Block ciphers
Block Ciphers
notes from the open course provided by Stanford University: https://www.coursera.org/learn/crypto/home/module/2
What is block ciphers
A block cipher is made up of two algorithms, E and D. These are encryption and decryption algorithms. Both of these algorithms take N-bit plaintext as input and output the same number of bits as output.
So it maps N bits of inputs to N bits of outputs.
Block ciphers are typically built by iteration.
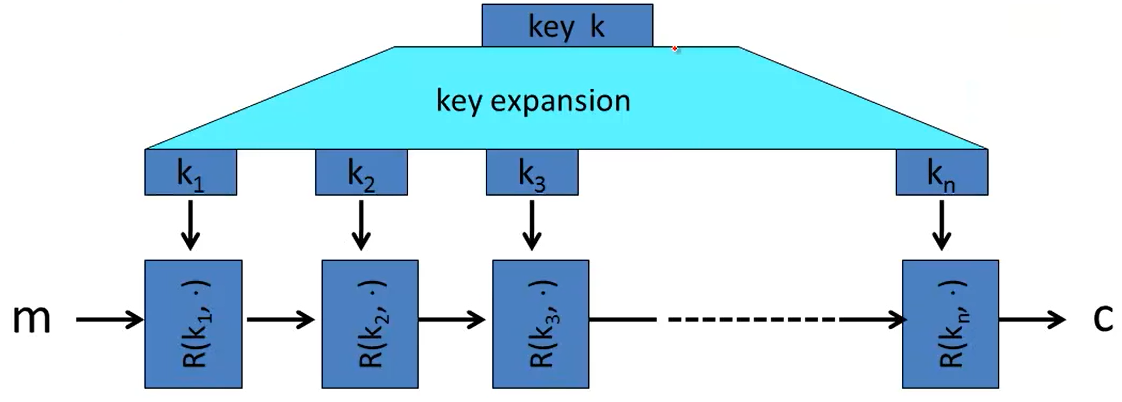
where the R(k, m) is called a round function.
Block ciphers are slower than stream ciphers, but we’ll see that we can do many things with block cipher that we couldn’t do very efficiently with constructions like RC4.
PRFs and PRPs
PRF is a pseudorandom function, which is defined over a key space, an input space, and an output space. It can be written as follows:
\(\mathcal{F}: K \times X\to Y\)
And the only requirement is that there’s an efficient way to evaluate the function.
For a pseudorandom function, we’re not requiring that they be invertible. We just need them to be evaluatable.
A related concept that more accurately captures what a block cipher is is pseudorandom permutation, PRP. So a PRP is defined over a key space and then just a set X. And what it does is it takes an element in the key space, an element of X, and outputs one element in X. It can be written as follows:
\(\mathcal{E}: K\times X\to X\)
The function E should be easy to evaluate, so there should be an algorithm to evaluate the function E.
Once we fix the key K, this function E will be one-to-one.
A PRP is also a PRF where X=Y and is efficiently invertible.
Let \(F: K\times X\to Y\) be a PRF, Funs[X, Y] be the set of all functions from X to Y, \(S_F=\{F(k, \cdot), k\in K\}\subset\) Funs[X, Y], be the set of all functions that function F traverse all keys from the key space.
Obviously, the size of Funs[X, Y] is \(|X|^{|Y|}\) and the size of \(S_F\) is |K|.
Def.: A PRF F is secure if a randomly selected function in Funs[X, Y] is indistinguishable from a random function in \(S_F\).
let:
f\(\gets\) Funs[X, Y] in a uniform distribution,
k \(\gets\) K in a uniform distribution
the adversary is capable of querying the challenger with a sequence of inputs, and the challenger will return the output from either random function f or PRF F(k, \(\cdot\)).
If F is a secure PRF, then the adversary can't tell the difference.
\(\mathcal{Intuition}\): even if you have a secure PRF, it's enough that on just one known input the output is not random, the output is fixed, and already the PRF is broken, even though you realize that everywhere else the PRF is perfectly indistinguishable from random.
