Overview and Stream Cipher
Overview and Stream Cipher
notes from the open course provided by Stanford University: https://www.coursera.org/learn/crypto/home/module/1
Course Overview
The goal of this course is to teach you how crypto primitives work how to use them correctly and reason about the security of your constructions.
In this course, you will learn some abstracts of some cryptography primitives and do some security proof.
Some Discrete Probability Notions for Cryptography:
Discrete probability is always defined over a finite set called the universe, which is denoted by U. And the probability distribution P over this universe U is basically a function that assigns to every element in the universe a weight in the interval zero to one.
Probability Distribution: \(P: U\to [0, 1]\) and \(\sum_{x\in U}P(x) = 1\)
Distribution Vector: \((P_0, P_1, ..., P_n)\), Where P is a probability distribution over the universe.
Event: For a set \(A \subset U, Pr[A] = \sum_{x\in A}P(x)\), the set A is a event.
Random Variable: X is a map \(X: U \to V\), Where V is a set, and the V is where the random variable x takes its value.
-
For Example, here is a random variable \(X: \lbrace0, 1\rbrace ^n \to \lbrace 0, 1\rbrace; X(y) = lsb(y)\in \{0, 1\}\)
So the value of random variable X is going to be either 0 or 1.
What the random variable X means is the least significant bit of a random sample from U.
In more general case, assume there is a random variable X take its value on the set V, so the variable outputs v, with the same probability that if we sample a random element in the universe and then we apply the map X to this element, how likely is it that the output is actually equal to v.
Formally, we say the probability that X outputs v, is the same as the probability of the event that when we sample a random element in the universe, we fall into the pre-image of v under the funciton X.
This notion can be written as:
\(\Pr[X = v]:=\Pr[X(r)=v,r\in U] := \sum_{r\in X^{-1}(v)}P(r):= \Pr[X^{-1}(v)]\)
Randomized algorithms: \(y \leftarrow A(m; r)\), where \(r \stackrel{r}{\gets}\lbrace 0, 1\rbrace ^ n\)
It takes input data as input, but it also has an implicit argument called r, where this r is sampled anew every time the algorithm is run, and in particular this r is sampled uniformly at random from the set of all n-bit binary strings for all arbitary end.
Therefore, everytime we run the algorithm on a particular input m, and we will get a different output, because a different r is generated every time.
-
It's different from the deterministic algorithm: \(y \gets A(m)\)
The deterministic algorithm can be regarded as a function, A, that given a particular input data, m, will always produce the same output A of m.
So really the way to think about the randomize algorithm is that it's defining a random variable. So given a particular input, it's defining a random variable which is defining a distribution over the set of all possible outputs of this algorithm given the input m.
In a nutshell, the output of a randomize algorithm changes every time you run it. And in fact, the algorithm defines a distribution on the set of all possible outputs.
-
Let's look at a particular example.
Suppose there is a randomize algorithm that takes a message m as input, and of course it is going to take an implicit argument random string r to randomize its operation, so what the algorithm will do is simply will encrypt the message m using the random string as input.
So it's basically defines a random variable, this random variable takes values that are encryption of the message m and the random variable is a distribution over the set of all possible encryption of the message m under a uniform key.
An important property of the XOR operation:
Theorm. assume that X is a random variable over \(\lbrace 0, 1\rbrace^n\), and Y is an independent uniform random variable on \(\lbrace 0,1\rbrace^n\), then \(Z := Y \oplus X\) is a uniform random variable on \(\lbrace 0,1\rbrace ^n\)
-
Proof.
For n = 1 case
\(\because Z := X\oplus Y\)
\[\begin{align} \therefore \Pr[Z = 0] &= \Pr[X = 1, Y = 0] + \Pr[X = 0, Y = 1]\\ &=\Pr[X = 1]\times \Pr[Y=0] + \Pr[X=0]\times\Pr[Y=1]\\&=\frac{1}{2}\times\Pr[X=1] + \frac{1}{2}\times\Pr[X=0]\\&=\frac{1}{2}\times(\Pr[X=0] + \Pr[X=1])\\&=\frac{1}{2} \end{align} \]\(\Pr[Z=0] = 1 - \Pr[Z = 0] = \frac{1}{2}\)
Therefore, Z is a uniform random variable on
The Birthday Paradox:
Let \(r_1, \dots, r_n \in U\) be independent and identically distributed random variable.
Theorem. When \(n=1.2\times \sqrt{N}\) then \(\Pr[\exist i\ne j, r_i = r_j] \ge \frac{1}{2}\), where N is the size of all possible value.
-
Proof.
