)的Joe Witt创建,2015年7月20日,Apache 基金会宣布Apache NiFi顺利孵化成为Apache的顶级项目之一。NiFi初始的项目名称是Niagarafiles,当NiFi项目开源之后,一些早先在NSA的开发者们创立了初创公司Onyara,Onyara随之继续NiFi项目的开发并提供相关的支持。Hortonworks公司收购了Onyara并将其开发者整合到自己的团队中,形成HDF(Hortonworks Data Flow)平台。2018年Cloudera与Hortonworks合并后,新的CDH整合HDF,改名为Cloudera Data Flow(CDF),并且在最新的CDH6.2中直接打包,参考《0603-Cloudera Flow Management和Cloudera Edge Management正式发布》,而Apache NiFi就是CFM的核心组件。
上面这一坨花里胡哨的组织、协议、文献, 其实不用那么在意,只需要知道Apache是啥就够了。总之上面那坨介绍帮我们解决了第一个问题,
即:这玩意的全称叫做 Apache-Nifi,它的第一任爹是M国国安局(根儿正苗红), 现在是Apache的一个顶级开源项目,最终这个Nifi是一个软件成品,并且有专门的团队在维护它,运营它。
Nifi能干什么
了解完它的族谱、性质,下面就是个重头戏,Nifi能干什么;
Apache NiFi 是为数据流设计,它支持高度可配置的指示图的数据路由、转换和系统中介逻辑,支持从多种数据源动态拉取数据。简单地说,NiFi是为自动化系统之间的数据流而生。 这里的数据流表示系统之间的自动化和受管理的信息流。 基于WEB图形界面,通过拖拽、连接、配置完成基于流程的编程,实现数据采集、处理等功能。
上面这段话,写的很专业、很术语,翻译过来无非就是,Nifi是一个专门用来流转、处理数据的高级分发系统。说白了,就是用来倒腾数据。
举一个例子:当一个企业或者一个组织,大多数业务都采用信息化的时候,势必就要使用各式各样的软件系统(人事管理系统、财务管理系统、报表管理系统、物流管控系统等等),不同的软件系统来自于不同的厂家,它们设计的初衷就是各自为政,只负责自己的业务范围。现在用户需要想把各个业务块的数据整合(比如我想把财务、人事、考勤啥的串起来,方便统一查阅、统计),就必然要经过从各个系统中导出数据、汇总数据、处理数据冲突,这些事如果让人来干,结果可想而知,而Nifi就能充分解决这种场景。
总的来说,Nifi就是一个数据接入、处理、清洗、分发的系统(基于Web方式工作,后台在服务器上进行调度)。
Nifi的基本架构
nifi的核心概念
1、NiFi的基本设计理念是基于数据流的编程 Flow-Based Programming(FBP)。简单点理解就是:将数据看作水管中的水,它是顺着某个流程管道流动,在这中间,可以在任意节点处堵截这个“水流”,并对它进行改造,然后放回管道继续向下流去。
以下是Nifi的一些术语对应的FBP概念:
| NiFi术语 | FBP术语 | 描述 |
|---|---|---|
|
FlowFile |
Information Packet |
FlowFile表示在系统中移动的每个对象,对于每个对象,NiFi跟踪 key/value 属性字符串的映射及其相关的零个或多个字节的内容。 |
| FlowFile Processor |
Black Box |
处理器实际上执行工作。在[eip]术语中,处理器正在对系统之间的数据路由,转换或中介进行某种组合。处理器可以访问给定FlowFile及其内容流的属性。处理器可以在给定的工作单元中对零个或多个FlowFile进行操作,并提交工作或回滚。 |