Theorem.: If F: \(K\times \{0, 1\}^n\to \{0, 1\}^n\) is a secure PRF, then the following G: \(K\to \{0, 1\}^nt\) is a secure PRG:
\(G(k) = F(k, 0) || F(k, 1) || \cdots || F(k, t)\)
-
Proof(Roughly).
Since F is a secure PRF, it's indistinguishable from a truly random function f
\(F(k, 0) || F(k, 1) || \cdots || F(k, t)\) is indistinguishable from \(f(0) || f(1) || \cdots || f(t)\)\(\because\) f is a truly random function
\(\therefore\) f(0) is random, and f(1) is also independently random, and so on.
\(f(0) || f(1) || \cdots || f(t)\) is a random string.Therefore, \(F(k, 0) || F(k, 1) || \cdots || F(k, t)\) is indistinguishable from a random string.
Such construction is sometimes called "counter mode". The key property of such construction is parallel, which means it could reach a faster speed in a multi-processor system than the sequential PRG, such as RC4.
Data Encryption Standard
The core idea behind DES is the Feistel network.
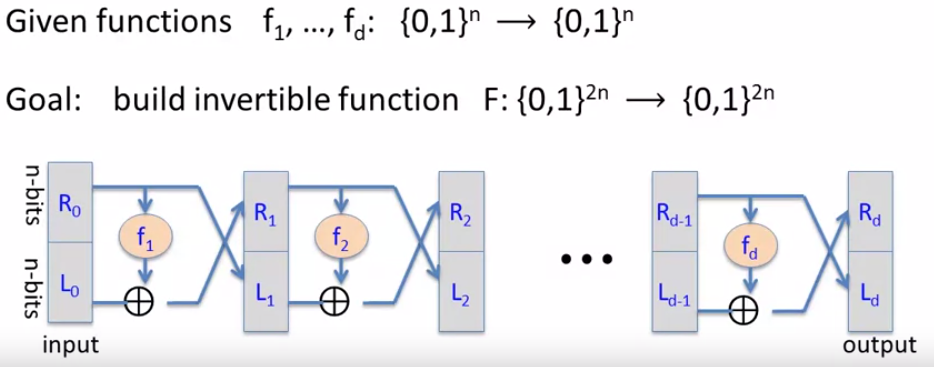
for all \(f_1, ..., f_d: \{0, 1\}^n\to \{0, 1\}^n\), the Feistel network is invertible.
Proof. construct inverse
Theorem.: let \(f: K\times \{0, 1\}^n\) be a secure PRF, then 3-round Feistel \(F: K^3\times \{0, 1\}^{2n}\to\{0, 1\}^{2n}\) is a secure PRP
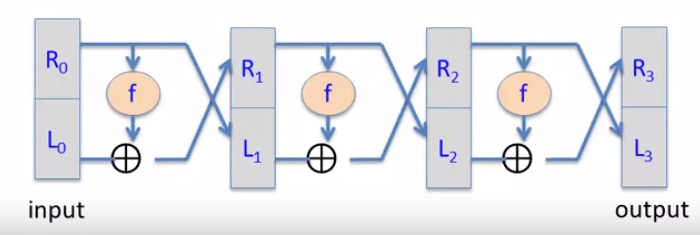
where the \(K^3\) means three independent keys.