Let P denote the probability that every two sample have different value, then P is equal to:
\(P = \frac{N}{N} \times\frac{N-1}{N}\times\cdots\times\frac{N-n + 1}{N} = \frac{N!}{N^n\times n!}\)
since that \(\Pr[\exist i\ne j,r_i = r_j] = 1 -\Pr[\forall i\ne j,r_i \ne r_j]\), the probability that there exist two samples get the same value is:
\(\Pr[\exist i\ne j, r_i = r_j] = 1 - P = 1 - \frac{N!}{N^n\times n!}\)
then we can get the following relationship:
\(1 - \frac{N!}{N^n\times n!} \ge \frac{1}{2}\)
\(1 - (\frac{N-1}{N} \times \frac{N -2 }{N}\times \cdots \times \frac{N- n+1}{N})\ge \frac{1}{2}\)
\(1 - (1 - \frac{1}{N})\times (1 - \frac{2}{N})\times \cdots \times (1 - \frac{n-1}{N}) \ge\frac{1}{2}\)
Since \(\forall x, e^{-x} \ge (1 - x)\), we can transform it to:
\(1 - (1 - \frac{1}{N})\times (1 - \frac{2}{N})\times \cdots \times (1 - \frac{n-1}{N}) \ge 1 - e^{-\frac{1}{N}}\times e^{-\frac{2}{N}}\times \cdots \times e^{-\frac{n-1}{N}} \ge \frac{1}{2}\)
\(1 - e^{- \frac{n(n-1)}{2N}} \ge \frac{1}{2}\)
\(e^{-\frac{n(n-1)}{2N}}\le \frac{1}{2}\)
\(\frac{n(n-1)}{2N}\ge \ln 2\approx 0.69\)
\(n\ge 1.2\sqrt{N}\)
Strong collision
Suppose we have a known sample r, then how many sample should we take to get a sample whose value is equal to r with the probability of 1/2?
Assume that we should take k samples to find the sample whose value is equal to r, then
\(\Pr[r_i = r] = \frac{1}{n}\), where \(r_i\) was a sample from the subset, and n is the size of all possible value.
\(\Pr[r_i\ne r] = (1 - \frac{1}{n})\)
\(\Pr[\forall r_i, r_i\ne r] = (1- \frac{1}{n})^k\)
\(\Pr[\exist r_i, r_i = r] = 1 - \Pr[\forall r_i, r_i \ne r] = 1 - (1 - \frac{1}{n})^k\)
\(\Pr[\exist r_i, r_i = r] = (1 - (1 - \frac{1}{n}))(1 + (1 - \frac{1}{n}) + (1 - \frac{1}{n})^2 + \cdots + (1 - \frac{1}{n})^{k - 1}) = \frac{1}{2}\)
In practice, n is very large, almost greater than \(2^{128}\), so we can transform it to:
\(\Pr[\exist r_i, r_i = r] \approx 1- \frac{k}{n} = \frac{1}{2}\)
\(k = \frac{n}{2}\)
Information Theoretic Security
A cipher is define over a triple, (K, M, C), where K is the set of all possible keys, M is the set of all possible messages, and C is the set of all possible Ciphertexts.
While a cipher itself is a pair of "efficient" algorithms (E, D), where
\(E: K\times M\to C\)
\(D: K\times C \to M\)
The requirement for the pair of algorithm is consistent, which is called the correctness of the cipher, the pair of algorithms should satisfy:
\(D(k, E(k, m)) = m, \forall m \in M, k\in K\)
In the definition of cipher, we put the word efficient in quota because this word means different things for different people. In theory, efficient means that algorithm runs in polynomial time for the size of input. In practice, efficient means that algorithm should runs in a certain time period.
The algorithm E is often randomize algorithm, which means that algorithm E is going to generate random bits for itself as our encrypting messages, and it's going to use those random bits to actually encrypt the messages that are given to it. On the other hand, the algorithm D is always determinist algorithm. In other words, the output is always the same for a given pair of key and ciphertext, and it doesn't depend on any randomness that's use by the algorithm.
One Time Pad
One Time Pad is a cipher defined over \(\lbrace K, M, C\rbrace, K = M = C = \{0,1\}^*\)
The encrypt and decrypt algorithm defined below:
\(E: C:= K\oplus M\)
\(D:M = K\oplus C\)
It's an early secure cipher, and it can run very fast. However, it can not be used in practice, since each key can be used for only one time and the size of key must to be the same as the message.
Why one time pad is a secure cipher?
Basic: Cipher text should reveal no information about the plaintex. In other words, if all you get to see is the cipher text, then you should learn absolutely nothing about the plaintext.
