
Java的垃圾回收机制及算法
写在前面:
该系列文章,主要是为了深入学习Java完成的一条链,推荐阅读的整体顺序为:Java的内存模型(根源),一个java文件被执行的历程,一个Java类的加载,Java的垃圾回收机制及算法,Linux(六):系统运维常用命令 和 Java程序运行状态的监控(实用,定位Java程序问题)
Java的垃圾回收机制
前面的已经说过关于 Java在内存中的内存划分(Java的内存模型),一个java文件执行的流程、一个Java类如何被加载,本着有始有终的原则,下面该说一下 如何 “ 死亡 ”。
Java的编译流程已经提过了,其实更多的就是类+对象+内存,就是将程序员抽象的类文件,加载到内存区,形成一个个的对象,对象可以极端的理解为就是内存中的一部分,内存划分好块之后,对象都在堆中创建,其中一个对象,便是堆区中的一块内存。
随着程序的运行,各种套娃的逻辑,new的使用,数据的转存等等,都会让堆内的对象递增,这就涉及一个问题,堆内的内存是有限的,对象如何只是不停的增加,早晚会爆炸,也就是常说的堆栈溢出;最经典就是C++,习惯写C++的小伙伴肯定知道,每次创建对象,都要想着析构,因为C++是不会自己清除无效对象的,它的内存空间就会不停的增加,只有研发人员自发的去释放掉,这样就要求写C++的研发要时刻牢记内存的释放。
但是Java就不需要,我们只需要无脑的new new new ,套娃套娃套娃,原因就是Java有一套自动的对象销毁机制,也叫垃圾回收机制,这也是学习JVM,以及各种面试都会问到的点。
通常要聊Java的垃圾回收机制,需要搞清除三个问题:
- 哪些内存会被回收清理
- 怎样回收清理
- 什么时候会被回收清理
哪些内存(对象)会被回收清理
之前说过,在java中,万物皆对象,而对象存在于堆内存中,要说哪些对象会被清除,其实可以理解为,哪些对象已经“死了”。也就是说哪些对象已经不再被程序需要,不再被调用,这里判断对象是否需要被回收,一般是两种算法:引用计数器算法和可达性算法
引用计数器法
原理其实很简单,给运行的对象添加一个引用计数器,每当有一个地方引用它时,计数器+1;当引用失效时,计数器就-1,任何时刻计数器为0的对象,就视作不可能再被使用。