DES: a 16 round Feistel Network, \(f_1, ..., f_{16}: \{0, 1\}^{32}\to \{0, 1\}^{32}, f_i(x)=F(k_i, x)\)

the structure of DES round function(i.e., the SPN(Substitution-Permutation) structure):
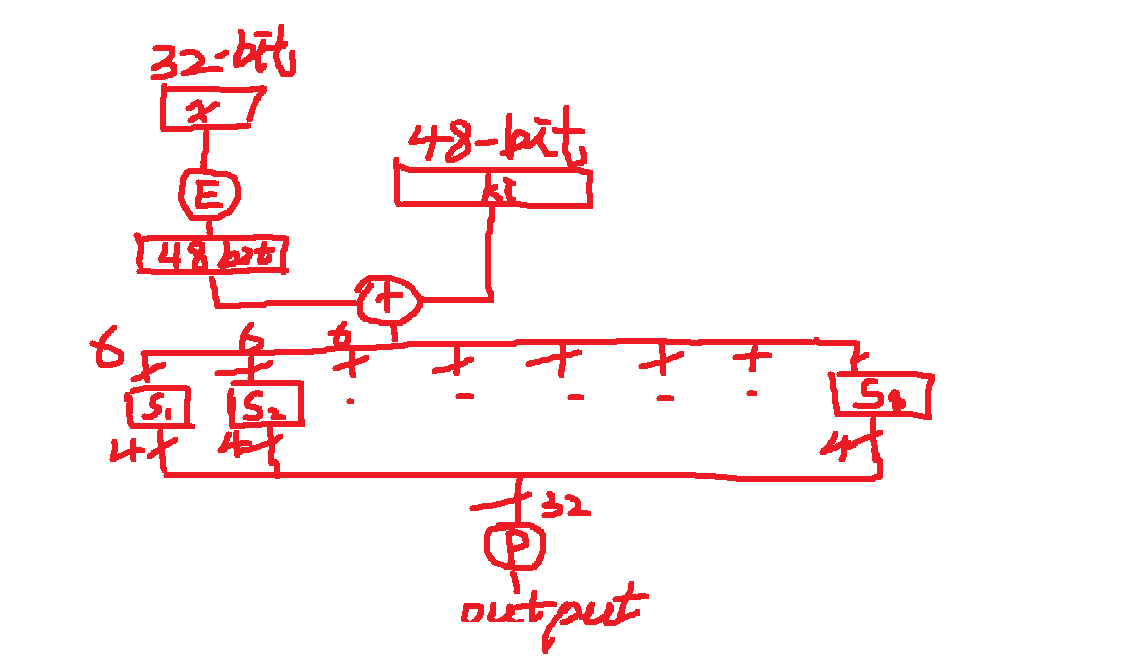
the key component of the round function is S boxes, a non-linear function implemented as a look-up table.
\(\mathcal{Note}\): The S box should never be a liner function.
Suppose we have a bad S-box, implemented as:
\(S_i(x_1, x_2, ..., x_6) = (x_2\oplus x_3, x_1\oplus x_4 \oplus x_5, x_1\oplus x_6, x_2\oplus x_3 \oplus x_6)\)
or written equivalently:
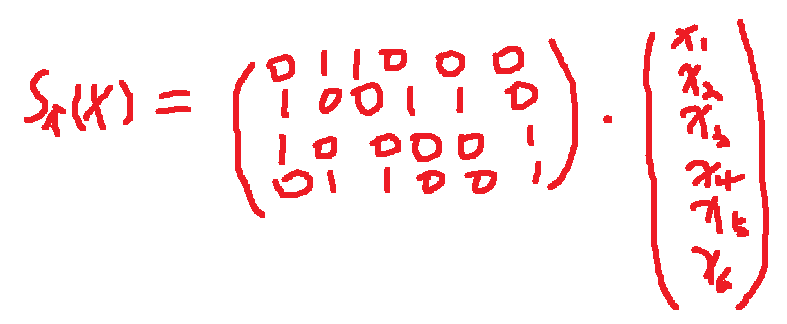 we say that $S_i$ is a linear function.
we say that $S_i$ is a linear function.
since the permutation is also a linear function, suppose a 4-bit permutation \(P, P(x): (b_0, b_1, b_2, b_3)^{-1} \to (b_2, b_1, b_3, b_0)^{-1}\), then such permutation can be written as:
*Then, the DES would be entirely linear, exists a matrix B, satisfy \(DES(K, m) = B\times(K, m)\):

If the DES is \(\mathrm{linear}\) function, then, \(DES(K, m_1)\oplus DES(K, m_2)\oplus DES(K, m_3) = B\times (K, m_1)\oplus B\times(K, m_2)\oplus B\times(K, m_3) = B\times (K\oplus K\oplus K, m_1\oplus m_2\oplus m_3)\)
\(DES(K, m_1)\oplus DES(K, m_2)\oplus DES(K, m_3) = DES(K, m_1\oplus m_2 \oplus m_3)\)
thus, DES is not a random function, since a random function will never satisfy this equality.
