
Linux(六):系统运维常用命令
实际的生产环境下,不论是研发还是运维,或多或少的得面对在linux上定位问题这个关卡,这里介绍一下linux环境下一些状态查看常用的命令。
系统资源监控
总体资源占用情况查看
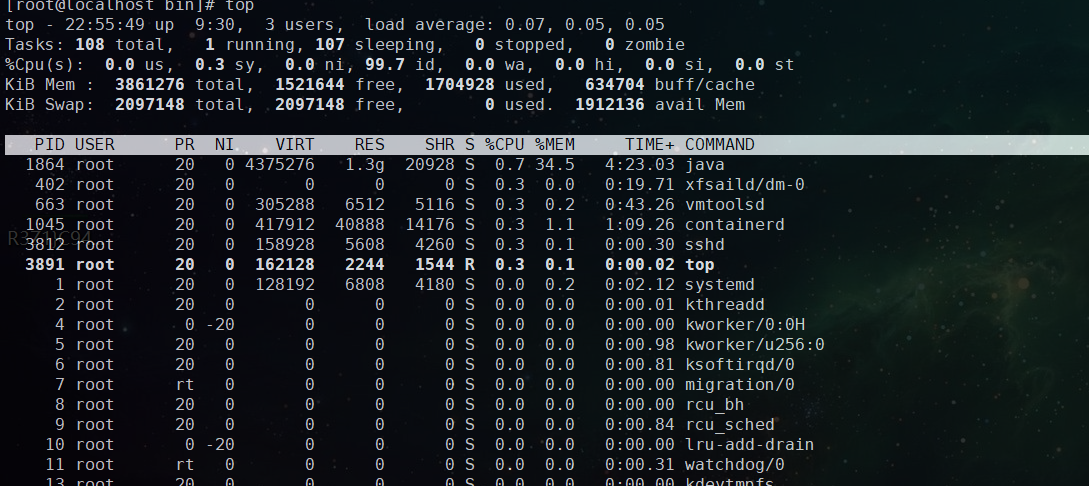
命令:top
像windows一样,linux也有一个“进程管理”,可以在命令行执行 top ,就可以整体的查看当前机器的资源及进程情况。
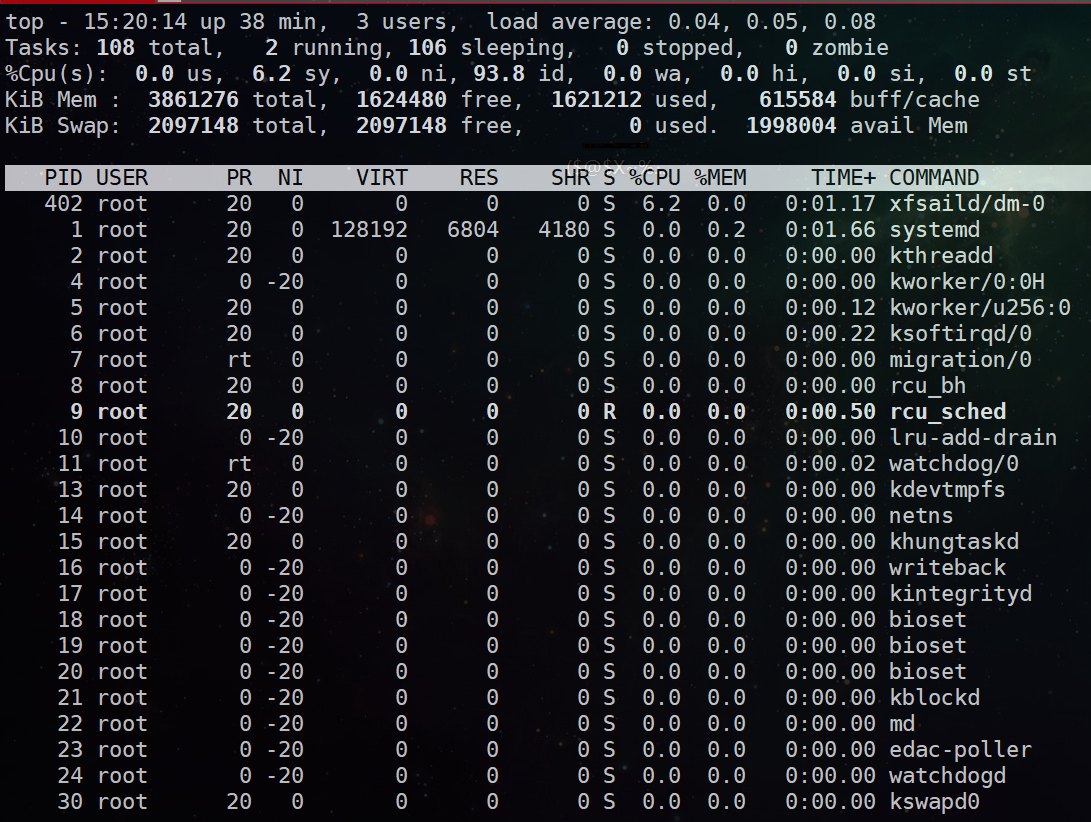
这里第一行 (top) 显示的信息包含:
系统时间:19:27:01
运行时间:up 54 min,
当前登录用户: 1 user
负载均衡(uptime) load average: 0.02, 0.03, 0.00
average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行 (Tasks)显示的当前的进程整体统计
第三行 (%CPU)是CPU状态信息,具体为:
0.0%us【user space】— 用户空间占用CPU的百分比。
0.1%sy【sysctl】— 内核空间占用CPU的百分比。
0.0%ni【】— 改变过优先级的进程占用CPU的百分比
99.9%id【idolt】— 空闲CPU百分比
0.0%wa【wait】— IO等待占用CPU的百分比
0.0%hi【Hardware IRQ】— 硬中断占用CPU的百分比
0.0%si【Software Interrupts】— 软中断占用CPU的百分比
第四行 (KiB Mem)整体内存的状态,分别为总量,已用,空闲,缓存
第五行 (KiB Swap)交换区内存
最后是各进程的状况
这里说一下第四行和第五行,第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。
对于内存监控,也就是说我们对于内存的监控主要是看第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
命令:top -p [pid]
除了整体来看,我们也可以锁定单个进程的资源情况进行查看。
