密码学基础(三) - 私钥加密
计算安全性
计算安全性相比于完美保密放松了两个限制:1)安全只针对在可行时间内运行的高效敌手;2)敌手可以有非常小的概率成功,即在完美保密的实验中敌手猜中明文的概率比1/2稍大些。
放松的必要性
假设有一个加密方案,其密钥空间 K 的大小远小于明文空间 M 的大小,则不论这种加密方案是怎么构造的,都有两个适用的攻击方法:
1)暴力搜索:给定一个密文 c ,则敌手可以通过尝试密钥空间 K 中的所有密钥 k 来破解密文 c ,通过尝试不同的密钥,敌手可以获取一系列可能与密文对应的消息,但是由于|K| < |M|,这将会泄露一些关于明文的信息;此外,敌手可以实施已知明文攻击,从而了解密文c1, ..., cl分别对应的明文m1, ..., ml,然后敌手再次尝试所有可能的密钥直到找到一个密钥:Deck(ci) = mi,0 ≤ i ≤ l。从而敌手就有可能获取了通信方正在使用的密钥,那么通信方如果再使用这个密钥进行通信就是不安全的了。
2)随机数攻击:再次考虑当敌手获取了密文c1, ..., cl分别对应的明文m1, ..., ml的信息,这次敌手不再是尝试所有可能的密钥,而是在密钥空间中随机的抽取密钥 k 进行尝试,则有 1/|K| 的概率成功破解。
所以,如果想要多次使用同一个密钥来加密多条明文,那么需要限制敌手破解密文的时间才能够保证通信的安全,并且允许敌手以极小的概率成功。
具体的方法
具体安全性的定义:一个加密方案是(t, ε)安全的,如果对任何一个敌手都有在不超过 t 的时间内有 ε 的概率成功破解这个加密方案。
实例:一般认为,现代私钥加密方案在以下意义上提供了几乎最佳的安全性:
如果密钥的长度为 n,敌手在时间 t 内能够有ct/2n的概率破解这个加密方案,其中 c 为一个固定的常数。
假设在最简单的情况下,c = 1,密钥的长度n = 60就能对于使用桌面电脑的敌手提供足够的安全性:在一个4GHz的电脑上,260个CPU周期需要260 / (4*109) 秒,相当于9年;而在世界上最快的电脑上也需要运行1分钟。
而现在最常见的密钥长度一般都是n = 128。
渐进的方法
这种方法植根于复杂性理论,引入了一个整数值安全参数(用n表示),它参数化了加密方案和所有相关方(即通信方和攻击方)。现在将敌手的运行时间以及其成功的概率看作一个带参数的函数,而不是一个具体的时间。
渐进安全性的定义:如果PPT(Probabilistic Polynomial-Time)上的任何敌手破解该加密方案的概率是可以忽略不计的,那么该方案就是安全的。
实例1:在这个例子中,敌手运行 n3 分钟能够成功破解加密方案的概率为240*2-n。
- n≤40:一个运行403分钟(约6周)的对手可以破环该方案,概率为1。
- n = 50:一个运行503分钟(约3个月)的对手可以破坏该方案,概率约为1/1000。
- n = 500:一个运行了200多年的对手只有在概率大约为2 -500的情况下才会破坏这个方案。
实例2:现在有一个加密方案,通信方需要106*n2个CPU周期,而敌手需要108*n4个CPU周期以2-n/2的成功概率破解这个加密方案。
1)假设通信方和敌手都使用2GHz的计算机,并且n=80,则通信方运行106*6400个CPU周期,大约为3.2秒;而敌手破解这个加密方案则需要108*804个CPU周期,大约为3个星期,而成功破解的概率为2-40。
2)假设通信方和敌手都是用8GHz的计算机,并且n=160,则通信方运行时间仍然为3.2秒;而敌手破解这个加密方案需要8*106秒,大约为13个星期,而成功的概率为2-80。
可以看出,在这种情况下计算效率更高的计算机使得敌手的破解工作变得更加困难。
- 高效率的敌手:运行在 n 个时间多项式上的随机算法,这意味着存在某个多项式p,当安全参数为 n 敌手运行的时间最多为 p(n)。当然,也需要要求通信方运行在p(n)的时间内。
- 极低的成功概率:即成功的概率小于 n 中的任何逆多项式,这种可能性可以忽略不计。
- 高效率的算法:如果存在一个多项式p(.),对于任意x ∈ {0,1}*,算法A计算A(x)能够在最多p(|x|)步骤中终止运算(其中|x|为x的长度),则称算法A是高效率的算法,或者称算法A运行在多项式时间内。
默认情况下,允许所有算法都是概率的(或随机的)。算法可以在每一步访问一个无偏随机位。
默认考虑随机算法有两个原因::1) 随机性在密码学中是必要的(例如…为了选择随机的密钥等等)。2) 随机化是实用的,并且它给了攻击者额外的能力。
- 可忽略函数:一个从自然数映射到非负实数的函数 f 是可以忽略的,如果对于每个多项式 p 都有一个 N 对于所有整数n > N使得 f(n) < 1/p(n)。
可忽略函数的性质:假设negl1 和 negl2为两个可忽略的函数,则:
- 函数negl3(n) = negl1(n) + negl2(n),negl3也是可忽略的函数。
- 对于任何一个正多项式 p ,函数negl4(n) = p(n) * negl1(n),negl4也是可忽略的函数。
如果一个事件在某一个确定的实验中发生的概率是可忽略的,那么即使这个实验重复多项式的数目次这个事件发生的概率也是可忽略的。
渐进安全性更加具体的定义:
如果对于每个PPT上执行指定的攻击方式的敌手,并且对所有正多项式p,存在一个正整数N;当 n>N 时,敌手A成功破解的概率小于1/p(n)。
需要注意的时,如果n≤N则没有任何保障,这就是为什么会称这种安全为渐进的安全,因为敌手仍然有概率成功破解,当n<N的时候。
- 为什么使用PPT来衡量效率?