| Connection | Bounded Buffer |
Connections提供处理器之间的实际链接。它们充当队列并允许各种进程以不同的速率进行交互。这些队列可以动态优先化,并且可以在负载上具有上限,从而实现反压。 |
| Flow Controller | Scheduler |
流控制器维护流程如何连接和管理所有流程使用的线程及其分配的知识。Flow Controller充当促进处理器之间FlowFiles交换的代理。 |
|
Process Group |
subnet |
进程组是一组特定的进程及其连接,可以通过输入端口接收数据并通过输出端口发送数据。以这种方式,进程组允许仅通过组合其他组件来创建全新组件。 |
2、应用的方式是:将处理数据的工序做成黑盒处理器,由多个处理器经过连接管道串成一个流程,数据逐个处理器最终以想要的形式流向目的地。
数据进入一个节点(处理器),由该节点(处理器)对数据进行处理,根据不同的处理结果将数据路由到后续的其他节点(处理器)进行处理。这是NiFi的流程比较容易可视化的一个原因。
nifi的基本架构
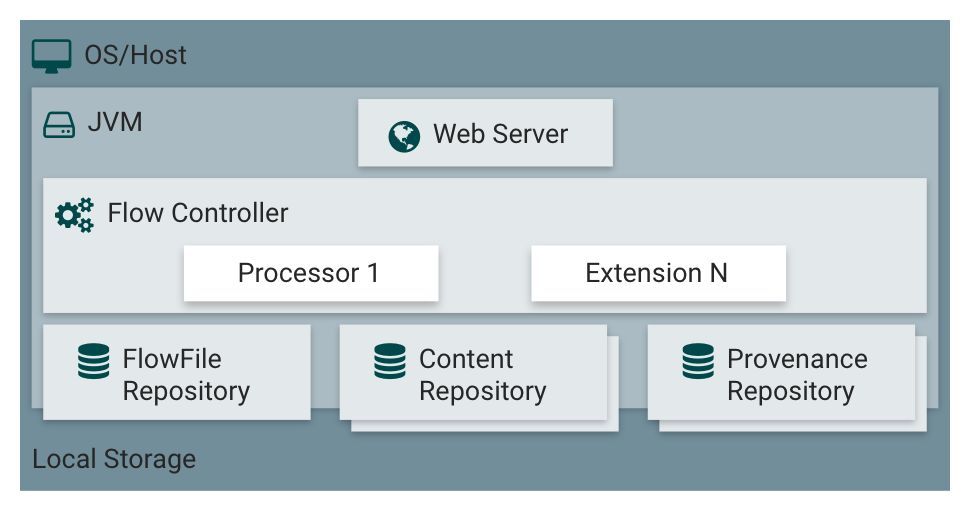
Nifi说白了也是一个Java程序,它需要基于JVM的一套运行环境。
1.Web Server
直接面向用户的页面及页面的交互,承载NiFi基于HTTP的命令和控制API。就是一套完备的Web应用
2.Flow Controller
是NiFi的核心之一,执行具体操作的大脑,负责从线程资源池中给Processor分配可执行的线程,以及其他资源管理调度的工作。管控着整个nIfi的大后方
3.FlowFile Repository
负责保存在目前活动流中FlowFile的状态,其功能实现是可插拔的。默认的方式是通过一个存储在指定磁盘分区的持久预写日志(WAL),来实现此功能。
4.Content Repository
负责保存在目前活动流中FlowFile的实际字节内容,其功能实现是可插拔的。默认的方式是一种相当简单的机制,即存储内容数据在文件系统中。多个存储路径可以被指定,因此可以将不同的物理路径进行结合,从而避免达到单个物理分区的存储上限。
5.Provenance Repository
负责保存所有跟踪事件数据,同样此功能是可插拔的,并且默认可以在一个或多个物理分区上进行存储,在每个路径下的事件数据都被索引,并且可被查询。
nifi的性能
NiFi旨在充分利用底层服务器的能力,最大化使用CPU和磁盘这种资源特别有优势。
对于IO:
期望的吞吐或时延与实际情况可能会存在很大的差异,这取决于系统的配置方式。
鉴于大多数主要NiFi子系统都是可插拔式的,性能取决于部署实施的方式。对于通用需求建议使用开箱即用的默认实现。使用本地磁盘对于所有子系统都可以持久化保存数据,从而保证交付。保守一点假设一台典型的服务器上的一般磁盘或者RAID卷大约每秒50MB的读写速率。则NiFi中的较大类型的数据流可以达到每秒100MB或者更高的吞吐。这是因为添加到NiFi的每个物理分区和content repository会呈线性增长。这将在FlowFile repository和provenance repository的某个点上出现瓶颈。我们计划在搭建时提供一个基准测试和性能测试模板,允许用户轻松测试他们的系统并确定瓶颈在哪里。此模板还应使系统管理员可以轻松进行更改并验证其影响。
对于CPU:
Flow Controller充当引擎,指示特定Processor何时被赋予执行线程。Processor被设计为一旦执行任务完成立即返回线程。Flow Controller有一个配置项,用以表明它维护的各个线程池的可用线程。理想的线程数取决于服务器的CPU核的数量,系统是否正在运行其他服务,以及flow中的处理性质。对于典型的IO很重的flow,使许多线程可用是合理的。
