
恢复系统
系统故障:掉电或者突然关机,易失性内存中的数据丢失。
事务故障恢复
需要保证事务的持久性:已提交的事务,缓冲区内容能保证写回到磁盘;未提交的事务,缓冲区内容不能影响到磁盘
需要保证事务的原子性:input(B)将B从磁盘复制到内存;output(B)将B从内存写回到磁盘;read(X)从缓冲区读取X的值;write(X)把X的值写回到缓冲区。如果在write和output之间发生系统故障,那么事务的原子性遭到破坏。
对于发生故障时已提交的事务,需要进行重做Redo
对于发生故障时未提交的事务,需要进行撤销Undo
缓冲区处理策略
Force:内存中的数据最晚在commit的时候写入磁盘
No steal:不允许在commit之前写回磁盘
No force:允许在commit之后再写回磁盘(可能在系统崩溃之后没有更新到磁盘,需要Redo)
Steal:允许在commit之前写回磁盘(可能会有未完成的事务在系统崩溃之前完成了更新,此时需要Undo)
当前常用的缓冲区处理策略是:Steal+No force
故障恢复的基本思路
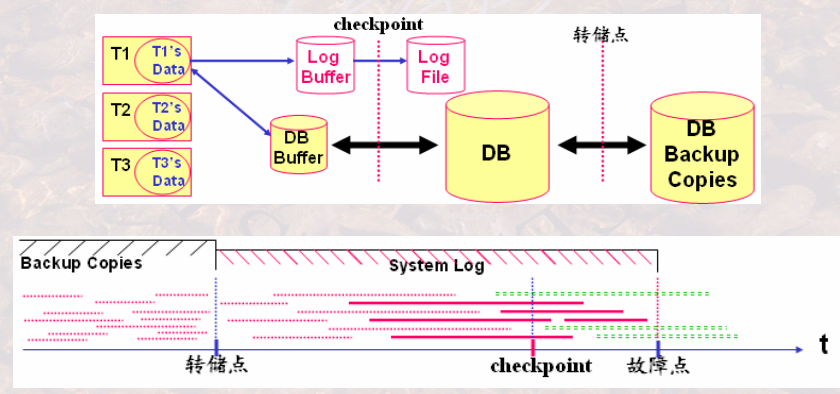
副本:在某一时刻,对数据库在其他介质存储上产生另一份等同的记录。如果法伤了介质故障,就用副本替换被损坏 的数据库。
转储点:进行备份的时刻。为了使运行日志和转储操作能够无隙连接,通常要求转储点也是运行日志开始和结束的时刻。
转储点过频会影响系统的效率,转储点过疏会导致运行日志过大,也会影响系统性能。
数据库中的故障恢复是通过日志完成的,先写日志再执行操作。
运行日志是DBMS维护的一个文件,该文件以流水方式记录了每一个事务对数据库的每一次操作以及操作顺序;运行日志直接写在介质存储上,从而保持正确性;当事务对数据库进行操作时:应该先写日志;写成功后(步骤①),再与数据库缓冲区进行信息交换(步骤②)。
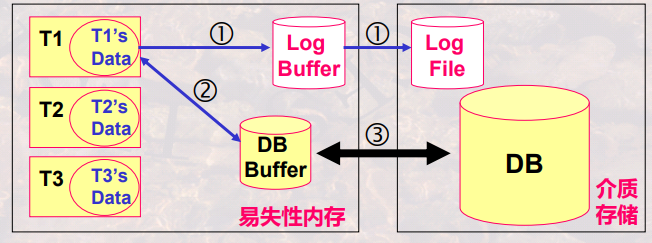
检查点:检查点是这样的一个时刻:系统将DB buffer中更新的内容写回到DB中的时刻。也就是说,检查点之前缓冲区与数据库应该是一致的,所以在检查点之前提交的事务就不需要进行处理了,因为它们的更新已经写回到DB中了。
在检查点之后结束或者发生的事务需要依据运行日志进行故障恢复:故障点之前结束的事务需要重做,故障点时刻未结束的事务需要撤销。
故障恢复
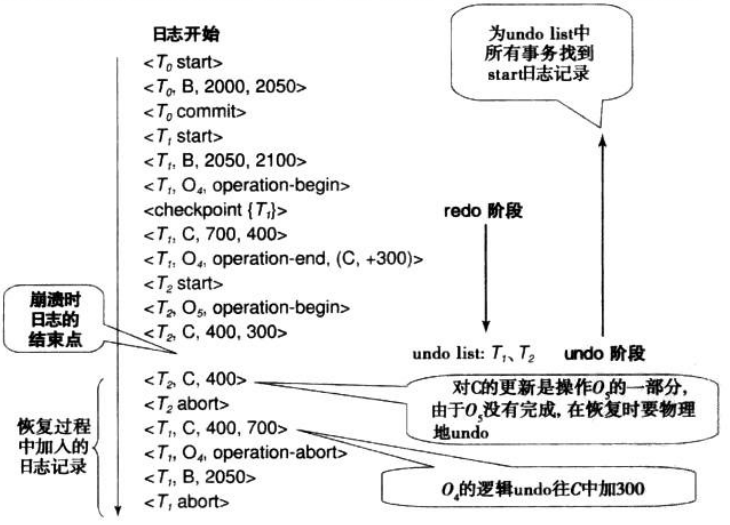
运行日志:一个包含日志记录的只能追加的顺序文件,不同事务的日志记录交错存储,按照发生时间进行存储。
日志记录的信息:
<Start T>,表示事务T已经开始
<Commit T>,表示事务T成功完成
<Abort T>,表示事务T未成功,被终止
<T,X,v1>,表示事务T将数据项X的值设为v1;或者<T,X,v1,v2>,表示事务T该表了数据项X的值,其中X的旧值是v1,新值是v2
- 对于在检查点之前完成(commit或者abort)的事务不做任何处理;
- 对于在检查点之后完成的事务,加入redo-list
- 对于在检查点之后还没有出现commit或者abort记录的事务,加入undo-list
对于redo-list中的事务,按照时间正序,将所有数据项设为新值;对于undo-list中的事务,按照时间倒序,将所有数据项设为旧值。
故障恢复的具体步骤:
Redo阶段(按照运行日志从上往下检查):检查redo-list中的事务,一旦发现有更改数据项的操作记录,就重做该纪录中执行的操作。
Undo阶段(按照运行日志从下往上检查):检查undo-list中的事务,一旦发现形如<T,X,v1,v2>的日志记录,就将X置为v1并添加一条<T,X,v1>记录;一旦发现<Start T>就添加一条<Abort T>记录。
逻辑undo日志记录:
<T,O,operation-begin>,表示操作O开始
<T,O,operation-end,U>,表示操作O结束,其中U表示undo的信息,比如(X,200)即表示数据项X的新值需要+200得到旧值
<T,O,operation-abort>,执行了undo操作后添加的日志
逻辑undo的事务回滚:
- 通过使用日志记录中的undo信息U来回滚操作。在对操作的回滚中,将所执行的更新记入日志,就像操作首次执行时进行的更新一样。在操作回滚到最后,数据库系统不产生<T,O,operation-end,U>日志记录,而是产生<T,O,operation-abort>日志记录。
- 随着对日志记录的反向扫描(按照时间倒序)的进行,系统跳过事务T的所有日志记录,直到遇到<T,O,operation-begin>日志记录。
下面给出一个例子:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号