这使得不再必须指定具体的计算模型;并且PPT算法满足的理想的闭包属性:对多项式时间子程序进行多项式多次调用的算法(并且只做多项式计算)本身将在多项式时间内运行。
- 为什么使用可忽略函数来等价敌手成功的概率?
由可忽略函数的性质可知:可忽略函数的任何乘以任何整数仍然是可忽略的,因此,如果一个算法多项式地多次调用某个子程序,每次调用“失败”的概率可以忽略不计,那么对该子程序的任何一次调用失败的概率仍然可以忽略不计的。
计算性安全的定义
私钥加密方案是一组概率多项式时间算法(Gen, Enc, Dec),如:
密钥生成算法Gen将1n作为输入(即,安全参数为一元),输出密钥 k ;我们写 k←Gen(1n) (需要强调Gen是随机算法)。不失一般性,假设Gen(1n)输出的任何密钥 k 满足 |k|≥n。
加密算法Enc将密钥 k 和明文 m ∈ {0,1}* 作为输入,然后输出密文 c ;考虑到Enc可能会被随机化,可以写成 c←Enck(m)。
解密算法Dec将密钥 k 和密文 c 作为输入,输出明文 m 或者一个错误;假设Dec是确定的,则可以写成 m := Deck(c) ,(假设Dec不会返回一个错误),并且用来表示错误。
正确性要求:对每个 n ,由Gen(1n)生成的每个密钥 k 以及每个明文 m ∈ {0,1}*,都有Deck(Enck(m)) = m。
如果对于由Gen(1n)生成的密钥 k ,加密算法的明文输入为固定的m ∈ {0,1}l(n),则称加密方案(Gen, Enc, Dec)是对于明文长度l(n)的固定长度私钥加密方案。
- 无状态的加密方案:Enc(和Dec)的每次调用都独立于所有先前的调用。
- 有状态的加密方案:发送方(可能还有接收方)需要在多次调用中维护状态。
(在后续的讨论中除非有明确的说明为有状态,都默认为无状态加密)
窃听者存在下的不可区分性
窃听者存在下的不可区分性和完美不可区分性一样:都是基于某个窃听实验而定义的,加密方案Π(Gen, Enc, Dec),运行在PPT上的敌手A,以及一个可以去任何值的安全参数n
被动攻击下的窃听实验(PrivKeavA, Π (n)):
- 敌手A获取了1n,输出一对明文m0, m1,其中|m0| = |m1|。
- 通过运行Gen(1n)生成密钥k,并选择一个统一的bit b∈{0,1}。密文 c←Enck (mb) 返回给敌手A;(称之为密文挑战)
- A输出一位b '。
- 如果b ' = b,则定义实验输出为1,否则为0。 如果PrivKeavA, Π (n)=1,则A成功了。
窃听者存在下的不可区分性的定义:一个加密方案是窃听者存在下的不可区分性的或者是窃听安全的,当且仅当对所有运行在PPT上的敌手 A,存在一个可忽略函数 negl ,对所有 n 有:
Pr[PrivKeavA, Π (n)=1] ≤ 1/2 + negl(n)
引理:一个私钥加密方案Π(Gen, Enc, Dec)具有窃听者存在下的不可区分性,当且仅当对所有运行在PPT上的敌手A,存在一个可忽略函数 negl 有:
| Pr[outA(PrivKeavA, Π (n,0)=1)] - Pr[outAPrivKeavA, Π (n,1)=1] | ≤ negl(n),(其中, PrivKeavA, Π (n,b)为固定 b 的窃听实验,outA(PrivKeavA, Π (n,b))表示敌手A在窃听实验中输出的 b‘ )
即敌手成功的概率和失败的概率相差一个可忽略函数。
引理的证明:
充分性
显然,Pr[outA(PrivKeavA, Π (n,0)=1)]+Pr[outA(PrivKeavA, Π (n,1)=1)] = 1
∴| Pr[outA(PrivKeavA, Π (n,0)=1)] - Pr[outAPrivKeavA, Π (n,1)=1] | ≤ negl(n)
| 1 - 2*Pr[outAPrivKeavA, Π (n,1)=1] | ≤ negl(n)
-negl(n) ≤ 1 - 2*Pr[outAPrivKeavA, Π (n,1)=1] ≤ negl(n)
Pr[outAPrivKeavA, Π (n,1)=1] ≤ 1/2 + 1/2 * negl(n)
由可忽略函数的性质可知:nelg2(n) = 1/2 * negl(n) 仍然是一个可忽略函数
∴ Pr[outAPrivKeavA, Π (n,1)=1] ≤ 1/2 + negl2(n)
即Pr[PrivKeavA, Π (n)=1] ≤ 1/2 + negl(n)
必要性
∵Pr[PrivKeavA, Π (n)=1] ≤ 1/2 + negl(n)
即Pr[outAPrivKeavA, Π (n,1)=1] ≤ 1/2 + negl(n)
且 Pr[outA(PrivKeavA, Π (n,0)=1)]+Pr[outA(PrivKeavA, Π (n,1)=1)] = 1
∴| Pr[outA(PrivKeavA, Π (n,0)=1)] - Pr[outAPrivKeavA, Π (n,1)=1] | = | 1 - 2*Pr[outAPrivKeavA, Π (n,1)=1] | ≤ 2negl(n)