Def. Suppose we have a cipher(E, D) defined over {K, M, C} has perfect secrecy if the following conditions hold:
\(\forall m_0, m_1\in M, |m_1| = |m_2|, \forall c \in C, \Pr[E(k, m_0) = c] = \Pr[E(k, m_1) = c]\), where k is uniform in K, \(k \stackrel{R}{\gets} K\).
This definition means that given a cipher text we can tell if it came from \(m_0\) or \(m_1\) for all \(m_0, m_1\).
To say it in one more way, there is no cipher text-only attack on a cipher that has perfect secrecy.
- Lemma: OTP has perfect secrecy.
-
Proof.
Suppose that there are two different messages \(m_0, m_1\in M, |m_0| = |m_1| = N\), where N is a positive integer. we expect them to encrypt to the same cipher text \(c \in C\).
It's obviously to see that there exist only one key that \(k_0 := m_0\oplus c \in K\) and \(k_1 := m_1 \oplus c \in K\).
Therefore, both \(m_0\) and \(m_1\) has the probability of \(1/2^N\) to encrypt to c.
It means that OTP has perfect secrecy.
-
Lemma: If a cipher has perfect secrecy, then necessarily the number of keys or the length of keys must be no less than the length of the messages. We can write it as the following:
**\(perfect\space secrecy\Rightarrow |K| \ge |M|\)
-
Proof.
Assume that \(|K| \lt |M|\)
let \(M(c) := \lbrace m| m = D(k, c), \forall k \in K \rbrace\)
then |M(c)| = |K|
(Notice that |M(c)| can't be less than |K|, becasue any cipher text can't be decrypt to the same plain text with different keys)
\(\because |M(c)| = |K| < |M|\)
\(\therefore \exist m\in M, m\notin M(c), \Pr[E(k, m) = c] = 0\)
So this cipher doesn't have perfect secrecy.
Then we can get \(|K| \lt |M| \Rightarrow not\space perfect\space secrecy\)
\(\Rightarrow perfect\space secrecy \Rightarrow |K| \ge |M|\)
Stream Cipher: making OTP practical
Idea of stream cipher: replace "random" key by "pseudorandom" key based on the OTP. So we need Pseudo Random Generate to do this part of work. PRG(Pseudo Random Generator) denoted by g is a function that takes a seed, a s bits binary string, and maps it to a much larger string which will denoted by n bits binary string, where n >> s.
First of all, the PRG is efficiently computable, which means that PRG is combined by efficient algorithm, and this algorithm should be deterministic.
It's important to understand that PRG itself has no more randomness in it. It's totally deterministic. The only thing that's random here is the random seed that given as input to the function.
And the other property is that the output should looks random.
Suppose we have a PRG, then we can use the seed as our key, which means the seed is our secret key, and then PRG is going to expand the seed much larger random looking sequence. We denote the output of PRG as G(k), then we just XOR the G(k) and our message like in the one time pad, so we can get the XOR result as the cipher text. It can be written as the following:
\(c:=E(k, m) = G(k) \oplus m\)
When we want to decrypt, basically we do exactly the same thing:
\(m = D(k, m) = c\oplus G(k)\)
-
Can a stream cipher have perfect secrecy?
Refer to the second lemma above, since the key is much shorter than message, so the stream cipher doesn't have perfect secrecy.
Stream cipher need a different definition of security and the security of stream cipher depend on PRG.
PRG must be Unpredictable
Unpredictability is the minimal property need for secruity in PRG. The reason is discussed below.
Suppose there is a PRG that are predictable, which means that there exist an integer i, if give the first i bits of the outputs, then there is some sort of an efficient algorithm will compute the rest of the string.
Lemma: if the PRG is predictable, then the stream cipher is not secure.
-
Proof.
Suppose an adversary intercepts a particular cipher text denoted by c.
In fact, by some prior knowledge, the adversary actually knows that the initial part of the message happens to be some known value. For example, the protocol head of the this message or some messages start with a clone word. That would be a prefix that adversary knows.
So adversay can XOR this prefix with c, then he can get the first some bits of the G(k). While the PRG is predictable, then adversary can use these first some bits of G(k) to recover the entire G(k), and recover the plaintext by XORing the entire G(k) with the cipher text finnally.
Def. PRG \((G:K\to {0, 1}^n)\) is called predictable if the following condition holds:
if there exist an efficient algorithm denoted by A and a position i \((1\le i\le n-1)\) satisfy:
\(\Pr_{k\stackrel{R}{\gets}K}[A(G(k)|_{1,.., i}) = G(k)|_{i + 1}] \ge \frac{1}{2} + \varepsilon\)
for some non-negligible \(\varepsilon\).