例如: top -p 1864

详细内容为
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S —进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
计算机端口关联进程查看
这里也是我们最经常用到的,不管是安装新应用,还是排查应用的进程情况,都需要一个去了解端口是否被占用,或者根据端口来拿到一个进程的pid。
命令:lsof -i: [端口号]
例如:lsof -i:22

这里,我们以查看22端口被监听的进程为例,这一就能得出,22这个端口被哪一进程监听,从而得到Pid等多个参数。
COMMAND 进程名称 | PID 进程标识符 | USER 进程所有者 | FD 文件描述符 | TYPE 文件类型 | DEVICE 指定磁盘名称|SIZE 文件大小 | NODE 索引节点 | NAME 打开文件的确切名称
有些系统可能并没有lsof命令,如果系统在互联网环境下,可以执行 yum install lsof 进行安装。
命令:netstat -tunlp | grep [端口号]
有些环境下的linux可能并没有安装lsof,并不支持lsof命令,我们又无法安装losf的时候,我们可以使用linux自带的netstat来定位。
例如: netstat -tunlp | grep 22

这里,根据netstat提供的信息,可以知道哪些进程在监听22端口,并且得知进程唯一标识pid 。
关于 netstat命令的其他参数这里不过多解释,可以自行某度,同样,若系统无该命令,可以使用 yum -y install net-tools 进行安装。
计算机内存状态查看
命令:free -g
除了前面的top可以查看内存的情况,也可以单独的查看当前linux内存的状况,那就是 free -g 命令
例如:free -g

详细字段解释为:
total:表示 总计物理内存的大小。
used:表示 已使用多少。
free:表示 可用内存多少。
Shared:表示多个进程共享的内存总额。
Buffers/cached:表示 磁盘缓存的大小。
这里对于内存的监控同top一样,我们还是主要关心 swap 这一栏。