同样地,由于可忽略函数的性质:negl3(n) = 2 * negl(n) 也是一个可忽略函数
∴| Pr[outA(PrivKeavA, Π (n,0)=1)] - Pr[outAPrivKeavA, Π (n,1)=1] |≤ negl3(n)
加密与明文长度:当使用加密算法的时候需要考虑是否会泄露明文的长度1)如果可以加密任意长度的明文则不可能隐藏所有关于明文的信息;2)而如果泄露了明文的长度则会带来一些新的问题。
语义安全性
一个私钥加密方案在窃听者存在下是语义安全的,如果对于任何PPT上的算法 A ,存在另一个PPT算法 A' ,对于所有的PPT上的算法Samp以及多项式时间可计算的函数 f 和 h 有:
Pr[A(1n, Enck(m), h(m))=f(m)] - Pr[A'(1n, |m|, h(m))=f(m)]
上面的概率是可忽略的。
用图解的形式表示如下图:

定理:一个加密方案是具有不可区分性,当且仅当其在窃听者存在下是语义安全的。
构造一个安全的加密方案
伪随机发生器
正如不可区分性(即窃听者存在下的不可区分性)是相对于完美保密的一个计算性的放松,伪随机数也是真正的随机化的一个计算性的放松。
伪随机生成器(PRG, pseudorandom generator)是一个高效并且确定性的用于将一个称为种子的短的字符串转换为一个较长的“看起来均匀”(或“伪随机”)字符串。
- 伪随机串:由伪随机生成器输出的一个字符串。
- 均匀的串:根据均匀分布采样的字符串。
统计测试的简单例子:某个伪随机发生器产生的为随机字符串的第一个比特等于 1 的概率应该为 1/2 。
一个好的PRG需要通过所有的统计测试:对于任何高效率的统计测试(或者区分器)D,当接收PRG的输出的串后输出1的概率,需要接近和接收一个均匀的串后输出1的概率。换句话说,PRG的输出应该对于每一个区分器都“看起来像”一个均匀的串。
伪随机生成器的定义:设 l 是一个多项式,G是一个多项式时间的算法,并且G对于任何输入s∈{0, 1}n,其输出的结果的长度为 l(n) ,称G是伪随机生成器,如果其满足以下两个条件:
- 扩张性:对于任意的 n 有 l(n)>n.
- 伪随机性:对于任意的PPT上的算法D,存在一个可忽略函数 negl 有:| Pr[D(G(s))=1] - Pr[Dr(r)=1] | ≤ negl(n),其中的第一个概率就是区分器D以G输出为输入而输出1的概率,第二个概率就是D以一个均匀的01串为输入而输出1的概率。
需要注意的是:在进行伪随机测试的时候区分器并不能知道种子 s 的内容。
反例1,确定型函数:假设某个伪随机生成器G(s)的算法结构为在输入字符串的最后一位添加一位,这一位是前面 n 位的异或结果。则该伪随机生成器的扩张因子就为 l(n)=n+1。则区分器可以采取以下策略:对于一个输入的字符串w,当且仅当w的最后一位等于前面n位的异或结果时才输出1。
在这种情况下:Pr[D(G(s))=1] = 1,Pr[D(r)=1] = 1/2,Pr[D(G(s))=1] - Pr[D(r)=1] = 1/2,这是不可忽略的,所以G并不是一个伪随机生成器。
反例2,错误的构造方法:设G是一个伪随机生成器,其扩张因子为 l(n) > 2n
- 定义一个新的伪随机生成器G'(s) = G(s1, ..., sfloor(n/2))
l'(n) > 2*floor(n/2),当n为偶数时,l'(n) > n;当n为奇数时,l'(n) > n-1;所以G'(s)并不满足为随机生成器的扩张性,因此G'(s)不是伪随机生成器。
- 定义一个新的伪随机生成器G''(s) = G(0|s| || s)
因为G是伪随机生成器,所以当s∈{0, 1}n,且r∈{0, 1}l(n)时,| Pr[D(G(s))=1] - Pr[D(r)=1] | ≤ negl(n)。然而 b = 0|s| || s,b∈{0, 1}2n,则Pr[D(G'‘(s))=1] = Pr[D(G(b))=1],所以:
|Pr[D(G''(s))=1] - Pr[D(r)=1]| = |Pr[D(G(b))=1] - Pr[D(r)=1]|,在这种情况下,因为G期望的输入长度是n,而实际的输入长度是2n,所以|Pr[D(G(b))=1] - Pr[D(r)=1]|是不可忽略的。因此G''(s)也不是伪随机生成器。
流密码
将流密码看作一对确定的算法(Init, GetBits),其中
Init:将种子 s 和可选初始化向量 IV 作为输入,输出初始状态st0
GetBits:将状态信息 sti 作为输入,然后输出一个比特 y ,然后更新一个状态sti+1。
流密码的输入:种子 s 以及一个随机选择的初始向量IV
流密码的输出:y1, ..., yl
流密码的程序结构:
st0 := Init(s, IV)
for i = 1 to l:
(yi, sti) := GetBits(sti-1)