In fact, you just need 832 input-output pairs to recover the entire secret keys under a linear S-box construction. The DES is insecure even if the S-box is close to linear(i.e., linear at most of the time) (linear analysis attacks, or linear cryptanalysis).
Exhaustive Search Attacks
Goal: Given a few input-output pairs \(m_i, c_i, c_i = E(m_i, K), i = 1, 2, 3, ...\) find the certain key K.
how many input-output pairs required to find the key that does this map?
the answer is just one pair is enough to find the key.
Lemma: Suppose DES is an \(\mathcal{ideal}\) cipher(which means we're going to pretend the DES is made up of random invertible functions), then for every key K, DES implements a random invertible function.
Proof.
Since the size of key space is \(2^{56}\), we pretend the DES is a collection of \(2^{56}\) random invertible functions: \(\varpi_1, \varpi_2, ..., \varpi_{56}: \{0, 1\}^{64}\to \{0, 1\}^{64}\)
then \(\forall m, c\), to find key k mapping the m to c, s.t., \(c=DES(k, m)\), then the key is unique with probability \(1 - 1/256\approx 99.5\%\)
get the probability that the key k is NOT unique:
\(\Pr[\exists k'\ne k, c = DES(k, m) = DES(k', m)] \le \sum_{k'\in \{0, 1\}^{56}} \Pr[DES(k, m) = DES(k', m) = c]\)
\(\because \Pr[\forall k \in K, DES(k, m) = c] = 1/2^{64}\)
\(\therefore \sum_{k'\in \{0, 1\}^{56}} \Pr[DES(k', m) = c] = 2^{56}\times 1/2^{64} = 1/256\)
therefore, the probability that the key k is unique \(\Pr = 1 - \Pr[\exists k'\ne k, c = DES(k, m) = DES(k', m)] = 1 - 1/256\)
For two plain-cipher pairs, the key k mapping \((m_1, m_2) \to (c_1, c_2)\) is unique with probability \(1 - 1/2^{71}\).
DES-challenge: given two or three pairs of plaintext-ciphertext, find key \(k \in \{0, 1\}^{56}\) s.t. \(E(k, m_i)=c_i\), i = 1, 2, 3.
this challenge can be solved by essentially trying all possible keys.
- in 1997, the internet search, takes 3 months
- in 1998, the EFF machine(deep crack), takes 3 days
- in 1999, the combined search, takes 22 hours
- in 2006, the COPACABANA(120 FPGA), 7 days
therefore, 56-bit ciphers should not be used!
Strengthening the DES
#1. \(3DES((k_1, k_2, k_3), m) = E(k_3, D(k_2, E(k_1, m)))\)
Why not double DES? \(2DES((k_1, k_2), m) = D(k_2, E(k_1, m))\)
because it is vulnerable for meet in the middle attack
Meet in the Middle attack
given a brunch of input-output pairs \(M=m_1, ..., m_{10}\) and \(C=c_1, ..., c_{10}\),
to find the \(K=(k_1, k2)\) s.t. \(E(k_1, E(k_2, M)) = c_i\)
obviously the key also satisfy \(E(k_2, M) = D(k_1, C)\)
1st, build a table with \(2^{56}\) entries, mapping the key to the corresponding ciphertext, \(k_i\to E(k_i, M)\)
2nd, for all \(k\in \{0, 1\}^{56}\) do: if the D(k, C) is found in that table, then \(E(k_i, M) = D(k, C)\)
then we can get the key \(K=(k_i, k)\)
the time complexity is approximately \((2^{56} + 2^{56})\log{2^{56}} \lt 2^{63}\)
even 3DES has an attack that basically explores on \(2^{112}\) possible keys. but it is still secure enough to be standardized by the NIST.
#2. DESX
let \(E:K\times \{0, 1\}^n\to \{0, 1\}^n\) be a block cipher
Define EX as \(EX((k_1, k_2, k_3), m) = k_1\oplus E(k_2, k_3\oplus m)\)
the size of key space |K| = 2^{64 + 56 +64} = 2^{184}
however, the DESX can be cracked in 2^{120} computes.