Def. PRG is unpredictable if it is not predictable.
Weak PRGs
There are some very common PRGs that are easy to predict, so don't use these PRGs to construct cipher.
-
Linear Congruential generator
It has a three parameters denoted by (a, b, p), where a and b is integer and p is prime, and the generator is defined as follows:
let r[0] be the seed of generator, then
L0:
r[i] \(\gets\) a * r[i - 1] + b mod p
output few bits of r[i]
i++
goto L0
This generator has a good stastical property like that the number of 0-bit is similar to the number of 1-bit in the output.
But it is very easy to predict, this generator should never ever be used in crypto.
-
random() in glibc
This is very closely related to the linear congruential generator, and this is a random number generator implemented in glibc.
the definition of this generator is like this:
\(r[i]\gets (r[i - 3] + r[i - 31]) \mod 2^{32}\)
then output r[i] >> 1
Negligible and non-Negligible
In practice, negligible and non-negligible are just particular scalars that are used in the definition.
-
For example
If a value is more than one over a billion(\(1/2^{30}\)), which means likely to happen over 1 GB of data.
On the other hand, if an event that happens with the probability of one over two to eighty(\(1/2^{80}\)), then we can say that event is a negligible event, because that event actually not going to happen over the life of the key.
In cryptography, when we talk about the probability of an event, we don't talk about these probability as scalars, but rather we talk about them as function of a security parameters.
And these functions maps positive integers to positive real values, which written as follows:
\(\varepsilon: Z^{\ge0}\to R^{\ge 0}\)
the output non-negative real values that are supposedly probabilities.
Here, we will explain what does it mean for a function to be non-negligible.
We say a function is non-negligible if the function is bigger than some polynomial infinitely often. In other words, for many infinite value, the function is bigger than some one over polynomial, we can write it as follows:
\(\exist d: \varepsilon(\lambda)\ge 1/\lambda^d\), for many \(\lambda\), then the function \(\varepsilon\) is non-negligible.
On the other hand, if a function is smaller than all polynomials, then we'll say that function is negligible.
In other words, for any degree polynomial, for all constant d, there exist some lower bound \(\lambda_d\), and for all \(\lambda\) bigger than this \(\lambda_d\) the function is smaller than one over the polynomial. It can be written as follows:
\(\forall d, \lambda \ge \lambda_d: \varepsilon(\lambda)\le 1/\lambda^d\), (for large \(\lambda\)), then the function \(\varepsilon\) is negligible.
-
For example
Let \(\varepsilon(\lambda)= 1/2^\lambda\), then \(\varepsilon(\lambda)\) is negligible, since for any constant d there is a sufficiently large lambda that \(1/2^{\lambda} \le 1/\lambda^d\).
Let \(\varepsilon(\lambda) = 1/\lambda^{1000}\), then \(\varepsilon(\lambda)\) is non-negligible. Because if set d to be 10000, then this function is obviously bigger than \(1/\lambda^{10000}\).
The following is a little bit confusion example:
\[\varepsilon(\lambda) = \begin{cases}1/2^{\lambda}, for \space odd\space \lambda\\ 1/\lambda^{1000}, for \space even\space \lambda\end{cases} \]From the definition of negligible and non-negligible, this function is non-negligible.
The intuition in general case is that, mostly use negligible to mean less than one over exponential, and non-negligible to mean less than one over polynomial.
Attacks on Stream Ciphers and the One Time Pad
Never use stream cipher key more than one time
If we use the same stream cipher key to encrypt two different messages, then we can get the following statement:
\(c_1\oplus c_2 \to m_1\oplus m_2\)
since that:
\(c_1 = m_1\oplus G(k)\)
\(c_2 = m_2\oplus G(k)\)
because of the enough redanduncy in English and ASCII encoding, it's easy to recover the two messages:
\(m_1\oplus m_2 \to m_1, m_2\)
-
Real-world example
This is an example come up in networking protocols, called the PPTP(Point-to-Point Transfer Protocol), and this is a protocol for client wishing to communicate securely with a server.
Here, the client and the server both share a secret key, and them both send messages to each other.
The PPTP consider all of the messages sent by client as one long stream, and all part of the stream are encrypted using the key k, and the same thing is also happening on the server side. There is no problem here.
But the real problems is that both the server side and the client side using the same stream cipher key to encrypt messages, and the two time pad is happening here.
The lesson here is that you should never use the same stream cipher key to encrypt traffic in both direction.
-
Another kind of two time pad
There is an important example of two time pad comes up in Wi-Fi communication, particularly in the 802.11B protocol. The 802.11B protocol contains an encryption layer called WEP.
