pandas 哑变量处理 聚合 分组
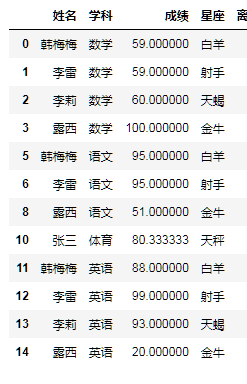
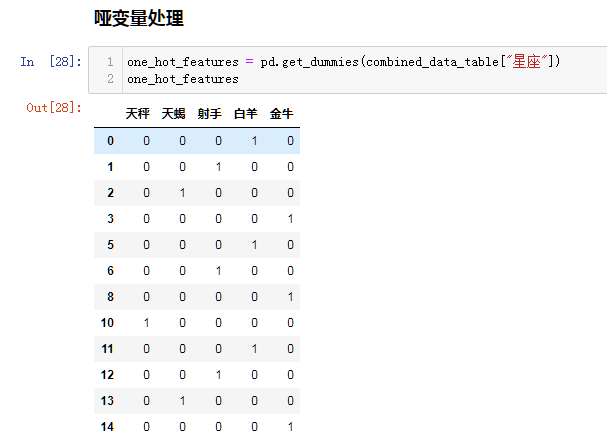
哑变量处理 pd.get_dummies(table,columns=['column1',''...])
pd.get_dummies(combined_data_table,columns=["星座",'学科'],drop_first=True) # drop_first 星座有5种,设置为True后,会删掉一种。统计学里头自由度为n-1,最后一种是多余的。
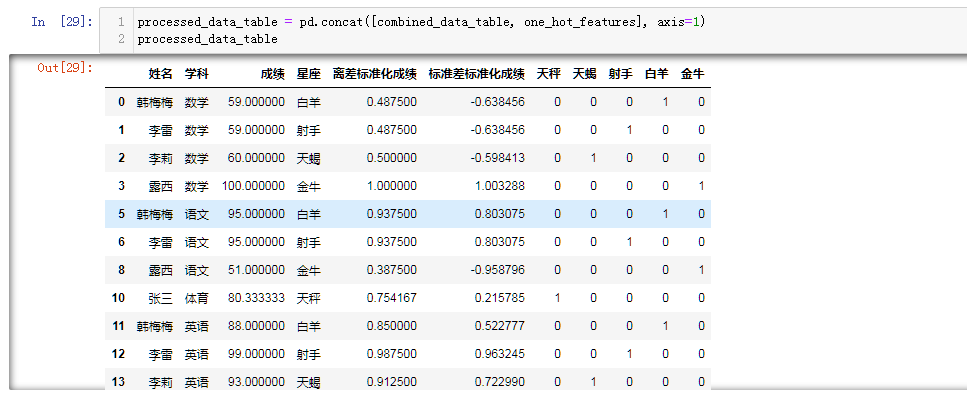

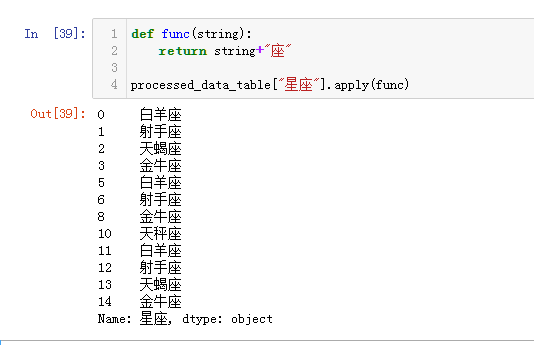
批量操作 df.apply(func)
processed_data_table["星座"].apply(lambda x: x+"座")
def func(string):
return string+"座"
processed_data_table["星座"].apply(func)
数据标准化
离差标准化
combined_data_table["离差标准化成绩"] = (combined_data_table["成绩"] - combined_data_table["成绩"].min()) \
/ (combined_data_table["成绩"].max() - combined_data_table["成绩"].min())
标准差标准化