Proof.
homework
Note that, the implementation of \(k_1\oplus E(k_2\oplus, m)\) or \(E(k_1, k_2\oplus m)\) does NOTHING for the security against exhaustive search attacks.
Proof.
homework
More attacks on block ciphers
#1. Side-channel attacks:
- measure the time to do enc/dec, or measure the power of enc/dec.
even use mask to mitigate the side-channel attacks, there still exists a differential analysis attack to extract the secret information. - cache side-channel attacks:
#2. Fault attacks:
computing errors in the last round exposed the secret key k
\(\mathcal{Note}\): do not even implement the crypto primitives by yourself.
because 1) you have to make sure there are no side-channel attacks on your implementation, 2) you have to make sure that the implementation is secure against fault attacks.
instead, you just use the standard library like the ones available in OpenSSL.
Linear and differential attacks
Goal: given many inp/out pairs, can recover the secret key k in less \(2^{56}\) times computes.(better than the exhaustive search)
lesson: A tiny bit of linearly in \(S_5\) lead to a \(2^{42}\) time attack. do not design cipher by yourself.
Quantum attacks:
Generic search problem: let \(f: X\to \{0, 1\}\) be a function, the goal is find \(x\in X\) s.t. \(f(x)=1\)
the best you can do is just try all possible input, so this takes time which is linear in the size of the domain, i.e. O(|X|)
if you can build a computer on the quantum physics, then you can solve this problem faster. [Grover'96] In fact you can solve this search problem not in $O(|X|)$ but $O(|X|^{1/2})$. Therefore the quantum computer has a great impact on the modern cryptography.
Advanced Encryption Standard
Since the DES and 3DES are simply not designed for modern hardware and are too slow, the NIST publishers request for proposal called Advanced Encryption Standard, and them finally adopt the Rijndael as AES.
The AES block cipher
the AES is constructed by the Substitution-Permutation Network(SPN) instead of Feistel network.
Remember that there are half of bits unchanged round to round in Feistel network. While in SPN all the bits are changed every round.