return y1...yl
如果某个流密码算法没有初始向量IV,并且对于任何一个大于 n 的多项式 l(n) ,这个流密码算法是以 l(n) 为扩张因子的伪随机生成器。 则这个流密码是安全的。
Proof by Reduction
如果想要证明一个给定的算法是计算性安全的,则必须依赖一个未经证明的(P≠NP)假设;除非这个算法是理论上信息安全的。
proof by reduction的步骤:
1.假设某个高效率的敌手攻击加密方案Π,用ε(n)表示敌手成功破解的概率。
2.构造一个算法A‘,将其称为“约简”,其试图利用敌手A作为子程序来解决某个数学难题 X ,但 A' 除了知道 A 在攻击Π以外什么都不知道。所以对于数学难题 X 的某些实例输入 x ,算法A’ 将A模拟为加密方案 Π 的一个实例:
- (a)当A作为A‘的子程序的时候的运行环境应该和当A和Π进行互动的时候的运行环境一致。
- (b)如果A’ 成功模拟的A破解加密方案Π,则A‘解决以x作为实例输入的数学难题X的概率为1/p(n)。
3.在2(a)和2(b)的前提下,A’ 成功解决数学难题X的概率为ε(n)/p(n)。
- 所以如果ε(n)是可忽略的函数,那么ε(n)/p(n)也是可忽略的函数。
- 然而,如果A是一个高效率的敌手,则A‘ 可以以一个不可忽略的函数的概率解决数学难题X,但这与前提相矛盾。
4.综上所述,没有一个运行在PPT上的敌手能够以一个不可忽略函数的概率破解 Π (Π是计算安全性的)。
构造计算性安全的加密方案
设G是一个扩张因子为 l 的伪随机生成器,定义一个用于加密长度为 l 的明文的私钥加密方案为:
Gen:对于输入1n,均匀选择k ∈ {0,1}n作为密钥
Enc:对于输入的密钥 k ∈ {0,1}n 以及明文m∈ {0,1}l(n),输出的密文为:c := G(k)⊕m
Dec:对于输入的密钥 k ∈ {0,1}n 以及密文c ∈ {0,1}l(n),输出的明文为:m := G(k)⊕c
定理:如果G是PRG,则上述的固定长度私钥加密方案是不可区分的。
证明:
证明这个定理的最关键的一点就是将窃听实验和区分器区分实验结合在一起从而构造关系。
通过敌手 A 构造一个区分器 D ,将 D 的区分G的输出和一个随机字符串的能力直接与 A 分辨 Π 加密明文的能力建立联系。即区分器将敌手 A 作为自己的一个子程序来完成区分实验。
区分器 D :D 获得一个输入字符串w ∈ {0, 1}l(n)
- 运行A(1n)来获取一对明文m0, m1 ∈ {0, 1}l(n)
- 随机的选择一个比特b∈{0, 1},计算密文c := w ⊕ mb
- 将c返回给 A 然后获取A输出的b‘,如果b=b',则输出1;否则输出0
进一步实验:构造一个加密方案Π’ = (Gen', Enc', Dec'),其与上面所构造的加密方案 Π 的唯一区别就是将G(k)替换成一个随机的长度为 l(n) 字符串,实际上 Π‘ 就是完美保密的One-Time Pad加密方案。
则Pr[PrivKeavA, Π’(n)=1] = 1/2
- 如果D的输入是一个长度为l(n)的随机字符串,则对于 A 来说相当于在进行PrivKeavA, Π' (n)实验,根据上面区分器 D 的策略可知:Pr(w←{0, 1}l(n)) [D(w)=1] = Pr[PrivKeavA, Π'(n)=1] = 1/2
- 如果D的输入是G(k),则对于 A 来说相当于在进行PrivKeavA, Π (n)实验,根据上面区分器 D 的策略可知:Pr(k←{0, 1}n) [D(G(k))=1] = Pr[PrivKeavA, Π(n)=1]
又因为 G 是一个PRG,所以存在一个可忽略函数negl,使得:| Pr(k←{0, 1}n) [D(G(k))=1] - Pr(w←{0, 1}l(n)) [D(w)=1] | ≤ negl(n)
而上式又等于 | Pr[PrivKeavA, Π(n)=1] - 1/2 | ≤ negl(n)
所以Pr[PrivKeavA, Π(n)=1] ≤ 1/2+negl(n)
更强的安全概念
多明文下的窃听实验(PrivKmultA,Π(n)):
- 敌手得到输入1n,然后输出一对等长的明文序列M0=(m0,1, ..., m0,t)以及M1=(m1,1, ..., m1,t),其中对于所有 i 都有:|m0,i| = |m1,i|
- 通过运行G(1n)获得一个密钥,然后随机的选择一个比特b∈{0,1}。然后对所有 i ,密文 ci ← Enck(mb,i),最终将密文C=(c1, ..., ct)返回给A
- A输出一个比特b'
- 如果b’ = b,则该实验的输出为1,否则为0。
同样的,如果某个多明文加密方案满足Pr[PrivKmultA,Π(n)=1] ≤ 1/2 + negl(n),则称这个加密方案具有多明文加密下不可区分性。
定理:如果某个私钥加密方案是不可区分性的,那么在多明文加密下就不具备不可区分性。
证明:假设敌手在多明文下的实验中采取这样的策略:
输出的明文M0=(0l,0l)以及M1=(0l,1l),设返回的敌手的密文为C=(c1, c2),如果c1=c2,则敌手输出0;否则敌手输出1。
由于同一个密钥加密两次明文,所以如果b=0,则必然有c1=c2,然后A在这种情况下输出0;如果b=1,则有c1≠c2然后A输出1。
所以这个实验输出1的概率为1,所以也就不具备多明文下的不可区分性。
选择明文攻击
定义:敌手有能力选择某些明文进行加密,其目的在于推断出关于使用相同的密钥加密的明文的信息。
选择明文攻击窃听实验(PrivKcpaA,Π(n)):
- 通过运行G(1n)获得密钥k
- 敌手得到输入1n,以及一个加密预言机Enck( . ),然后输出一对等长的明文m0, m1。
- 随机的选择一个比特 b∈{0,1},将密文c ← Enck(mb)返回给敌手A
- 敌手通过访问预言机Enck( . )然后输出一个比特b'
- 如果b'=b,则该实验的输出为1,否则为0。
同样的,如果某个私钥加密方案满足Pr[PrivKcpaA,Π(n)=1] ≤ 1/2 + negl(n),则称这个加密方案具有选择明文攻击下的不可区分性或者CPA安全的。
结论:上面构造的计算安全的加密方案在CPA攻击下并不具有不可区分性
证明:
敌手可以向预言机查询m对应的密文,预言机计算c := G(k)⊕m并返回给敌手A,于是敌手可以通过计算 G(k) = c ⊕ m得到G(k),在这种情况下,敌手相当于就获取了密钥,无论返回什么密文都可以通过 m := G(k)⊕c,而得到明文。,
多明文下的选择明文攻击:在上面的定义的基础上,允许敌手访问一个“左或右”预言机,这个预言机对于输入的一对等长明文m0, m1,计算密文 c←Enck(mb) 并且将 c 返回给敌手。如果b=0,则加密“左边”的明文,否则就加密“右边”的明文。
敌手可以通过向预言机查询LRk,b(m, m)来获取Enck(m)。
多明文下的选择明文窃听实验(PrivKLR-cpaA,Π(n)):
- 通过运行G(1n)获得密钥k
- 随机的选择一个比特 b∈{0,1}
- 敌手得到输入1n,以及一个上面所定义的预言机LRk,b( . ,.),输出挑战明文(m0,1, ..., m0,t)以及(m1,1, ..., m1,t),将密文LRk,b(m0,1, m1,1), ..., LRk,b(m0,t, m1,t)返回给敌手。
- 敌手输出一个比特b'
- 如果b'=b,则该实验的输出为1,否则为0。
还是和以前一样,如果某个多明文加密的私钥加密方案满足Pr[PrivKLR-cpaA,Π(n)=1] ≤ 1/2 + negl(n),则称这个加密方案具有多明文下选择明文攻击不可区分性或者说是对于多明文具有CPA安全性。
定理:任何一个CPA下安全的私钥加密方案在多明文加密下也是CPA安全的。
构造一个CPA安全的私钥加密方案
带密钥的函数:设F: {0, 1}* × {0, 1}* → {0, 1}*,是一个接收两个输入的函数,第一个输入即密钥,用 k 表示,第二个输入用 x 表示。如果 F 能够在给定k和x,多项式时间内计算出F(k, x),则称这个函数的高效率的。
通常密钥 k 一旦被选定就是固定了的,所以更加关注一个接收一个输入的函数 F: {0, 1}* → {0, 1}*,其定义为Fk(x) = F(k, x)
前面所讲的安全参数 n ,用于规定密钥长度,输入的长度以及输出的长度;
所以函数 F 通常也与另外三个函数建立联系:lkey, lin以及 lout:对于任何密钥 k ∈{0, 1}lkey(n),函数 Fk 定义为对任何输入x∈{0, 1}lin(n),都有F(x)∈{0, 1}lout(n)。
简易起见,假设 F 是长度保留的函数,也就是说lkey(n) = lin(n) = lout(n) = n,在这种情况下,固定密钥 k∈ {0, 1}n后,可以是函数Fk将 n 比特的输入映射到 n 比特的输出上。
伪随机函数的非形式化定义:如果一个函数Fk,对于任意的密钥 k 都是与具有相同定义域和值域的所有函数集合中均匀随机选择的函数不可区分的,则称这个函数是不可区分的。也就是说,没有任何一个高效率的敌手能够将 Fk (对于任意的密钥 k )和 f (从所有的将n比特输入映射到n比特输出的函数集合中任意选择的一个函数)区分开来。
- Fk与密钥k的长度有关,也就是说如果密钥k的长度为n,那么就可能有2n个Fk,那么在这种情况下,f 所属的集合Funcn(所有将n比特输入映射到n比特输出的函数的集合)应该有多大呢?
可以将任何一个函数 f 的映射关系用一张表来表示,这个表中的第 x 行中存储着对应的 f(x),所以对于n比特的输入,映射表应该有2n个行,而每一行中是一个n比特的01串,由此可以将任何一个函数用一个长度为n2n的串来表示。此外,还要考虑到 f 是一个双射函数,也就是说任何一个长度为n2n的串都唯一的表示一个函数 f ,所以Funcn的大小就是这个长度为n2n对应的实际数值,即|Funcn| = 2^{n2n}