In WEP, there is a client and access point, and they both share a secret key k.
And when they wanna transmit a frame to one another in a secure way. The frame contains the plaintext m and the checksum of m called CRC(m).
Then, WEP runs the encryption process using a stream cipher, where the stream cipher key is a concatenation of value IV and the secret key k. The IV(Initial Vector) is a 24-bit binary sting. The IV will change every time encryption a message. It may start from zero and it's a counter that counts increment by one for every packets.
The design of IV is because the designer realized that the stream cipher key is supposed to encrypt only one message. And the way WEP change the stream cipher key was by prepending this IV to it, since the IV changes on every packet. So the encryption process can written as:
\(c:=PRG(IV||k)\oplus m\), IV counts the increment by one.
Finally the frame sent by client is combined by the cipher text and the IV, so the access point can decrypt the cipher text.
The problem is that the IV is only 24-bit long, it has to cycle after encrypted \(2^{24}\) frames.
After IV cycled, the same IV is used to encrypt two different message, and these two messages is encrypted using the same stream cipher key, since the key k never changes.
A more significant insecurity of WEP is that the seeds in PRG are closely related since all of them have the same suffix, the-bit long secret key k. Based on this feature, we can recover the secret key k after \(2^{24}\) frames transmitted.
Stream cipher provide no integrity(Or Stream cipher is malleable)
Adversary can be rather active than just eavesdropping, so basically he can intercept and modify the cipher text. For example, adversary can XOR the cipher text with a certain value p, which is called a sub-permutation key.
The malleability means that modifications to cipher text are undetected and have predictable impact on plaintext.
Since the following expression holds:
\(E(k,m) := m\oplus k\to c\), adversary intercepts and modifies the cipher text c, then \(c ' = c\oplus p\)
\(D(k, c'):= c'\oplus k = c\oplus p \oplus k = m\oplus k \oplus p \oplus k \to m \oplus p\)
Real-world Stream Cipher
In this section, we will firstly introduce two badly broken stream ciphers that widely used.
RC4
used in https and WEP.
RC4 takes variable size seed, and here just give as an example where it would take 128 bits as the seed size, which would then be used as the key for the stream cipher.
The first thing it does, is it expands the 128-bit secret key into 2048 bits, which are gonna be used as the internal state for the generator. And then it basically executes a very simple loop, where very iteration of this loop outputs one byte of outputs. You can run the generator for as long as you want, and generate one byte at a time.
The simplified structure of RC4 algorithm is indicated as follow:

Weakness of RC4
- Bias in initial output
It found that \(\Pr[2 ^{nd} byte = 0] = \frac{2}{256}\), which means the probability that the second byte of outputs happen to be equal to 0 would be exactly one over 256, since there are 256 possible byte.
Actually the first byte and the third byte are also bias in initial output.
As a result, it's recommended that if you're gonna use RC4, what you should do is ignore basically the first 256 bytes of the outputs.
While if the generator of RC4 is really random, the probability should be one over 256.
- More likely to get two bytes of 0
Probability that two bytes of sequence happen to be (0, 0) is equal to \(1/256^2 + 1/256^3\), which the probability should be \(1/256^2\) .
Related key attacks
CSS(Content Scrambling System)
used in DVD encryption.
The CSS turns out to be badly broken stream cipher, and here will demonstrate how the attack algorithm works.
How CSS works
CSS is based on a mechanism called linear feedback shift register(LFSR), which is easily implemented in hardware.
A linear feedback register is basically a register that consists of cells where each cell contains one bit. Then what happens is there are these taps into certain cells, not all cells, certain position are called taps. And then these taps feed into an XOR and then at every clock cycle, the register shifts to the left. The last bit falls off and then the first bit becomes the result of this XOR. It's demonstrated in the following picture:
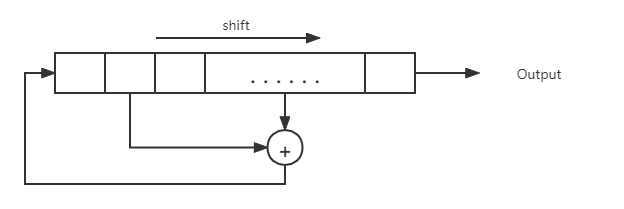
The seed is the initial state of LFSR. LFSR is the basis of a number of stream cipher.
CSS takes 5-byte seed, namely 40 bits. The following figure demonstrate how CSS works:

How to break CSS
Suppose we get an encrypted DVD encrypted by CSS, and we have no idea about what's inside of here.