the workflow of SPN:
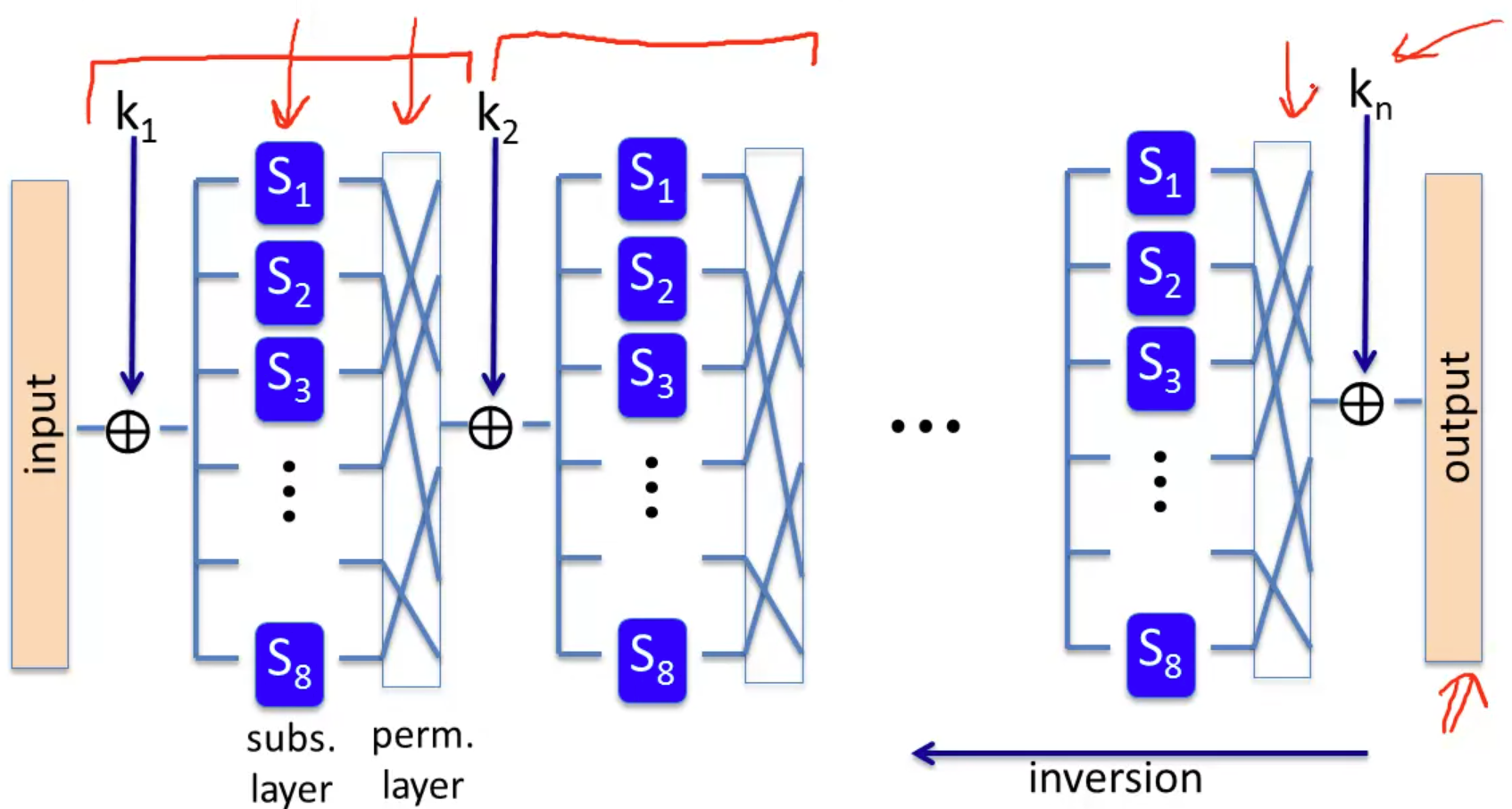
the inversion of SPN is simply done by applying all of the steps in the reverse order.
the AES works on 128-bit block, so the message block is handled in a 4\(\times\) 4 bytes matrix.
the specific work flow of AES:
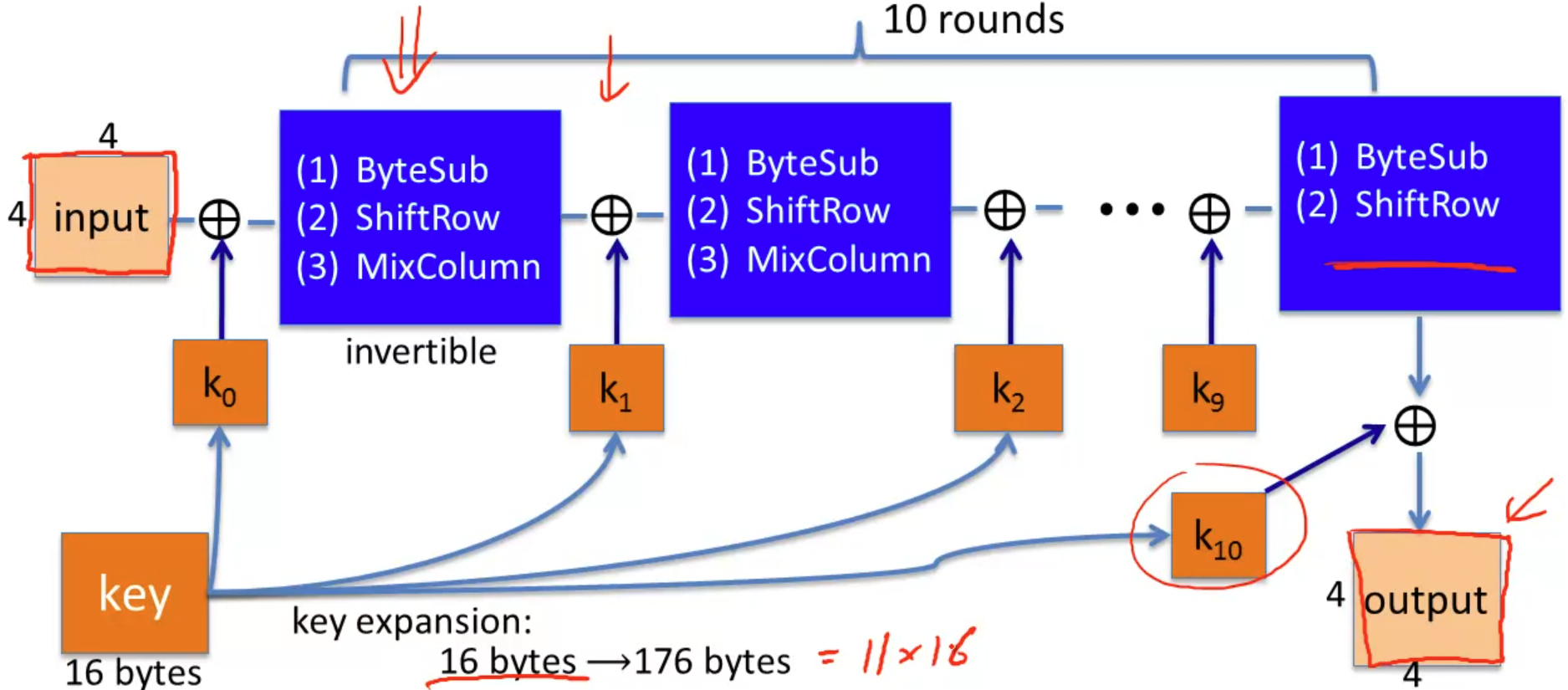
#1. byte substitution:
the way byte substitution works is literally based on S-box containing 256(16 \(\times\) 16) bytes, and essentially what it does is applying the S-box to every byte in the current states matrix.
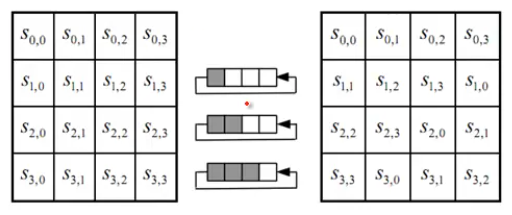
#2. shift rows:
just shift the rows of state matrix:
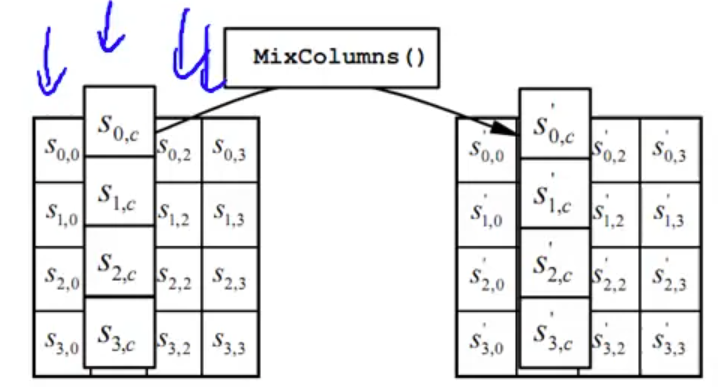
#3. mix columns:
literally apply a linear transformation to each one of these columns.
it should point out that shift rows and mixed columns are very easy to implement in code, and the byte substitution itself is also easily computable. Therefore, you can simply shrink the description of AES by literally storing code that computes the table rather than hardwiring the table into the implementation.