命令:cat /proc/meminfo
确切地说,这个不能叫做命令,只是一个打开系统级参数文件的查看,proc目录下放着系统的一些资源情况的文件。
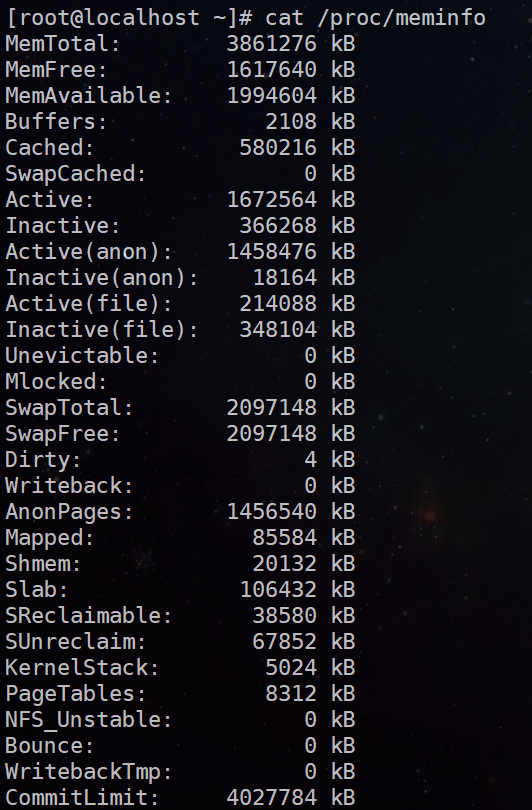
清空缓存:echo3 >/proc/sys/vm/drop_caches
当在Linux下频繁存取文件后,物理内存会很快被用光,当程序结束后,内存不会被正常释放,而是一直作为caching,一直被占用着,会导致上面的top以及free命令查看的内存计算不够准确,这时候我们可以通过执行 echo3 >/proc/sys/vm/drop_caches 来进行手动释放缓存。
关于清除缓存的详细细节可以看一下 https://blog.csdn.net/qq_36357820/article/details/79798788
计算机CPU状态查看
命令:cat /proc/cpuinfo
和上面的内存一样,这也是在proc这个目录下查看当前机器的cpu状况
例如:cat /proc/cpuinfo
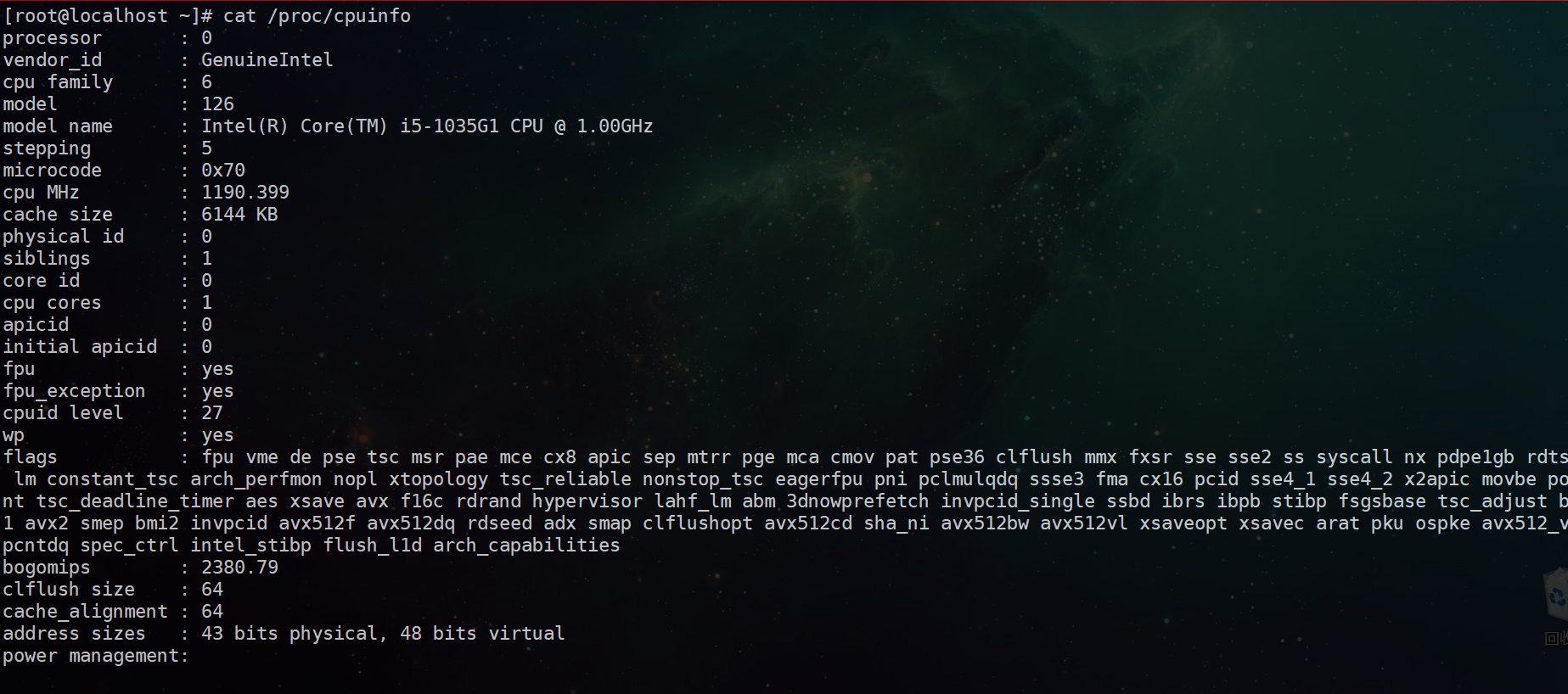
详细字段解释:
processor :系统中逻辑处理核的编号。对于单核处理器,则课认为是其CPU编号,对于多核处理器则可以是物理核、或者使用超线程技术虚拟的逻辑核
vendor_id :CPU制造商
cpu family :CPU产品系列代号
model :CPU属于其系列中的哪一代的代号
model name:CPU属于的名字及其编号、标称主频
stepping :CPU属于制作更新版本
cpu MHz :CPU的实际使用主频
cache size :CPU二级缓存大小
physical id :单个CPU的标号
siblings :单个CPU逻辑物理核数
core id :当前物理核在其所处CPU中的编号,这个编号不一定连续
cpu cores :该逻辑核所处CPU的物理核数
apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
fpu :是否具有浮点运算单元(Floating Point Unit)
fpu_exception :是否支持浮点计算异常
cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
flags :当前CPU支持的功能
bogomips :在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)
clflush size :每次刷新缓存的大小单位
cache_alignment :缓存地址对齐单位
address sizes :可访问地址空间位数
power management :对能源管理的支持,有以下几个可选支持功能:ts: temperature sensor
fid: frequency id control
vid: voltage id control
ttp: thermal trip
tm:
stc:
100mhzsteps:
hwpstate:
命令:uptime
如果再细致一点,查看当前系统的负载情况,可以使用 uptime来进行查看
例如:uptime

这里,第一项是当前时间,up 表示系统正在运行,5:53 是系统启动的总时间,最后是系统的负载load信息。
系统负载是处于可运行runnable或不可中断uninterruptable状态的进程的平均数。可运行状态的进程要么正在使用 CPU 要么在等待使用 CPU。
不可中断状态的进程则正在等待某些 I/O 访问,例如等待磁盘 IO。
有三个时间间隔的平均值。负载均值的意义根据系统中 CPU 的数量不同而不同,负载为 1 对于一个只有单 CPU 的系统来说意味着负载满了,而对于一个拥有
4 CPU 的系统来说则意味着 75% 的时间里都是空闲的。
计算机存储状态查看
命令:df -h
可以对整体的Linux进行一下磁盘整体使用情况的查看
例如:df -h
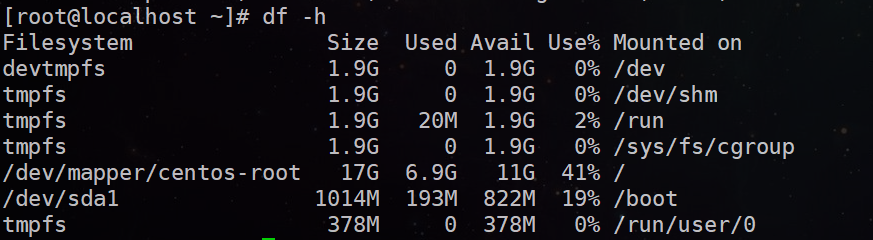
Filesystem:文件系统
Size: 分区大小
Used: 已使用容量
Avail: 还可以使用的容量
Use%: 已用百分比
Mounted on: 挂载点
此外,还有部分额外命令
df -hl:查看磁盘剩余空间
df -h:查看每个根路径的分区大小
du -sh [目录名]:返回该目录的大小