combined_data_table["标准差标准化成绩"] = (combined_data_table["成绩"] - combined_data_table["成绩"].mean()) \
/ combined_data_table["成绩"].std()
整列合并计算 df1.agg({'column1':np.means,'column2':'mode'})
# agg 聚合简写,np.mean 对列取平均,mode 众数
table.agg({"成绩": np.mean, "星座": 'mode'})

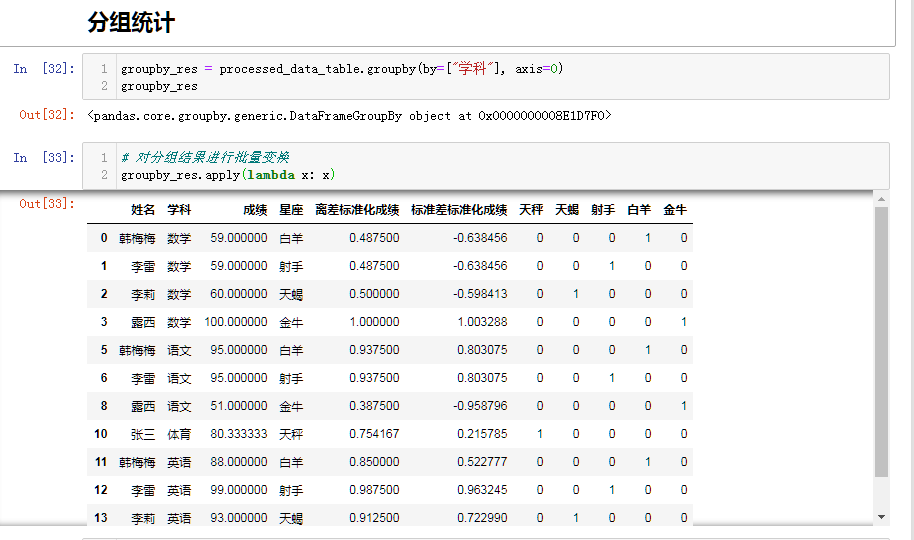
分组统计 df1.groupby()
groupby_res = processed_data_table.groupby(by=["学科"], axis=0)
# 对分组结果进行批量变换,原表返回
groupby_res.apply(lambda x: x)
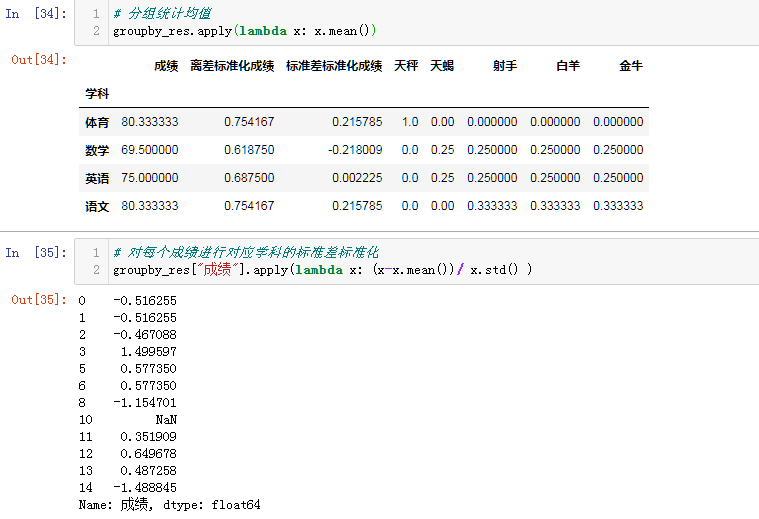
# 分组统计均值
groupby_res.apply(lambda x: x.mean())
# 对每个成绩进行对应学科的标准差标准化.组内标准化
groupby_res["成绩"].apply(lambda x: (x-x.mean())/ x.std() )
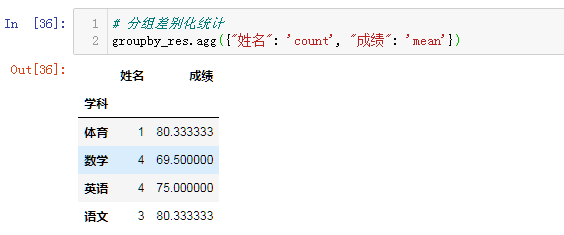
# 分组差别化统计
groupby_res.agg({"姓名": 'count', "成绩": 'mean'})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号