伪随机函数的定义:设F: {0, 1}* × {0, 1}*→{0, 1}*是一个高效率且长度保留的带密钥的函数。F 是一个伪随机函数,如果对于任何一个运行在概率多项式时间上的区分器 D 都存在一个可忽略函数 negl 有:
| Pr[DFk(.)(1n)=1] - Pr[Df(.)(1n)=1] | ≤ negl(n)
D可以根据以前的所有输出自适应地选择查询。由于D运行在多项式时间内,因此它只能查询多项式多的查询。预言机的查询是一个确定性函数,也就是说对两次相同的查询会返回同样的结果。因此,为了不失一般性,可以假设D不会对相同的输入进行两次查询。
最重要的一点在于,D并不知道密钥 k ,因为如果D知道了k,那么借助预言机可以很简单的区分 Fk 和 f 。
反例1,确定型函数:定义一个带密钥的且长度保留的函数 F 为 F(k, x) = k ⊕ x。对于任何的输入 x ,Fk(x)都是均匀分配的,因为k是随机的。
那么区分器可以采取以下策略:对任意的两个不同的输入x1, x2,向预言机查询y1 = O(x1)以及y2 = O(x2),如果y1 ⊕ y2 = x1 ⊕ x2,就输出 1。
在这种情况下,如果O=Fk,那么D输出1的概率就是1;如果O = f,那么 D 输出1的概率就是Pr[ f(x1)⊕f(x2) = x1⊕x2 ] = Pr[ f(x2)=x1⊕x2⊕f(x1) ] = 2-n。
显然1-2-n并不是可忽略的,所以 F 不是伪随机函数。
反例2,错误的构造方法:设F是一个长度保留的伪随机函数,则定义一个新的带密钥函数F' : {0, 1}n × {0, 1}n-1 → {0, 1}2n,F'k(x) = Fk(0||x) || Fk(x||1)
区分器的策略:选择x1=0n-1, x2 = 0n-21,然后发送给预言机 O 。如果O(x1)的后 n 位与O(x2)的前 n 位相同则输出1。
当O=F'k时,因为F'k(x1) = Fk(0n)||Fk(0n-11),F'k(x2) = Fk(0n-11) || Fk(0n-212),所以Pr[DF'k(·)(1n)=1] = 1
当O= f 时,Pr[Df(·)(1n)=1] = 1/2n
所以|Pr[DF'k(·)(1n)=1] - Pr[Df(·)(1n)=1]| = 1-1/2n,1-1/2n显然不可忽略,所以F'k并不是伪随机函数。
带密钥置换:设F是一个带密钥的函数,称 F 是带密钥置换如果有:lin = lout,对于所有密钥 k ∈ {0, 1}lkey(n),函数Fk : {0, 1}lin(n) → {0,1}lout(n)是一个满射函数。
其中 lin 称为F的块长度。
对于给定的 k 和 x ,如果存在一个多项式时间的算法能够计算出Fk(x),并且给定 k 和 y ,存在一个多项式时间的算法能计算出F-1k(y),则称这个伪随机置换高效率的。
伪随机置换的定义:称一个高效率的带密钥置换为伪随机置换如果不存在一个高效率的算法能够区分 Fk 和任意的 f ∈ Permn(即所有的在{0, 1}n上的置换)
需要注意的是,无论块长是否是足够的长,一个随机的置换本身就和一个随机的函数是不可区分的。
定理:设 F 是一个随机置换,如果 lin(n) ≥ n,则 F 也是一个伪随机函数。
强伪随机置换的定义:设Fk : {0, 1}* → {0, 1}*是一个高效率且长度保留的带密钥置换,称 F 是强伪随机置换如果对所有运行在PPT上的区分器 D ,存在一个可忽略函数有:
| Pr[DFk(.), Fk-1(.)(1n)=1] - Pr[Df(.), f-1(.)(1n)=1] | ≤ negl(n),同样的,f ∈ Permn
如果有了伪随机函数,那么构造一个伪随机生成器G就会变得十分简单,可以直接对不同的输入求 F 的值:G(s) ≝ Fs(1) || Fs(2) || ... || Fs(l)。
基于伪随机函数构造流密码
还可以基于任何一个伪随机函数或者块密码来构造一个流密码:
设 F 是一个伪随机函数,定义一个流密码(Init, GetBits),其中GetBits的每次输出都是 n 比特的:
Init:对于输入s ∈ {0, 1}n,以及初始向量IV ∈ {0, 1}n,输出st0 := (s, IV)
GetBits:对于输入sti = (s, IV),计算 IV ` := IV+1,然后设y := Fs(IV `),sti+1 := (s, IV `),输出(y, sti+1)。
构造CPA下安全的加密方案
设F是一个伪随机函数,则定义一个对于明文长度为 n 的私钥加密方案如下:
Gen:对于输入1n,随机的选择 k ∈ {0, 1}n 并输出k
Enc:对于输入的 k ∈ {0, 1}n以及明文 m ∈ {0, 1}n,随机的选择 r ∈ {0, 1}n,然后输出密文 c := <r, Fk(r)⊕m>
Dec:对于输入的 k ∈ {0, 1}n以及密文 c = <r, s>,输出明文 m := Fk(r)⊕s
定理:如果F是一个伪随机函数,则由上面的方案构造的对于明文长度为 n 的私钥加密方案是CPA安全的。