这一种方式,实现简单,逻辑也清晰,大部分的情况下,它都可以达到很好的效果,尽管这样,计数器算法还是存在但是的,但是它无法解决循环引用的场景,这也是主流Java虚拟机没有选用这一算法的原因。
说一般存在于:虚拟机栈、java方法区、本地方法区的对象都是可达的,也就是GCRoots对象
1、方法区静态属性引用的对象 全局对象的一种,Class对象本身很难被回收,回收的条件非常苛刻,只要Class对象不被回收,静态成员就不能被回收。
2、方法区常量池引用的对象 也属于全局对象,例如字符串常量池,常量本身初始化后不会再改变,因此作为GC Roots也是合理的。
3、方法栈中栈帧本地变量表引用的对象 属于执行上下文中的对象,线程在执行方法时,会将方法打包成一个栈帧入栈执行,方法里用到的局部变量会存放到栈帧的本地变量表中。只要方法还在运行,还没出栈,就意味这本地变量表的对象还会被访问,GC就不应该回收,所以这一类对象也可作为GC Roots。
4、JNI本地方法栈中引用的对象 和上一条本质相同,无非是一个是Java方法栈中的变量引用,一个是native方法(C、C++)方法栈中的变量引用。
5、被同步锁持有的对象
怎样回收清理
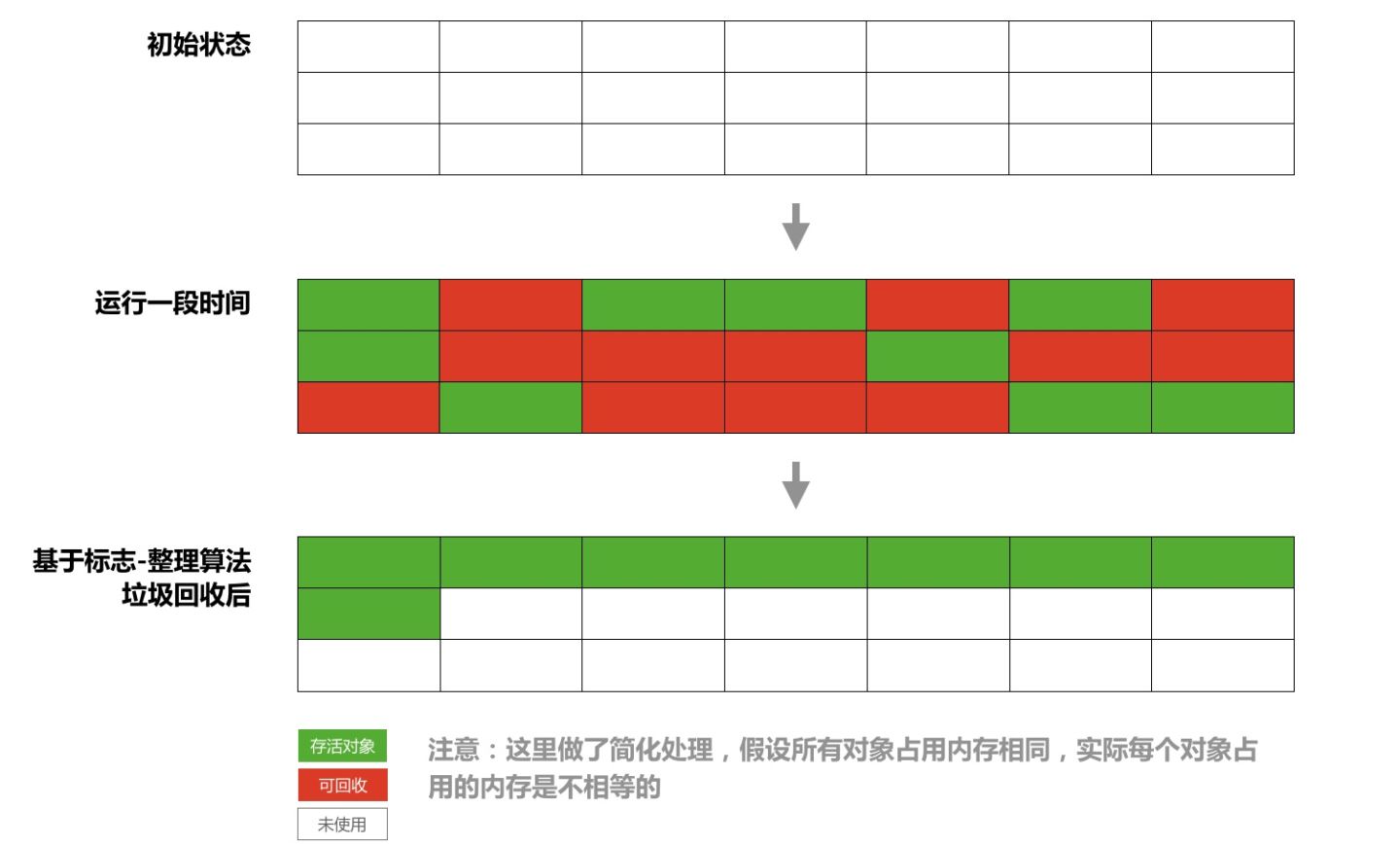
该算法很简单,使用通过可达性分析分析方法标记出垃圾,然后直接回收掉垃圾区域。简单粗暴,即标记删除的对象,对其进行内存回收;它的一个显著问题是一段时间后,内存会出现大量碎片,导致虽然碎片总和很大,但无法满足一个大对象的内存申请,从而导致 OOM,而过多的内存碎片(需要类似链表的数据结构维护),也会导致标记和清除的操作成本高,效率低下。

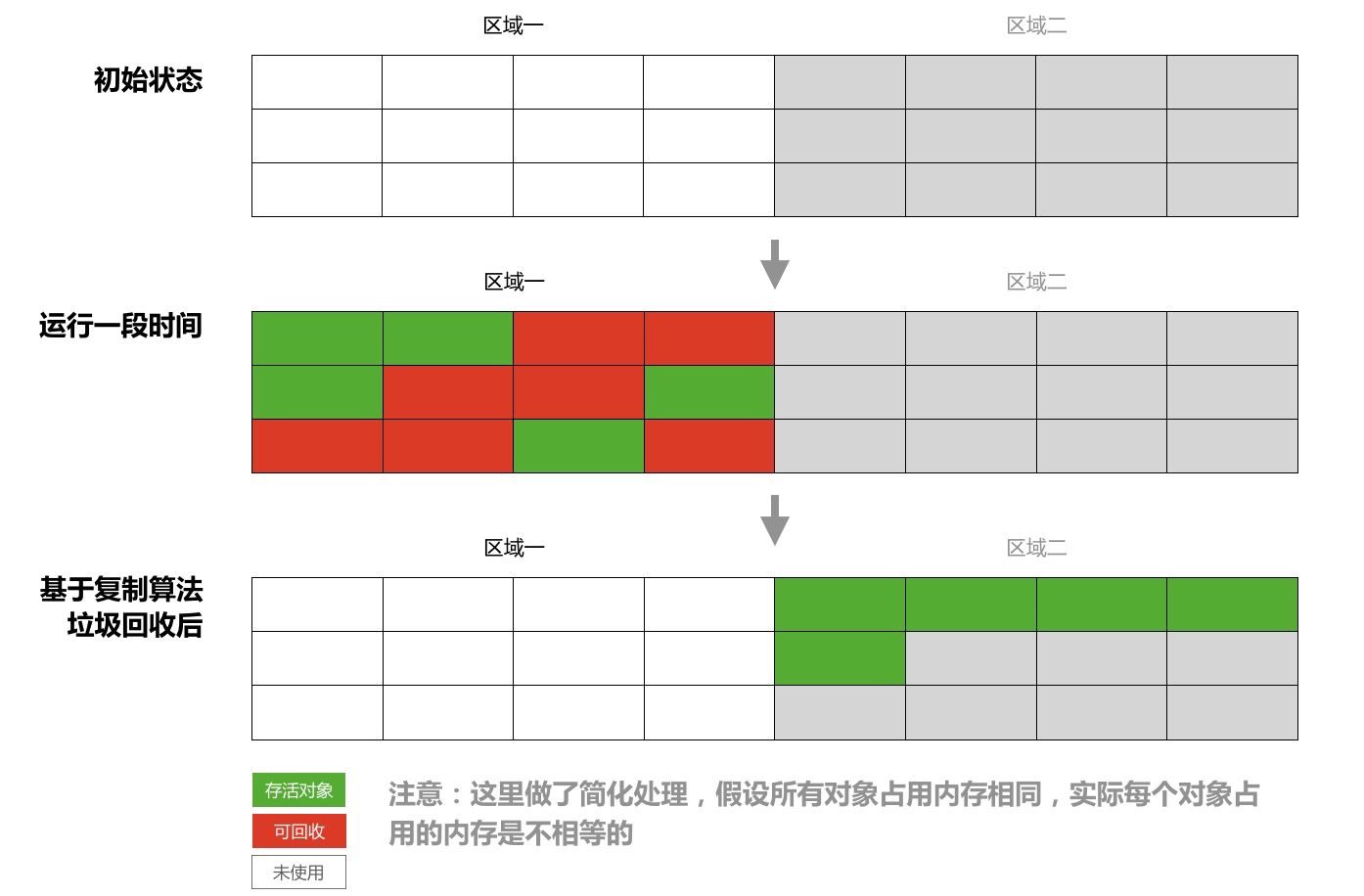
为了解决标记清除算法的效率问题,有人提出了复制算法。它将可用内存一分为二,每次只用一块,当这一块内存不够用时,便触发 GC,将当前存活对象复制(Copy)到另一块上,以此往复。这种算法高效的原因在于分配内存时只需要将指针后移,不需要维护链表等。但它最大的问题是对内存的浪费,使用率只有 50%。
但这种算法在一种情况下会很高效:Java 对象的存活时间极短。据 IBM 研究,Java 对象高达 98% 是朝生夕死的,这也意味着每次 GC 可以回收大部分的内存,需要复制的数据量也很小,这样它的执行效率就会很高。