du -sm [文件夹]:返回该文件夹总M数
du -h [目录名]:查看指定文件夹下的所有文件大小(包含子文件夹)
杀死进程
命令:kill
杀死一个进程 ,在linux中我们使用kill命令,kill命令的基本格式是 kill [参数] [进程号],这里要说一下这个参数位置,这个参数可放kill的基本参数,具体这里就不多说了,可以自行去了解,另外可以放信号,信号的意思是向操作系统发送一个杀死进程的命令,并携带额外的信息,例如是强制杀死,还是由你系统稍后杀死。
kill命令可以带信号号码选项,也可以不带。如果没有信号号码,kill命令就会发出终止信号(15),这个信号可以被进程捕获,使得进程在退出之前可以清理并释放资源。也可以用kill向进程发送特定的信号。
例如我想强制杀死一个进程,立即执行,那信号值为9 即:kill -9 12342
实际应用:定位进程
找到PID
一般系统出现了问题(系统卡顿、程序缓慢、服务无响应……),我们可以通过各种手段去定位问题,使用最多的思路就是,根据全局的资源信息判断造成问题的进程是哪个,通过上面介绍的 top命令就可以看到整体的系统情况,从中找到资源占用最大的或者认为有问题的进程;
根据PID找到进程所在程序的位置
方式一: 命令 ps -aux | grep -v grep | grep [pid]
我们已经通过top 找到了PID,下面通过命令锁定进程1864进程。
ps -aux |grep -v grep|grep 1864

方式二:命令 ps -ef | grep [进程/程序关键字]
或者你事先知道你要定位的程序名称 使用 ps -ef | grep [进程/程序关键字] , 例如 我们想知道tomcat的进程
ps -ef | grep tomcat
这时候就能得到进程的基本信息

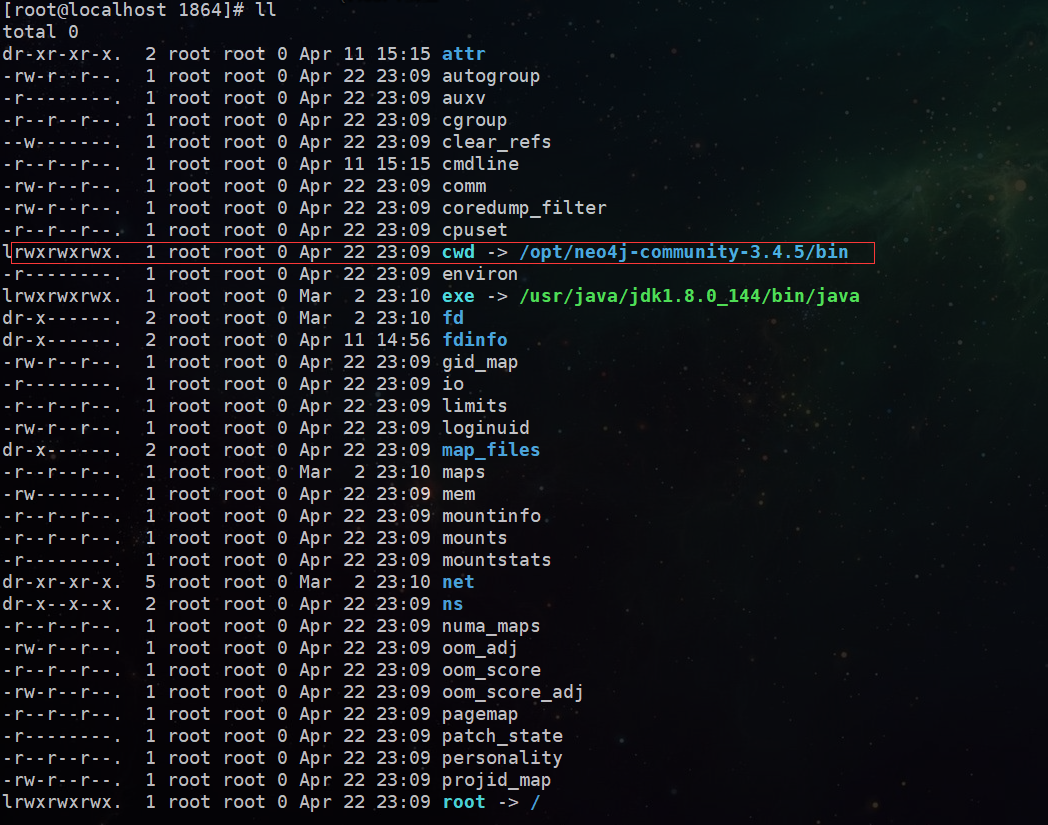
方式三: 查看 /proc/[PID] 目录
就像之前看内存一样,我们可以直接从 /proc目录下,查看当前运行进程的情况
cd /proc/1864
然后,通过ll命令查看
问题定位解决思路


 浙公网安备 33010602011771号
浙公网安备 33010602011771号