一个常见的模板,用于大多数的安全证明:
- 首先,考虑一个假设的构造版本,其中伪随机函数被替换为随机函数。
- 然后讨论—使用proof by reduction证明—此修改不会显著影响攻击者的成功概率
定理的证明:
设加密方案 Π' =(Gen', Enc', Dec'),其与上面所构造的加密方案唯一的区分就是用一个随机的函数 f 取代了Fk
又设 q(n) 是敌手 A 在CPA窃听实验中查询加密预言机的查询次数上限
区分器 D 利用 A 来进行对伪随机函数 F 的区分实验,也就是说 D 对 A 进行了一个仿真的PrivKcpa实验:
- 运行A(1n),当 A 向自己的加密预言机查询 m 的密文时,D随机的选择一个01串 r ∈ {0, 1}n,然后 D 又利用自己的预言机计算O(r),然后返回<r, O(r)⊕m>给敌手A
- 当敌手输出挑战明文m0, m1 ∈ {0, 1}n时,随机的选择一个比特 b ∈ {0, 1},然后又随机的选择一个01串 r ∈ {0, 1}n,计算O(r),然后返回<r, O(r)⊕mb>给敌手A
- 敌手 A 可以向 D 进行多次查询。D 获得敌手输出的b',如果 b = b',则输出 1;否则输出0。
根据前面所构造的加密方案Π‘,则可以得出以下结论:
- 如果 D 的预言机是一个伪随机函数 F ,则对于 A 来说就相当于进行PrivKcpaA, Π(n)实验;根据 D 的策略可知:Pr(k←{0,1}n)[DFk(·)(1n)=1] = Pr[PrivKcpaA, Π(n)=1]
- 如果 D 的预言机是一个随机的函数 f , 则对于 A 来说就相当于进行PrivKcpaA, Π’(n)实验;根据 D 的策略可知:Pr(f←Funcn)[Df(·)(1n)] = Pr[PrivKcpaA, Π‘(n)=1]
因为F是一个伪随机函数,所以存在一个可忽略函数negl,使得:
| Pr(k←{0,1}n)[DFk(·)(1n)=1] - Pr(f←Funcn)[Df(·)(1n)] | ≤ negl(n)
再由上面的等式关系可以得出:| Pr[PrivKcpaA, Π(n)=1] - Pr[PrivKcpaA, Π‘(n)=1] | ≤ negl(n)
现在再来考虑实验PrivKcpaA, Π’,这个实验有两种可能性:
- 如果在加密挑战明文时所使用的 r 在前面 A 的查询中没有出现过,那么 A 就对 f(r) 的任何信息都不知情,那么 A 输出的b'=b的概率就是1/2
- 如果在加密挑战明文时所使用的 r 在前面 A 的查询中出现过,也就是说 A 获取了<r, f(r)⊕m>,那么其可以通过计算 f(r)=f(r)⊕m⊕m 就能得出f(r),在得知了 f(r) 的情况下,A输出的b'=b的概率就为1了
把事件“加密挑战明文时所使用的 r 在前面 A 的查询中出现过” 记为事件Repeat,则Pr[Repeat] ≤ q(n) / 2n,从而:
Pr[PrivKcpaA, Π'(n)=1] = Pr[PrivKcpaA, Π‘(n)=1 ∧ Repeat] + Pr[PrivKcpaA, Π’(n)=1 ∧ Not Repeat] = Pr[Repeat] + Pr[PrivKcpaA, Π‘(n)=1 ∧ Not Repeat] ≤ q(n)/2n + 1/2
再把这个式子带到上面的等式中可以得到:
Pr[PrivKcpaA, Π(n)=1] ≤ 1/2 + q(n)/2n +negl(n)
因为q(n)是一个多项式,所以q(n)/2n也是可忽略的,两个可忽略函数的和仍然是可忽略的,所以存在一个可忽略函数negl'(n) = q(n)/2n + negl(n),则:
Pr[PrivKcpaA, Π(n)=1] ≤ 1/2 + negl'(n)
操作模式
这里所讨论的操作模式即在使用流密码或者块密码加密长的明文时所采用的加密流程。
流密码下的操作模式
上面所构造的计算安全的加密方案有两个缺点:
- 需要事先知道待加密的明文的长度并固定
- 加密方案只在被动攻击下具有不可区分性,但在CPA下并不具有不可区分性
而流密码事实上可以看作一个灵活的伪随机生成器,从而弥补上面个的那两个缺点。
流密码的操作模式有两种:同步模式和异步模式
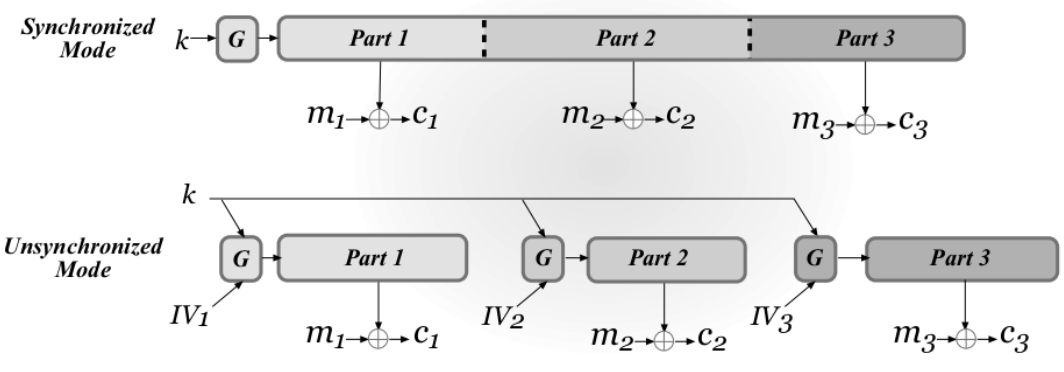
同步模式下,在有状态的加密方案中,发送方和接收方都必须保持同步以确定有多少明文已经被加密了。同步模式通常用于通信双方的单向通信,无状态的通信在其中也是可以接受的并且明文是按顺序接受以确保不会被丢失。为了保持状态,通信双方可以使用相同的密钥来加密多个明文,将多条明文看作一个长的明文,在同步模式下,加密的过程不需要初始向量IV。同步模式允许通信双方发送无线条任意长度的明文,然而同步模式通常只适用于通信双方单向会话,但这并不适合用于不定时的通信或者通信中的一方可能会超时或者转接到另外一台设备上。
异步模式下,接收初始向量IV作为 Init 函数的输入,从而可以实现加密任何长度明文的无状态CPA安全的加密方案。