在实际的Java程序中,大部分的对象存活周期都较短,基本上创建完,紧接着处理完数据就被丢弃了,大部分 Java 对象是朝生夕死的,所以我们将内存按照 Java 生存时间分为 新生代(Young) 和 老年代(Old),前者存放短命僧,后者存放长寿佛,当然长寿佛也是由短命僧升级上来的。然后针对两者可以采用不同的回收算法,比如对于新生代采用复制算法会比较高效,而对老年代可以采用标记-清除或者标记-整理算法。这种算法也是最常用的。
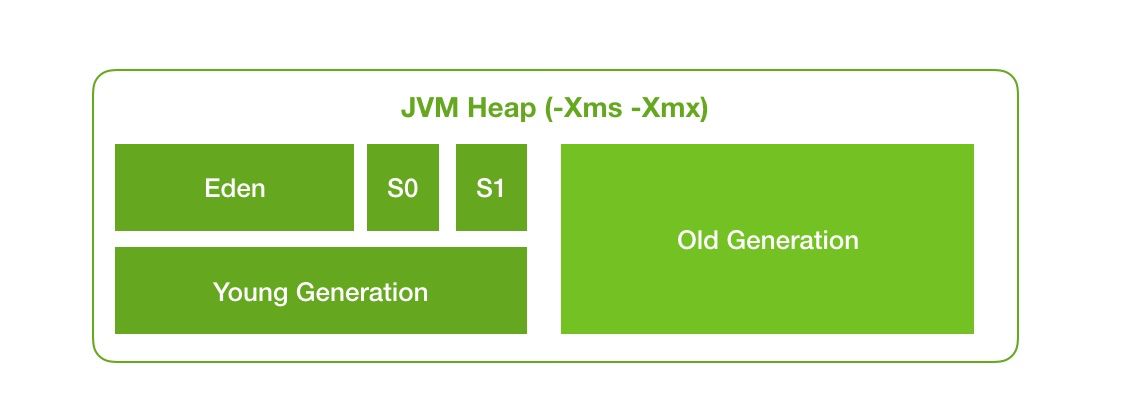
将内存分代后的 GC 过程一般类似下图所示:
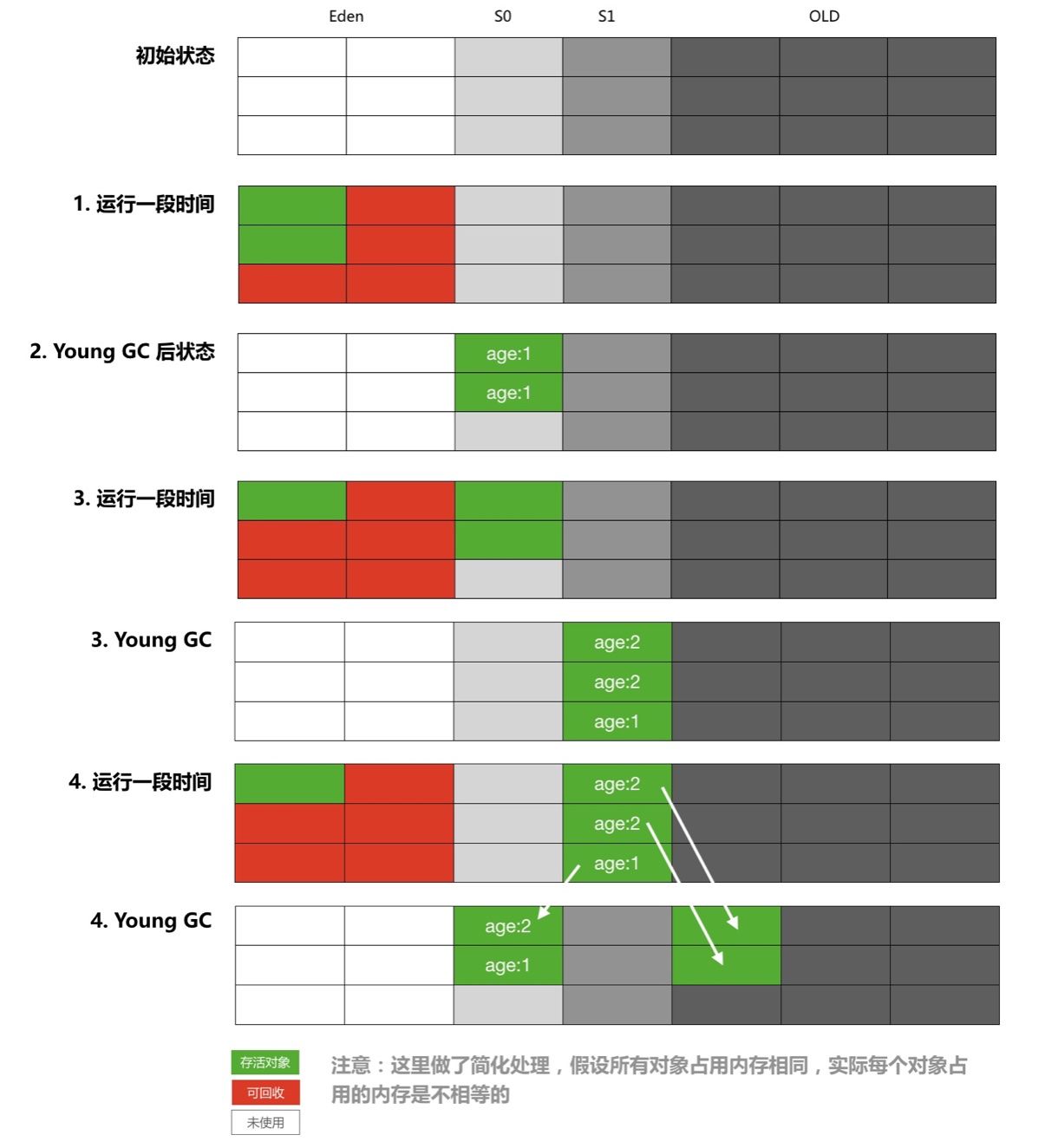
-
-
当
Eden区满,触发 Young GC,此时将Eden中还存活的对象复制到S0中,并清空Eden区后继续为新的对象分配内存 -
当
Eden区再次满后,触发又一次的 Young GC,此时会将Eden和S0中存活的对象复制到S1中,然后清空Eden和S0后继续为新的对象分配内存 -