对于内存:
NiFi运行在JVM中,因此受限于JVM提供的内存空间。JVM的GC对于限制总实际堆大小以及优化应用程序运行时间是一个非常重要的因素。定期阅读相同内容时,NiFi作业可能是I/O密集型的。配置足够大的磁盘以优化性能。
Nifi的扩展性:
Nifi本身即为可扩展而生,扩展点包括:处理器,控制器服务,报告任务,优先级排序器和用户界面。
1.类装载器隔离
对于任何基于组件的系统,随着规模的扩张,组件之间的依赖会越来越错综复杂。为了解决这个问题,NiFi通过提供自定义类装载器模型,来确保每个扩展组件之间的约束关系被限制在非常有限的程度。因此,在创建扩展组件时,就不用再过多关注其是否会与其他组件产生冲突。
2.Site-to-Site通信协议
NiFi实例之间的首选通信协议是NiFi Site-to-Site(S2S)协议。S2S可以轻松,高效,安全地将数据从一个NiFi实例传输到另一个实例。NiFi客户端库可以轻松构建并捆绑到其他应用程序或设备中,以通过S2S与NiFi进行通信。S2S中支持基于socket的协议和HTTP(S)协议作为底层传输协议,使得可以将代理服务器嵌入到S2S通信中。
Nifi的伸缩性:
1.横向扩展(集群)
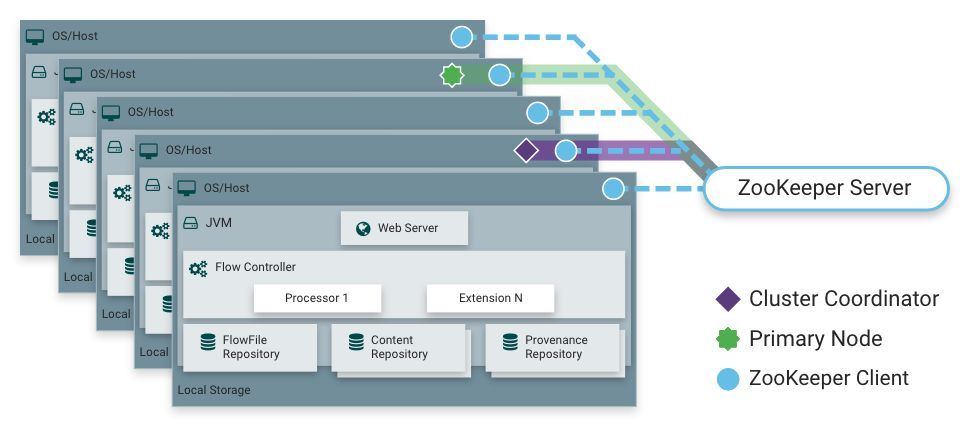
从NiFi 1.0版本开始,NiFi采用Zero-Master集群模式。NiFi集群中的每个节点都对数据执行相同的任务,但每个节点都运行在不同的数据集上。Apache ZooKeeper选择其中一个节点作为集群协调器,故障转移由ZooKeeper自动处理。所有集群节点都会向集群协调器报告心跳和状态信息。集群协调器负责断开和连接节点。作为DataFlow管理器,您可以通过集群中任何节点的UI与NiFi集群进行交互。您所做的任何更改都会复制到集群中的所有节点,从而允许多个入口点进入集群。
如上所述,NiFi可以通过将许多节点聚集在一起以集群的方式实现横向扩展。如果单节点被配置为每秒处理数百MB的数据,则集群方式可以达到每秒处理GB级别。这就带来了NiFi与其获取数据的系统之间的负载均衡和故障转移的挑战。使用基于异步排队的协议(如消息服务,Kafka等)可以提供帮助。使用NiFi的“site-to-site”功能也非常有效,因为它是一种协议,允许NiFi和客户端(包括另一个NiFi集群)相互通信,共享有关加载的信息,以及交换特定授权的数据端口。
2.放大和缩小
NiFi还可以非常灵活地放大和缩小。从NiFi框架的角度来看,如果要增加吞吐,可以在配置时增加“Scheduling”选项卡下processor的并发任务数。这允许更多进程同时执行,从而提供更高的吞吐。 另一方面,您可以完美地将NiFi缩小到适合在边缘设备上运行,因为硬件资源有限,所需的占用空间很小。要专门解决第一英里数据收集挑战和边缘用例,您可以使用MiNiFi,参考:https://cwiki.apache.org/confluence/display/NIFI/MiNiFi
1、Nifi:基本认识
2、Nifi:基础用法及页面常识
3、Nifi:ExcuseXXXScript组件的使用(一)
4、Nifi:ExcuseXXXScript组件的使用(二)
5、Nifi:ExcuseXXXScript组件的使用(三)
6、Nifi:自定义处理器的开发
7、Nifi:Nifi的Controller Service

 浙公网安备 33010602011771号
浙公网安备 33010602011771号