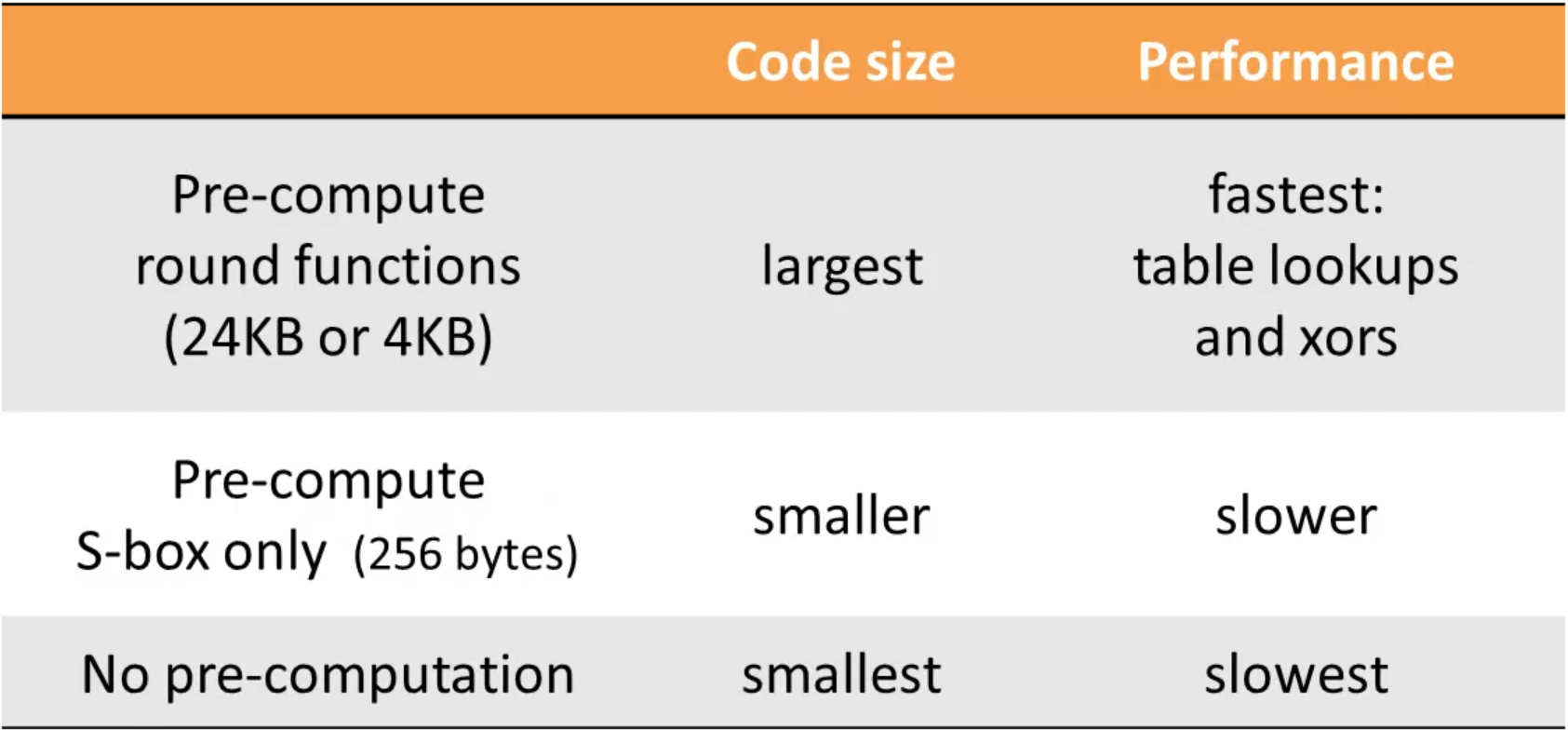
Code size & Performance tradeoff
a popular performance optimization of AES is precompute some of the transformation and then look-up the table:
Example: Javascript AES.
it send the AES library to the browser with no pre-computation (6.4 KB in size) to lower the network transmission overhead. the laptop will compute the lookup table on the AES library arrival to reach the best performance.
AES in hardware
AES instructions in Intel Westmere:
- aesenc, aesenclast: do one round function of AES and the last round function of AES
128-bit registers: xmm1<-state, xmm2<-round key
aesenc xmm1, xmm2; puts round function result in xmm1 - aeskeygenassist: perform AES key expansion
Claim 14x speedup over OpenSSL on the same hardware.
Similar instructions on AMD Bulldozer.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号