每经过一次 Young GC,存活下来的对象都会将自己存活次数加1,当达到一定次数后,会随着一次 Young GC 晋升到
Old区 -
Old
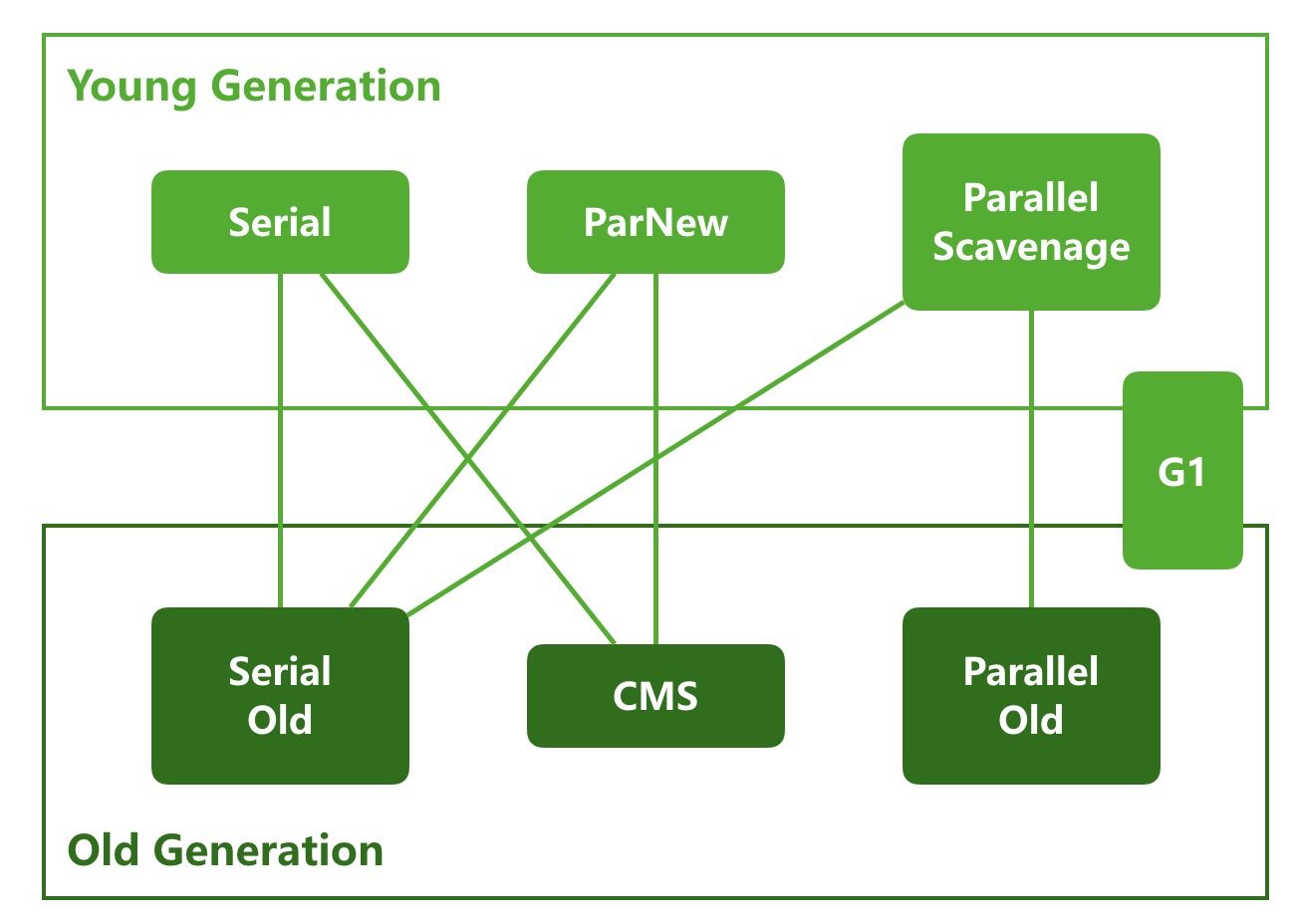
-
Serial GC,串行,单线程的收集器,运行 GC 时需要停止所有的用户线程,且只有一个 GC 线程
-
Parallel GC,并行,多线程的收集器,是 Serial 的多线程版,运行时也需要停止所有用户线程,但同时运行多个 GC 线程,所以效率高一些
-
什么时候会被回收清理
-
-
Serial Old 和 Parallel Old 在
Old 区是在 Young GC 时预测Old 区是否可以为 young 区 promote 到 old 区 的 object 分配空间,如果不可用则触发 Old GC。这个也可以理解为是Old区满时。 -
CMS GC 是在
Old 区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号