块密码下的操作模式
上面所构造的CPA安全的加密方案同样也有一个缺陷,那就是密文的长度是明文长度的两倍。
而块密码的模式提供了一种用更短的密文加密任意长度的明文的加密方法。
设 F 是一种块密码,而 n 是其块长度,如果明文的长度不是 n 的整数倍,则通过在明文末尾添加足够多的 0 并跟上一个 1 使得明文的长度为 n 的整数倍。
在此基础上,可以将明文表示为:m = m1, m2, ..., ml,其中mi ∈ {0, 1}n。
- ECB(Electronic Code Book)模式
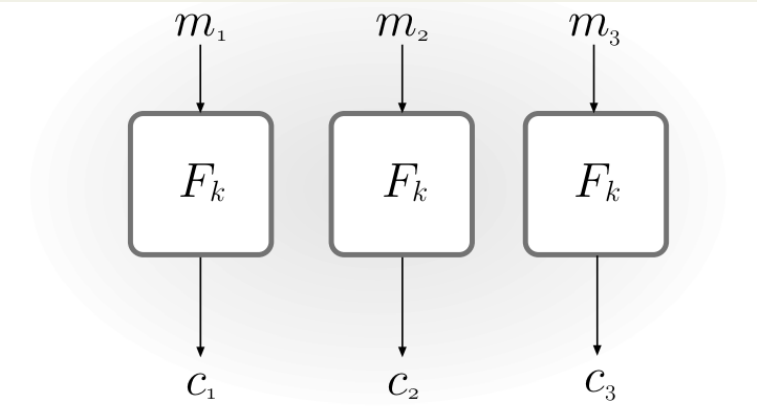
c := <Fk(m1), Fk(m2), . . . , Fk(ml )>
相应的,解密过程就通过F(-1)k来计算明文。
然而ECB模式显然不是CPA安全的加密方案,更糟糕的是,ECB甚至在被动攻击下也不具有不可区分性,这是因为如果相同的块如果在明文中出现两次,那么也能在密文中找到两个相同的块。
因此ECB从来没有被使用过。
- CBC(Cipher Block Mode)模式
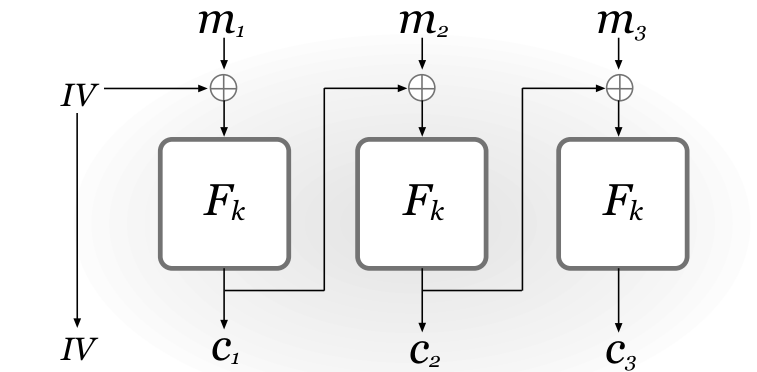
在开始加密之前,需要随机的选择一个 n 比特长的初始向量IV,然后将当前明文块和前一个密文块的异或,再通过 F 函数生成新的密文块。
需要强调的是,初始向量也是密文的一部分。
可以通过证明得知如果 F 是一个伪随机置换,那么CBC模式是CPA安全的。
然而CBC主要的缺点在于其加密过程必须按顺序执行,所以如果在并行程序下,CBC就不是最有效率的方案。
- OFB(Output Feedback Mode)模式
这种模式和异步模式下的流密码相似
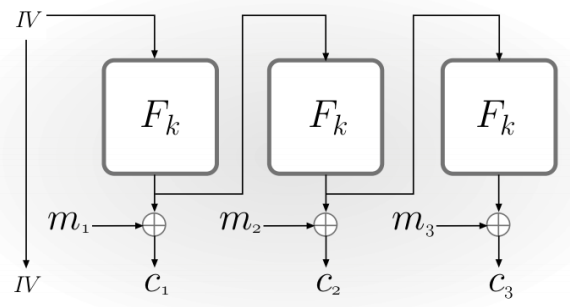
和前面两种模式相比,这里不再要求 F 是可逆的函数,或者说不需要 F 是置换。
此外,OFB模式下并不需要明文长度是块长度的整数倍。
如果 F 是为随机函数那么 OFB 模式就是CPA安全的方案。
这种模式的优点在于可以在明文到来之前完成一部分的计算( Fk部分 ),从而提高加密的效率。
- CTR(Counter)模式
CTR模式也可以看作异步模式下的流密码:
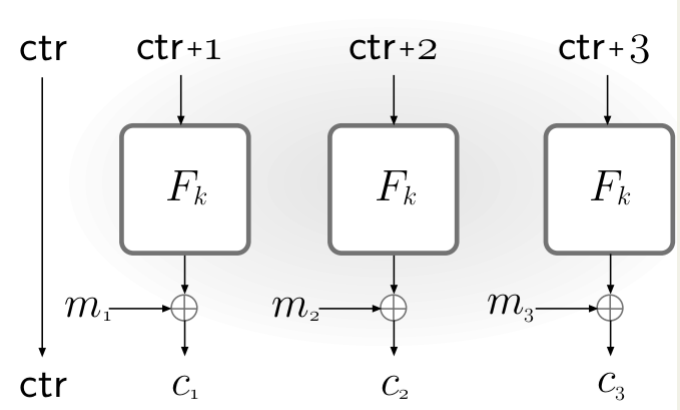
在开始加密之前需要选择一个ctr ∈ {0, 1}n,然后计算yi := Fk(ctr+i)(其中 ctr 和 i 都被看做整数,并进行模2n的运算),最后第 i 个密文块就是 ci := yi ⊕ mi。
同样的,ctr 也会被作为密文的一部分,而且不需要 F 是可逆函数,或者不需要 F 是置换。
和前面的几种模式相比,CTR是可以并行进行的,而且在同样可以在明文到来之前计算不同的Fk,从而提高加密效率。
如果 F 是伪随机函数,那么CTR模式是CPA安全的。
选择密文攻击
在选择明文攻击下,敌手不仅可以选择一个明文 m 来获得对应的密文,或可以选择一个密文 c 来获得对应的明文。
选择密文攻击窃听实验(PrivKccaA,Π(n)):
- 通过运行G(1n)获得密钥k
- 敌手得到输入1n,以及一个加密预言机Enck( · )和解密预言机Deck( · ),然后输出一对等长的明文m0, m1。
- 随机的选择一个比特 b∈{0,1},将密文c ← Enck(mb)返回给敌手A,将这个密文称为挑战密文。
- 敌手可以访问预言机Enck( · )和Deck( · ),但是不允许使用预言机来查询挑战密文,然后输出一个比特b'
- 如果b'=b,则该实验的输出为1,否则为0。
同样的,如果某个多明文加密方案满足Pr[PrivKccaA,Π(n)=1] ≤ 1/2 + negl(n),则称这个加密方案具有选择密文攻击下的不可区分性或者是CCA安全的。
定理:任何一个CCA下安全的私钥加密方案在多明文加密下也是CCA安全的。
前面所构造的CPA安全的加密方案在选择密文攻击下不具有不可区分性
证明:
敌手输出的两条挑战明文可以为:m0=0n,m1=1n,在收到了挑战密文<r, s>后,敌手可以将 s 的第一个比特进行翻转并令其等于 c‘ ,然后向解密预言机查询<r, c'>,因为c' ≠ s,所以查询会被允许。如果返回的结果为10n-1则输出b'=0,如果返回结果为01n-1则输出b'=1。
CCA安全的必要条件
密文的可延展性:如果已知m1, ..., mk对应的明文为c1, ..., ck,那么对c1, ..., ck进行某个线性组合后仍然是一个合法的密文,即解密后可以得到相应的明文
密文的可延展性往往表现在同态加密上
同态加密:
- Deck(Enck(m1) · Enck(m2)) = m1 + m2(加法同态)
- Deck(Enck(m1) · Enck(m2)) = m1 × m2(乘法同态)
如果一个加密方案是同态的,那么必然不是CCA安全的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号