However, it's so happens that just because DVD encryption is using MPEG files, which means we can get a known prefix of the plaintext, maybe this is twenty bytes, so we can get the first 20 bytes of the PRG by XORing the first 20 bytes of ciphertext with the known plaintext.
Then we try all possible \(2^{17}\) initial state of the first LFSR and using this possible initial state to output 20 bytes. Now we can take the first 20 bytes of output from the PRG to subtract the output we got from the first LFSR.
If in fact our guess for the initial state of the first LFSR is correct, what we should get is the first 20-byte output of the second LFSR.
Now it turns out that looking at a 20-byte sequence, it's very easy to tell whether this 20-byte sequence came from a 25-bit LFSR or not.
By telling whether the subtracting result came from a 25-bit LFSR or not, we can get the correct initial state of the first LFSR and we will have also learned the correct initial state of the second LFSR. And then we can recover the seed of this encryption and decrypt this cipher text.
PRG Security Definitions
To get a more close understanding about PRG, here is going to talk about the definition of PRG.
The goal of PRG definition
As we mentioned above , we can consider PRG with a key space \(\mathcal{K}\) that output n-bit strings.
let \(G:\mathcal{K}\to \{0, 1\}^n\) be a PRG.
Our goal is to define what does it mean for the output of the generator to be indistinguishable from random?
In other words, we're going to define a distribution that basically is defined by choosing a random key in the key space, and then we take the chosen key as the output of the generator. This distribution of pseudo random strings is indistinguishable from a truly uniform distribution.
\(\lbrace G(k)\space |\space k\stackrel{R}{\gets}\mathcal{K}\rbrace\) is "indistinguishable" from \(\lbrace r \space | \space r\stackrel{R}{\gets}\lbrace 0, 1\rbrace ^n\rbrace\)
This definition may be surprising since that all possible outputs of the PRG is a very tiny subset of the \(\lbrace 0,1 \rbrace^n\), because the seed is very small.
What we are arguing is that an adversary who looks at the output of the generator in this tiny set can't distinguish it from the output of the uniform distribution over the entire set. That's the property that we're actually shooting for.
Definition of indistinguishability from random
To define this concept of indistinguishability from random, we need the concept of a statistical test.
Here is going to define a statistical test on \(\lbrace 0,1 \rbrace^n\).
Def. A statistical test A over \(\lbrace 0,1 \rbrace^n\) is basically a algorithm that takes n-bit binary string and simply output 0 or 1. A outputs 1 if and only if the given n-bit string is actually random.
Let's look at a couple of examples:
The first example based on the fact that for a random string, the number of 1 is roughly equal to the number of 0. So it can be defined as:
\(A(x) = 1 \iff | \# 0(x) - \# 1(x)| \le 10\times \sqrt{n}\)
where the #0(x) denotes the number of 0 in x.
The second example, it counts the number of time that we see the pattern two consecutive 0. For a random string, we will expect to see 0,0 as probability \(\frac{1}{4}\), so it can be defined as following:
\(A(x) = 1\iff |\# 00(x) - \frac{n}{4}| \le 10\times \sqrt{n}\)
The third example counts the longest length of consecutive 0 sequence, named as the max run of 0(x), so it was defined as:
\(A(x) = 1 \iff max-run-of-0(x)\le 10\times \log_2(n)\)
In this example, A will output 1 if it takes a input like n-bit 1 sequence, even though it's not random, so statistical tests don't have to get things right.
How to characterize the advantage of a statistical test?
In other words, how to evaluate whether a statistical test is good or not?
Here is going to give the definition of advantage of a statistical test:
Def. let \(G:\mathcal{K}\to \lbrace 0,1 \rbrace^n\) be a PRG, and A is a statistical test over \(\lbrace 0,1 \rbrace ^n\), then we can define the advantage of A as:
\(Adv_{PRG}(A,G) := |\Pr_{k\stackrel{R}{\gets}\mathcal{K}}[A(G(k)) = 1] - \Pr_{r\stackrel{R}{\gets}\lbrace 0,1 \rbrace^n}[A(r) = 1]|\in [0, 1]\)
If \(Adv_{PRG}(A, G)\) close to 1, then we say A can distinguish G from random.
If \(Adv_{PRG}(A, G)\) close to 0, then we say A can not distinguish G from random.
-
Example
Suppose we get a PRG, \(G:\mathcal{K}\to \lbrace 0,1 \rbrace^n\), satisfies msb(G(k)) = 1 for 2/3 of keys in \(\mathcal{K}\).
Define statistical test A(x) as
if[msb(x) = 1], then A output 1, otherwise output 0.
So, the advantage of statistical test A is:
\(Adv_{PRG}(A,G) = |Pr[A(G(k)) = 1] - \Pr[A(r) = 1]| = \frac{2}{3} - \frac{1}{2} = \frac{1}{6}\)
then we say A breaks the generator G with advantage of 1/6, which means that the PRG is not good.
Secure PRG: Cryptograph definition
Now that we understand what statistical tests are, we can go ahead and define what is a secure pseudo random generator.
Basically, we say a PRG is secure if essentially no efficient statistical test can distinguish its output from random.
Def. We say that a PRG \(G:\mathcal{K}\to\lbrace 0,1 \rbrace^n\) is secure if:
for all efficient statistical test A, \(Adv_{PRG}(A, G)\) is negligible.
Restricting this definition into only efficient statistically tests is actually necessary for this to be satisfiable.
How to prove secure PRG?
Suppose we constructed a PRG, then how to prove that there is no efficient statistical test can distinguish it's output from random string?
The answer is we actually can not. In fact, it's not known.
Since we can't find all efficient statistical test in fact.
It's very easy to show that there are no secure PRGs.
even though we can't actually rigorously prove that a particular PRG is secure, we still have a lot of heuristic candidates.
Theorem: A secure PRG is unpredictable.
Proof.
On the verse, we prove that if a PRG is predictable then it is insecure.
Suppose there is a predictor A, is actually an efficient algorithm , it takes the first i bit of a string and guess the next bit of the string. It can be written as:
\(A(X|_{1,\dots,i}) = X|_i\)
So, if a PRG G is predictable, then we can get that:
\(\Pr_{k\stackrel{R}{\gets}\mathcal{K}}[A(G(k)|_{1\dots i}) = G(k)|_i]\ge \frac{1}{2} + \varepsilon\)
for non-negligible function \(\varepsilon\).
then we can define a statistical test B as:
the advantage of B is equal to:
\(Adv_{PRG}(B,G) = |\Pr_{k\stackrel{R}{\gets}\mathcal{K}}[B(G(k)) = 1] - \Pr_{r\stackrel{R}{\gets}\{0,1\}^n}[B(r) = 1]| \ge \frac{1}{2} + \varepsilon - \frac{1}{2} = \varepsilon\)
since \(\varepsilon\) is non-negligible, the PRG G is not secure.
Therefore, we can get a conclusion that secure PRG is unpredictable using the contrapositive.
Theorem: An unpredictable PRG is secure.
the proof is given but is not easily to understand.
Semantic Security
Attacker’s abilities: obtains one ciphertext (for now)
Possible security requirements:
atttempt #1: attacker cannot recover secret key.
-
That’s a actually terrible definition,
think about the following cipher: E(k, m) = m
then, attacker cannot recover the secret key given any ciphertext.
But the cipher is clearly insecure.
attempt #2: attacker cannot recover all of plaintext.
-
Think about the following cipher:
\(E(k, m_0||m_1)\) = \(m_0 || E'(k, m_1)\)
where E’(k, m) = k \(\oplus\) m, one-time-pad
then attacker cannot recover any plaintext since the last half of the plaintext was encrypted by one-time-pad.
This cipher can satisfy the above definition but is still insecure, because it leak the first half of the plaintext. Attacker cannot recover all of the plaintext, but he can recover most of the plaintext.
Shannon’s idea: Ciphertext should reveal no information about the plaintext.
Shannon’s Perfect Secrecy:
let (E, D) be a cipher over (K, M, C)
(E, D) has perfect secrecy if \(\forall m_0, m_1\in M (|m_0|= |m_1|)\), \(\{ E(k, m_0)\} = \{ E(k, m_1)\}, k\stackrel{r}{\gets} \mathcal{K}\)
-
Intuition:
if the adversary observes the ciphertexts then he doesn’t know whether it came from the distribution as the result of encryption \(m_0\) or it came from the distribution as the result of encryption \(m_1\).
the attacker cannot tell what message was encrypted.
This definition is too strong in the sense that it requires really long keys that in the same length with the message. Otherwise, it can’t possibly satisfy this definition.
Weaken the definition a little bit:
(E, D) has perfect secrecy if \(\forall m_0, m_1\in M (|m_0|= |m_1|)\), \(\{ E(k, m_0)\} \approx_{p} \{ E(k, m_1)\}, k\stackrel{r}{\gets} \mathcal{K}\)
The two distributions is not absolutely indistinguishable but computationally indistinguishable.
Semantic Security Experiments for one-time key
For b = 0, 1,define experiments EXP(0) and EXP(1) as:
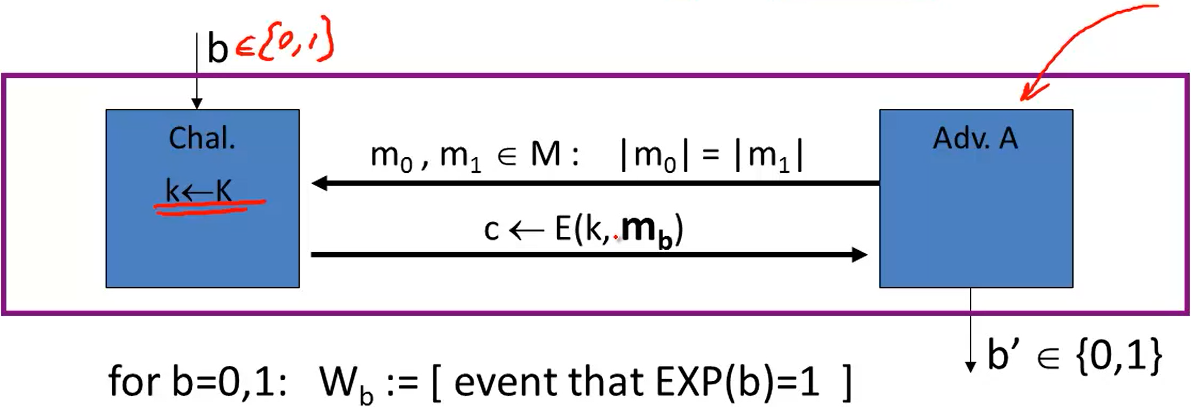
Semantics security advantage of the adversary A against the scheme E is noted as follow:
\(Adv_{ss} = |\Pr[W_0] - \Pr[W_1]| \in [0, 1]\)
If the advantage is close to zero that means the adversary was not able to distinguish EXP(0) and EXP(1).
Def. Scheme E is semantically secure if for all efficient Adversary A:
\(Adv_{ss}(A, E)\) is negligible.
If the advantage is equal to zero for all eficient adversary, then this scheme is perfectly secure.
OTP is semantically secure
-
Proof.
for all efficient adversary A:
\(Adv_{ss}[A, E] = |\Pr[A(k\oplus m_0) = 1] - \Pr[A(k\oplus m_1) = 1]| = 0\)
According to the property of XOR, both the distribution of \(k\oplus m_0\) and the distribution of \(k\oplus m_1\) are uniform distribution if k is random pad, which means that these distribution are absolutely identical distribution.
Stream ciphers are semantically secure
Theorem. If \(G: K\to \{0,1\}^n\) is secure PRG, then stream cipher E derived from G is semantically secure.
-
Proof.
If we say a stream cipher E derived from a secure PRG G is semantically secure, then the following statement should hold:
Let A be a semantically secure adversary,
\(|\Pr_{k\stackrel{r}{\gets}K}[A(G(k) \oplus m_0) = 1] - \Pr_{k\stackrel{r}{\gets}K}[A(G(k)\oplus m_1) = 1] | \le negl\)
For OTP, we already know that:
\(|\Pr_{r\stackrel{r}{\gets}\{0,1\}^n}[A(r\oplus m_0) = 1] - \Pr_{r\stackrel{r}{\gets}\{0,1\}^n}[A(r\oplus m_1) = 1]| = 0\)
\(Pr[A(r\oplus m_0) = 1] = \Pr[A(r\oplus m_1) = 1]\)
So let B be a PRG adversary it takes a n-bit string come from the secure PRG G and tell it’s random or not.
Here we let B be the challenger of A, which means that when it get a n-bit string y, it just encrypt \(m_0\) and send it back to A, and takes A’s output as B’s output.
The advantage of B agains G is:
\(Adv_{PRG}(B, G) = |\Pr[B(G(k)) = 1 ] - \Pr[B(r) = 1] |\)
which is equal to \(|\Pr[A(G(k) \oplus m_0) = 1] - \Pr[A(r\oplus m_0) = 1] |\)
Since G is a secure PRG, then
\(Adv_{PRG}(B, G) \le negl\)
\(|\Pr[A(G(k)\oplus m_0) = 1] - \Pr[A(r\oplus m_0) = 1]| \le negl\)
Let B encrypt \(m_1\) then we can get:
\(|\Pr[A(G(k)\oplus m_1) = 1] - \Pr[A(r\oplus m_1) = 1]|\le negl\)
According all above statements:
\(Adv_{SS}(A, E) = |\Pr[A(G(k)\oplus m_0) = 1] - \Pr[A(G(k)\oplus m_1) = 1]| \le 2\times Adv_{PRG}(B, G)\)
which is still negligible.
Hence, stream cipher derived from a secure PRG is semantically secure.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号